Map-Style Datasets using Amazon’s S3 Connector for PyTorch and MinIO

Before diving into Amazon’s S3 Connector for PyTorch, it is worthwhile to introduce the problem it is intended to solve. Many AI models need to be trained on data that cannot fit into memory. Furthermore, many really interesting models being built for computer vision and generative AI use data that cannot even fit on the disk drive that comes with a single server.
Solving the storage problem is easy. If your dataset cannot fit on a single server, then you need S3-compatible object storage. In the cloud, that will most likely be Amazon’s S3 object store. For on-premise model training, you will need MinIO. S3 compatibility is important since S3 has become the de facto interface for unstructured data, and a solution that uses an S3 interface will give your engineers more options when choosing a data access library.
Solving the memory problem is more challenging. Instead of loading your dataset once at the beginning of your training pipeline, you need to figure out a strategy for reading your data every time a batch of data is needed for training. A common approach is to load a list of object paths at the start of the training pipeline, and then, as you batch through this list of paths, you retrieve each object to get the actual object data. The two visualizations below show the details of front loading versus batch loading.

Training Pipeline that retrieves the entire dataset at the start of the training pipeline
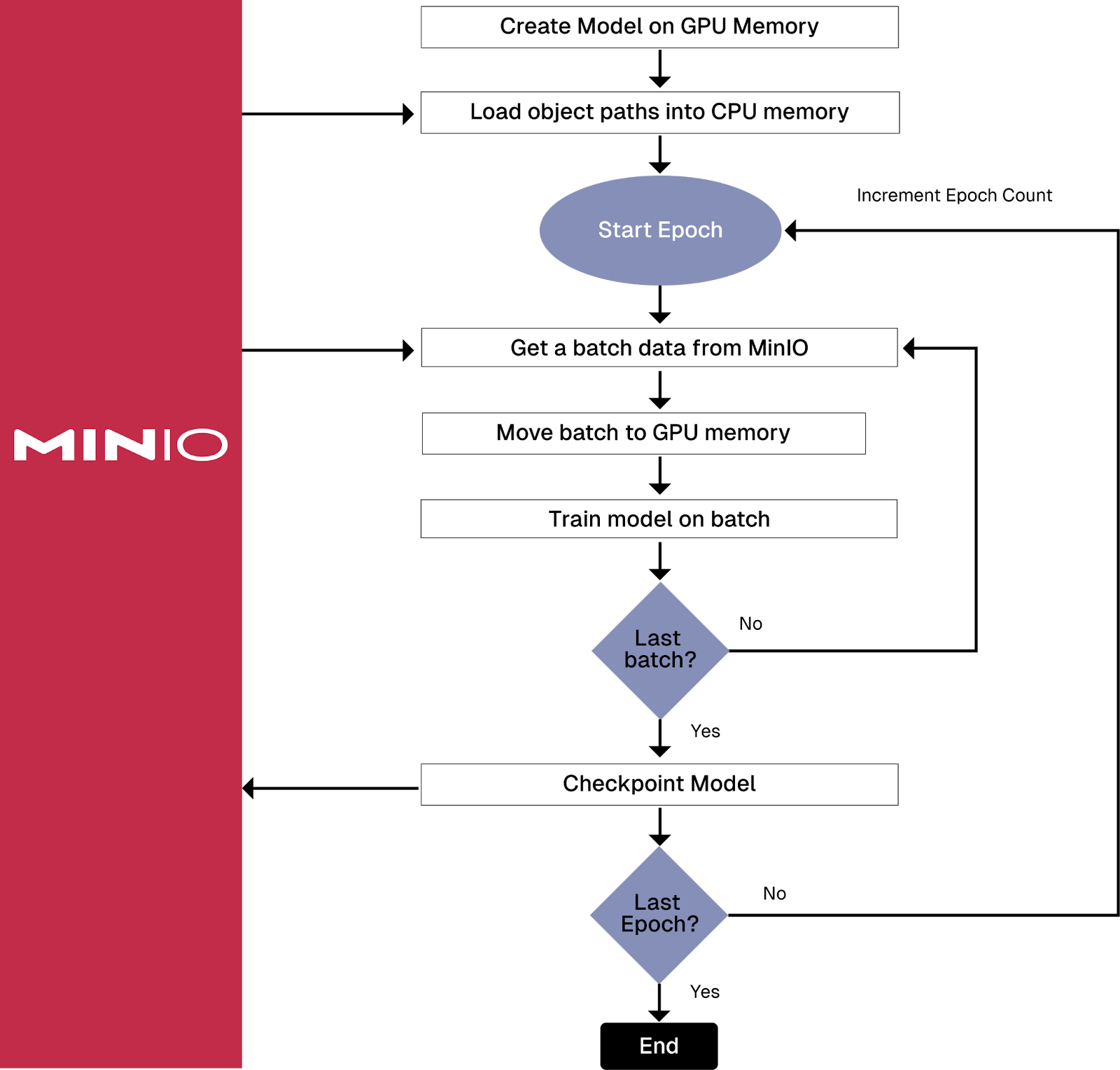
Training Pipeline that retrieves data from storage for every batch
As you can see, batch loading puts more of a burden on your network and your storage solution, both of which will need to be fast. This is one of the approaches to the “large dataset problem” that Amazon’s S3 Connector for PyTorch solves by making data access more efficient and reducing the amount of code that needs to be written.
