AI Data Workflows with Kafka and MinIO

AIStor is a foundational component for creating and executing complex data workflows. At the core of this event-driven functionality is MinIO bucket notifications using Kafka. AIStor produces event notifications for all HTTP requests like PUT, POST, COPY, DELETE, GET, HEAD and CompleteMultipartUpload. You can use these notifications to trigger appropriate applications, scripts and Lambda functions to take an action after object upload triggers an event notification.
Event notifications provide a loosely-coupled paradigm for multiple microservices to interact and collaborate. In this paradigm, microservices do not make direct calls to each other, but instead communicate using event notifications. Once a notification is sent, the sending service can return to its tasks, while the receiving service takes action. This level of isolation makes it easier to maintain code — changing one service does not require changing other services as they communicate through notifications, not direct calls.
There are several use cases which rely on AIStor event notification to execute data workflows. For example we can run AI/ML pipelines using the raw data for objects that will be stored in AIStor.
- The pipeline that processes the data will trigger whenever raw objects are added
- Based on that objects added, the models will run.
- The final model can be saved to a bucket in AIStor which could then be consumed by other applications as the final product.
Building a workflow
We’re going to build an example workflow using AIStor and Kafka for a hypothetical image resizer app. It essentially takes incoming images and resizes them according to certain app specifications, then saves them to another bucket where they can be served. This might be done in the real world to resize images and make them available to mobile apps, or simply to resize images to alleviate the strain on resources that occurs when resizing them on the fly.
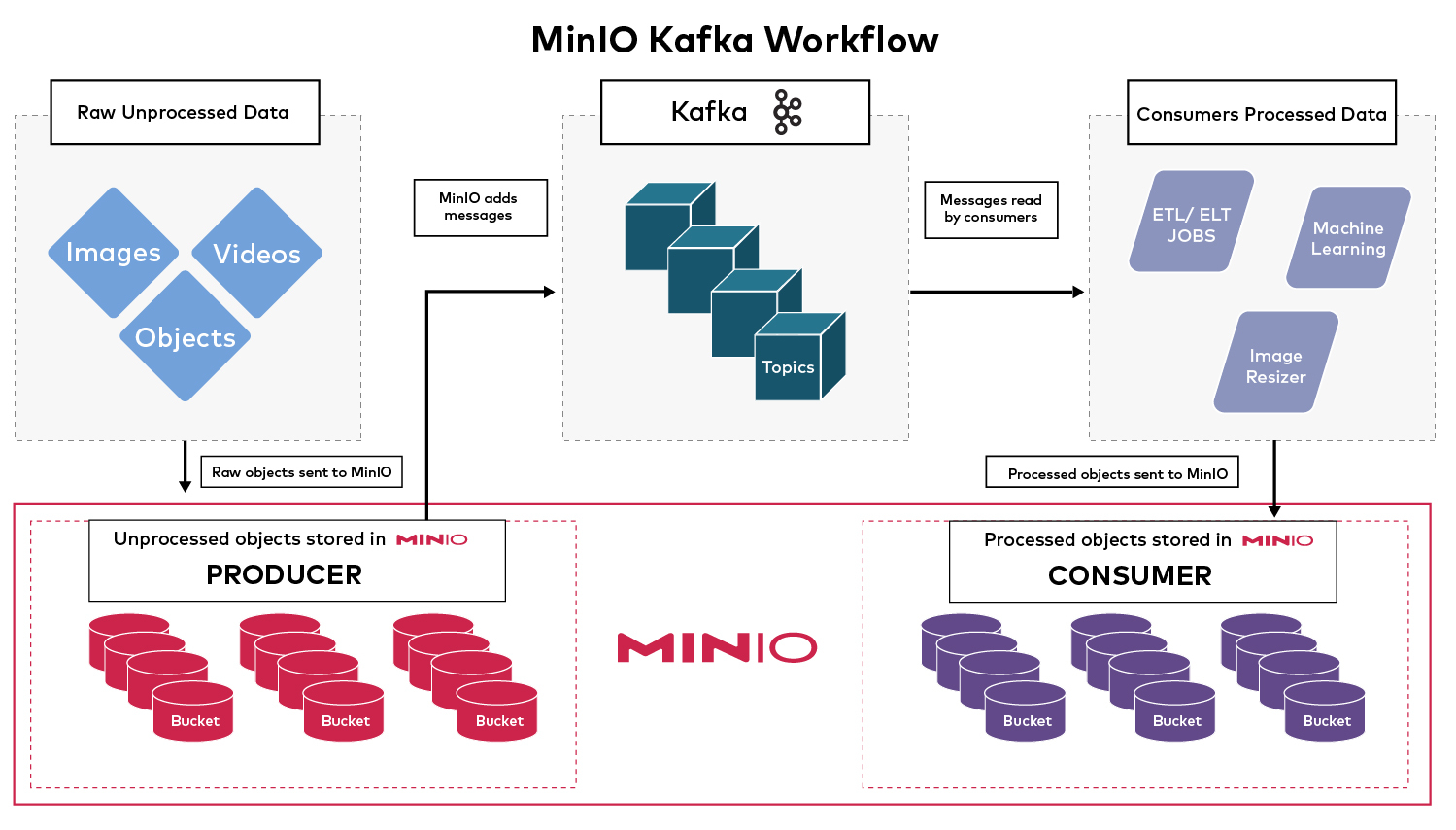
There are several components to it and Kafka and AIStor are used together to power this complex workflow
- AIStor, the producer: Raw objects that are coming in are stored in AIStor. Any time an object is added, it sends a message to Kafka to broker a specific topic.
