AI/ML Best Practices During a Gold Rush

Introduction
The California Gold Rush started in 1848 and lasted until 1855. It is estimated that approximately 300,000 people migrated to California from other parts of the United States and abroad. Economic estimates suggest that, on average, only half made a modest profit. The other half either lost money or broke even. Very few gold seekers made a significant profit.
Gold was not the only way to make money during these years, though It turns out that the wealthiest man in California during the earlier years of the Gold Rush was a man named Samuel Brennan. When the Gold Rush began, he bought all the mining supplies available in San Francisco and sold them for a substantial profit to the newly arriving miners. Another creative businessman, Levi Strauss, realized that the tough working conditions required tough clothing. So, he began selling denim overalls in San Francisco in 1853. In short, it was better to be a vendor than a miner.
For miners, the California Gold Rush was not an investment that could be completely analyzed and planned. If you wanted to participate, you left your family and started the long, arduous journey to California. Once you got there, you bought your supplies and started digging. This was the best that could be done in 1849. In short, gold miners were “all in,” or they stayed out of California.
The AI/ML boom is similar to the California Gold Rush in that tool vendors have an advantage — they profit whether an organization succeeds or fails. Every sale to a party that fails is worth just as much as the same sale to a party that profits, with the obvious caveat that a failed company can’t renew a license. With AI/ML, cloud providers, compute vendors, storage vendors and chip manufacturers will benefit the most.
Unlike the Gold Rush, the adoption of AI/ML can be planned. It should be planned. This post looks at how an organization can start small, improve internal tooling and processes, and intelligently adopt large language models (LLMs) that are capable of generative AI.
Start with a Simple Problem
A better name for LLMs would be “complicated and expensive to train models.” Unfortunately, that does not roll off the tongue like “large language models.” The point is that LLMs are not a good way to start with AI/ML. A better approach is to look for low-hanging fruit – find areas of your organization that would benefit from a model that makes a simple prediction. This could be a regression, categorization or classification problem. Building a model that predicts a single value (regression), categorizes or classifies your data will require far less compute than an LLM, so you will see value with less investment. Additionally, the tools and processes that you put in place while building a regression, categorization or classification solution will get your team and infrastructure ready for more complex projects like large language models.
Let’s take a look at these processes and tools you should put in place while building your first production model.
Invest in All Phases of the AI/ML Workflow
The AI/ML workflow starts with unstructured storage for your raw data and ends with a model serving predictions in a production environment. Using the right tools for each model development phase will speed up the process and produce better results. At a high level, this workflow looks like the graphic below.

Storage
For storage, you will want a future-proof solution. Someday you may need to support petabytes of data and feed GPUs that are training models. A storage solution that can not keep up with a GPU will cause the GPU to wait. A waiting GPU is wasted. This is where software-defined, high-performance object storage helps. When you employ this architecture, the same interface is used by engineers when the object store is used on low-cost infrastructure and when it is used on a high-end cluster. A high-end deployment of MinIO on a Kubernetes cluster with NVMe drives can keep up with the fastest GPUs. This is important because a GPU that waits for data is an underutilized GPU.
Preprocessing, Feature Engineering, Model Training
Consider using tools like Kubeflow, MLflow, and Airflow to build data pipelines and model training pipelines for the preprocessing, feature engineering and model training phases of your workflow. The more efficiently you run experiments and track results, the better your models.
If you do not have a lot of GPUs, don’t worry. Distributed training is a way to squeeze every ounce of compute from your existing CPUs. PyTorch and TensorFlow, the two most popular frameworks for training models, have libraries for distributed training. If you want to take advantage of existing clusters within your data center, then consider a library like Ray.
Model Testing
When testing a model, be sure to hold out a test set from your engineers. This is a great way to see how a model will perform when it is given data it has never seen before. You can also use a test set to ensure that a new version of a model is an improvement over the previous version.
Model Serving
Finally, tools like TorchServe, TensorFlow Serving and KServe can serve your models in a production environment.
