Machine Learning (ML) initiatives can push compute and storage infrastructures to their limits. Many DataOps teams rely on a Kubernetes-based hybrid cloud architecture to satisfy compute and object storage requirements for scalability, efficiency, reliability, multi-tenancy, and support for RESTful APIs. DataOps teams have standardized on tools that rely on high-performance S3 API-compatible object storage for their pipelines, training and inference needs.
Kubeflow is the standard machine learning toolkit for Kubernetes and it requires S3 API compatibility. Kubeflow is widely used throughout the data science community, but the requirement for S3 API compatible object storage limits deployment options. How would you run Kubeflow on Azure or GCP when they lack S3 API support for their object storage offerings?
In this post we are going to set up a Kubeflow cluster using Azure Kubernetes Service (AKS) using MinIO as the underlying storage for the whole setup and to test it End to End we are going to deploy a pipeline that access its data on MinIO and stores the resulting model there as well. The problem we are going to use is the traditional MNIST challenge, which consists of an Optical Character Recognition (OCR) problem.
Setting up the Kubernetes Cluster
Let's start by setting up the AKS cluster called KubeFlowMinIO with four nodes within a resource group called MinIOKubeFlow.
az group create -n $RESOURCE_GROUP_NAME -l $LOCATION
export NAME=KubeFlowMinIO
export AGENT_SIZE=Standard_D4s_v3
export AGENT_COUNT=4
az aks create -g $RESOURCE_GROUP_NAME -n $NAME -s $AGENT_SIZE -c $AGENT_COUNT -l $LOCATION --generate-ssh-keys
This process will take a few minutes, and after that you'll have a working Kubernetes cluster ready to go. You just need to configure your local kubectl with the access for this cluster.
