Migrating MinIO Cluster Instances with Zero Downtime and Zero Data Loss

With the advent of cloud computing, ephemeral compute instances have become ubiquitous. This introduces a whole set of challenges around managing the software, applying DevOps principles, addressing security vulnerabilities and ensuring automation. These are mission-critical in order to prevent data theft and service disruption.
Addressing security vulnerabilities is particularly challenging as it frequently takes the form of updating and restarting software.
Computer Vulnerabilities and Exposures (CVE) is a numbered list of publicly disclosed computer security flaws. Security advisories issued by vendors and researchers almost always mention at least one CVE ID. CVEs help IT professionals coordinate their efforts to prioritize and address known vulnerabilities to make computer systems more secure.
The never-ending barrage of CVEs presents major challenges to product vendors, software engineers and cloud architects - and adds complexity to the already complex tasks of designing and building for an ephemeral cloud solutions architecture. The underlying infrastructure, the platform and the vendor supplied products and services built on top of it must be elastic and nimble enough to deal with the many frequent updates required to remediate these vulnerabilities.
With the rise of high performance object storage, enterprises are now providing Internet scale to cloud-native applications, adding a new dimension to the previously described equation. Now the enterprise must account for ephemeral storage, which is a massive challenge because this would mean frequent machine image changes and potential downtime and possible data loss.
Understanding locally attached vs network attached storage
Before we can approach the operational challenges presented by cloud environments, we need to first discuss storage in general. Specifically we need to address appliance vs. software-defined, the tradeoffs of drive types and the ways those drives are presented to the instances.
Software-defined storage is the way storage is done in the cloud-native world. It is easily containerized and orchestrated using Kubernetes. This makes it elastic and agile. Appliance based solutions, on the other hand are not containerizable which is why you will not find them in the public cloud or other cloud operating model deployments scenarios.
Software-defined storage does introduce adjacent challenges. It requires the organization to tackle network attached storage (NAS) design and to address network bandwidth challenges. To mitigate the network bandwidth requirements, we need to design for direct attached storage (DAS). References to DAS are usually related to storage devices such as HDDs or SSDs/NVMes.
A direct-attached storage device is not networked. There are no connections through Ethernet or Fiber Channel (FC) switches, as is the case for network-attached storage (NAS) or a storage area network (SAN).
An external DAS device connects directly to a computer through an interface such as Small Computer System Interface (SCSI), Serial Advanced Technology Attachment (SATA), Serial-Attached SCSI (SAS), FC or Internet SCSI (iSCSI). The device attaches to a card plugged into an internal bus on the computer.
When adopting containerization on a Kubernetes platform, such drives get referred to as local persistence volumes (localpv) and network attached persistence volumes (networkpv). The architecture of such a software defined high performance object storage solution would look like the diagram below compared to a network attached storage solution.
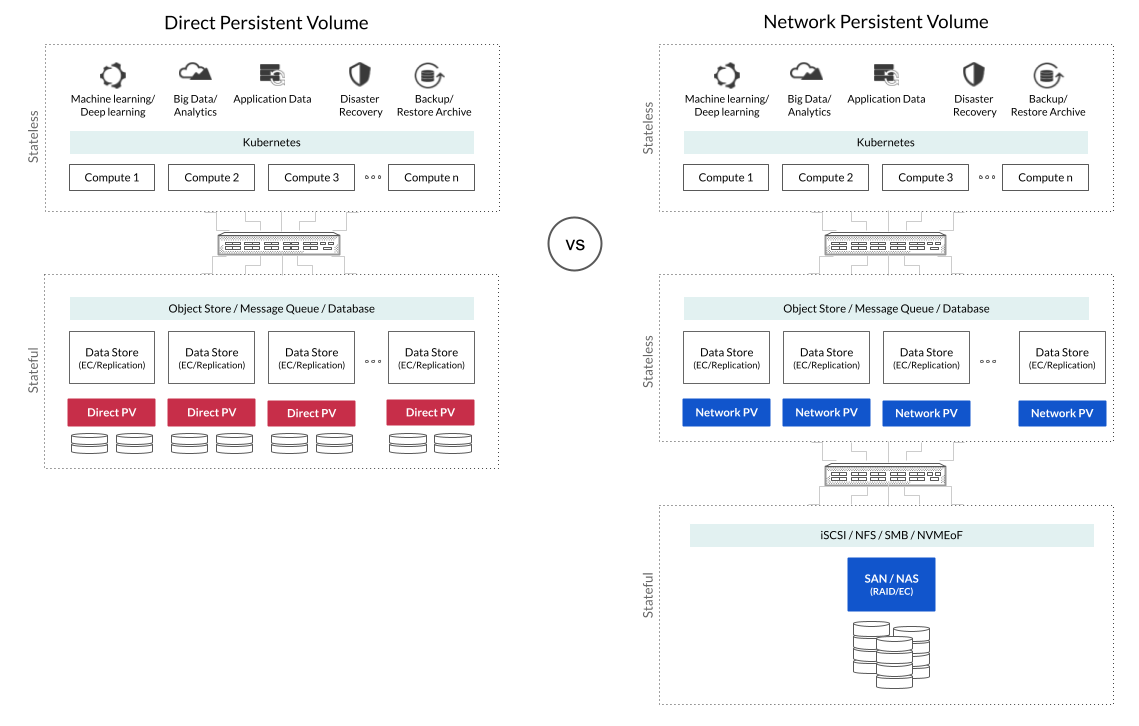
Advantages and Disadvantages of Local Persistence Volumes
Local persistence volumes deliver far better performance for use cases like Data Lakes and AI/ML because it mitigates the network bandwidth bottlenecks to read and write data. For this reason sophisticated enterprises adopt local pv for applications that require high performance. Local pv has the additional benefit of being less complex than network-based storage systems, making it easier to implement and maintain resulting in savings on Day 1 and on Day 2.