Once you have harvested all the low-hanging fruit in your organization, you will want to include generative AI capabilities into your applications. Before looking at LLM options, let’s get an idea of cost based on the size of the LLM.
Related: MLOps Architecture Guide for AI Infrastructure
The Cost of Training Large Language Models
The public LLMs — ChatGPT from OpenAI and Microsoft, Large Language Model Meta AI (LLaMA) from Meta, and Pathways Language Model Version 2 (PaLM 2) from Google — are general purpose LLMs. They need to be able to handle requests on all topics from the entire recorded history of humankind. Consequently, these models are exceptionally large and correspondingly expensive.
As an example, consider the statistics recently released by Meta about its latest and largest LLM, known as LLaMA. The model contains 65 billion parameters. It used 2,048 Nvidia A100 GPUs to train on 1.05 trillion words. Training took 21 days. That is 1 million GPU hours. An A100 GPU costs roughly $10,000. The total cost for just the GPUs would be around $20.5 million. Consider this the on-premises training cost. And at 65 billion parameters, it’s smaller than the current GPT models at OpenAI like ChatGPT-3, which has 175 billion parameters. For most organizations, building such a large model is cost prohibitive, regardless of your choice of compute (purchased GPUs or cloud). Furthermore, you may not need all this information in your model. The alternative is to explore other options. These other options are:
- Train a large language model from scratch with less data
- Use an API from a public LLM
- Fine-tune an existing LLM
- Use retrieval augmented generation
The rest of this post will look at each of these options. Let’s start by seeing what it would take to build an LLM from scratch, but with less data.
Train a Large Language Model from Scratch
An LLM trained on a corpus of your choosing will be cheaper to train if the amount of data used is smaller than that used to train the public LLMs. (If it is not, then this option may not be best for you. Consider using one of the public LLMs, as discussed in the next section.) The answers it provides will also be more specific if your corpus comes from a specific domain or industry. Another benefit is that this option gives you complete control over all the information the model sees. Don’t confuse this option with fine-tuning a pre-trained model (discussed later). When you train a model from scratch, you start with a model with zero knowledge. In other words, it is your code that will instantiate the model for the first time and send it on its first epoch. Consider using the source code from an open sourced LLM as your starting point. This will give you a model architecture from a proven LLM.
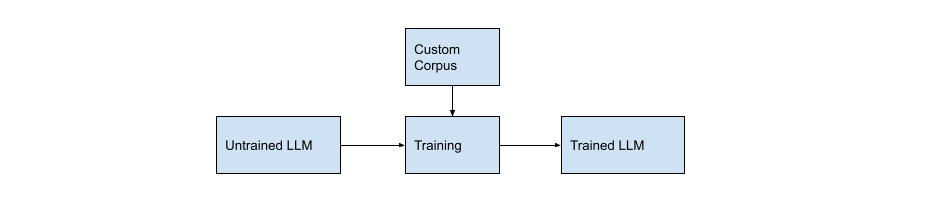
When you are in control of all the information an LLM sees, then you are basically building a domain-specific LLM. Such an LLM would produce great results for a company that owns a corpus of proprietary information with deep knowledge of a specific industry. Health care, professional services and financial services are a few industries that come to mind. This could also be the way to go if you are heavily regulated and need control over all the data used.
Next, let’s look at an option that does not require training at all, and costs are based on usage.
Use the APIs from a Public LLM
All the major public LLMs expose their models via an API. Using these APIs is a quick way to add generative AI capabilities into your application without having to host a model yourself or purchase additional infrastructure to handle the additional compute required. It will also serve as a performance benchmark should you decide to move on and build your own custom LLM. (Performance here refers to the accuracy of the response.)
Using these APIs is a little more involved than passing along a question that a user entered into an interface. The payload you send to the API of a public LLM is known as a “prompt.” A prompt is composed of the question as well as additional context that could help the LLM produce an accurate response. The context can even contain new information you would like the LLM to incorporate into its answer. Finally, if the question being asked is part of a previous conversation with the LLM, then the previous questions and answers must be included in the prompt.

