Backing Up Weaviate with MinIO S3 Buckets

Weaviate is a pioneering, open-source vector database, designed to enhance semantic search through the utilization of machine learning models. Unlike traditional search engines that rely on keyword matching, Weaviate employs semantic similarity principles. This innovative approach transforms various forms of data (texts, images, and more) into vector representations, numerical forms that capture the essence of the data’s context and meaning. By analyzing the similarities between these vectors, Weaviate delivers search results that truly understand the user’s intent, offering a significant leap beyond the limitations of keyword-based searches.
This guide aims to demonstrate the seamless integration of MinIO and Weaviate, leveraging the best of Kubernetes-native object storage and AI-powered semantic search capabilities. Leveraging Docker Compose for container orchestration, this guide provides a strategic approach to building a robust, scalable, and efficient data management system. Aimed at how we store, access, and manage data, this setup is a game-changer for developers, DevOps engineers, and data scientists seeking to harness the power of modern storage solutions and AI-driven data retrieval.
Introduction to the Tech Stack
In this demonstration, we'll be focusing on backing up Weaviate with MinIO buckets using Docker. This setup ensures data integrity and accessibility in our AI-enhanced search and analysis projects.
- MinIO for Storage: We're using MinIO as our primary storage platform. Known for its high performance and scalability, MinIO is adept at handling large volumes of data securely and efficiently. In this demo, you'll see how MinIO buckets are used to back up Weaviate data, ensuring that our system's integrity and performance remain uncompromised.
- Weaviate Vector Database: Central to this integration, Weaviate’s vector database empowers AI applications with its ability to perform semantic searches. By transforming unstructured data into meaningful vector representations, it enables applications to understand and interact with data in a deeply nuanced manner, paving the way for more intelligent and responsive AI-driven functionalities.
This demonstration aims to highlight the seamless integration of MinIO and Weaviate using Docker, showcasing a reliable method for backing up AI-enhanced search and analysis systems.
Resources
- All files are available via the GitHub minio/blog-assets/minio-weaviate-backups repository folder.
- docker-compose.yaml
- schema.json
- data.json
- s3_backup_module.ipynb
Knowledgeable Prerequisites
- Docker and Docker Compose installed on your machine.
- Basic understanding of Docker concepts and YAML syntax.
- Python environment for using the weaviate-client library.
- Command-line access for running commands such as curl.
Integration and Configuration with Docker Compose
The docker-compose.yaml file provided here is crafted to establish a seamless setup for Weaviate, highlighting our commitment to streamlined and efficient data management. This configuration enables a robust environment where MinIO acts as a secure storage service and Weaviate leverages this storage for advanced vector search capabilities.
The docker-compose.yaml provided below outlines the setup for Weaviate.
version: '3.8'
services:
weaviate:
container_name: weaviate_server
image: semitechnologies/weaviate:latest
ports:
- "8080:8080"
environment:
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
ENABLE_MODULES: 'backup-s3'
BACKUP_S3_BUCKET: 'weaviate-backups'
BACKUP_S3_ENDPOINT: 'play.min.io:443'
BACKUP_S3_ACCESS_KEY_ID: 'minioadmin'
BACKUP_S3_SECRET_ACCESS_KEY: 'minioadmin'
BACKUP_S3_USE_SSL: 'true'
CLUSTER_HOSTNAME: 'node1'
volumes:
- ./weaviate/data:/var/lib/weaviateDocker-Compose: Deploy Weaviate with backups-s3 module enabled and play.min.io MinIO server
Configuring Weaviate for S3 Backup
With the above docker-compose.yaml, Weaviate is intricately configured to utilize MinIO for backups, ensuring data integrity and accessibility. This setup involves essential environment variables such as ENABLE_MODULES set to backup-s3, and various settings for the S3 bucket, endpoint, access keys, and SSL usage. Additionally, the PERSISTENCE_DATA_PATH is set to ensure data is persistently stored, and CLUSTER_NAME for node identification.