Advancements in virtualization technologies have transformed localpv. This is especially apparent when looking at modern hyperconverged infrastructure (HCI) systems. An HCI system is made up of multiple server and local pv storage nodes, with the storage consolidated into logical resource pools, providing a more flexible storage solution than conventional localpv.
Local pv is not without challenges, however. It has limited scalability and lacks the type of centralized management and backup capabilities available to other storage platforms. In addition, it can’t be easily shared and doesn’t facilitate failover should the server crash. Because of these challenges, conventional forms of local pv are not suited for many enterprise workloads.
A software defined storage solution would need to build tools and capabilities around these challenges. Here are the use cases and how local pv helps and its benefits and challenges.
There is enough reason to indicate direct persistence volumes are the right architecture when it comes to data intensive storage requirements.
Drive Attachments at Instance Level
Taking the conversation further down, to the instance level, we will compare the different types of storage available for AWS EC2 instances. These instances support two types for block level storage, HDD or NVMe/SSD drives.
We could choose Elastic Block Storage (EBS) backed instances or Instance Store (ephemeral store) instances. Elastic block storage is a detachable storage from the instance whereas Instance Store volumes are root volumes attached locally along with additional volumes. Instance Store-backed EC2 instances are ephemeral and the volumes are not detachable and hence ephemeral by default.
