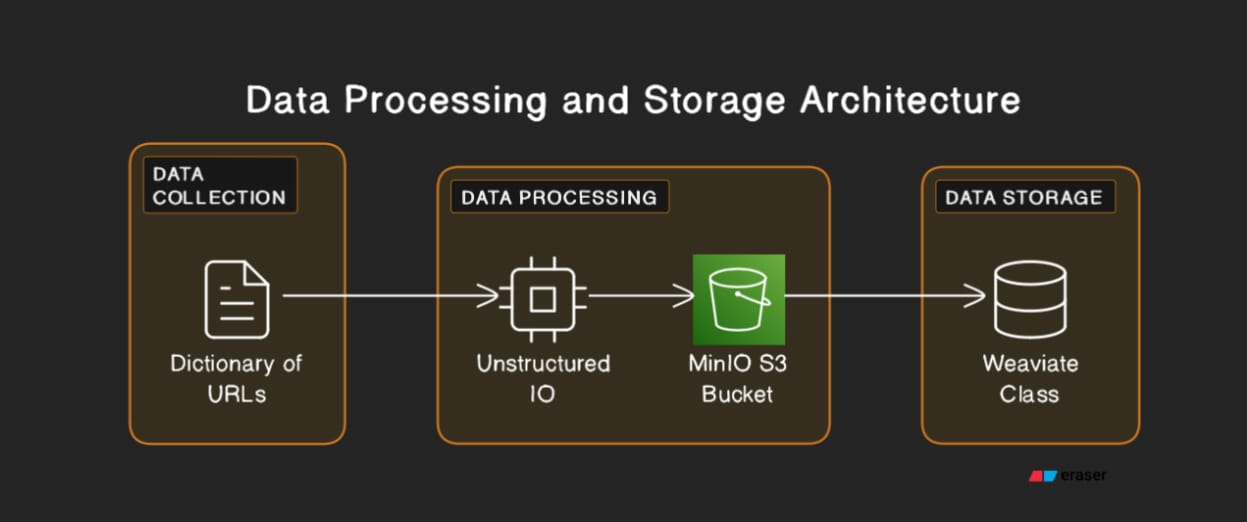
Dynamic ETL Pipeline: Hydrate AI with Web Data for MinIO and Weaviate using Unstructured-IO

In modern-day data-driven landscapes, the web is an endless source of information, offering vast potential for insight and innovation. However, the challenge lies in extracting, structuring, and analyzing this vast sea of data to make it actionable. This is where the innovation of Unstructured-IO, combined with the robust capabilities of MinIO’s object storage and Weaviate’s AI and metadata functionalities, steps in. Together, they create a dynamic ETL pipeline capable of transforming unstructured web data into a structured, analyzable format.
This article explores how the integration of these powerful technologies revolutionizes data hydration and analysis, providing a comprehensive solution that not only manages but also extracts tangible value from the deluge of web-generated content. By leveraging Unstructured-IO’s dynamic processing tool designed to intelligently parse and structure vast quantities of unstructured data, we are at the forefront of an evolution, illustrating a holistic approach to Dynamic ETL that is reshaping the landscape of data management and insight generation.
Unveiling the Potential of Unstructured-IO
The process begins with Unstructured-IO, a powerful tool designed to sift through the chaos of unstructured web data, extracting valuable information and converting it into a structured format. This is crucial for businesses and researchers who rely on web-generated content, but face hurdles in managing and analyzing it effectively.
Next, MinIO comes into play, providing the object storage solution that ensures the structured data is stored securely and efficiently. Its high performance and compatibility with existing tools make it an ideal backbone for handling the volumes of data processed by Unstructured-IO.
Finally, Weaviate enriches structured data with AI and metadata capabilities, transforming plain text into rich custom objects. This enhancement turns data into deeply contextualized insights, elevating decision-making and innovation.
A Practical Application
Imagine you come across valuable content on the web. With just a push of a button from an iOS shortcut, this content is captured, processed, and stored. This isn’t just about saving links; it’s about enriching your data ecosystem in real-time, making every piece of information immediately accessible and analyzable.