az aks get-credentials -n $NAME -g $RESOURCE_GROUP_NAME
Setting up MinIO
The next step is to set up the MinIO Operator to manage our Object Storage on Azure. We've simplified the management of MinIO on Kubernetes plenty, so there are multiple ways to install the MinIO operator and you can choose the one that best matches your workflow. For this post we'll use MinIO's krew plugin to set up the MinIO Operator and our object storage.
Download the MinIO Krew plugin.
kubectl krew install minio
Then initialize the operator.
kubectl minio init
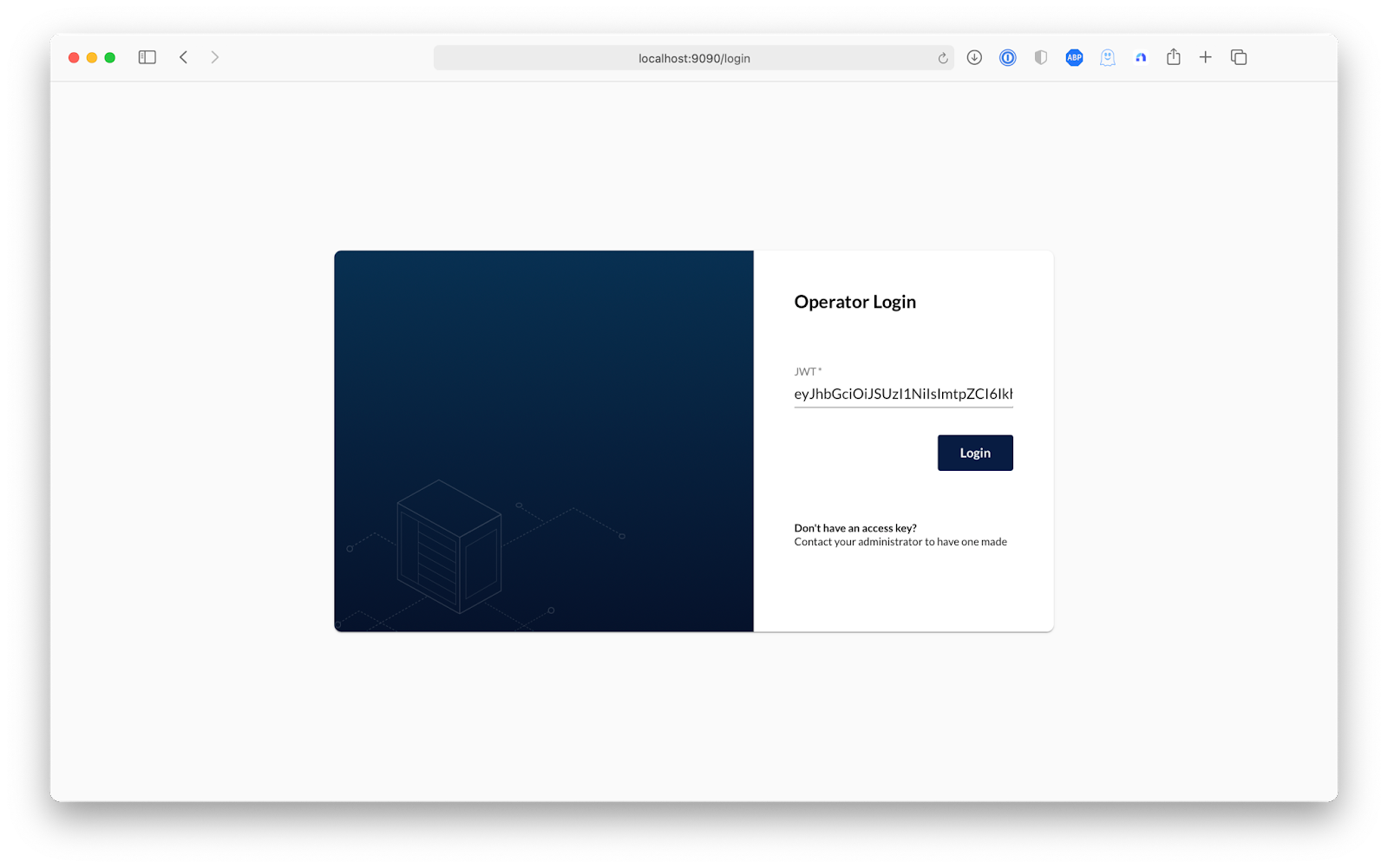
Now, let's go into the MinIO Operator UI to create our first Tenant. Enter the following command to receive a locally accessible endpoint and a token to log in.
kubectl minio proxy -n minio-operator
The expected output is:
Starting port forward of the Console UI. To connect open a browser and go to http://localhost:9090 Current JWT to login: eyJhbGciOiJSUzI1NiIsImtpZCI6IkhWclVWMmc2YjNuZlRKcGY1YUxJTTh1Mjd2d3ZKZmh5dzBKaE10cm5QYUUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJtaW5pby1vcGVyYXRvciIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJjb25zb2xlLXNhLXRva2VuLTh2cDRxIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImNvbnNvbGUtc2EiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI4MDJkMmFlZi02ZTQxLTQyMzctYjIyYS04OGVkNjhhNTFkMWMiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6bWluaW8tb3BlcmF0b3I6Y29uc29sZS1zYSJ9.CxaS7Xy6l63Z90FLDL0XV0FB4iYYD93-EZ9lT6dUxHTkaYIwGzuVAOVYKclIAslpJqvANzurnuCQv2DSYuptBokqNyJqBZ_Mdfxk_BD8k9LNvvhH2B75FXJOlLUvO43HZp-vWqiBLHvhWD86KI5YdCqgXq0KB2Yuw03pIeAkGhdo-QN7EnTVt-mu6OniB6q_oSC61wUoToHCZKbq7OLeg2zzwqo9JGCBvghBbiVFzeMTYAQHdad69PsWjBRBlUKbG7v5eNWiVPiV44r0-fUZxdCr-1JEP9e4Ag-8J2GzIU1-yBIc_Yn1ok59HxXwiT-_fmp2tpe2WsArY7Hwzza2qLoVSkITzPX6eMVbGfRdzbcxd396LcQfg8GJn4Rbs1Z4YCRqMK_DpoQqYOFf-pjZ6Oa91GlZpMVSH_6_H4xxBuuobyn3WK7XyuBxJuFcl7KoIKoa4qwi87eUE139RXPOZKsCrMX-YmKxTAixKlGux2U4jRaN2lav6_y-ayUvHt0syEJqu0uhqdPNVxGIWW0sabJJ0sSfQdacmrBY1VazIYsN2NAL1N2QCwmQvvjRlqpEAWPF_uhuVwGtgcDX8-CxRKtfoY-8gn7ujwCKl1GMpyr-nE8p88eMIxEkaXqBia0erRLwUGTHrS2ymGN0Ii85_2wRZmDuCGA9QiQ01r89ZXU Forwarding from 0.0.0.0:9090 -> 9090