It is easier to comprehend the differences and their implications with side-by-side diagrams.
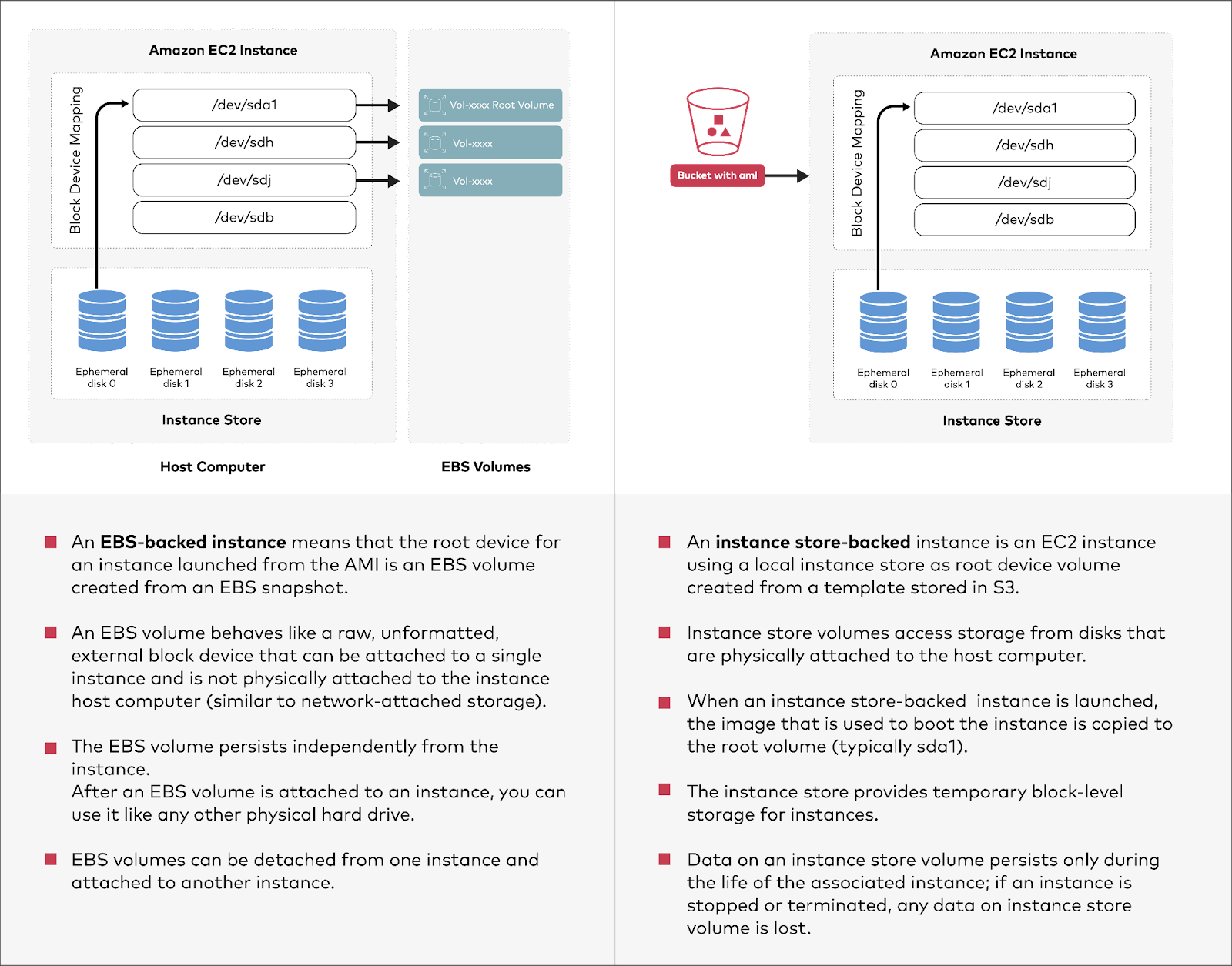
Comparing EBS-Backed Instances and Local Instance Stores
As we noticed the features (or lack thereof) of the EBS-backed instances and local Instance Stores, we can compare and contrast the two types of storage across several characteristics to make an informed decision as to which is better suited to meet the particular requirements of the use case.
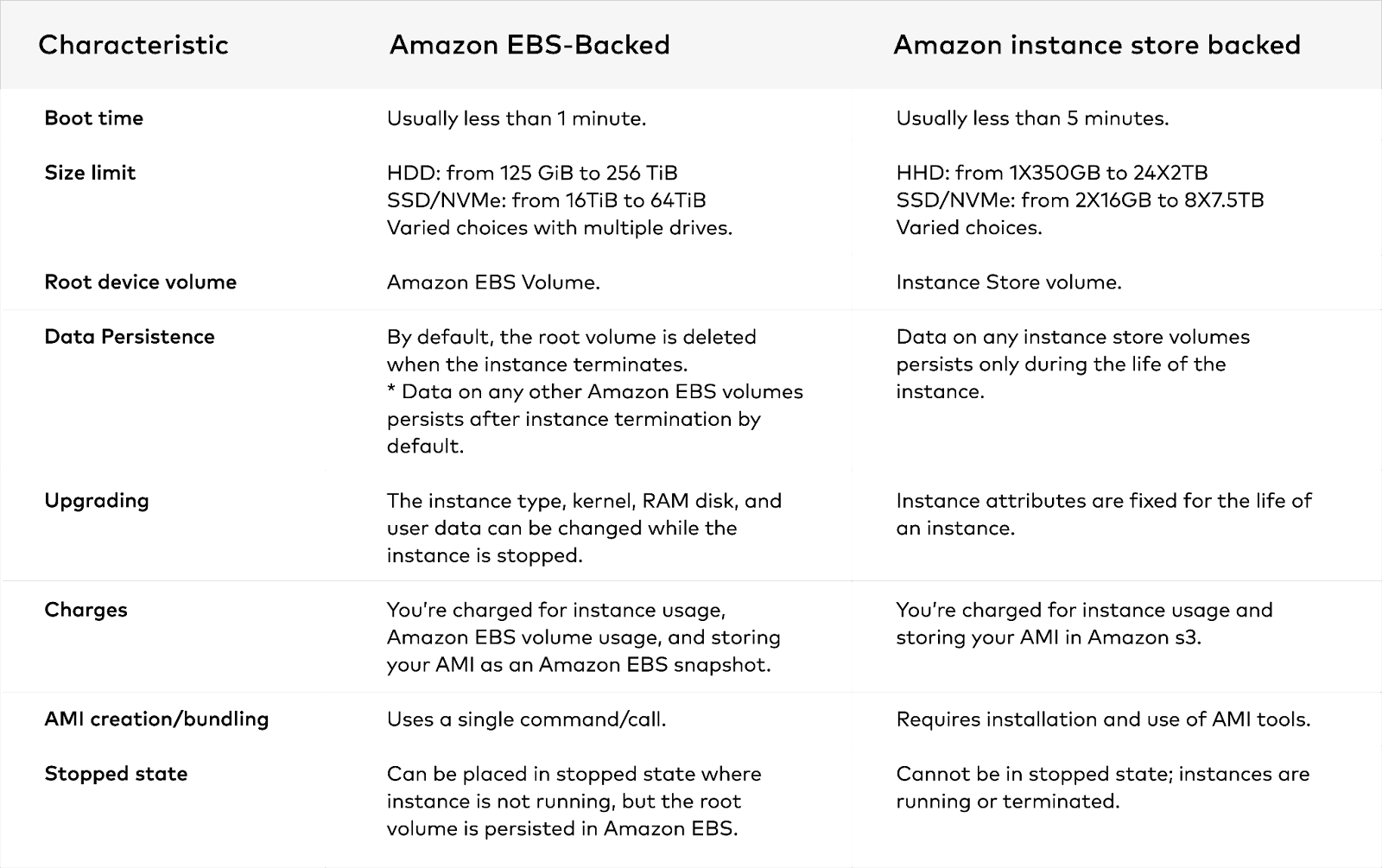
*By default, Amazon EBS-backed instance root volumes have the DeleteOnTermination flag set to true. You must either keep the root volume smaller and not store any data on it, or flip the flag so the volume is not deleted on termination.
Every use case is different because every enterprise is different and every dataset is different. As a result, there is no single answer. The local Instance Store makes the most sense for demanding data workloads, but EBS-backed instances provide the ability to persist data outside of the ephemeral instances. What this means is that we could detach the volume from the instance and reattach it to a different instance without any loss of data.
Addressing Cluster Instance Migration Challenges