- Kafka, the broker: The broker maintains the state of the queue, stores the incoming messages, and makes it available for consumers to consume.
- AIStor, the consumer: The consumer will read this message in the queue, as they come in in real time, process the raw data, and upload it to an AIStor bucket.
AIStor is the foundation of all of this as it is the producer and the consumer of this workflow.
Use a Kubernetes cluster
We need a Kubernetes cluster for our services to run on. You can use any Kubernetes cluster but in this example we’ll use a kind cluster. If Kind is not already installed, please follow this quickstart guide for instructions. Use the below kind cluster configuration to build a simple single master with a multi-worker Kubernetes cluster.
Save this yaml as kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
- role: workerLaunch the cluster (this may take several minutes)
Verify the cluster is up
Installing Kafka
Kafka requires a few services to be running to support it before it can be run. These services are:
- Certmanager
- Zookeeper
Let’s install cert-manager in our Kubernetes cluster
Check the status to verify cert-manager resources have been created
Install zookeeper using Helm charts. If you don’t have helm installed, you can follow the installation guide available in the helm docs.
You should see output similar to this, which means the cluster creation is in progress.
Verify that both the zookeeper operator and cluster pods are running
Now that we have all the prerequisites out of the way, let’s install the actual Kafka cluster components.
Kafka has an operator called Koperator which we’ll use to manage our Kafka install. It will take about 4-5 minutes for the Kafka cluster to come up.
Run kubectl -n kafka get po to confirm that Kafka has started. It takes a few minutes for Kafka to be operational. Please wait before proceeding.
Configuring Kafka topic
Let’s configure the topic before configuring it in MinIO; the topic is a prerequisite.
Create a topic called my-topic
It should return the following output. If it does not, the topic creation was not successful. If unsuccessful, wait for a few minutes for the Kafka cluster to come online and then rerun it again.
We need one of the Kafka pod’s IP and Port for the next few steps
To get the IP:
Note: The IP will be different for you and might not match above.
There are a few ports we’re interested in
Tcp-internal 29092: This is the port used when you act as a consumer wanting to process the incoming messages to the Kafka cluster.Tcp-controller 29093: This is the port used when a producer, such as MinIO, wants to send messages to the Kafka cluster.
These IPs and Ports might change in your own setup so please be sure to get the correct value for your cluster.
Install MinIO
We’ll install MinIO in its own namespace in the same Kubernetes cluster as our other resources.
Fetch the MinIO repo
Apply the resources to install MinIO
Verify MinIO is up and running. You can get the port of the MinIO console, in this case 9443.
Set up kubernetes port forwarding: we chose port 39443 here for the host but this could be anything, just be sure to use this same port when accessing the console through a web browser.
Access through the web browser using the following credentials
URL: https://localhost:39443
User: minio
Pass: minio123
Configure MinIO producer
We’ll configure MinIO to send events to my-topic in the Kafka cluster we created earlier using the mc admin tool.
I’m launching an Ubuntu pod here so I have a clean workspace to work off of and more importantly I’ll have access to all the pods in the cluster without having to port-forward each individual service.
Shell into the Ubuntu pod to make sure it’s up
If you see any command prefixed with root@ubuntu:/ that means it is being run from inside this ubuntu pod.
