Dremio and MinIO on Kubernetes for Fast Scalable Analytics

Cloud native object stores such as MinIO are frequently used to build data lakes that house large structured, semi-structured and unstructured data in a central repository. Data lakes usually contain raw data obtained from multiple sources, including streaming and ETL. Organizations analyze this data to spot trends and measure the health of the business.
What is Dremio?
Dremio is an open-source, distributed analytics engine that provides a simple, self-service interface for data exploration, transformation, and collaboration. Dremio's architecture is built on top of Apache Arrow, a high-performance columnar memory format, and leverages the Parquet file format for efficient storage. For more on Dremio, please see Getting Started with Dremio.
MinIO for Cloud-Native Data Lakes
MinIO is a high-performance, distributed object storage system designed for cloud-native applications. The combination of scalability and high-performance puts every workload, no matter how demanding, within reach. MinIO has created a comprehensive blueprint for data infrastructure to support exascale AI and other large scale data lake workloads. It is called the MinIO DataPod. Why? Because exascale data is the reality that is common today in today's enterprise.
MinIO is built to power data lakes and the analytics and AI that runs on top of them. MinIO includes a number of optimizations for working with large datasets consisting of many small files, a common occurrence with any of today’s open table formats.
Perhaps more importantly for data lakes, MinIO guarantees durability and immutability. In addition, MinIO encrypts data in transit and on drives, and regulates access to data using IAM and policy based access controls (PBAC).
Set up Dremio OSS in Kubernetes
We can use Helm charts to deploy Dremio in a Kubernetes cluster. In this scenario, we will use the Dremio OSS (Open Source Software) image to deploy one Master, three Executors and three Zookeepers. The Master node coordinates the cluster and the Executors processing data. By deploying multiple Executors, we can parallelize data processing and improve cluster performance.
We’ll use a MinIO bucket to store the data. New files uploaded to Dremio are stored in the MinIO bucket. This enables us to store and process large amounts of data in a scalable and distributed manner.
Prerequisites
To follow these instructions, you will need
- A Kubernetes cluster. You can use Minikube or Kind to set up a local Kubernetes cluster.
- Helm, the package manager for Kubernetes. You can follow this guide to install Helm on your machine.
- A MinIO server running on bare metal or kubernetes, or you can use our Play server for testing purposes.
- A MinIO client (mc) to access the MinIO server. You can follow this guide to install mc on your machine.
Clone minio/openlake repo
MinIO engineers put together the openlake repository to give you the tools to build open source data lakes. The overall goal of this repository is to guide you through the steps needed to build a data lake using open source tools like Apache Spark, Apache Kafka, Trino, Apache Iceberg, Apache Airflow, and other tools deployed on Kubernetes with MinIO as the object store.
!git clone https://github.com/minio/openlakeCreate MinIO bucket
Let's create a MinIO bucket openlake/dremio which will be used by Dremio as the distributed storage
Clone dremio-cloud-tools repo
We will use the helm charts from the Dremio repo to set it up
We will use the dremio_v2 version of the charts, and we will use the values.minio.yaml file in the Dremio directory of the openlake repository to set up Dremio. Let’s copy the YAML to dremio-cloud-tools/charts/dremio_v2 and then confirm that it has been copied
Deployment Details
If we take a deep dive into the values.minio.yaml file (feel free to cat or open the file in your editor of choice), we’ll gain a greater understanding of our deployment and learn about some of the modifications made to the distStorage section
We set the distStorage to aws, the name of the bucket is openlake and all the storage for Dremio will be under the prefix dremio (aka s3://openlake/dremio). We also need to add extraProperties since we are specifying the MinIO Endpoint. We also need to add two additional properties in order to make Dremio work with MinIO, fs.s3a.path.style.access needs to be set to true and dremio.s3.compat must be set to true so that Dremio knows this is an S3 compatible object store.
Apart from this we can customize multiple other configurations like executor CPU and Memory usage depending on the Kubernetes cluster capacity. We can also specify how many executors we need depending on the size of the workloads Dremio is going to handle.
Install Dremio using Helm
Make sure to update your Minio endpoint, access key and secret key in values.minio.yaml. The commands below will install the Dremio release named dremio in the newly created namespace dremio.