Now that we understand the storage patterns, the differences between direct persistence volume vs network persistence volumes and we have looked at the differences at Amazon instance level drive mapping patterns, we will need to understand the new activities that arise and their definitions due to the ephemeral storage, elasticity and nimbleness in the architecture. These arise as we adopt to cloud native solutions and they are defined below:
- Image Rehydration: Image Rehydration is the process of spinning up new servers with the latest patches for vulnerabilities identified (as mentioned in problem statement) already installed on them and decommissioning/destroying old servers that do not. It is possible to rehydrate tens, hundreds and even thousands of servers at the same time in the public cloud.
- Instance upgrades: As new high performance instances are released, it is prudent to upgrade to those instances for high performance and improved resilience.
- Changing drives: MinIO supports erasure coding to manage drive failures to avoid data loss effectively, but there could be other instances where we decide to upgrade drives from HDD to SDD for a particular customer's needs.
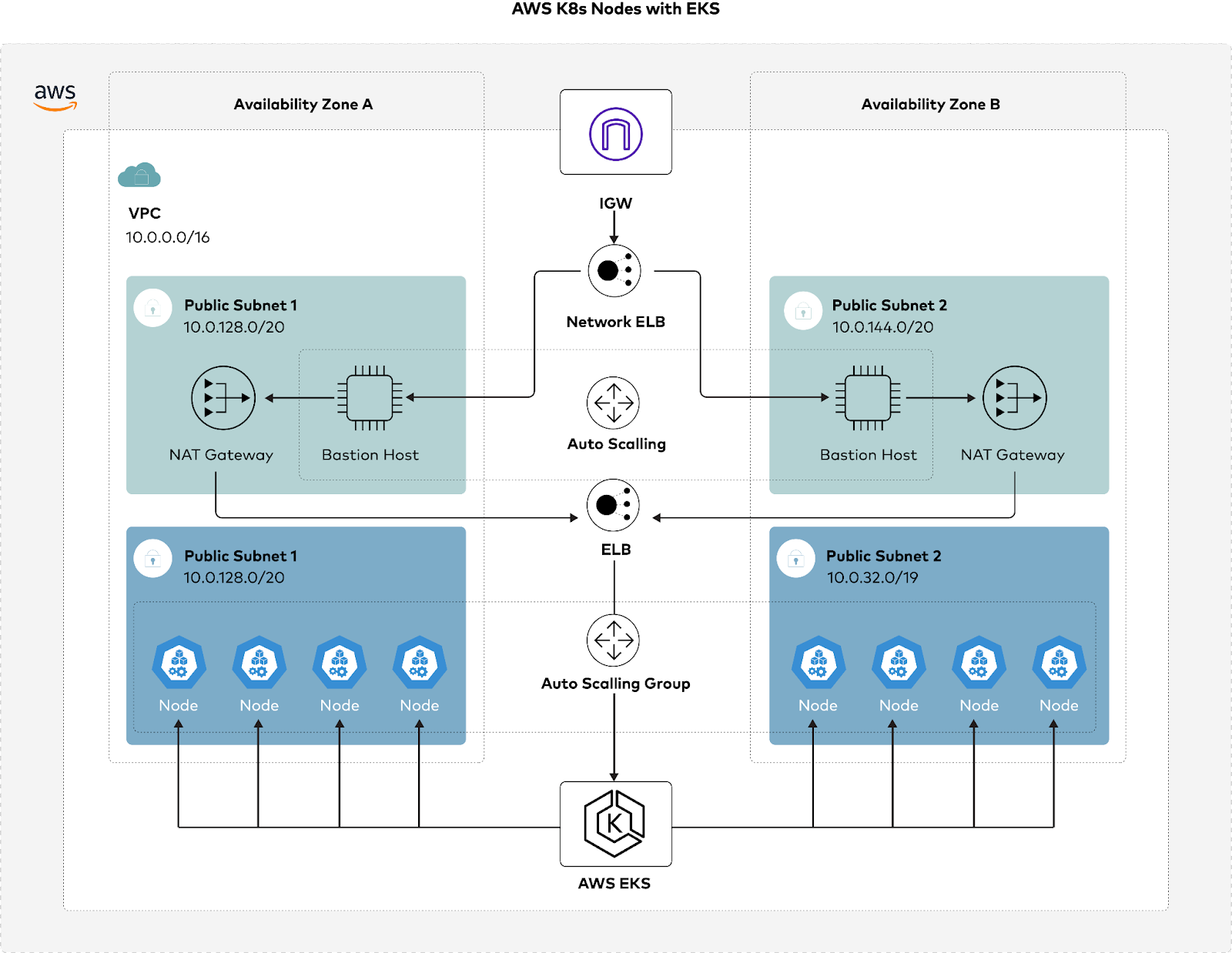
The key challenges with all these scenarios is, we want to avoid down time and protect ourselves from data loss. This is where containerized MinIO deployed onto Kubernetes is a huge advantage. Taking a Kubernetes Day 2 operations approach improves your ability to administer and update the cluster with all your workloads running on it. In this case let us continue with Amazon leveraging a managed Kubernetes cluster in EKS on AWS.
