Integrating MinIO with Hugging Face Datasets

Hugging Face's DatasetDict class is a part of the Datasets library and is designed to make working with datasets destined for any model found on the Hugging Face Hub efficient. As the name implies, the DatasetDict class is a dictionary of datasets. The best way to understand objects created from this class is to look at a quick code demo. The code below will load the emotions dataset from the Hugging Face Hub into a DatasetDict object. I featured this dataset in my previous two posts on fine-tuning and feature extraction.
The output:
<class 'datasets.dataset_dict.DatasetDict'>
<class 'datasets.arrow_dataset.Dataset'>
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 16000 })
validation: Dataset({
features: ['text', 'label'],
num_rows: 2000 })
test: Dataset({
features: ['text', 'label'],
num_rows: 2000 }) })Passing a single string parameter to the load_dataset function assumes you want a dataset from the Hugging Face Hub. It knows how to phone home. No connection information needed.
By looking at the output, we can see right off the bat that this object is holding our training, validation, and test sets. There is also some metadata - like each set's features and number of rows. Another trick I like to employ when learning a new library is printing out the types of new objects. I did this in the first two lines of the output. The top level object is a DatasetDict and each split is a Dataset object.
While this looks nice, one may wonder - “Is this overengineering?” After all, the Pandas DataFrame and Numpy arrays have become the de facto standard for working with ML data. Another question that may pop into your head is, “How do I get my data - which cannot exist in Hugging Face’s Hub, into a DatasetDict object?
In this post, I will address each of these questions. I’ll start by looking at the features and benefits of the DatasetDict object. Then, I’ll show several techniques for loading data from MinIO into a DatasetDict object. Specifically, the data flow I want to enable for everyone who has data that they wish to send to a transformer - whether it is for training or inference is shown below. This flow starts with MinIO. Next, the data is loaded into a DatasetDict object, and from there, it can be used by any transformer in Hugging Face’s Hub - assuming you have the correct data and model for the task at hand.

Features and Benefits of Dataset Dictionaries
The first thing to understand is that the Pandas DataFrame and Numpy arrays predate transformers (Large Language Models used for generative AI). So, while they are beneficial for standard data manipulation, there are a few things that a DatasetDict object does better since the DatasetDict was built with Large Language Models in mind. The first is tokenizing text. Consider the code below, an excerpt from my fine-tuning and feature extraction posts.
The output:
With just a few lines of code, I am getting the tokenizer that is packaged with each transformer in the Hugging Face Hub, and I am using the DatasetDict’s map function to apply it to the training set, validation set and test set.
Another advantage is that the DatasetDict object is framework agnostic. Looking closely at the tokenizer function, you will see the return_tensor parameter set to “pt”, which indicates that the returned tensors should be Pytorch tensors.
A final advantage, which I will demonstrate later in this post, is lazy loading. When training a Large Language Model, you will have a training set that cannot fit into memory. The DatasetDict object has features that allow large training sets to be cached locally so that only samples needed for the current training batch are loaded.
A detailed investigation would yield more valuable tools for transformers that save coding time. However, in this section, I have highlighted the three most significant advantages: mapping, framework agnosticism, and lazy loading.
The following sections will present three ways an organization can load custom data that cannot exist in the cloud into a DatasetDict object.
Use the MinIO SDK
If you already have a module with reusable functions built with the MinIO SDK, chances are you have a get_object function that will download an object to a file. If you do not have a utility module with reusable functions for accessing ML data in MinIO, download the code samples for this post. There is a utils.py module with several utilities for getting and sending data to MinIO.
Let’s assume you have three objects that contain product review information in a MinIO bucket for training, validation, and testing - as shown in the screenshot below.
