Apache XTable: Advancing Data Interoperability in Data Lakehouses

Apache XTable takes a big step in enhancing interoperability by providing access to your data in multiple open table formats. Moving data is hard, and in the past this meant that when selecting an open table format for your data lakehouse you were locked into that selection.
When interoperability is introduced at this layer of the data stack, it effectively commoditizes query engines, driving down pricing and forcing the query engines themselves to differentiate their offerings to the benefit of their users with things like advanced features, optimized query performance, and other value-added capabilities that go beyond simple data access, ultimately fostering innovation and competition in the analytics ecosystem.
What is Apache XTable?
Apache XTable is an open-source metadata translator that simplifies interoperability between the open table formats: Apache Iceberg, Apache Hudi, and Delta Lake. Instead of duplicating data or being locked into one format, XTable lets you read and write across multiple table types. It's lightweight, efficient, and ideal for flexible data architectures where format flexibility matters.
How Does it Work?
XTable lets you switch between the open table formats without moving or rewriting your data. It works by reading your table’s existing metadata and writing out new metadata in the right format, so your data appears as if it was originally written in Delta, Hudi, or Iceberg. The metadata is stored where each format expects: delta_log for Delta, metadata/ for Iceberg, and .hoodie/ for Hudi. From there, your choice for compute can read your data with the metadata of your choice.
The architecture of Apache XTable comprises three primary components:
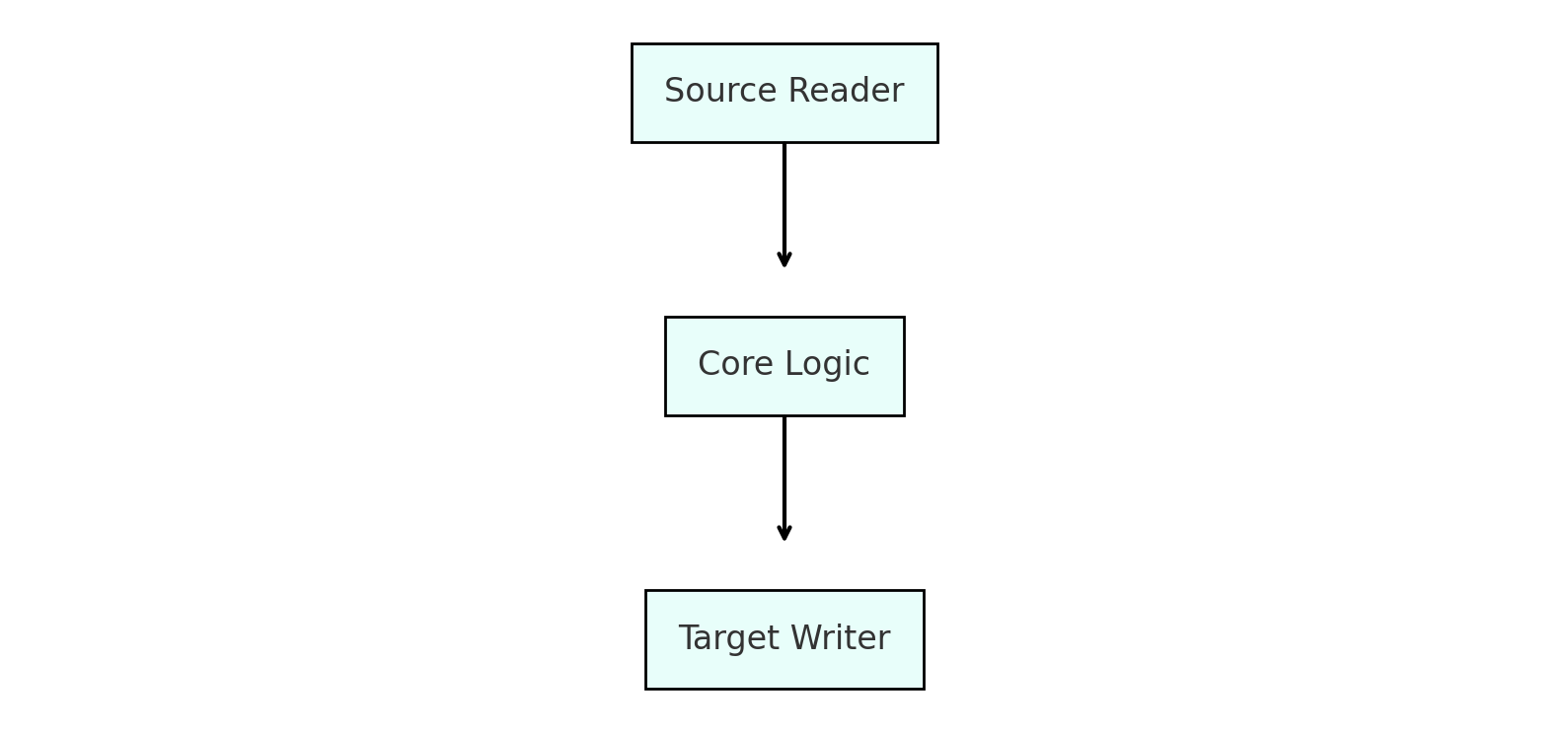
Source Reader: This module is responsible for reading metadata from the source table format. It extracts essential information such as schema definitions, transaction history, and partitioning details, converting them into a unified internal representation.
Core Logic: Serving as the central processing unit, the core logic orchestrates the entire translation process. It manages the initialization of components, oversees state management, and handles tasks like caching for efficiency and incremental processing.
Target Writer: This module takes the unified internal representation from the core logic and maps it accurately to the target table format's metadata structure, ensuring consistency and compatibility
Use Cases
We’ve already shown you how you can migrate from Hadoop to MinIO without a complete rip out and replace. Great software came out of the Hadoop ecosystem, including HMS and Hudi.