With Amazon EKS managed Kubernetes, the node groups get automated provisioning and lifecycle management of nodes. We don’t need to separately provision or register EC2 instances, every managed node is provisioned as part of an EC2 auto scaling group, which is managed for you by Amazon EKS. Every resource, including the instances and auto scaling groups runs within your AWS account. Each node group runs across multiple availability zones that you define.
We need to choose EBS-backed volumes so we are able to perform the instance migration with zero downtime and zero data loss. An eight node cluster with an EBS-backed drive each would be deployed as shown in the figure below:
Deploy MinIO containers onto the eks cluster leveraging MinIO Operator to simplify the deployment as shown here.
Once you have set up the cluster and MinIO is successfully deployed, we must generate some load on the platform. One of the ways we can achieve that is by leveraging WARP, a complete object storage benchmarking tool. Although the steps indicated in the WARP test might be too aggressive since it was defined for benchmarking, dialing down and creating a steady load is configurable.
Now let us look at how exactly we are going to leverage Kubernetes to perform the instance migration with zero downtime and zero data loss. For example, let us consider an EKS cluster deployment has c6gn.8xlarge EBS-backed instances with 50 Gbps network performance and you are experiencing a network bottleneck. You need to improve your cluster’s overall performance by switching to c6gn.16xlarge EBS-backed instances with 100 Gbps network performance (see table below for details).

The below diagram shows us how the instance migration process occurs.