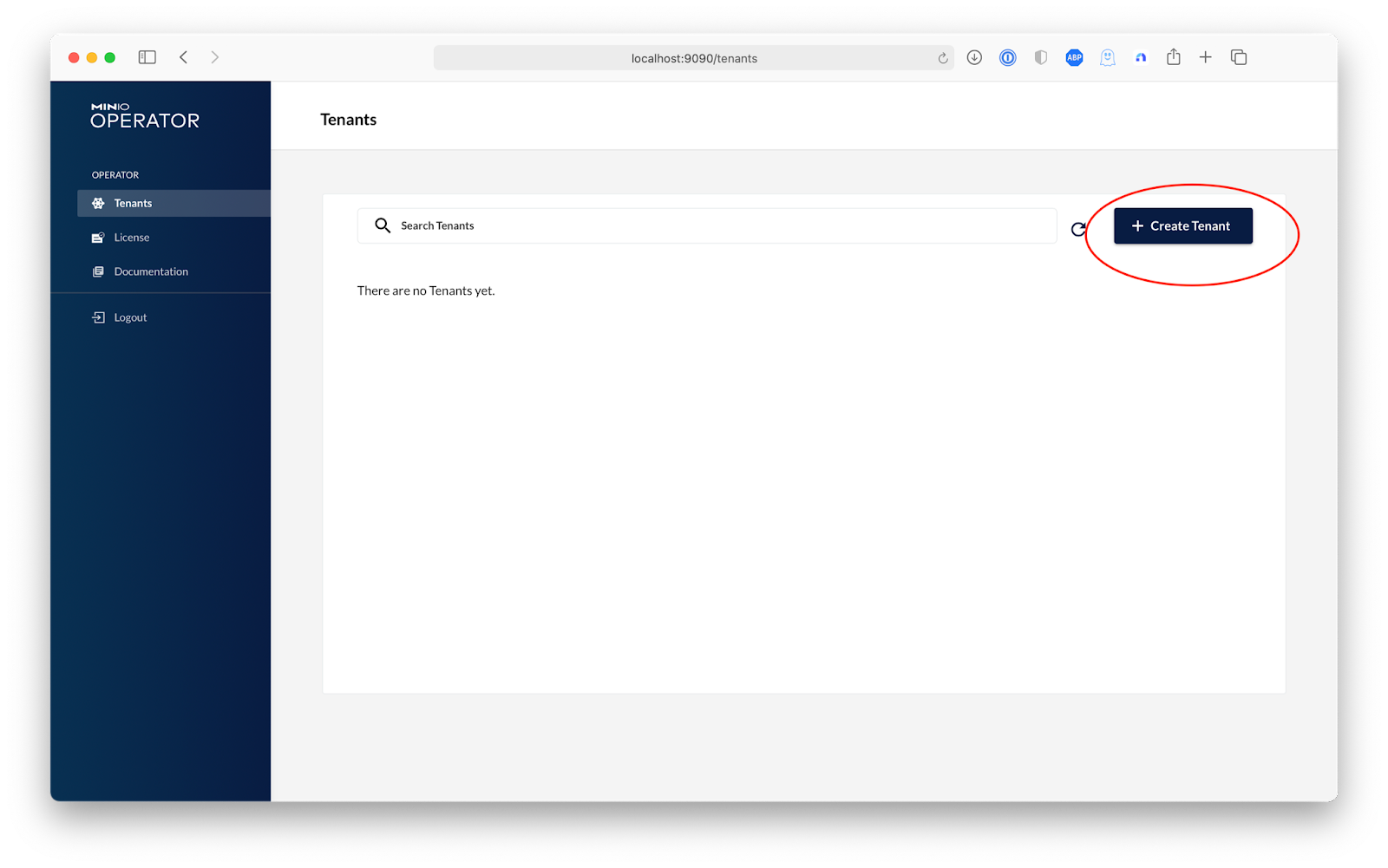
After logging in we'll be greeted with an empty list of Tenants, let's create one by clicking on + Create Tenant on the top right.
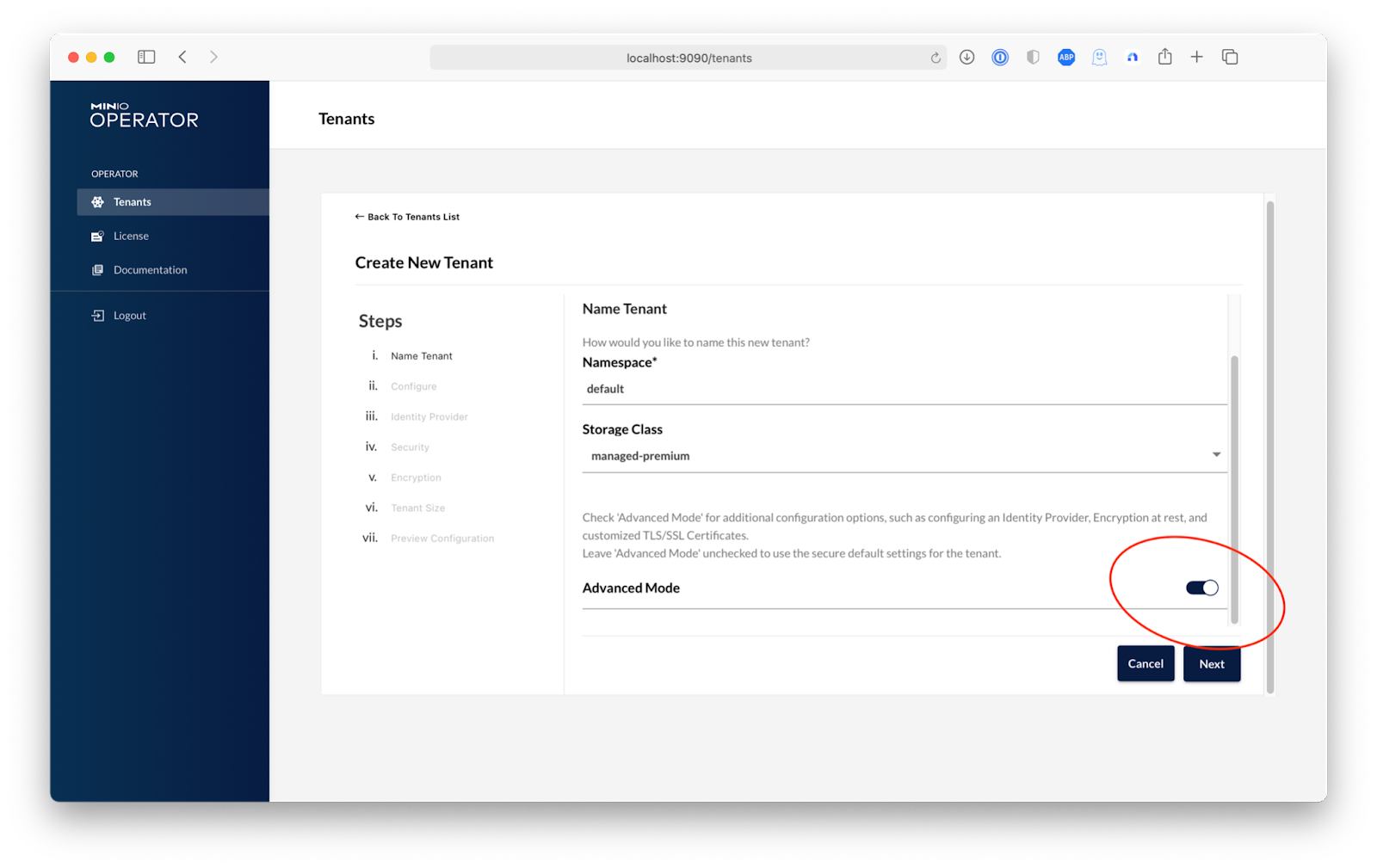
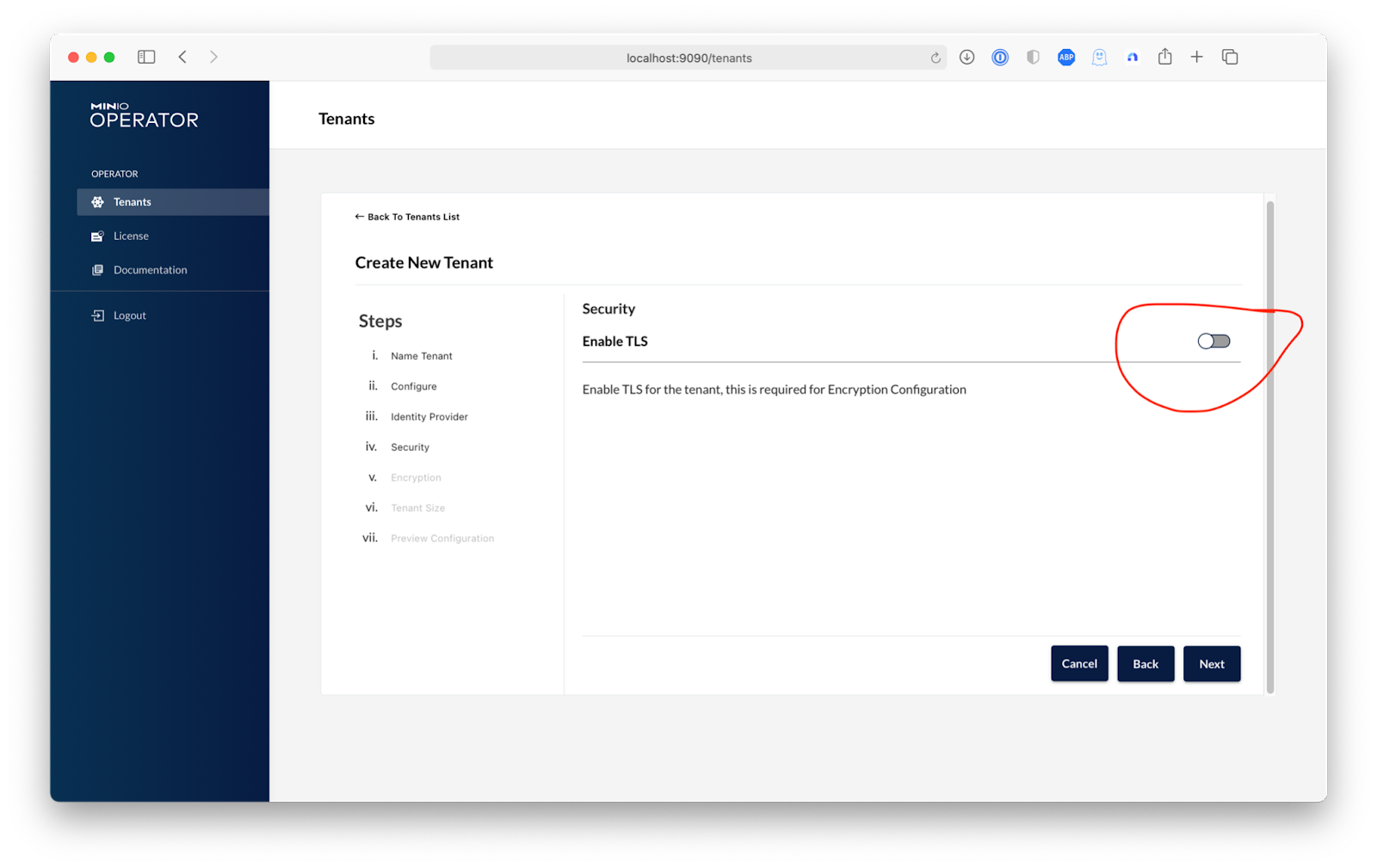
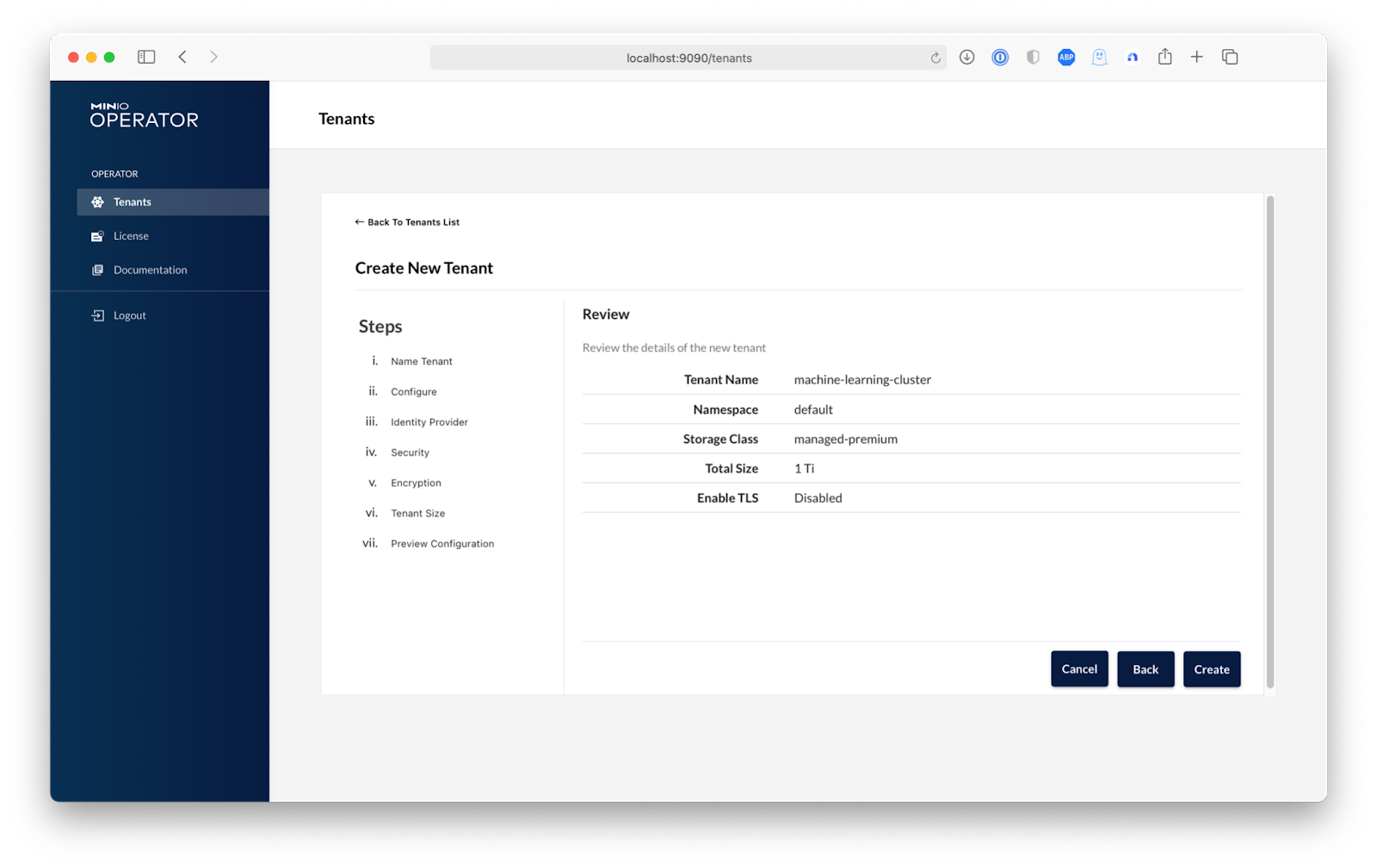
In order to keep things simple during this setup, we are going to create a tenant called machine-learning-cluster on the default namespace of our cluster. Of course you can change this to any namespace that suits your needs. Then we will choose a storage class, and since we are aiming for a high-performance data repository we will use Azure's Managed Premium Storage to get the best performance for our Kubeflow pipelines. After completing these fields, select Advanced. Here is where you can configure advanced features such as Custom Docker Registries, Identity Providers, Encryption and Pod Placement. For now, we are going to click Next until we reach the Security step and turn off TLS so we can complete this guide without needing to setup a domain and an external TLS certificate.
Turn off TLS for this tenant.
Now, we will tell the MinIO Operator how big we want our tenant. I'm going to go for 4 nodes to match our current setup and 1 Terabyte of capacity, but you can adjust this to whatever fits your needs.
The last step is a review of what's going to happen. simply click Create and MinIO does the rest!
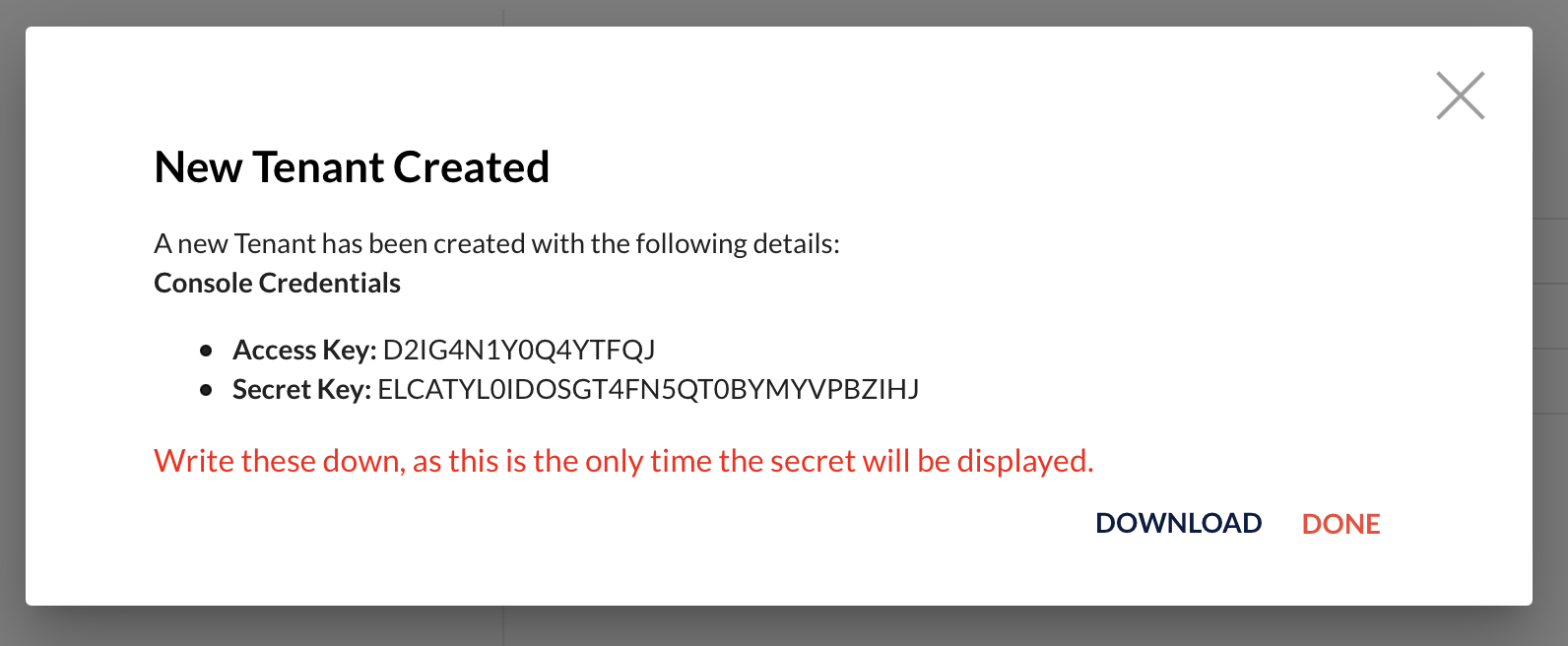
Write down the auto generated credentials to access your object storage, we will use these to access the underlying storage.