Notable environment variables include:
ENABLE_MODULES: 'backup-s3'BACKUP_S3_BUCKET: 'weaviate-backups'BACKUP_S3_ENDPOINT: 'play.min.io:443'BACKUP_S3_ACCESS_KEY_ID: 'minioadmin'BACKUP_S3_SECRET_ACCESS_KEY: 'minioadmin'BACKUP_S3_USE_SSL: 'true'PERSISTENCE_DATA_PATH: '/var/lib/weaviate'CLUSTER_NAME: 'node1'
The Weaviate service in this docker-compose is set up to utilize mounted volumes for data persistence; this ensures that your data persists across sessions and operations.
Note: The MinIO bucket needs to exist beforehand, Weaviate will not create the bucket for you.
Deployment Steps
To integrate MinIO and Weaviate into your project using Docker Compose, follow this detailed procedure:
Saving or Updating the Docker Compose File
- New Setup: If this is a new setup, save the provided docker-compose.yaml file directly into your project’s working directory. This file is critical for configuring the services correctly.
- Existing Setup: If you’re updating an existing production environment, modify your current docker-compose.yaml to reflect the settings outlined above. Ensure that these settings are accurately replicated to connect to your services.
Running the Docker Compose File
Once the docker-compose.yaml file is in place, use the following command in your terminal or command prompt to initiate the deployment:
docker-compose up -d --build
This command will start the Weaviate services in detached mode, running them in the background of your system.
Understanding Persistent Directories
- During the build and execution process, Docker Compose will create a persistent directory as specified in the docker-compose.yaml file. This directory (
./weaviate/datafor Weaviate) is used for storing data persistently, ensuring that your data remains intact across container restarts and deployments.