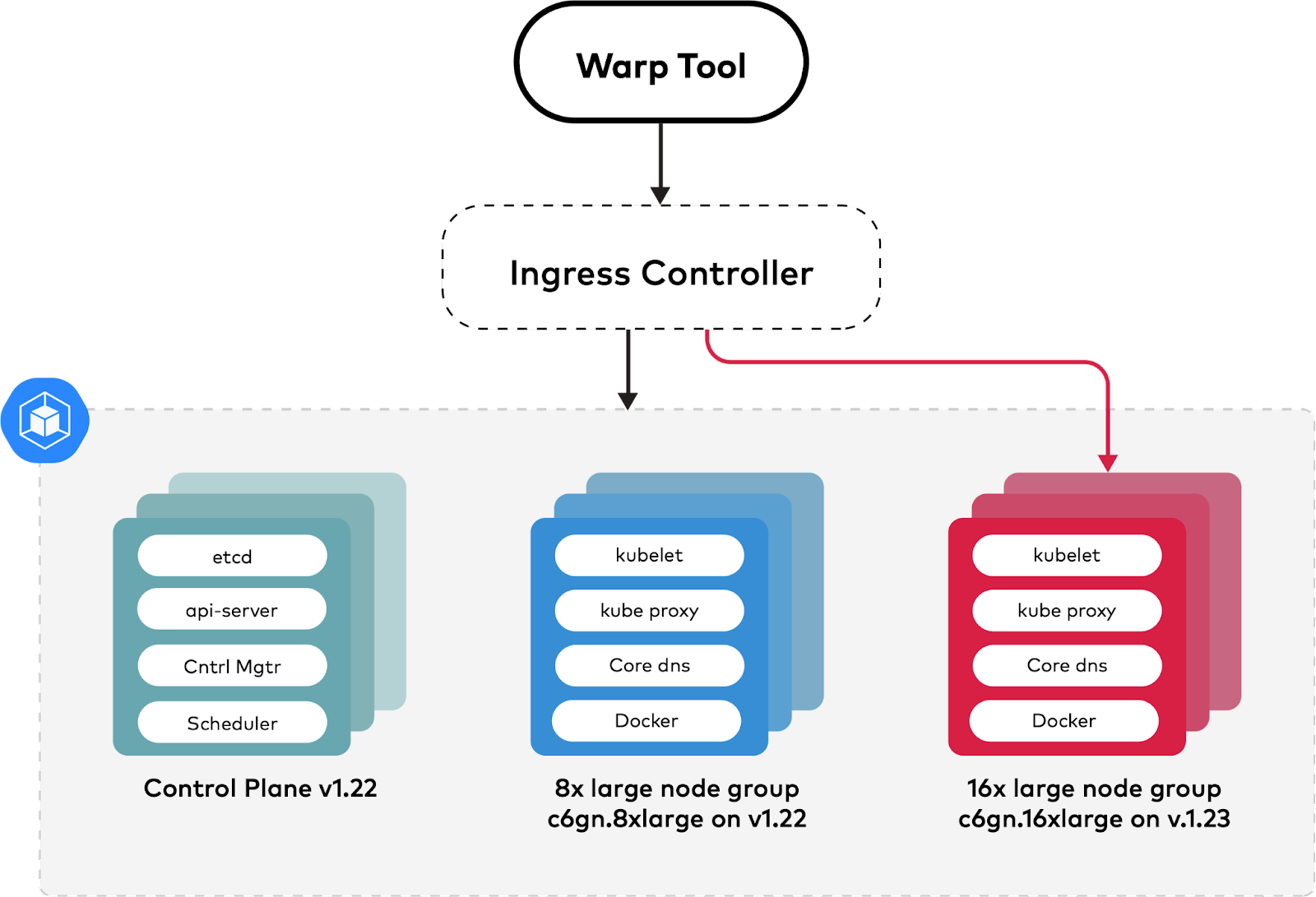
Once the cluster is up and running and WARP is generating load on MinIO, we can create the node group with a 16x large node group. Any number of automation techniques to bring up your Kubernetes service could be adopted. MinIO Operator simplifies deployment on the Kubernetes cluster and allows you to choose an appropriate amount of nodes and drives to meet your performance, capacity and resiliency needs. As mentioned earlier, deploying WARP is even simpler than the rest of this exercise, and we’re doing it to demonstrate that MinIO services will not be disrupted. With the MinIO cluster processing live traffic, let’s go ahead and create the Nodegroup with c6gn.16xlarge EBS-backed instances with the latest AWS machine image, ideally configured in accordance with (and blessed by your enterprise group) organization’s security policy.
With the 16x large node group created, you can migrate the ingress controller requests over to the 16x large node group by changing its node selector scheduling terms. This change updates the ingress controller deployment spec to require the use of c6gn.16xlarge nodes during scheduling, and forces a rolling update over to the 16x large node group. The ingress controller is able to successfully migrate across node groups because it is configured with HA settings, spread-type scheduling predicates, and can gracefully terminate within the Kubernetes pod lifecycle.
Once all the old pods are killed and the new pods are up and running in the node group, we are ready to terminate the old node group. Again, note that MinIO continues to read and write without service disruption.
Decommissioning the old node group involves these steps:
- Draining the Kubernetes nodes.
- Scaling down the auto scaling group to 0 for the node group.
- Deleting the node group.
This technique can be applied to AMI rehydration, instance upgrades and upgrading drives as well.
