IoT data storage and analysis with Fluentd, MinIO and Apache Spark
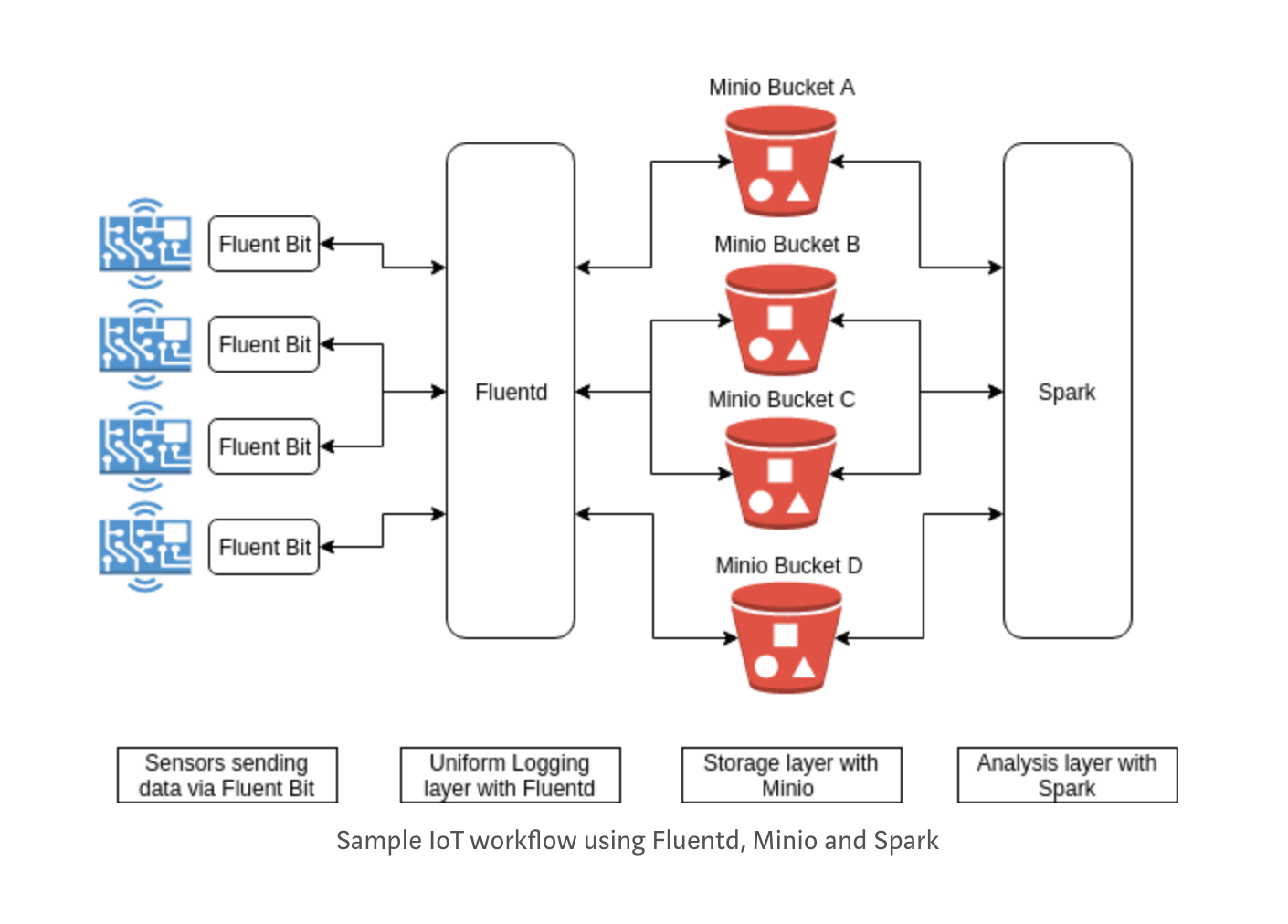
One of the major requirements for success with IoT strategy is the ability to store and analyze device and sensor data. As IoT brings thousands of devices online everyday, the data being generated by all these devices combined is reaching staggering levels.
Storing the IoT data in a scalable yet cost effective manner, while being able to analyze it easily is a major challenge.
In this post, we’ll see a set of enterprise grade open source products that will help set up a robust, cost efficient, IoT data storage and analysis pipeline. The products we’ll use in the set up are
- Fluent Bit: Data forwarder for Linux, OSX and BSD family operating systems.
- Fluentd: Unified data collection and consumption layer.
- MinIO: Scalable, cloud native storage backend.
- Spark: General purpose analysis engine for large scale data processing.