The persistent storage allows for a more stable environment where data is not lost when the container is restarted.
Once you’ve deployed your docker-compose you can visit your Weaviate server’s URL in a browser, followed by /v1/meta to examine if your deployment configurations are correct.
The first line of the JSON payload at http://localhost:8080/v1/meta should look like this:
{"hostname":"http://[::]:8080","modules":{"backup-s3":{"bucketName":"weaviate-backups","endpoint":"play.min.io:443","useSSL":true}...[truncated]...}Configuring MinIO: Access Policy for weaviate-backups Bucket
To integrate Weaviate with MinIO, the backup bucket in MinIO appropriately needs the Access Policy of the designated backup bucket, namely weaviate-backups, to Public. This adjustment is necessary to grant the Weaviate backup-s3 module the required permissions to successfully interact with the MinIO bucket for backup operations.
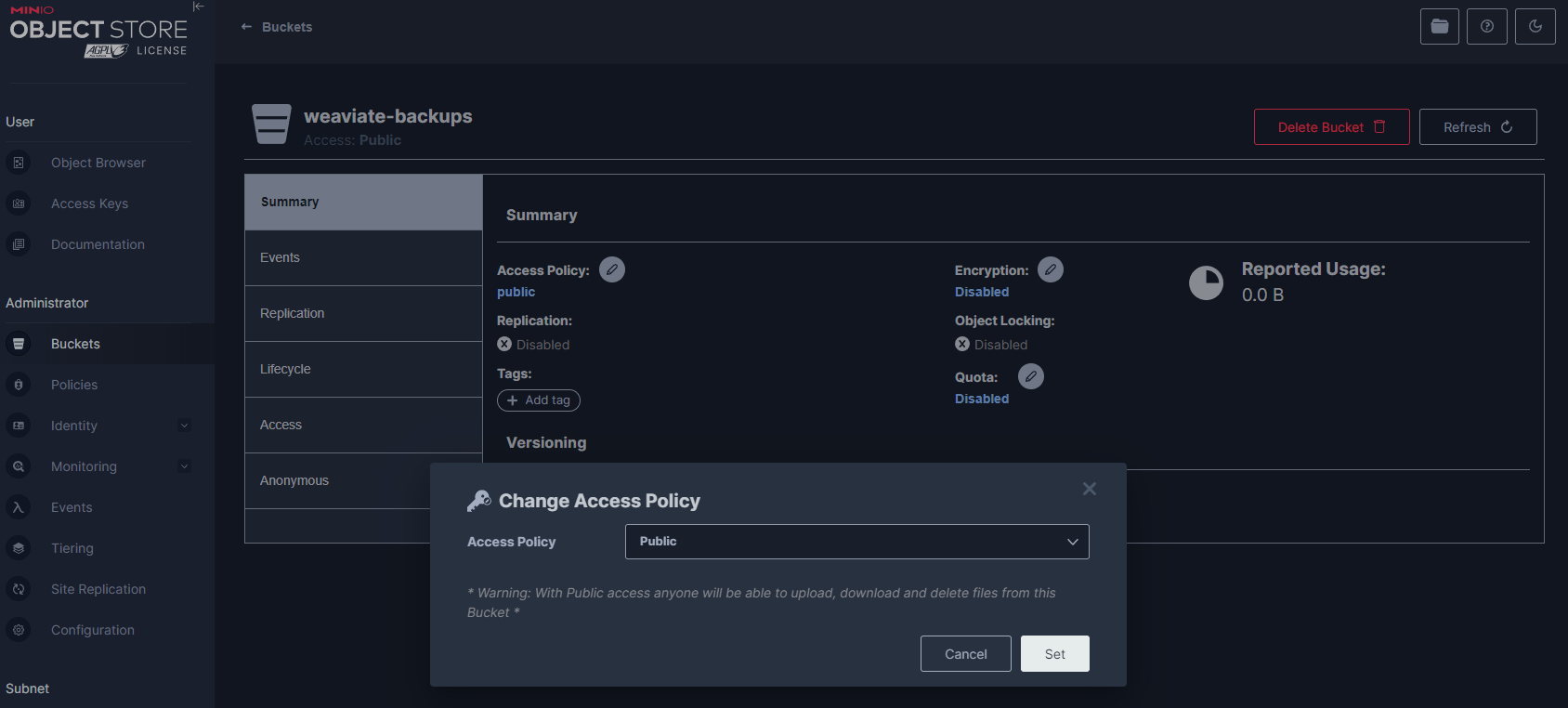
weaviate-backups bucket Access PolicyNote: In a production environment you probably need to lock this down, which is beyond the scope of this tutorial.
It's essential to approach this configuration with a clear understanding of the security implications of setting a bucket to “public”. While this setup facilitates the backup process in a development environment, alternative approaches should be considered for production systems to maintain data security and integrity. Employing fine-grained access controls, such as IAM policies or “presigned” URLs.
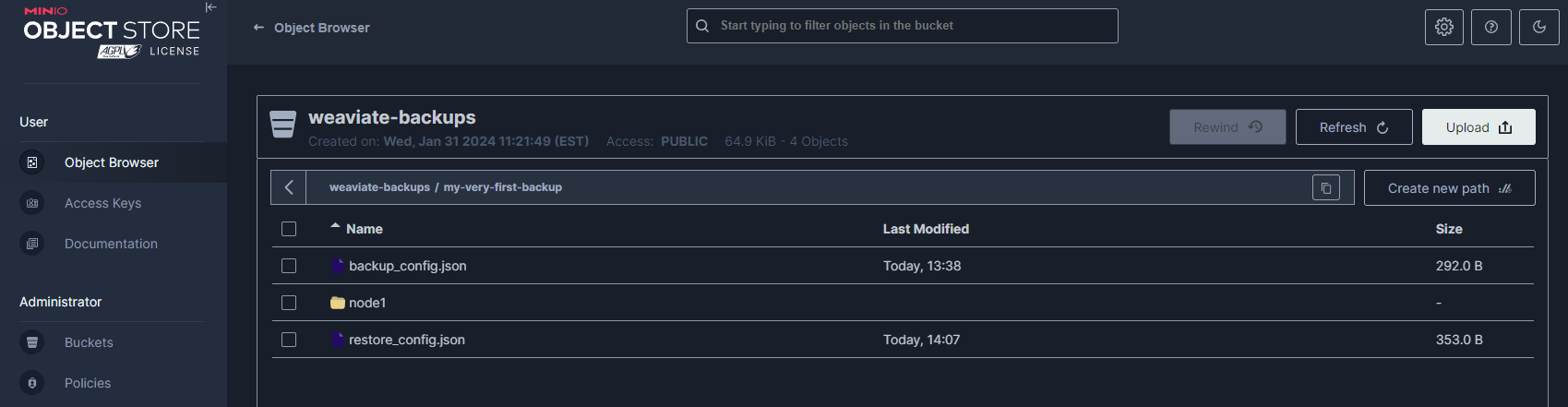
weaviate-backups bucketBy the end of this demonstration you will be able to see the bucket objects that Weaviate creates throughout the process when utilizing the backup-s3 module.