Our template for migration allows you to keep HMS, while dropping Hadoop in favor of MinIO for storage. This is possible because HMS has an S3 connector.
From this point, an organization can build data lakehouse with HMS, Hudi and MinIO. From there, without migrating their data they can explore other compute engines like Dremio and Snowflake, which operate over Iceberg Tables with XTable.
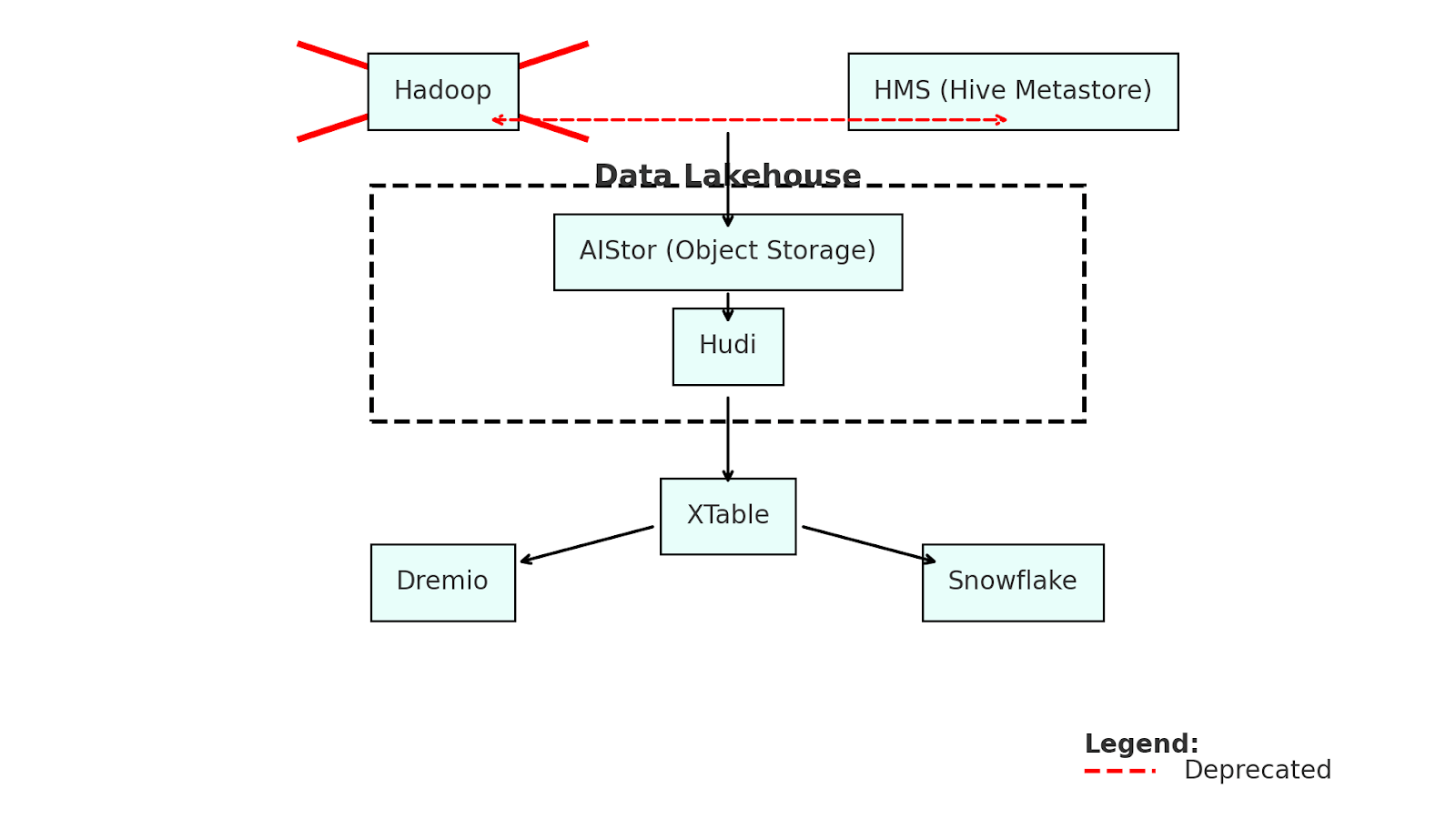
This could be a pathway to modernization for many still operating legacy systems. There are a great number of possibilities, but there are some limitations.
The Limitations
At this stage, XTable primarily supports Copy-on-Write (CoW) and Read-Optimized views of tables. This means that while the foundational Parquet files are synchronized, certain dynamic aspects aren't captured.
What's Not Synced?
- Hudi Log Files: For those utilizing Apache Hudi's Merge-on-Read (MoR) tables, the log files that store incremental data aren't currently synced by XTable. This omission can lead to incomplete data representation in scenarios where MoR is employed.
- Delta and Iceberg Delete Vectors: In formats like Delta Lake and Apache Iceberg, delete vectors play a crucial role in marking records for deletion without physically removing them. Presently, XTable doesn't capture these delete vectors, which might result in outdated or incorrect data being reflected post-sync.
Due to these limitations, any updates or deletions tracked by the aforementioned mechanisms in Hudi, Delta Lake, or Iceberg won't be reflected in the synchronized data. This could pose challenges for workflows that rely on the most current dataset state, especially in environments where data is frequently updated or deleted.
The Road Ahead
Despite the current write limitations, Apache XTable represents a significant step forward in the evolution of the modern data stack. It will be interesting to see what’s next for this exciting project. For now, organizations should strategically leverage XTable’s read capabilities while planning their write operations to fit within the constraints of their chosen formats.
Grow your career and get certified in data infrastructure in our training program. Drop us a line at hello@min.io or on our Slack channel.