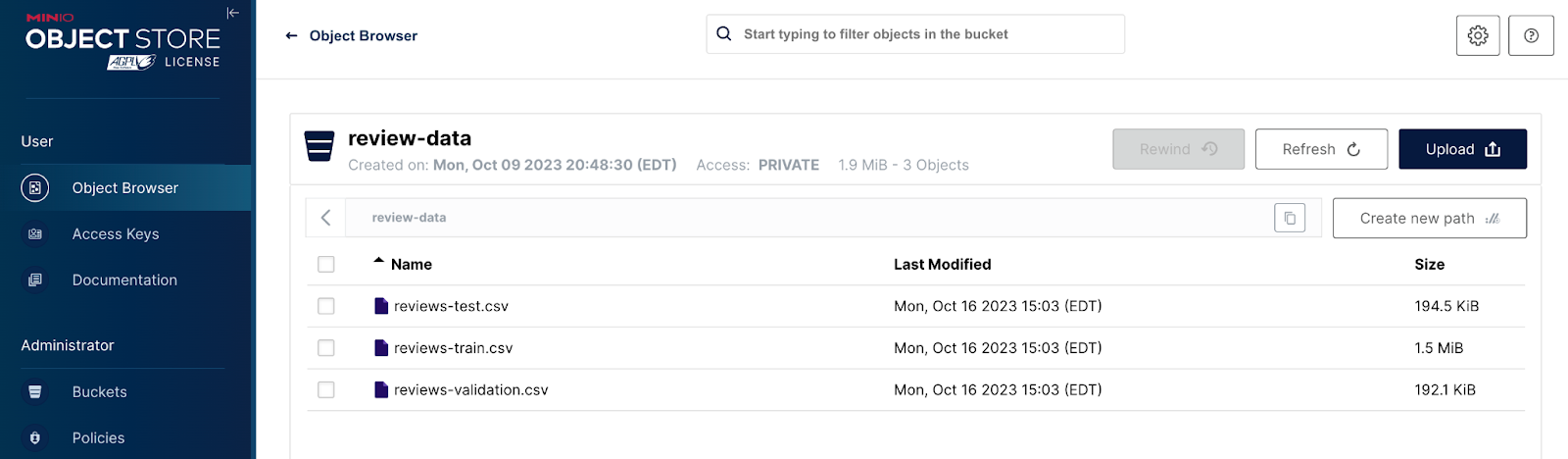
The code below shows how to use a get_object function to download and load these objects into a DatasetDict object.
The output is below. Notice that row counts and column names are present just as if this dataset had been downloaded from the Hub.
<class 'datasets.dataset_dict.DatasetDict'>
<class 'datasets.arrow_dataset.Dataset'>
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 16000 })
validation: Dataset({
features: ['text', 'label'],
num_rows: 2000 })
test: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
})The load_dataset() function parameters are much different than what we saw when downloading from the Hub. Here, we must first specify the format of our files. It is CSV in our demo, but JSON and Parquet are also supported. You also need to send a dictionary that identifies the split (training, validation, or test) and for each split, a file pointer must be specified.
Use an S3 Interface
It is fine if you do not want to use the MinIO SDK but would rather standardize on an S3 interface. The code below will use the standard s3fs library, which can interact with any S3 object store.
The output is the same as the previous technique using the MinIO SDK, so it is omitted for brevity. Also, the use of the load_dataset() function is the same.
Use a Python Generator for Large Datasets
If you are tinkering with LLMs and are either fine-tuning an existing LLM on a custom corpus of documents or training from scratch, you will be dealing with a training set that cannot fit into memory. For example, consider the following MinIO bucket, where each object is a paragraph from Niccolò Machiavelli’s “The Prince.”