It turns out that there have been previous attempts to solve the large dataset problem. Let’s study a little history and briefly talk about libraries that preceded Amazon’s new connector. Many of these libraries are still available, so it is important to know what they are so you do not use them.
Libraries of Yesteryear
Amazon announced the Amazon S3 Plugin for PyTorch in September 2021. This plugin never made it into PyPI as a true Python library. Rather, it was available via Amazon’s container registry, or it could be installed from its GitHub repository. If you navigate to this post today, you will see a notice recommending the S3 Connector for PyTorch.
In July 2023, PyTorch announced the CPP-based S3 IO DataPipes. This library looked promising as it was implemented as a C++ extension (interpret this to mean that it would be really fast) and had classes for listing and loading objects. Listing objects in an S3 bucket can sometimes be slow, so it looked like the PyTorch folks were on the correct path. The original announcement still exists without warning, but if you navigate to a few of the GitHub page for the S3 IO Datapipe Documentation you will see deprecation warnings and recommendations to use the S3 Connector for PyTorch. The user documentation has similar warnings.
Now that we know what not to use, let's look at the S3 Connector for PyTorch.
Introducing the S3 Connector for PyTorch
In November of 2023 Amazon announced the S3 Connector for PyTorch. The Amazon S3 Connector for PyTorch provides implementations of PyTorch's dataset primitives (Datasets and DataLoaders) that are purpose-built for S3 object storage. It supports map-style datasets for random data access patterns and iterable-style datasets for streaming sequential data access patterns. In this post, I will focus on map-style datasets. In a future post, I will cover iterable-style datasets. Also, the documentation for this connector only shows examples of loading data from Amazon S3 - I will show you how to use it against MinIO.
The S3 Connector for PyTorch also includes a checkpointing interface to save and load checkpoints directly to an S3 bucket without first saving to local storage. This is a really nice touch—if you are not ready to adopt a formal MLOps tool and just need an easy way to save your models. I will also cover this feature in a future post.
Just for fun, let’s build a map-style dataset manually. This is the technique you would need to employ if you need to connect to a data source that is not S3 compatible.
Building a Map Style Dataset Manually
A map-style dataset is created by implementing a class that overrides the __getitem__() and __len__() methods in PyTorch’s Dataset base class. Once instantiated, individual samples are mapped to an index or key. The code below shows how to override these methods. It uses the MinIO SDK to manually retrieve an object stored and apply a transformation to it. The full code download can be found here.
Notice two things about this class. First, when it is instantiated, it receives a list of S3 paths, not a list of S3 objects. The following function is used in the code download for this post to get a list of objects in a bucket.
Second, every time an individual sample is requested, a connection to the data source, MinIO, is made to retrieve the sample. In other words, a network request is made for each individual object in the dataset. The snippet below shows how to instantiate this class and use the dataset object to create a Dataloader.
Finally, the snippet below is an abbreviated training loop showing how this dataloader would be used. The highlighted code is the start of the batch loop. IO occurs whenever the for loop yields and a batch of ImageDatasetMap objects are returned. It is at this time that all the __getitem__() methods will be called. This results in a call to MinIO to retrieve the object data. If your batch size is set to 200, for example, then each iteration of this loop would result in 200 network calls to retrieve the 200 samples needed for the current training batch.
The code above makes your training loop IO-bound. If your dataset is too large to be loaded into memory at the beginning of your training pipeline, and each sample is an individual object, then this is your best option for accessing your dataset during model training.
Connecting the S3 Connector to MinIO
Connecting the S3 Connector to MinIO is as simple as setting up environment variables. Afterwards, everything will just work. The trick is setting up the correct environment variables in the proper way.
The code download for this post uses a .env file to set up environment variables, as shown below. This file also shows the environment variables I used to connect to MinIO directly using the MinIO Python SDK. Notice that the AWS_ENDPOINT_URL needs the protocol, whereas the MinIO variable does not. Also, you may notice some odd behavior with the AWS_REGION variable. Technically, it is not needed when accessing MinIO, but internal checks within the S3 Connector may fail if you pick the wrong value for this variable. If you get one of these errors, read the message carefully and specify the value it requests.
Creating a Map-Style Dataset with the S3 Connector
To create a map-style dataset using the S3 Connector, you do not need to code and create a class as we did in the previous section. The S3MapDataset.from_prefix() function will do everything for you. This function assumes that you have set up the environment variables to connect to your S3 object store, as described in the previous section. It also requires that your objects can be found via an S3 prefix. A snippet showing how to use this function is shown below.
Notice that the URI is an S3 path. Every object that can be recursively found under the path mnist/train is expected to be an object that is part of the training set. The function above also requires a transform to transform your object into a tensor and to determine the label. This is done via an instance of the callable class shown below.
That is all you need to do to create a map-style dataset using the S3 Connector for PyTorch.
Conclusion
The S3 Connector for PyTorch is easy to use and engineers will write less data access code when they use it. In this post I showed how to configure it to connect to MinIO using environment variables. Once configured three lines of code created a dataset object and the dataset object was transformed using a simple callable class.
High-speed storage and high-speed data access go hand in hand with high-speed compute. The S3 Connector for PyTorch is explicitly built for efficient S3 access and is authored by the company that gave us S3.
Finally, if your network is the weakest link within your training pipeline, consider creating objects containing multiple samples, which you can even tar or zip. Iterable-style datasets are designed for these scenarios. My next post on the S3 Connector for PyTorch will cover this technique.
If you have any questions, be sure to reach out to us on Slack.