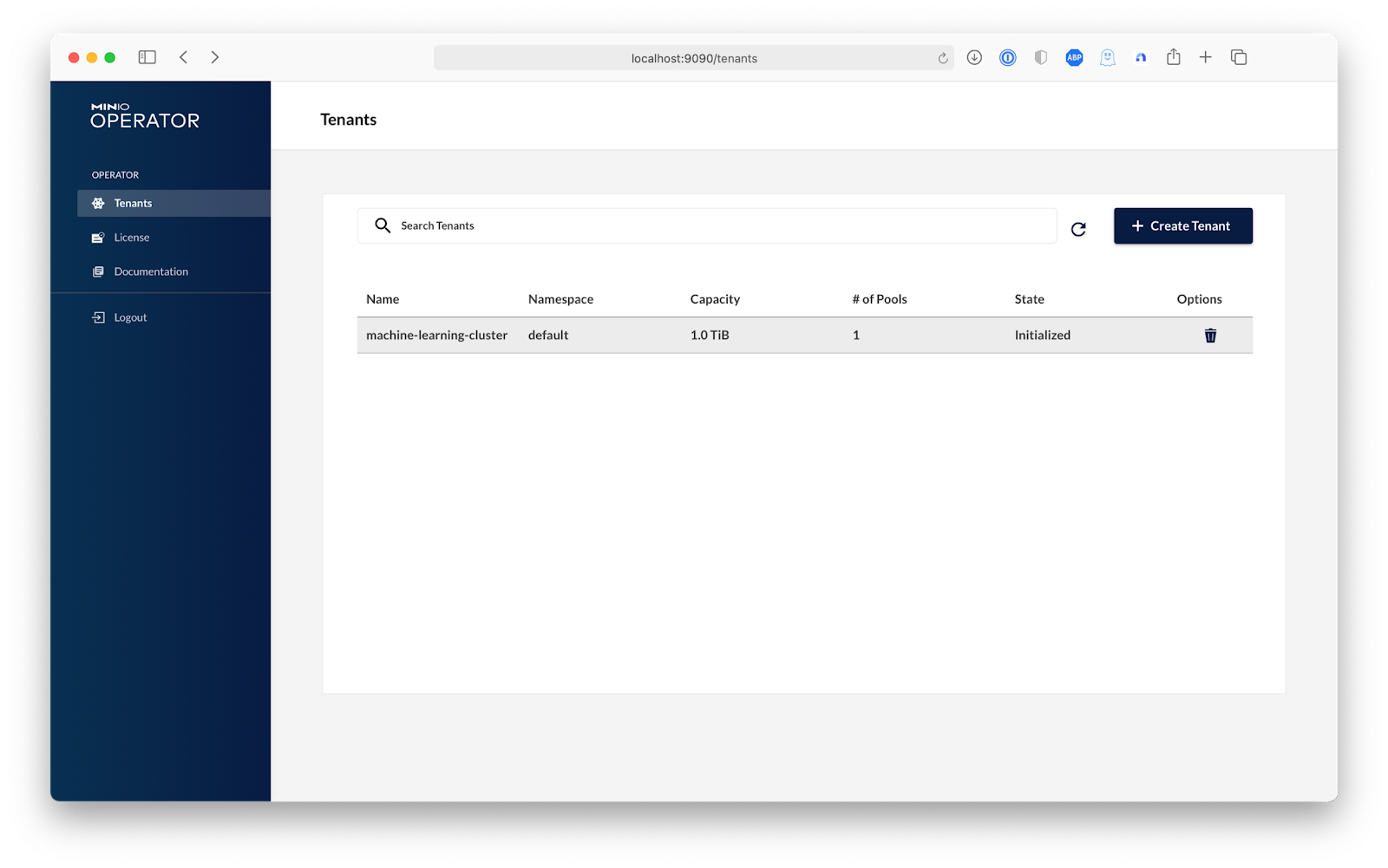
That's it! You've provisioned a high performance object storage and it took just a few minutes. After another few minutes you'll see the tenant Initialized and it's ready to go.
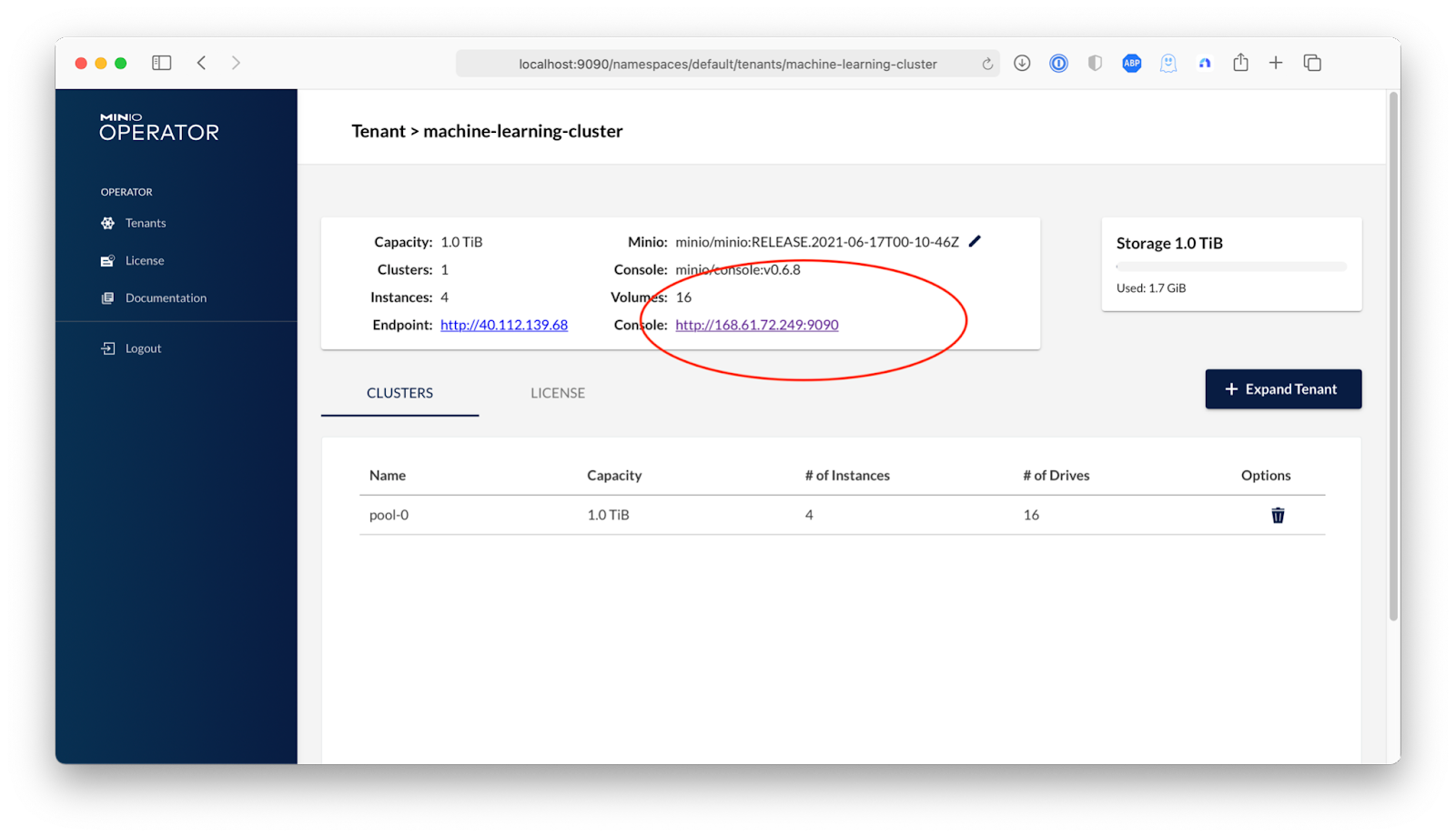
The Tenant details are where you can update your Object Storage and expand it. We can also see that there's a public IP for our object storage and for managing our object storage. We are not going to use that in this guide, but that's what you could use to start consuming the object storage from outside this cluster.