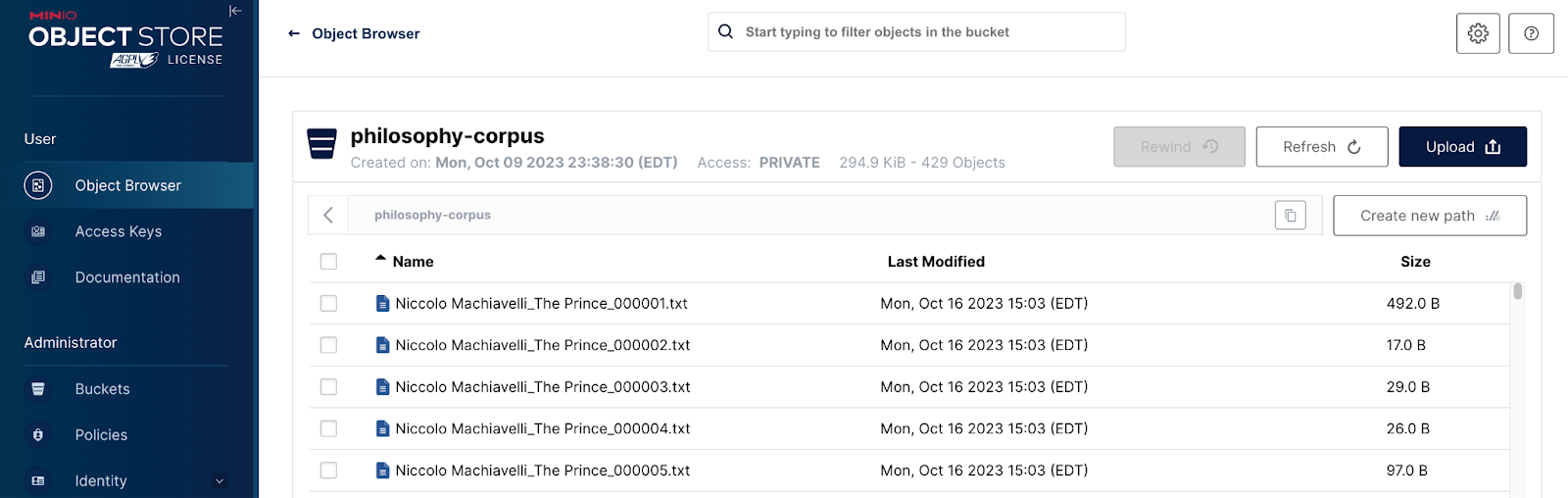
Let’s say you want to create an LLM capable of answering deep philosophical questions. We need a technique that works around memory limitations to train an LLM using this data. The from_generator() method is the most memory-efficient way to create a dataset from a Python generator. (You can brush up on Python generators here.) The dataset is generated on disk progressively and then memory-mapped. The code below shows how to do this. In the code below, the get_object_list() and the get_text() functions are part of the util.py module, which can be found in the code sample for this post.
The output:
The from_generator() function takes a function, which is a Python generator, and a directory for caching the data that will eventually be memory mapped. The gen_kwargs parameter is a dictionary of values to be passed to your generator - in this case, it is our MinIO bucket name.
Note from the output that this technique populates a Dataset object, not a DatasetDict object. If you need a DatasetDict object, then you can do the following.
The output:
What’s Missing?
For datasets that can fit into memory, it would be more efficient to stream right from MinIO into a DatasetDict object without copying data to a temporary file. In the samples above, when using the MinIO SDK and the S3 library, the data was saved to a temporary file, and then the DatasetDict object was sent file paths to the appropriate files.
It turns out that the Hugging Face folks have this in their backlog. You can read more here in my discussion with them on this request.
Summary
In this post, I highlighted the features and benefits of Hugging Face’s Datasets library, which contains the DatasetDict class that is needed for interfacing with the transformers found in the Hugging Face Hub. These benefits are Mapping (for tokenization), support for all the major frameworks, and lazy loading for large datasets that cannot fit into memory.
From there, I showed three ways to get enterprise data - or data that cannot reside in the cloud - from MinIO into a DatasetDict object. Currently, the three techniques that can be used are the MinIO SDK, an S3 interface, and lazy loading for large datasets.
Finally, I discussed a future feature I hope to see implemented in the Dataset library, which would allow the DatasetDict object to be loaded by a stream - no intermediary file needed.
If you have questions then drop us a line at hello@min.io or join the discussion on our general Slack channel.