Be sure to understand your expected usage and estimate your costs before pursuing this option. Price is based on the number of “tokens” sent in the prompt. (A token is typically 0.75 of a word.) This option may not be the best choice if your application is a public website.
There are a couple of disadvantages with public LLMs. The first is that they quickly become out of date. You could add new information in the context as previously described, but that means you have to go find the relevant information based on the question. It also adds to your cost since it will increase the token count on each request. Another disadvantage is that you may be sending private data to the public cloud if you are contextualizing your prompts. Be sure to check the source of all information put into your prompts and check the data policy of the public LLM you are using.
If you do not want to contextualize each prompt, then it is possible to fine-tune a model with additional information. Let’s look at fine-tuning next.
Fine-Tune an Existing LLM
“Fine Tuning,” a model is the act of taking a model that has already been trained and training it a little further with additional information. Before LLMs, this was often done with models created for image recognition. Let’s say you have a model that was trained on a large dataset of images, like ImageNet. This model would recognize many different shapes — it would be a generalist. If you needed a model that recognized dangerous animals, then you could fine-tune it by training it further with a collection of dangerous animal images. The final model would do a much better job detecting dangerous animals than the original model because it has additional information.
Large language models can also be fine-tuned. It works the same way as just described. An existing LLM can be further trained on information unavailable at the time of its initial training, bringing it up to date without requiring the model to be trained from scratch. An existing LLM could also be fine-tuned with information about a specific domain, making it more of an expert in this domain than the original LLM.
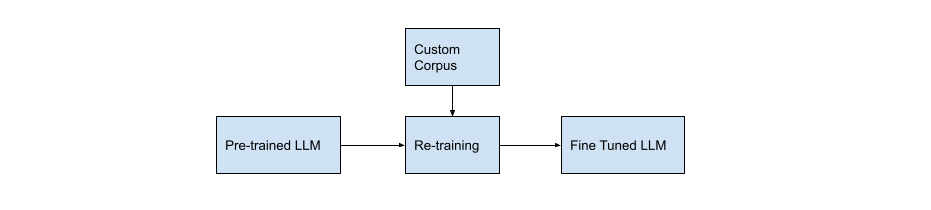
Also, many publicly available LLMs provide fine-tuning features. You can pick the model to start from, upload your data to be used for fine-tuning, train your custom model, and then send a request to it. Use this option with caution if you need an LLM trained on sensitive data. Both your new model and the data you sent to train it will be in the public cloud. Here are details on fine-tuning ChatGPT.
Fine-tuning may sound like a panacea, but fine-tuning can get expensive if it needs to happen often. Let’s look at an option that produces current responses while eliminating the need for retraining.
Retrieval Augmented Generation
Retrieval augmented generation (RAG) is a way to get the most value out of the context portion of an LLM prompt. As stated previously, the context is additional information sent to an LLM with the original question. It can help the LLM produce a more specific response. The context can also contain facts that the LLM did not have access to when it was trained and should be incorporated into the response. This may sound like an odd thing to include in a prompt. If you already know the answer, why are you asking the question? The code that creates a prompt does not have a priori knowledge about the answer to the question. Rather, it tokenizes the question and uses these tokens to find snippets of documents in a custom document database to include in the prompt as context.