We are ready to go on the object storage front - we've setup a high performance cluster and now we need to leverage it within our Kubeflow pipelines.
Setting up Kubeflow
To set up Kubeflow on AKS we are going to use the command line utility kfctl which can be downloaded from the kfctl release page. There are binaries for Mac and Linux, but if you are on Windows, you'll have to compile that binary from the source. Just make sure the kfctl binary is in your PATH.
# Set KF_NAME to the name of your Kubeflow deployment. You also use this # value as directory name when creating your configuration directory. # For example, your deployment name can be 'my-kubeflow' or 'kf-test'. export KF_NAME=my-kubeflow # Set the path to the base directory where you want to store one or more # Kubeflow deployments. For example, /opt/. # Then set the Kubeflow application directory for this deployment. export BASE_DIR=kubeflowsetup export KF_DIR=${BASE_DIR}/${KF_NAME} # Set the configuration file to use when deploying Kubeflow. # The following configuration installs Istio by default. Comment out # the Istio components in the config file to skip Istio installation. # See https://github.com/kubeflow/kubeflow/pull/3663 export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v1.2-branch/kfdef/kfctl_k8s_istio.v1.2.0.yaml" mkdir -p ${KF_DIR} cd ${KF_DIR} kfctl apply -V -f ${CONFIG_URI}
This process will take about eight minutes as configured, so grab a cup of coffee and monitor the completion with the following command.
kubectl get all -n kubeflow
Once all pods are running, we are ready to move forward with building a Kubeflow pipeline that leverages MinIO.
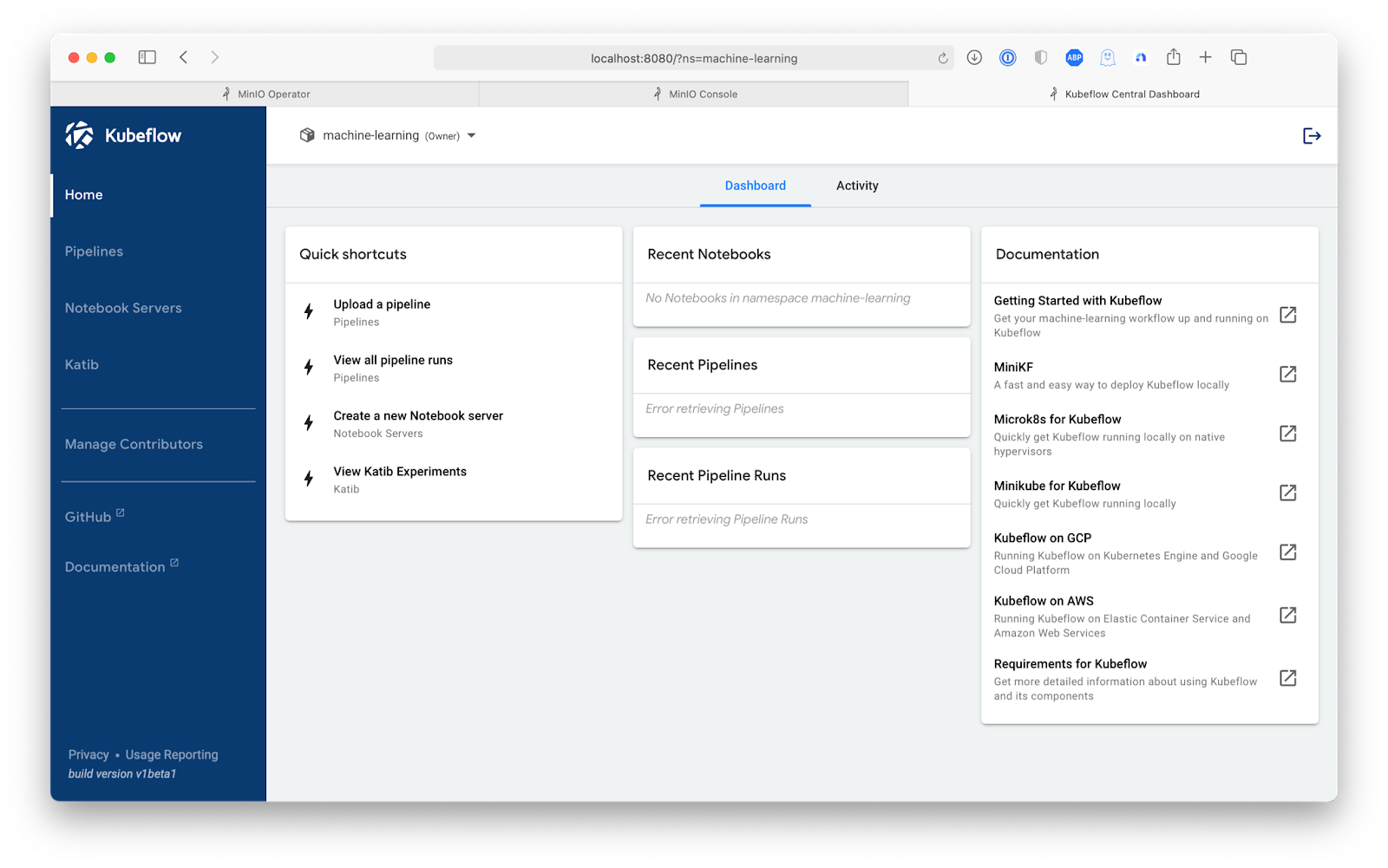
Open the Kubeflow dashboard by running the following port-foward command and going to http://localhost:8080.
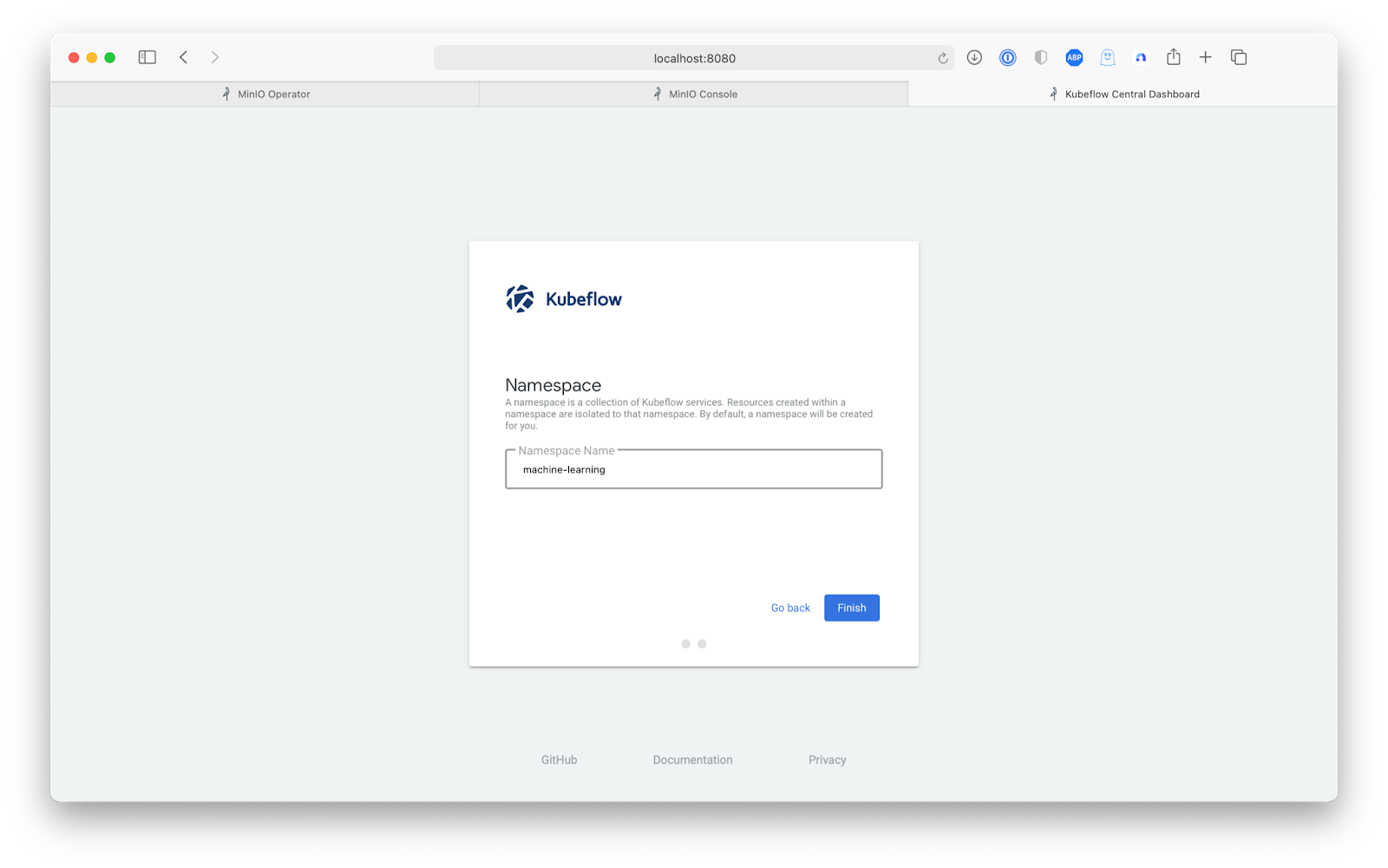
Then complete the Kubeflow setup by creating a machine-learning namespace.