Give Helm a few minutes to work its magic, then verify that Dremio was installed and is running
Log in to Dremio
To log in to Dremio, let’s open a port-forward for the dremio-client service to our localhost. After executing the below command, point your browser at http://localhost:9047. For security purposes, please remember to close the port-forward after you are finished exploring Dremio.
You will need to create a new user when you first launch Dremio
Once we have created the user, we will be greeted with a welcome page. To keep this workflow simple, let's upload a sample dataset to Dremio that is included in the openlake repo data/nyc_taxi_small.csv and start querying it.
We can upload openlake/dremio/data/nyc_taxi_small.csv by clicking on the + at the top right corner of the home page, as shown below
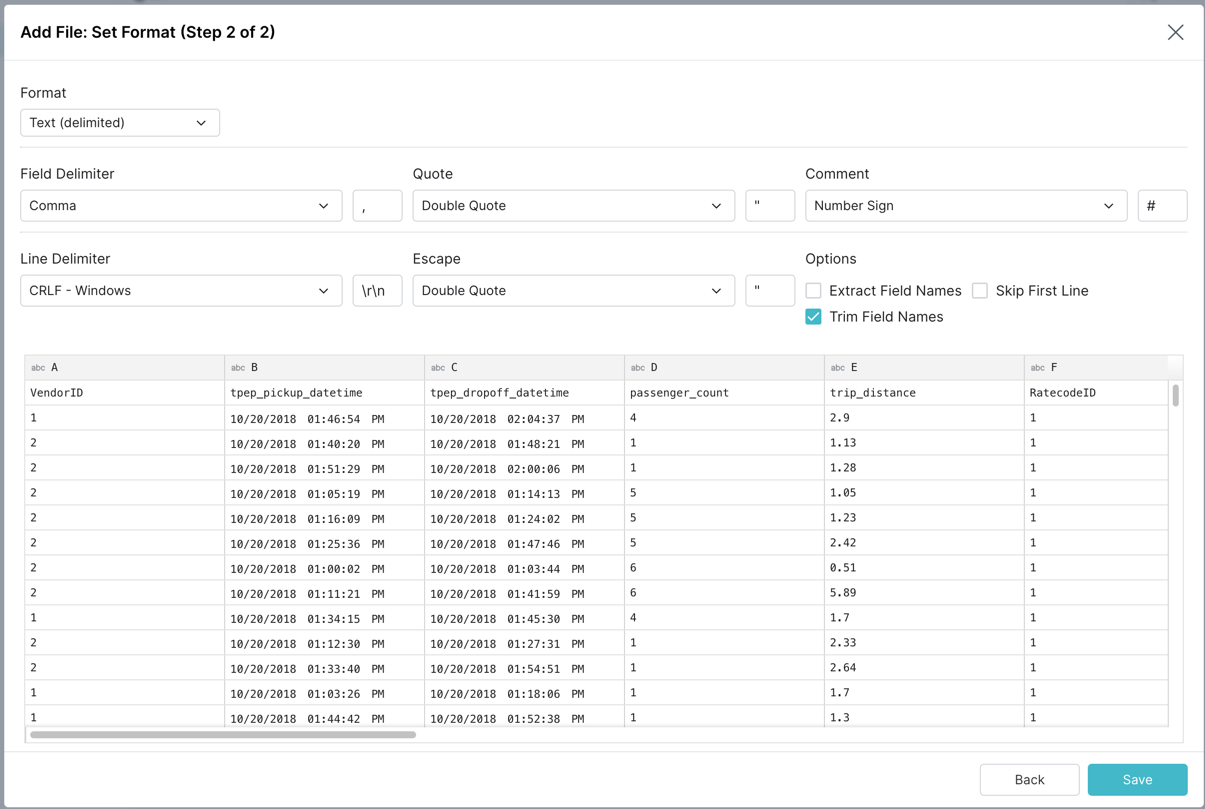
Dremio will automatically parse the CSV and provide the recommended formatting as shown below, click Save to proceed.
