Enhance Large Language Models Leveraging RAG and MinIO on cnvrg.io

This post was written in collaboration with Harinder Mashiana from cnvrg.io.
Large language models (LLMs) have revolutionized the world of technology, offering powerful capabilities for text analysis, language translation, and chatbot interactions. The revolution will heavily impact businesses, according to OpenAI, approximately 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of GPTs. While the promise and value of LLMs are apparent, they also have limitations that should be considered and addressed to improve their performance and efficiency. In this blog post, we will explore some of the shortcomings of LLMs and how you can overcome them by leveraging RAG (Retrieval Augmented Generation) and MinIO running on cnvrg.io. The demo presented here will show how to fine-tune an LLM for a specific use case.
Before we dive into the challenges, here is a brief overview of the tools we’re leveraging in this solution to build more effective LLMs.
The Challenges of Leveraging Large Language Models
The Large Language Models as standalone solutions have several shortcomings that can be mitigated. To name a few:
- Out of date responses - LLMs are bound to the data they were trained on and may produce outdated responses if not updated and retrained frequently.
- Lack of industry specific knowledge - Generic LLMs do not have domain specific knowledge needed to provide contextually specific responses.
- High training costs for frequent knowledge updates - The large-scale nature of LLMs results in costly and resource-intensive training requirements for frequent knowledge updates.
- Hallucinations - Even when fine-tuned, LLMs can "hallucinate" or generate factually incorrect responses not aligned with the provided data.
The Advantages of RAG to Enhance LLM Performance
Retrieval Augmented Generation (RAG) is a powerful tool to improve the strengths and efficiencies of Large Language Models.
How does RAG work?
Imagine you ask ChatGPT a question about something that happened today. It will not be able to answer that question because it was trained on data prior to 2021. RAG helps you overcome this. Retrieval augmented generation (RAG) is a technique that combines two key approaches in natural language processing: retrieval-based models and generation-based models. For example, imagine RAG has access to a database that contains the latest news articles. Now when your customer asks a question, RAG will access the top 5 most relevant documents based on the question and send them to your LLM in order to answer the question more accurately.
Using RAG, you can use smaller language models since up to date and contextually relevant information is sent with each request. RAG solves the challenges listed above that every organization will face when implementing LLMs.
- Up-to-date responses and improved precision and recall - RAG pipelines enhance precision and recall by incorporating retrieval mechanisms into LLMs, reducing the odds of inaccurate or irrelevant responses. This helps decrease inaccuracies and capture a wider scope of information, leading to an improvement in recall.
- Contextual understanding and industry specific knowledge - RAG pipelines enhance LLMs’ contextual understanding and industry-specific knowledge by integrating systems that can access external knowledge bases or the web allowing the models to retrieve relevant information beyond their training data.
- Efficient Computation and Reduced Latency - RAG pipelines reduce the high computational costs of LLMs and lower latency with smaller, more efficient models while delivering higher quality responses with significantly less computational overhead.
- Mitigating bias and improving fairness to address Hallucinations - Retrieval mechanisms enable more diverse information retrieval, offering multiple perspectives. Moreover, the explicit control over information sources provided by these systems allows for a curated, diverse document set, reducing the influence of biased sources.
How to apply RAG to enhance LLMs with MinIO on cnvrg.io
To demonstrate the capabilities of RAG and MinIO, we have built an end-to-end solution on cnvrg.io. This solution leverages RAG as an endpoint on cnvrg.io, allowing users to ask questions using API requests, cnvrg.io as the orchestration platform, and MinIO as the storage solution.
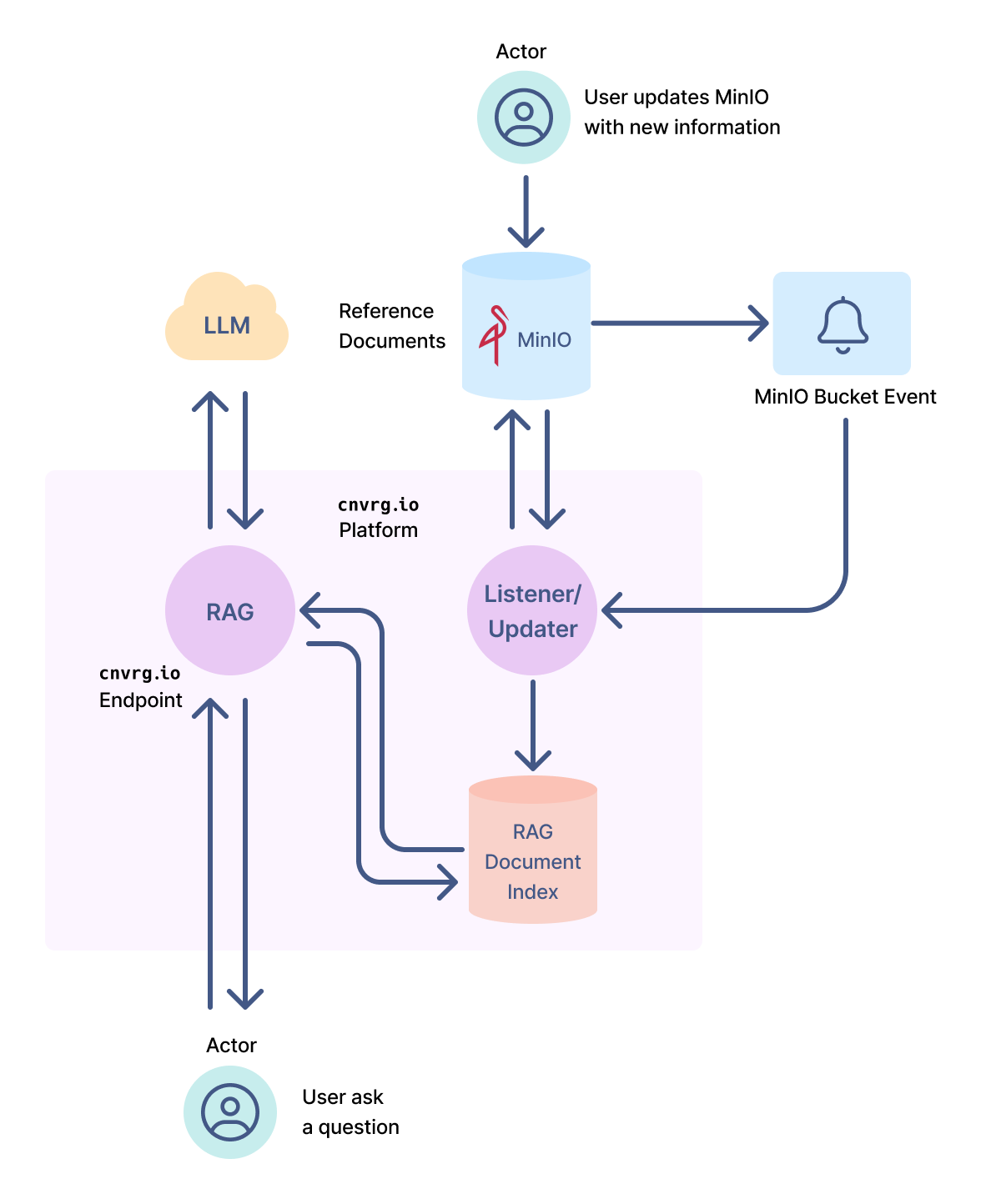
Figure 1
Building an Optimized LLM Pipeline
Using cnvrg.io you can build your own Retrieval Pipeline and to aid content generation with any generative model. Using cnvrg.io, MinIO, and RAG you can optimize your LLM and have the following advantages for your solution:
- Improved cost with reduced model size
- Contextual responses customized for your solution
In the solution shown in Figure 1, RAG is deployed as an endpoint on cnvrg.io, where users can submit a question via the API. The sequence of events for generating a response is summarized below:

Figure 2
Using MinIO, users can easily update documents utilized by RAG. Upload the new documents to the designated MinIO bucket, an event will be raised, which is picked up by the Listener/Updater, which will download the new documents from your bucket and update the RAG document index. The next time a question is submitted to the RAG endpoint, it will have access to the new documents and provide them to the LLM for generating improved responses.

Figure 3
Let’s see an example of how this might look from a user perspective. In this example, we are leveraging fastRAG an open source library for building performant RAG pipelines optimized for Intel CPUs.
Imagine there is a new disease that is spreading and you have updated your database with the information regarding this new disease called X.
Question: I have a sore throat and diarrhea. What could be the cause?
Answer without RAG: Sore throat and diarrhea could be caused by a number of different things, including a virus, bacteria, or even a food allergy. It is best to see your doctor for a proper diagnosis and treatment.
Answer with RAG: The cause of your symptoms could be due to a combination of factors, including a virus, bacteria, or food allergy, but it also sounds like you could have symptoms for disease X, a newly spreading disease. It is recommended that you get tested for disease X, and remain isolated from others until you have tested negatively. Additionally, it is important to rest and take care of yourself while you recover from the cold, sore throat, and diarrhea and to drink a lot of water. Please also see your doctor to get a proper diagnosis and treatment.
As you can see, the LLM without RAG did not have new data and produced an answer which did not contain information about the new disease. While the LLM with RAG had access to new and relevant data and produced an answer that contained information about the latest disease.
Document Storage with MinIO
When a customer uploads documents for fine-tuning the LLM, these documents are securely stored in MinIO. Additionally, the RAG solution took advantage of MinIO’s Bucket Events. When documents arrive in MinIO, an event is raised, resulting in a webhook being called. (The Listener/Updater in Figure 1.) The Listener/Updater processes the new document and updates the customer's document index database. Future versions of this solution may take advantage of MinIO’s Object Lambda feature. MinIO's Object Lambda enables application developers to process data retrieved from MinIO before returning it to an application. This is useful if you need to remove sensitive information or if you would like to log retrieval activity.
Intel Optimization for Inference
RAG algorithms and models can be deployed using CPU directly without needing expensive GPU for Retrieval pipelines. Large language models like GPT-3 are computationally expensive to run, especially for long and complex queries or documents. Retrieval models can act as an initial filter to narrow down the search space and reduce the number of queries that need to be processed by the generative model. By retrieving relevant documents or passages, we can significantly reduce the computational cost of generating responses for every input. Furthermore, depending upon the large language model being used, it is entirely possible to use CPU for deploying LLMs as we did for generating the example shared above.
Summary
Retrieval-augmented pipelines represent a significant advancement in the field of NLP, harnessing the strengths of large language models and efficient retrieval mechanisms. These pipelines offer advantages such as enhanced precision and recall, knowledge expansion, bias mitigation, computational efficiency, and improved generalization. By combining the power of large language models with information retrieval techniques, retrieval-augmented pipelines pave the way for more accurate, contextually rich, and efficient NLP systems. As research and development in this area continue to progress, we can expect retrieval-augmented pipelines to play a vital role in shaping the future of natural language processing.