The Kubeflow dashboard opens after we configure a namespace.
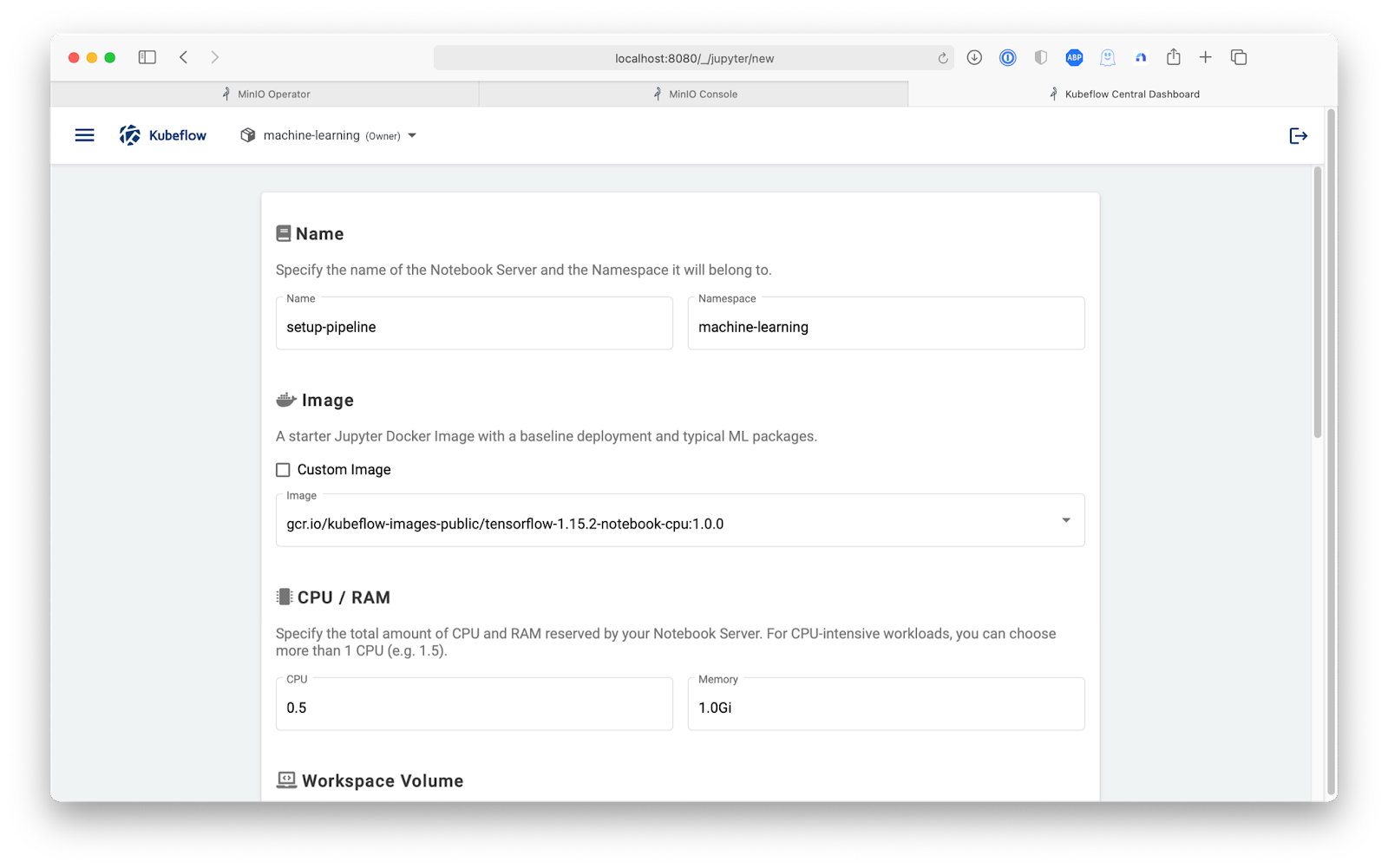
Let's set up a Jupyter notebook server and configure it from there. Using the Tensorflow 1.15 image, create a notebook called setup-pipeline.
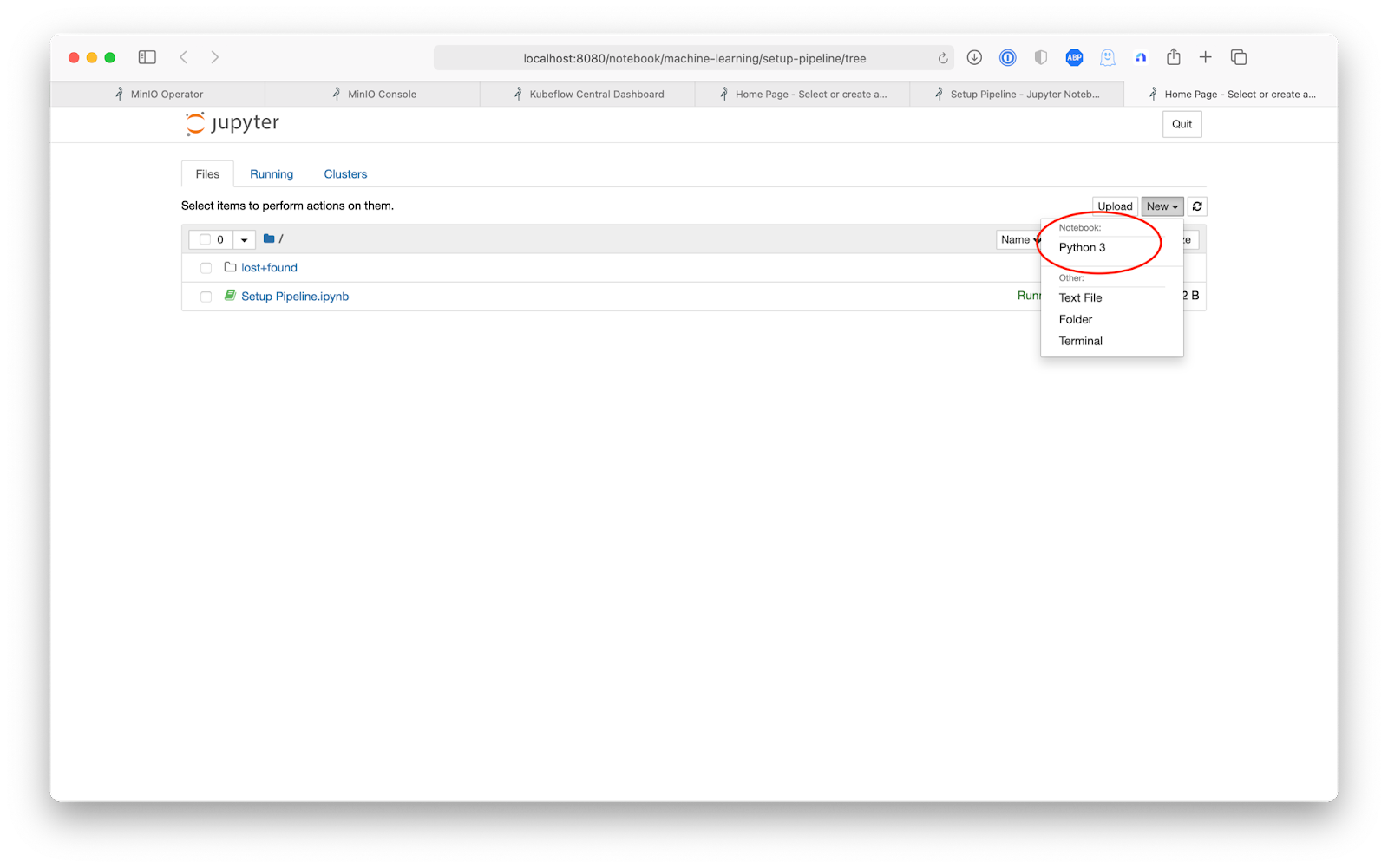
Once the server is ready, connect to it, and then create a Python 3 notebook called Setup Pipeline.
The final step is to configure your Docker account. Kubeflow will push to Docker every new model you build throughout your pipeline and you may hit the 100 request per hour limit pretty quickly. When you use a Docker account, the limit is raised to 200 requests per hour.