To verify that the CSV file was uploaded to the MinIO bucket
After loading the file, we will be taken to the SQL Query Console where we can start executing queries. Here are 2 sample queries that you can try executing
SELECT count(*) FROM nyc_taxi_small;
SELECT * FROM nyc_taxi_small;Paste the above in the console and click Run, then you see something like below
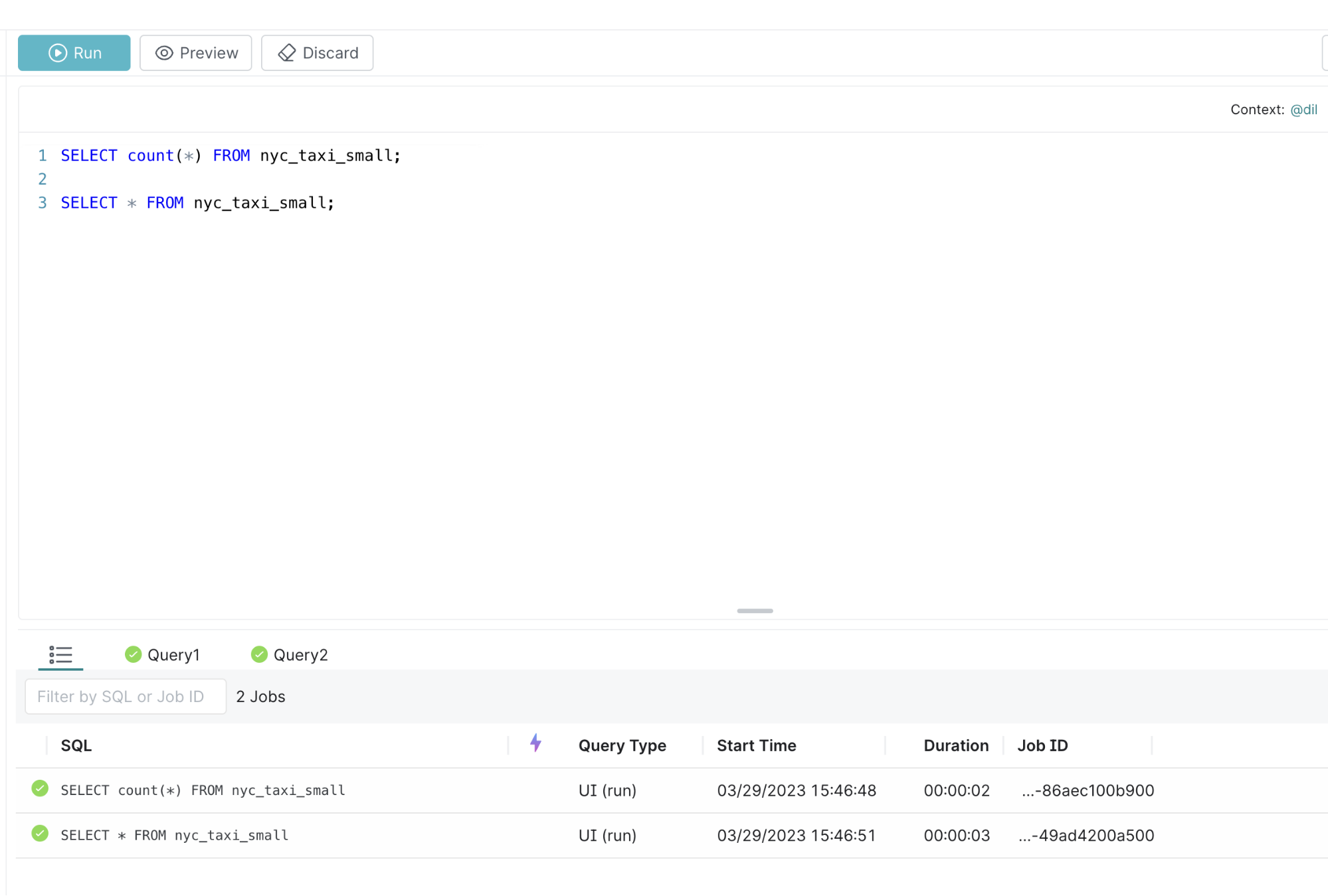
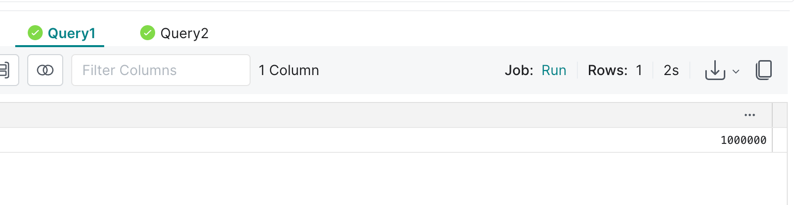
You can click on the Query1 tab to see the number of rows in the dataset
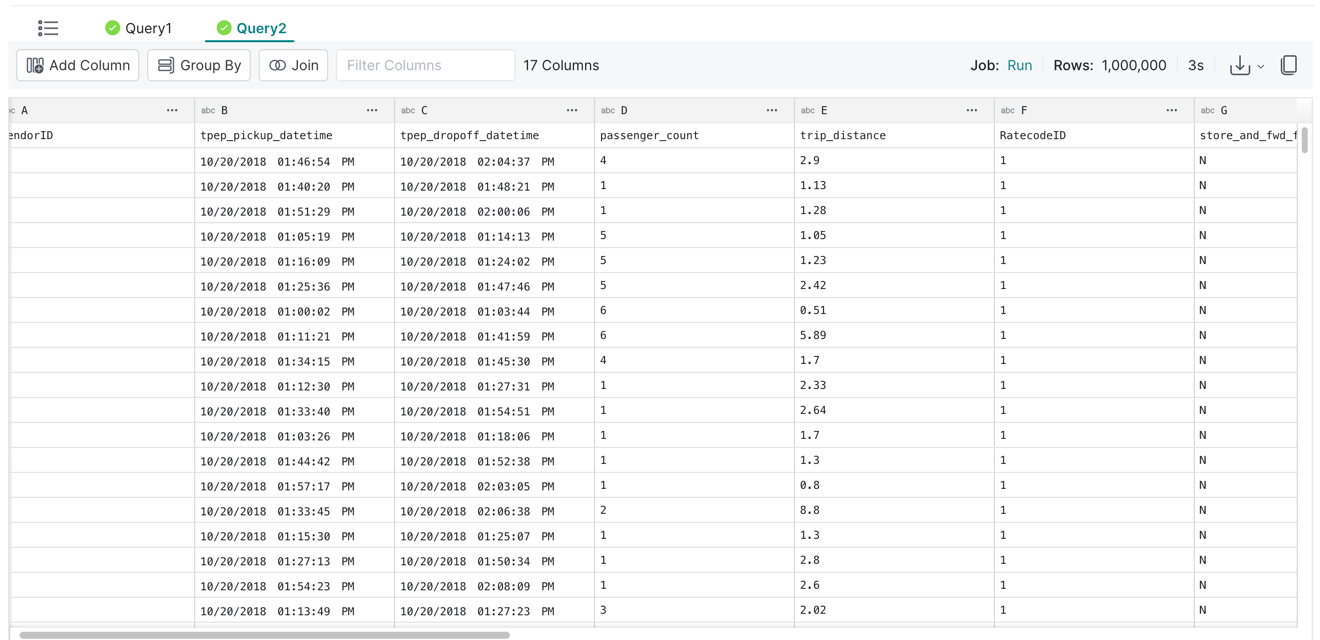
You can click on the Query2 tab to see the number of rows in the dataset
Data Lakes and Dremio
This blog post walked you through deploying Dremio in a Kubernetes cluster and using MinIO as the distributed storage. We also saw how to upload a sample dataset to Dremio and start querying it. We have just touched the tip of the iceberg 😜in this post to help you get started building your data lake.
Speaking of icebergs, Apache Iceberg is an open table format that was built for object storage. Many a data lake has been built using the combination of Dremio, Spark, Iceberg, and MinIO. To learn more, please see The Definitive Guide to Lakehouse Architecture with Iceberg and MinIO.
Try Dremio on MinIO today. If you have any questions or want to share tips, please reach out through our Slack channel or drop us a note on hello@min.io.