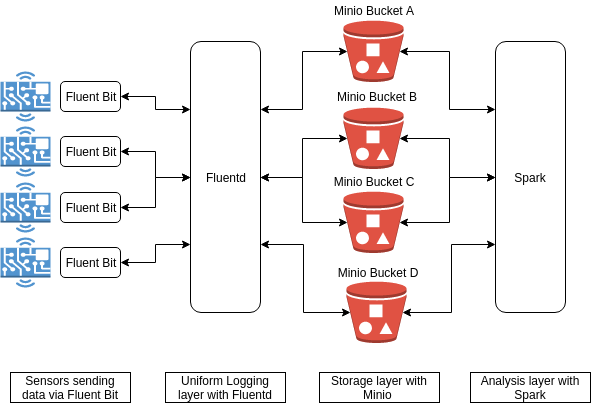
Let’s now go through individual steps and see how such a setup will operate.
Fluent Bit: last mile data collection
IoT data sources are as varied as they can get. In a typical setup, there can be several types of sensors, operating systems, databases, and others— with each sending data in its own format.
Fluent Bit simplifies collecting data from all these endpoints with its pluggable design. Each input and output route in Fluent Bit is a plugin, letting you ingest data from variety of sources and send it to various targets.
To get an idea of how the Fluent Bit works, let's see how to setup Fluent Bit to fetch CPU usage data and send it to a Fluentd instance.
To begin with, install Fluent Bit using the docs available here. To ingest data, we’ll use the cpu input plugin, and to send it to Fluentd, we’ll use the forward output plugin. Both of the plugins are available by default, so just run$ fluent-bit -i cpu -t fluent_bit -o forward://127.0.0.1:24224
This will send the cpu data to Fluentd instance listening on 127.0.0.1:24224
Fluentd: unified data collection layer
Given the size of logs being generated on a daily basis by a typical IoT deployment, it’s almost impossible to be analyzed by humans. Modern application logs are better consumed by machines instead of humans.
Fluentd serves as a unified logging layer, it can get data from variety of endpoints and lets you route it to long term storage or processing engines. In this post, we’ll take the log data storage route.
MinIO: storage for IoT data
With the data collection and unification taken care of, let’s see how to store the IoT logging data for long term analysis and consumption.
Key requirements while choosing storage for such large data streams are how well the storage scales, what is the cost effectiveness, and since there is a lot of data transfer involved, what is the bandwidth usage cost.
With inbuilt erasure-code and bitrot protection, storage hardware agnostic, easy deployment and multi-tenant scalability, MinIO checks all the above boxes, while being cost efficient and performant.
Before we move further, that lets see how to ingest data forwarded by Fluent Bit in Fluentd and forward it to a MinIO server instance. We’ll use the in_forward plugin to get the data, and fluent-plugin-s3 to send it to MinIO.
First, install Fluentd using the one of methods mentioned here. Then edit the Fluentd config file to add the forward plugin configuration (For source installs Fluentd config resides at ./fluent/fluent.conf by default). Add the following section<source>
type forward
bind 0.0.0.0
port 24224
</source>
This sets up Fluentd to listen on port 24224 for forward protocol connections. If you have Fluent Bit set up as explained in previous step, you should see the cpu data on the Fluentd console.
Next, set up Fluentd to send the logging data to MinIO bucket. Follow these steps to deploy MinIO server, and create a bucket using mc mb command.
Then install the fluent-plugin-s3 gem by$ fluent-gem install fluent-plugin-s3
Append the below section to the Fluentd config file to configure out_s3plugin to send data to a MinIO server.<match>
@type s3
aws_key_id minio
aws_sec_key minio123
s3_bucket test
s3_endpoint http://127.0.0.1:9000
path logs/
force_path_style true
buffer_path /var/log/td-agent/s3
time_slice_format %Y%m%d%H%M
time_slice_wait 10m
utc
buffer_chunk_limit 256m
</match>
Note that you’ll need to replace the aws_key_id , aws_sec_key , s3_bucketand s3_endpoint fields with actual values in your MinIO deployment.
Spark: IoT data processing
In order for data from connected devices to be useful, it is important to process and analyze it. Spark fits in very nicely here. It excels at handling huge volumes at speed, making it a natural choice for IoT data analytics.
As MinIO API is strictly S3 compatible, it works out of the box with other S3 compatible tools, making it easy to set up Apache Spark to analyze data from MinIO.
In our example above, we already have IoT data sent from endpoints (by Fluent bit) to a unified logging layer (Fluentd), which then stores it persistently in MinIO data store. Next step is to setup Spark to analyze the stored data. You can follow these steps to configure Spark to use MinIO server as the data source.
Spark is a general processing engine and opens up a wide range of data processing capabilities — whether you need predictive analysis of IoT data to find expected failure of certain hardware or analyze unstructured data to build models to understand certain patterns.
We saw how to create a typical IoT data collection, streaming, storage and processing pipeline with Fluentd, MinIO and Spark. Not only such a setup scales pretty well, it is also generic and can accommodate various types of IoT workflows.
While you’re at it, help us understand your use case and how we can help you better! Fill out our best of MinIO deployment form (takes less than a minute), and get a chance to be featured on the MinIO website and showcase your MinIO private cloud design to MinIO community.