Outlining the Process using Python
To enable S3 backups in Weaviate, set the necessary environment variables in your docker-compose.yaml file. This directs Weaviate to use MinIO as the backup destination, involving settings for backup modules and MinIO bucket details.
Before diving into the technical operations I would like to state that I am demonstrating the following steps in a JupyterLab environment for the added benefit of encapsulating our pipeline in a notebook, available here.
The first step involves setting up the environment by installing the weaviate-client library for python with pip. This Python package is essential for interfacing with Weaviate's RESTful API in a more Pythonic way, allowing for seamless interaction with the database for operations such as schema creation, data indexing, backup, and restoration. For the demonstration, we’ll illustrate using the Weaviate Python client library.
In this demonstration we are using Weaviate V3 API so you might see message like the one below when you run the python script:
|
`DeprecationWarning: Dep016: You are using the Weaviate v3 client, which is deprecated. |
This message is a warning banner and can be ignored, for more information you can visit this article on the Weaviate blog.
Outline of Python Steps:
- Install weaviate-client Library
- Client initialization
- Schema creation
- Data insertion
- Backup initiation
- Data restoration
1. Installation of Weaviate-Client Library
!pip install weaviate-client2. Importing Schema Classes for Article & Author
This section introduces the data structure and schema for 'Article' and 'Author' classes, laying the foundation for how data will be organized. It demonstrates how to programmatically define and manage the schema within Weaviate, showcasing the flexibility and power of Weaviate to adapt to various data models tailored to specific application needs.
import weaviate
client = weaviate.Client("http://localhost:8080")
# Schema classes to be created
schema = {
"classes": [
{
"class": "Article",
"description": "A class to store articles",
"properties": [
{"name": "title", "dataType": ["string"], "description": "The title of the article"},
{"name": "content", "dataType": ["text"], "description": "The content of the article"},
{"name": "datePublished", "dataType": ["date"], "description": "The date the article was published"},
{"name": "url", "dataType": ["string"], "description": "The URL of the article"},
{"name": "customEmbeddings", "dataType": ["number[]"], "description": "Custom vector embeddings of the article"}
]
},
{
"class": "Author",
"description": "A class to store authors",
"properties": [
{"name": "name", "dataType": ["string"], "description": "The name of the author"},
{"name": "articles", "dataType": ["Article"], "description": "The articles written by the author"}
]
}
]
}
client.schema.delete_class('Article')
client.schema.delete_class('Author')
client.schema.create(schema)Python: create schema classes
3. Setup of Schema and Data
After defining the schema, the notebook guides through initializing the Weaviate client, creating the schema in the Weaviate instance, and indexing the data. This process populates the database with initial data sets, enabling the exploration of Weaviate's vector search capabilities. It illustrates the practical steps needed to start leveraging Weaviate for storing and querying data in a vectorized format.