This dynamic ETL pipeline is not just a theoretical construct but a practical tool already enhancing data workflows. It exemplifies how modern solutions can tackle the deluge of web-generated data, transforming it into a structured, valuable asset for any organization.
By integrating Unstructured-IO with MinIO and Weaviate, we’re not just managing data; we’re unlocking its full potential, making it easier for you to derive meaningful insights from the vastness of the web. This is the future of data management and analysis, streamlined, secure, and intelligent, ready to elevate your projects to the next level.
Revolutionizing Data Hydration with Unstructured-IO
When mirroring the success of D-ETL in healthcare, Unstructured-IO redefines the process of data hydration for web-generated content. By seamlessly converting unstructured data into a structured, analyzable format, it not only enhances data quality and volume but also sets the stage for groundbreaking insights and AI-driven initiatives. This transformation is pivotal for businesses and researchers alike, offering a scalable solution for the efficient management and analysis of data in the digital era.
For an in-depth exploration of the Dynamic ETL approach and its application in healthcare data management, refer to the study titled “Dynamic-ETL: a hybrid approach for health data extraction, transformation and loading”, available at PubMed Central. This study exemplifies the innovative methods used to overcome the challenges of harmonizing electronic health records (EHRs) for clinical research networks.
Preparing the Development Environment
The initial phase of our D-ETL pipeline setup is crucial, focusing on equipping our development environment with the essential Python libraries. This step is executed via pip install, which installs the following three packages:
- weaviate-client: Facilitates direct interaction with Weaviate, enabling us to leverage its sophisticated AI-driven search functionalities.
- unstructured: Offers robust tools for the transformation of unstructured data into a format that's ready for analysis and storage.
- minio: Connects our workflow to MinIO, providing a seamless interface to interact with our object storage server, where our data will be securely stored.
|
pip install weaviate-client unstructured minio |
By integrating these packages into our environment, we ensure that our pipeline is fully equipped for the tasks ahead.
This setup not only lays the groundwork for efficient data extraction, transformation, and loading processes but also opens the door to innovative data management solutions. With these tools at our disposal, we're ready to embark on a journey of seamless data processing, from the initial extraction of web content to the final storage and analysis stages.
The demonstrated code, showcasing the integration and usage of MinIO, Weaviate, and unstructured, will be available for review and exploration here.
Initializing Clients
Establishing a solid foundation for the ETL process begins with the initialization of our MinIO and Weaviate clients.
|
from minio import Minio |
This process involves configuring each client with specific parameters such as access credentials and connection URIs.
Data Extraction and Transformation with Unstructured-IO’s Auto-Partitioning
This stage involves dynamically fetching web data, and utilizing a combination of requests for web scraping and Unstructured-IO for partitioning the content into manageable segments.
The code begins by importing necessary libraries—requests for HTTP operations, re for regex operations aiding in sanitizing of our URLs for a more descriptive object naming, io for handling byte streams, and unstructured.partition.auto for intelligently breaking down complex web content into structured data.
Two key helper functions, sanitize_url_to_object_name and prepare_text_for_tokenization, are employed to clean URLs and text content, ensuring the output is in a standardized format conducive to analysis. The sanitize_url_to_object_name function modifies URLs to create unique, filesystem-friendly names for each content piece, facilitating organized storage. The prepare_text_for_tokenization further cleans the text data, stripping unnecessary whitespace and preparing it for deeper analysis or AI processing.
|
import requests "https://unstructured.io/blog" |
This structured approach not only streamlines the ingestion of web data into our system but also lays the groundwork for subsequent stages, where this data will be stored in MinIO and indexed in Weaviate. By carefully selecting URLs as data sources, the process ensures a rich, varied dataset is available for exploration, ready to drive insights and decision-making in a wide array of contexts.
Loading to MinIO
This step is for ensuring that the newly structured and cleaned data is preserved in an organized manner, facilitating easy access for future analysis.