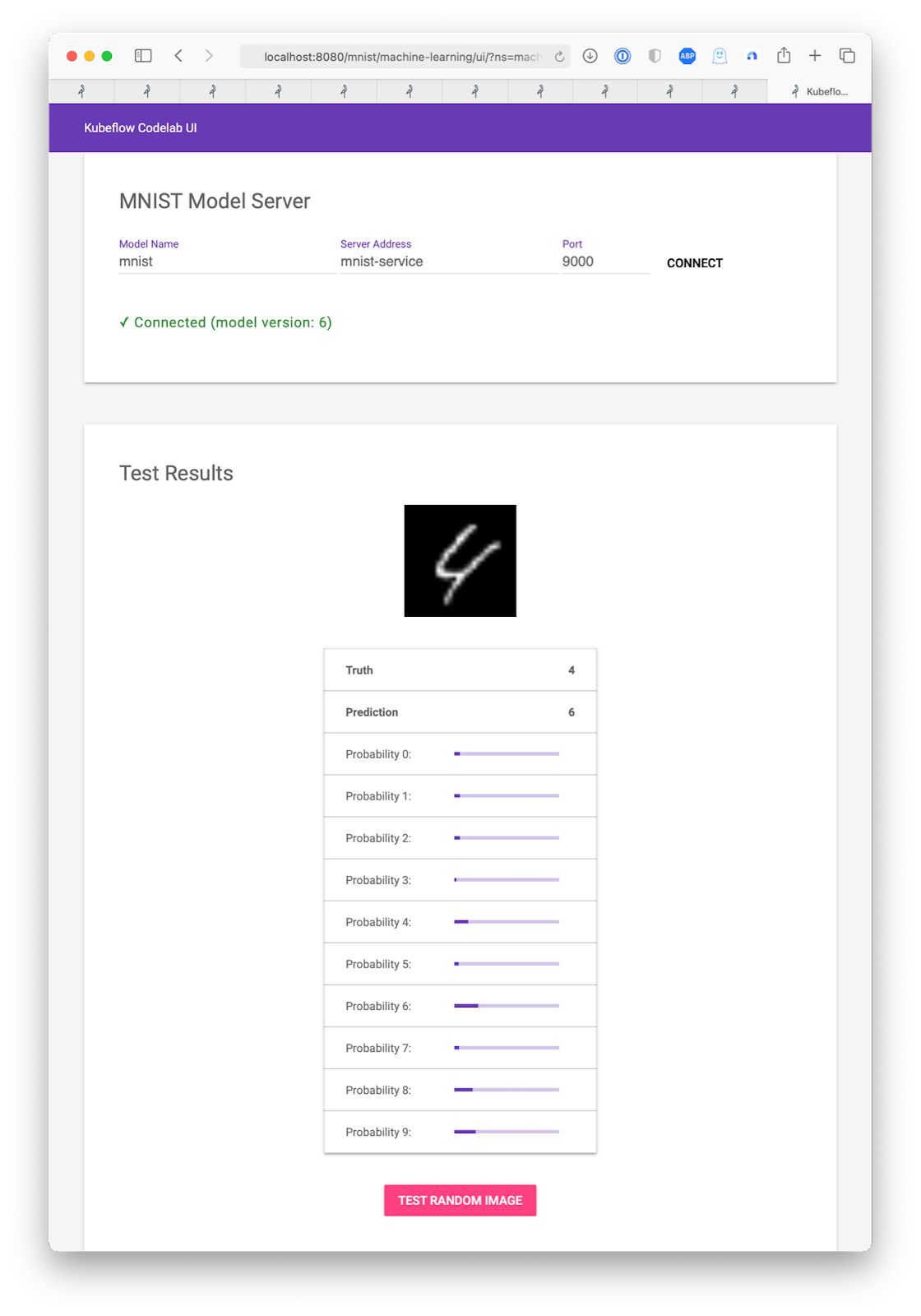
Now back to our Notebook. From here on, we will follow the excellent example for vanilla kubernetes that the Kubeflow team provides. We’ll learn how to submit models to Kubeflow for distributed training, as well as how to deploy and serve them.
You are going to need a few files for this notebook to work, mainly model.py, k8s_util.py, notebook_setup.py, requirements.txt and Dockerfile.model to build your model, submit it to Kubeflow and then deploy it. Let's start with the following snippet to download those files into our notebook.
import urllib.request import shutil file_list = ["https://raw.githubusercontent.com/kubeflow/examples/master/mnist/k8s_util.py","https://raw.githubusercontent.com/kubeflow/examples/master/mnist/Dockerfile.model","https://raw.githubusercontent.com/kubeflow/examples/master/mnist/model.py","https://raw.githubusercontent.com/kubeflow/examples/master/mnist/notebook_setup.py","https://raw.githubusercontent.com/kubeflow/examples/master/mnist/requirements.txt"] for url in file_list: file_name = url.split("/").pop() with urllib.request.urlopen(url) as response, open(file_name, 'wb') as out_file: shutil.copyfileobj(response, out_file)
Now, let's prepare the namespace and configure our MinIO credentials. For our endpoint we are going to use the internal Kubernetes service name minio.default.svc.cluster.local and for the DOCKER_REGISTRY we will enter our Docker username.
from kubernetes import client as k8s_client from kubernetes.client import rest as k8s_rest from kubeflow import fairing from kubeflow.fairing import utils as fairing_utils from kubeflow.fairing.builders import append from kubeflow.fairing.deployers import job from kubeflow.fairing.preprocessors import base as base_preprocessor DOCKER_REGISTRY = "miniodev" namespace = fairing_utils.get_current_k8s_namespace() from kubernetes import client as k8s_client from kubernetes.client.rest import ApiException api_client = k8s_client.CoreV1Api() minio_service_endpoint = "minio.default.svc.cluster.local" s3_endpoint = minio_service_endpoint minio_endpoint = "http://"+s3_endpoint minio_username = "AXNENHDUBB2LU24Y" minio_key = "GPONOCU0IDQZBMP55TTELR00D4HGFPJK" minio_region = "us-east-1" logging.info(f"Running in namespace {namespace}") logging.info(f"Using docker registry {DOCKER_REGISTRY}") logging.info(f"Using minio instance with endpoint '{s3_endpoint}'")
Next we’ll prepare the local notebook by installing dependencies and downloading the required data. All of this can be done in a single block but I used the same separate blocks as the example notebook to make it easier for you to follow.
import logging import os import uuid from importlib import reload import notebook_setup reload(notebook_setup) notebook_setup.notebook_setup(platform='none')
import k8s_util # Force a reload of kubeflow; since kubeflow is a multi namespace module # it looks like doing this in notebook_setup may not be sufficient import kubeflow reload(kubeflow) from kubernetes import client as k8s_client from kubernetes import config as k8s_config from kubeflow.tfjob.api import tf_job_client as tf_job_client_module from IPython.core.display import display, HTML import yaml
# TODO(https://github.com/kubeflow/fairing/issues/426): We should get rid of this once the default # Kaniko image is updated to a newer image than 0.7.0. from kubeflow.fairing import constants constants.constants.KANIKO_IMAGE = "gcr.io/kaniko-project/executor:v0.14.0"
from kubeflow.fairing.builders import cluster # output_map is a map of extra files to add to the notebook. # It is a map from source location to the location inside the context. output_map = { "Dockerfile.model": "Dockerfile", "model.py": "model.py" } preprocessor = base_preprocessor.BasePreProcessor( command=["python"], # The base class will set this. input_files=[], path_prefix="/app", # irrelevant since we aren't preprocessing any files output_map=output_map) preprocessor.preprocess()
# Use a Tensorflow image as the base image # We use a custom Dockerfile from kubeflow.fairing.cloud.k8s import MinioUploader from kubeflow.fairing.builders.cluster.minio_context import MinioContextSource minio_uploader = MinioUploader(endpoint_url=minio_endpoint, minio_secret=minio_username, minio_secret_key=minio_key, region_name=minio_region) minio_context_source = MinioContextSource(endpoint_url=minio_endpoint, minio_secret=minio_username, minio_secret_key=minio_key, region_name=minio_region)
cluster_builder = cluster.cluster.ClusterBuilder(registry=DOCKER_REGISTRY, base_image="", # base_image is set in the Dockerfile preprocessor=preprocessor, image_name="mnist", dockerfile_path="Dockerfile", context_source=minio_context_source) cluster_builder.build() logging.info(f"Built image {cluster_builder.image_tag}")
At this point, you can go to your personal Docker registry and confirm a new Docker image for the MNIST model was created.
The next step is to create a MinIO Bucket.
mnist_bucket = f"{DOCKER_REGISTRY}-mnist" minio_uploader.create_bucket(mnist_bucket) logging.info(f"Bucket {mnist_bucket} created or already exists")
Next we simply build a TFJob and Deployments to train our model, inspect it using TensorBoard and finally to serve it, with all the intermediate steps stored on your MinIO Tenant.