# JSON data to be Ingested
data = [
{
"class": "Article",
"properties": {
"title": "LangChain: OpenAI + S3 Loader",
"content": "This article discusses the integration of LangChain with OpenAI and S3 Loader...",
"url": "https://blog.min.io/langchain-openai-s3-loader/",
"customEmbeddings": [0.4, 0.3, 0.2, 0.1]
}
},
{
"class": "Article",
"properties": {
"title": "MinIO Webhook Event Notifications",
"content": "Exploring the webhook event notification system in MinIO...",
"url": "https://blog.min.io/minio-webhook-event-notifications/",
"customEmbeddings": [0.1, 0.2, 0.3, 0.4]
}
},
{
"class": "Article",
"properties": {
"title": "MinIO Postgres Event Notifications",
"content": "An in-depth look at Postgres event notifications in MinIO...",
"url": "https://blog.min.io/minio-postgres-event-notifications/",
"customEmbeddings": [0.3, 0.4, 0.1, 0.2]
}
},
{
"class": "Article",
"properties": {
"title": "From Docker to Localhost",
"content": "A guide on transitioning from Docker to localhost environments...",
"url": "https://blog.min.io/from-docker-to-localhost/",
"customEmbeddings": [0.4, 0.1, 0.2, 0.3]
}
}
]
for item in data:
client.data_object.create(
data_object=item["properties"],
class_name=item["class"]
)Python: index data by class
4. Creating a Backup
With the data indexed, the focus shifts to preserving the state of the database through backups. This part of the notebook shows how to trigger a backup operation to MinIO.
result = client.backup.create(
backup_id="backup-id",
backend="s3",
include_classes=["Article", "Author"], # specify classes to include or omit this for all classes
wait_for_completion=True,
)
print(result)Python: create backup
Expect:
{'backend': 's3', 'classes': ['Article', 'Author'], 'id': 'backup-id-2', 'path': 's3://weaviate-backups/backup-id-2', 'status': 'SUCCESS'}Successful Backup Response
5. Deleting Schema Classes for Restoring Purposes
Before proceeding with a restoration, it's sometimes necessary to clear the existing schema. This section shows the steps for a clean restoration process. This ensures that the restored data does not conflict with existing schemas or data within the database.
client.schema.delete_class("Article")
client.schema.delete_class("Author")6. Restoring the Backup
This section explains how to restore the previously backed-up data, bringing the database back to a known good state.
result = client.backup.restore(
backup_id="backup-id",
backend="s3",
wait_for_completion=True,
)
print(result)Python: restore backup
Expect:
{'backend': 's3', 'classes': ['Article', 'Author'], 'id': 'backup-id', 'path': 's3://weaviate-backups/backup-id', 'status': 'SUCCESS'}Successful Backup-S3 Response
Error Handling During Restoration
This part of the notebook provides an example of implementing error handling during the backup restoration process. It offers insights into unexpected issues during data restoration operations.
from weaviate.exceptions import BackupFailedError
try:
result = client.backup.restore(
backup_id="backup-id",
backend="s3",
wait_for_completion=True,
)
print("Backup restored successfully:", result)
except BackupFailedError as e:
print("Backup restore failed with error:", e)
# Here you can add logic to handle the failure, such as retrying the operation or logging the error.Expect:
Backup restored successfully: {'backend': 's3', 'classes': ['Author', 'Article'], 'id': 'backup-id', 'path': 's3://weaviate-backups/backup-id', 'status': 'SUCCESS'}Successful Backup Restoration
Verifying Restoration Success
Finally, to confirm that the backup and restoration process completed successfully, the notebook includes a step to retrieve the schema of the 'Article' class. This verification ensures that the data and schema are correctly restored.
client.schema.get("Article")Returns the Article class as a JSON object
Expect:
{'class': 'Article', 'description': 'A class to store articles'... [Truncated]...}Each section of the notebook provides a comprehensive guide through the lifecycle of data management in Weaviate, from initial setup and data population to backup, restoration, and verification, all performed within the Python ecosystem using the Weaviate-client library.
Outlining the Process using curl
So far we’ve shown you how to do this the Pythonic way. We thought it would be helpful to show internally via CURL how the same operations could be achieved without writing a script.
To interact with a Weaviate instance for tasks such as creating a schema, indexing data, performing backups, and restoring data, specific curl commands can be used. These commands make HTTP requests to Weaviate's REST API. For instance, to create a schema, a POST request with the schema details is sent to Weaviate's schema endpoint. Similarly, to index data, a POST request with the data payload is made to the objects endpoint.