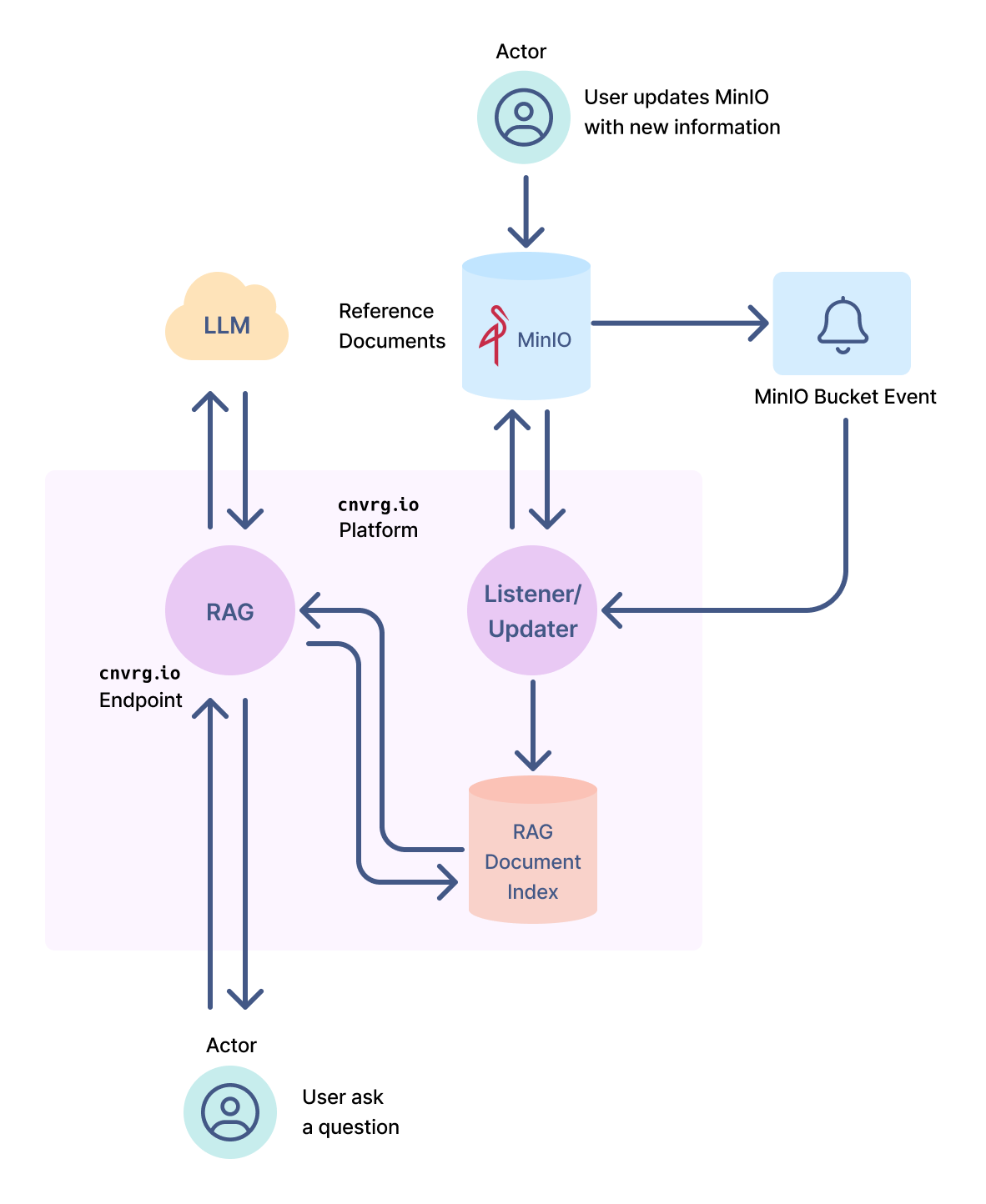
RAG is an exciting new use of LLMs that could provide the benefits of fine-tuning without the need for retraining. At MinIO, we partnered with Cnvrg.io to create a demonstration showing the value of this technique. A diagram of the solution is shown below. Cnvrg.io built a platform to make RAG turnkey for its customers. Their Cnvrg.io platform uses MinIO to store documents that are eventually used to create a prompt’s context. Cnvrg.io took advantage of MinIO’s bucket event notifications to keep its document index updated in real time. You can read more about the complete solution here.
Conclusion
AI/ML does not have to unfold like the California Gold Rush. Organizations can start small while improving internal tooling and processes. Think of your first AI/ML project as a search for your first few gold flakes. However, it does not have to be a random search like panning a riverbed. Every application can benefit from predictions, whether it is an internal line of business application or a public website. With a bit of analysis, you can find your first project that will provide maximum value.
When it comes to LLMs, they do not have to be an expensive undertaking —and you do not have to give all your profits to the vendors. By knowing all the options and the pros and cons of each option, organizations can pick the best choice for their needs.