Fetch mc binary and install using the following commands
Verify it’s installed properly
Configure mc admin to use our MinIO cluster
mc alias set <alias_name> <minio_tenant_url> <minio_username> <minio_password>
In our case that would translate to
Verify the configuration is working as expected by running the command below; you should see something similar to 8 drives online, 0 drives offline
Set the Kafka configuration in MinIO through mc admin. You will need to customize the command below with
There are a few of these configurations you have to pay particular attention to
brokers="10.244.1.5:29093": These are the Kafka servers with the formatserver1:port1,server2:port2,serverN:portN. Note: If you decide to give more than one Kafka server, you need to give the IPs of all the servers; if you give a partial list it will fail. You can give a single server, but the downside is that if that server goes down then the config will not be aware of the other Kafka servers in the cluster. As we mentioned before there are two ports:TCP-internal 29092andTCP-controller 29093. Since we are configuring MinIO as the Producer, we’ll use29093.topic="my-topic": The topic name should match the topic we created earlier in the Kafka cluster. As a reminder, MinIO does not create this topic automatically; it has to be available beforehand.notify_kafka:1: This is the configuration name that will be used to actually add the events later.
Please visit our documentation for more details on these parameters.
Once it is successful you should see the output below
And as required let’s restart the admin service
Create a bucket in MinIO called images. This is where the raw objects will be stored.
We want to limit the messages being sent to the queue only to .jpg images; this could be expanded as needed, for example if you wanted to set the message to fire based on another file extension such as .png.
For more details on how to configure Kafka with MinIO, please visit our documentation.
Build MinIO consumer
It would be very cool if we actually had a script that could consume these events produced by MinIO and do some operation with those objects. So why not do that? This way we have a holistic view of the workflow.
While still logged into our ubuntu pod, install python3 and python3-pip for our script to run. Since this is Ubuntu minimal we also need vim to edit our script.
For our Python consumer script we need to install a few Python packages through pip
If you see the above messages then we have successfully installed the required dependencies for our script.
We’ll show the entire script here, then walk you through the different components that are in play. For now save this script as minio_consumer.py
- We’ll import the pip packages we installed earlier in the process
- Rather than modifying parameters within the code each time, we’ve surfaced some common configurable parameters in this config dict.
- The MinIO cluster we launched is using a self-signed cert. When trying to connect we’ll need to ensure it accepts self signed certificates.
- We’ll check to see if our destination bucket to store the processed data exists; if it does not then we’ll go ahead and create one.
- Configure the Kafka brokers to connect to along with the topic to subscribe to
- When you stop the consumer generally it spits out a stack trace because a consumer is meant to be running forever consuming messages. This will allow us to cleanly exit the consumer
As mentioned earlier, we’ll be continuously waiting, listening for new messages on the topic. Once we get a topic we break it down into three components
request_type: The type of HTTP request: GET, PUT, HEADbucket_name: Name of the bucket where the new object was addedobject_path: Full path to the object where it was added in the bucket
- Every time you make any request, MinIO will add a message to the topic which will be read by our
minio_consumer.pyscript. So to avoid an infinite loop, let's only process when new objects are added, which in this case is the request type PUT.
- This is where you would add your customer code to build your ML models, resize your images, and process your ETL/ELTs jobs.
- Once the object is processed, it will be uploaded to the destination bucket we configured earlier. If the bucket does not exist our script will auto-create it.
There you have it. Other than a few boilerplate code we are essentially doing two things:
- Listening for messages on a Kafka topic
- Putting the object in a MinIO bucket
The script is not perfect — you need to add some additional error handling, but it's pretty straightforward. The rest you can modify with your own code base. For more details please visit our MinIO Python SDK documentation.
Consume MinIO events
We’ve built it, now lets see it in action. Create two terminals:
- Terminal 1 (T1): Ubuntu pod running
minio_consumer.py - Terminal 2 (T2): Ubuntu pod with
mc.
Open T1 and run the minio_consumer.py script we wrote earlier using python3. If at any time you want to quit the script you can type Ctrl+C
Now let’s open T2 and PUT some objects into the MinIO images bucket we created earlier using mc.
Start by creating a test object
Upload the test object to the images bucket to a few different paths
In our other terminal T1 where the MinIO consumer script is running, you should see a few messages similar to below
We should verify the processed object has been uploaded to the processed bucket also
As you can see we’ve successfully uploaded the object to a processed bucket from unprocessed raw data.
Build workflows on AIStor with notifications
What we showed here is just a sample of what you can achieve with this workflow. By leveraging Kafka’s durable messaging and AIStor's resilient storage, you can build complex AI applications that are backed by an infrastructure that can scale and keep up with workloads such as:
- Machine learning models
- Image resizing
- Processing ETL / ELT jobs
Don’t take our word for it though — build it yourself. You can download AIStor here and you can join our Slack channel here.