Performance Analysis of EBS-backed EC2 Instances vs Instance Store EC2 Instances
MinIO engineers conducted a thorough analysis of different types of nodes with local volumes and EBS backed volumes and other storage classes. Based on our analysis, EC2 instances with instance stores outperform EBS-backed instances by at least 1 GiB/s. Details are provided in the table below.
The key takeaway is that we cannot achieve the performance of the instances with local volumes, with EBS-backed instances with HDD (SC1 storage class) and SSD (GP2 storage class). We have to spend a little more to acquire GP3 storage class EBS volumes to achieve similar performance as instances with local volumes.
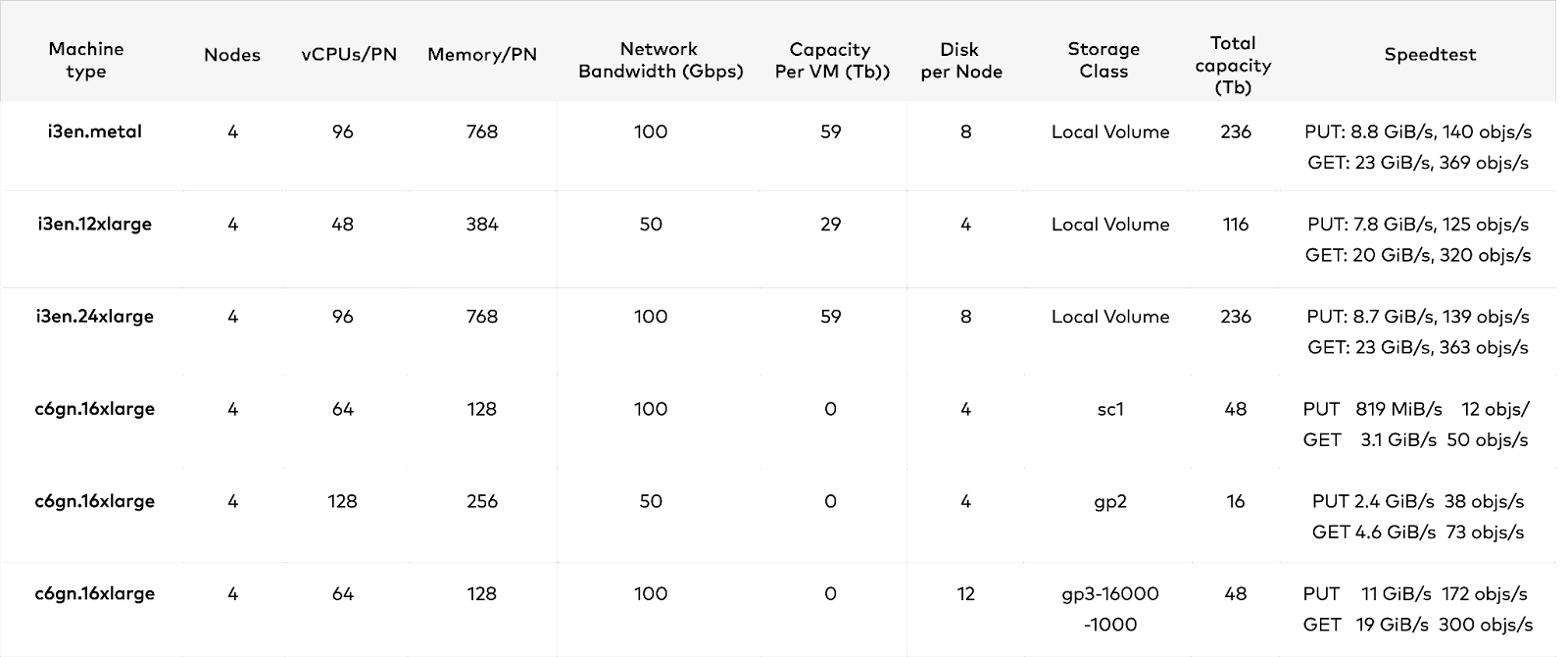
NOTE: These performance numbers are subject to conditions and configurations of the infrastructure creation and validations done with the constraints of our organization, obviously the conditions and configurations of each organization dictate the performance numbers. These results are to be taken as potential possible numbers and not as hard numbers for all use-cases and all customers.