Backups are triggered through a POST request to the backups endpoint, and restoration is done via a POST request to the restore endpoint. Each of these operations requires the appropriate JSON payload, typically provided as a file reference in the curl command using the @ symbol.
In order to implement Weaviate we of course will require sample data to work with, which
I’ve included the following:
schema.jsonoutlines the structure of the data we want to index.data.jsonis where our actual data comes into play, its structure aligns with the classes in the schema.json file.
The schema.json and data.json files are available in the MinIO blog-assets repository located here.
schema.json
{
"classes": [
{
"class": "Article",
"description": "A class to store articles",
"properties": [
{"name": "title", "dataType": ["string"], "description": "The title of the article"},
{"name": "content", "dataType": ["text"], "description": "The content of the article"},
{"name": "datePublished", "dataType": ["date"], "description": "The date the article was published"},
{"name": "url", "dataType": ["string"], "description": "The URL of the article"},
{"name": "customEmbeddings", "dataType": ["number[]"], "description": "Custom vector embeddings of the article"}
]
},
{
"class": "Author",
"description": "A class to store authors",
"properties": [
{"name": "name", "dataType": ["string"], "description": "The name of the author"},
{"name": "articles", "dataType": ["Article"], "description": "The articles written by the author"}
]
}
]
}Example schema classes for Article and Author
The schema.json file outlines the structure of the data to be indexed, detailing the classes, properties, and their data types, effectively setting the stage for how data is organized and interacted with within Weaviate. This schema acts as a blueprint for the AI to understand and categorize the incoming data, ensuring that the vector search engine can operate with precision and relevance.
On the other hand, the data.json file populates this schema with actual instances of data, mirroring real-world applications and scenarios. This sample data illuminates the potential of Weaviate's search capabilities, offering a hands-on experience that showcases how queries are resolved and how results are dynamically generated based on the AI's understanding of the content.
data.json
[
{
"class": "Article",
"properties": {
"title": "LangChain: OpenAI + S3 Loader",
"content": "This article discusses the integration of LangChain with OpenAI and S3 Loader...",
"url": "https://blog.min.io/langchain-openai-s3-loader/",
"customEmbeddings": [0.4, 0.3, 0.2, 0.1]
}
},
{
"class": "Article",
"properties": {
"title": "MinIO Webhook Event Notifications",
"content": "Exploring the webhook event notification system in MinIO...",
"url": "https://blog.min.io/minio-webhook-event-notifications/",
"customEmbeddings": [0.1, 0.2, 0.3, 0.4]
}
},
{
"class": "Article",
"properties": {
"title": "MinIO Postgres Event Notifications",
"content": "An in-depth look at Postgres event notifications in MinIO...",
"url": "https://blog.min.io/minio-postgres-event-notifications/",
"customEmbeddings": [0.3, 0.4, 0.1, 0.2]
}
},
{
"class": "Article",
"properties": {
"title": "From Docker to Localhost",
"content": "A guide on transitioning from Docker to localhost environments...",
"url": "https://blog.min.io/from-docker-to-localhost/",
"customEmbeddings": [0.4, 0.1, 0.2, 0.3]
}
}
]Sample data containing articles
Setting Up with curl
The schema acts as the structural backbone of our data management system, defining how data is organized, indexed, and queried.
Creating a Weaviate Schema
Through a simple curl command, and with our sample files cloned locally to our current working directory; we can post our schema.json directly to Weaviate, laying down the rules and relationships that our data will adhere to.
curl -X POST -H "Content-Type: application/json" \
--data @schema.json http://localhost:8080/v1/schemaCURL: create
Populating the Schema: Indexing Data
With our schema in place, the next step involves populating it with actual data. Using another curl command, we index our data.json into the schema.
curl -X POST -H "Content-Type: application/json" \
--data @data.json http://localhost:8080/v1/objectsCURL: index
Ensuring Data Durability: Backing Up with MinIO
We will need to assign a unique identifier, or "backup-id". This identifier not only facilitates the precise tracking and retrieval of backup sets but also ensures that each dataset is version controlled.