We’re ready to check the model on MinIO. We can do this via our notebook or through the MinIO Console. First, I’m showing how to do this through a notebook.
from botocore.exceptions import ClientError try: model_response = minio_uploader.client.list_objects(Bucket=mnist_bucket) # Minimal check to see if at least the bucket is created if model_response["ResponseMetadata"]["HTTPStatusCode"] == 200: logging.info(f"{model_dir} found in {mnist_bucket} bucket") except ClientError as err: logging.error(err)
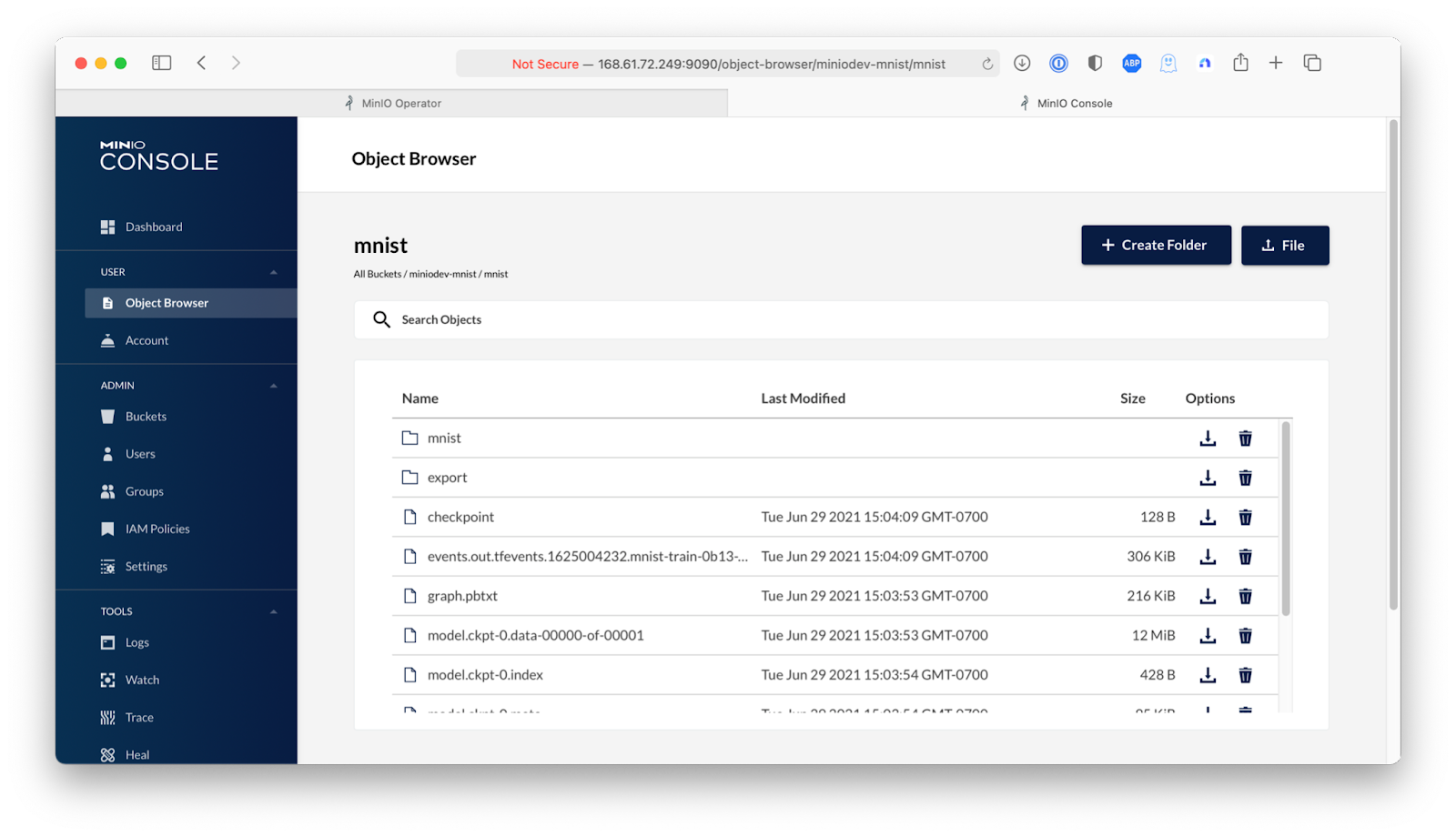
Now I’ll show how to do this using the Operator Console. Go into the Tenant Details In the Operator GUI and click on the console URL.
From here, log in to the MinIO Console, go into the Object Browser and explore the miniodev-mnist bucket where we can see the checkpoints and the model itself.
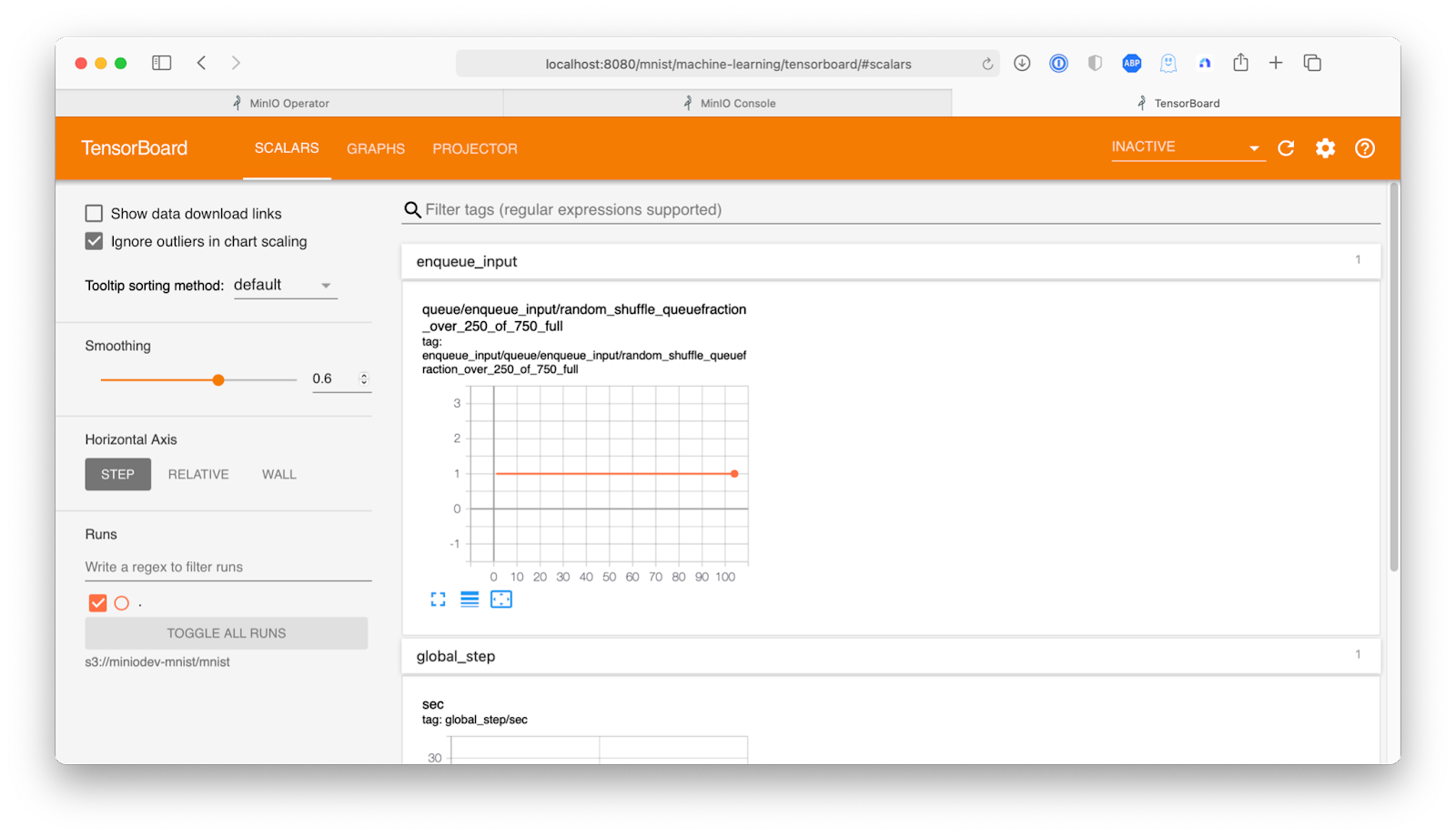
Let's explore how the training went. Using TensorBoard, we will create a deployment.
Alright! We reached the end of this large guide that explains how to set up MinIO on Azure Kubernetes Service and then deploy Kubeflow to work with MinIO out of the box. The easiest parts were setting up the building blocks of AKS, MinIO and Kubeflow thanks to their high degree of automation. This frees you to focus on more important tasks such as building your machine learning pipelines to run smoothly on Kubeflow, leveraging large datasets straight from MinIO and storing and deploying the models straight from the object storage as well.
Download MinIO to get started and if you have any questions join our Slack Channel or drop us a note at hello@min.io. We are here to help you.