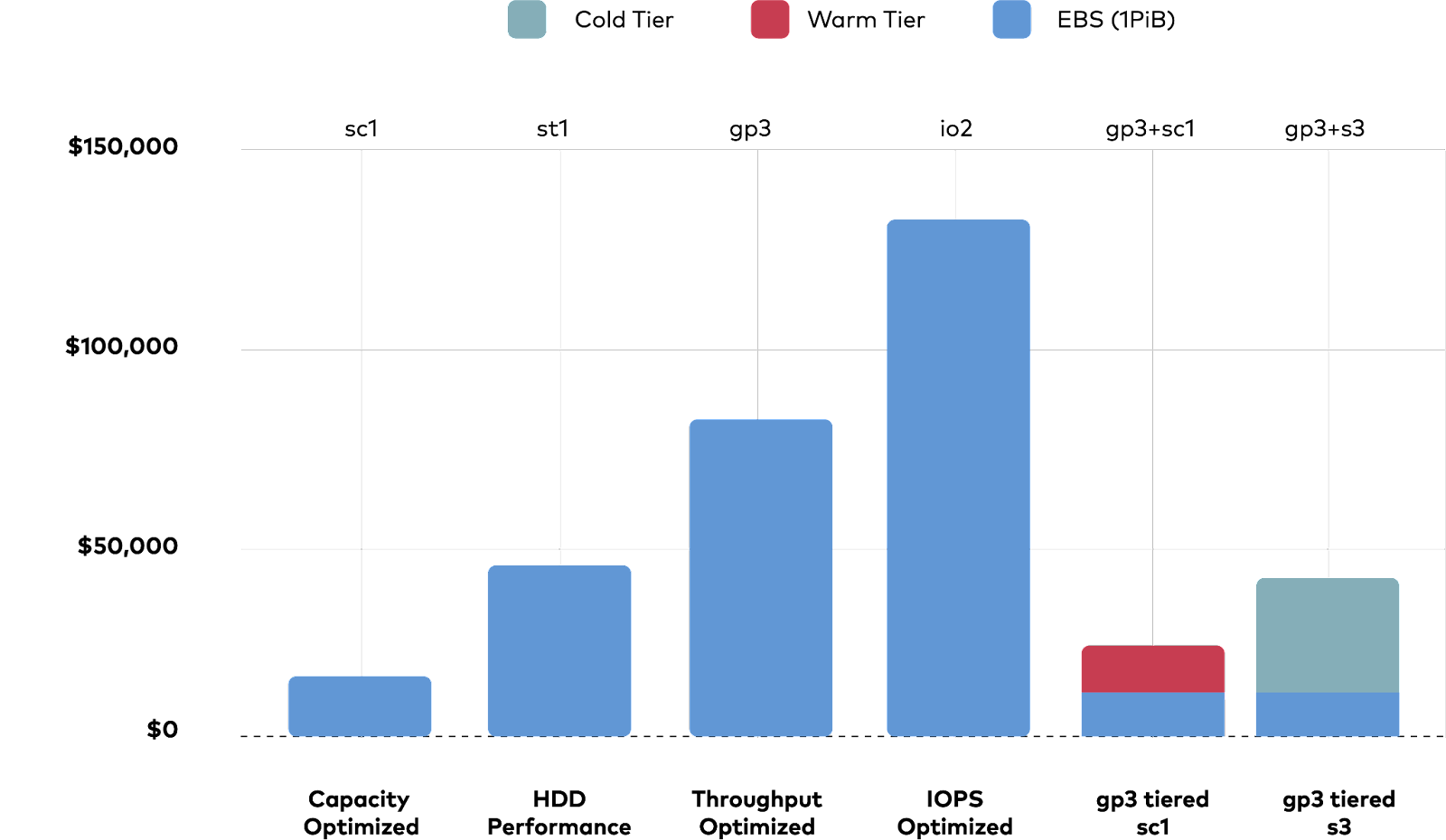
Cost Analysis of Instances with Local Volumes vs EBS-backed Volumes
Taking performance and cost of different storage classes into account, we see that leveraging a combination of GP3 and HDD warm tier would be more cost effective than EBS volumes of different storage classes. From the above instance performance assessment, we know to match the performance of the local volume instances, you would have to select EBS with storage class GP3 or IO2 - and they would cost significantly higher than tiering.
Conclusion
As with all architectural decisions there are pros and cons. Having a clear understanding of the pros and cons of leveraging high performance instance store (local volumes) deployments is critical when selecting instance types on EKS.
Ephemeral instances backed by local volumes provide better performance over ephemeral instances with EBS volumes.
MinIO running on local volumes can be expanded and/or upgraded without disruption leveraging other features like creating more pools of instances. However, EBS-backed volumes provided the ability to persist data and by detaching the volumes and attaching to nodes in a different nodegroup, allowing enterprises to reap the benefits of improved operations, zero downtime and zero data loss without suffering from the reduced performance or the increased cost associated with expensive EBS storage class.
Ultimately, business and enterprise goals drive these decisions. To go deeper, download MinIO and see for yourself or spin up a marketplace instance. You can find our AWS one here. As always you can continue the conversation on Slack or via hello@min.io.