curl -X POST 'http://localhost:8080/v1/backups/s3' -H 'Content-Type:application/json' -d '{
"id": "backup-id",
"include": [
"Article",
"Author"
]
}' CURL: backup-s3
Expect:
{'backend': 's3', 'classes': ['Article', 'Author'], 'id': 'backup-id', 'path': 's3://weaviate-backups/backup-id', 'status': 'SUCCESS'}Successful Backup-S3 Response
This output is formatted as a JSON object. It includes the backend used (in this case, ‘s3’), a list of classes that were included in the backup ('Article', 'Author'), the unique identifier id given to the backup ('backup-id'), the path indicating where the backup is stored within the S3 bucket (s3://weaviate-backups/backup-id), and the status of the operation ('SUCCESS').
This structured response not only confirms the successful completion of the backup process but also provides essential information that can be used for future reference, auditing, or restoration processes.
Data Restoration Process
The restoration of data within the Weaviate ecosystem is facilitated through a structured API call, via a POST request targeting the /v1/backups/s3/backup-id/restore endpoint, identified by backup-id. This curl call not only restores the lost or archived data but allows you to maintain continuity.
curl -X POST 'http://localhost:8080/v1/backups/s3/backup-id/restore' \
-H 'Content-Type:application/json' \
-d '{
"id": "backup-id",
"exclude": ["Author"]
}'CURL: restore
Expect:
{
"backend": "s3",
"classes": ["Article"],
"id": "backup-id",
"path": "s3://weaviate-backups/backup-id",
"status": "SUCCESS"
}Successful restoration response
Each of these commands should be adapted based on your specific setup and requirements. You may need to modify endpoint URLs, data file paths, and other parameters as needed. Also, ensure that the necessary files (schema.json, data.json) and configurations are available in your environment.
Additional Notes about Weaviate
Automations with GitOps
By codifying everything in Git, teams can easily track changes, rollback to previous states, and ensure consistency across environments. GitOps workflows can be integrated with continuous integration/continuous deployment (CI/CD) tools and Kubernetes, further simplifying the orchestration of containerized applications and infrastructure management. We’ll go into detail in a future post on how to automate using GitOps.
Partial Backups and Restores
Weaviate allows backing up or restoring specific classes, which is useful for cases like partial data migration or development testing.
Multi-node Backups: For multi-node setups, especially in Kubernetes environments, ensure that your configuration correctly specifies the backup module (like backup-s3 for MinIO) and the related environment variables.
Troubleshooting
If you encounter issues during backup or restore, check your environment variable configurations, especially related to SSL settings for S3-compatible storage like MinIO. Disabling SSL (BACKUP_S3_USE_SSL: false) might resolve certain connection issues.
A Robust and Scalable Backup Solution for Weaviate with MinIO
As we wrap up this exploration of integrating Weaviate with MinIO using Docker Compose, it’s evident that this combination is not just a technical solution, but a strategic enhancement to data management. This integration aligns perfectly with MinIO’s commitment to providing scalable, secure, and high-performing data storage solutions, now amplified by Weaviate’s AI-driven capabilities. The use of Docker Compose further streamlines this integration, emphasizing our focus on making complex technologies accessible and manageable.
As always, the MinIO team remains committed to driving innovation in the field of data management. Our dedication to enhancing and streamlining the way data is stored, accessed, and analyzed stands at the core of our mission.
By bringing together the advanced vector database capabilities of Weaviate with the robust storage solutions provided by MinIO, users are empowered to unlock the full potential of their data. This includes leveraging semantic search functionalities that ensure not only the accessibility of data but also its security at the foundational level.
We are truly inspired by the remarkable innovation that springs from the minds of dedicated and passionate developers like you. It excites us to offer our support and be part of your journey towards exploring advanced solutions and reaching new heights in your data-driven projects. Please, don't hesitate to reach out to us on Slack, whether you have questions or just want to say hello.