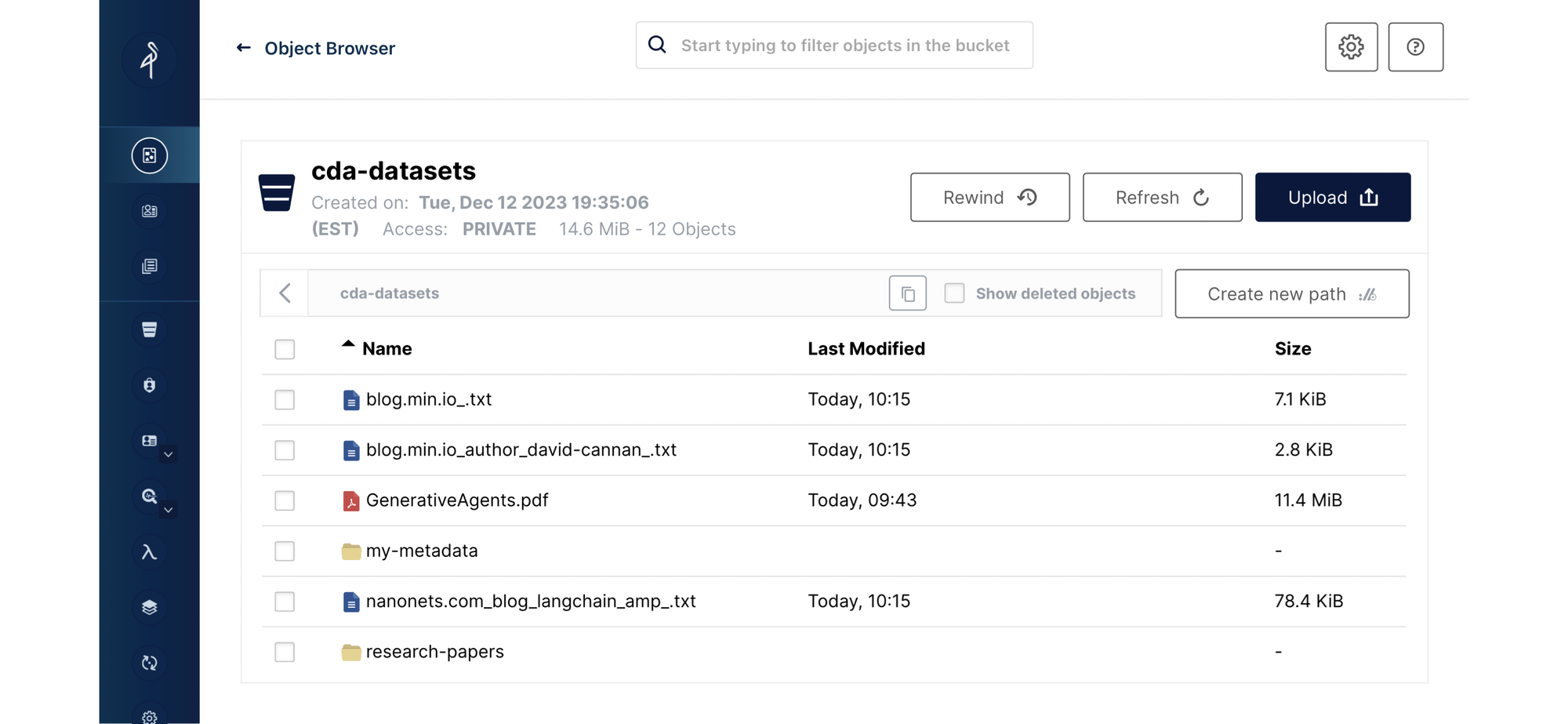
After data undergoes transformation, the next step involves securely storing it within MinIO, a process depicted in the following code-block:
|
bucket_name = "cda-datasets" |
The script automates the checking for an existing MinIO bucket or creates a new one if necessary, demonstrating the pipeline’s preparedness to handle data efficiently.
|
for url in urls: |
By systematically processing and uploading each data piece into MinIO, the approach underscores the importance of reliable storage solutions in maintaining the integrity and availability of data for subsequent retrieval and analytical endeavors.
Streamlining Data Utilization with Weaviate
After the data has been transformed, the next step is to funnel this refined information into Weaviate.
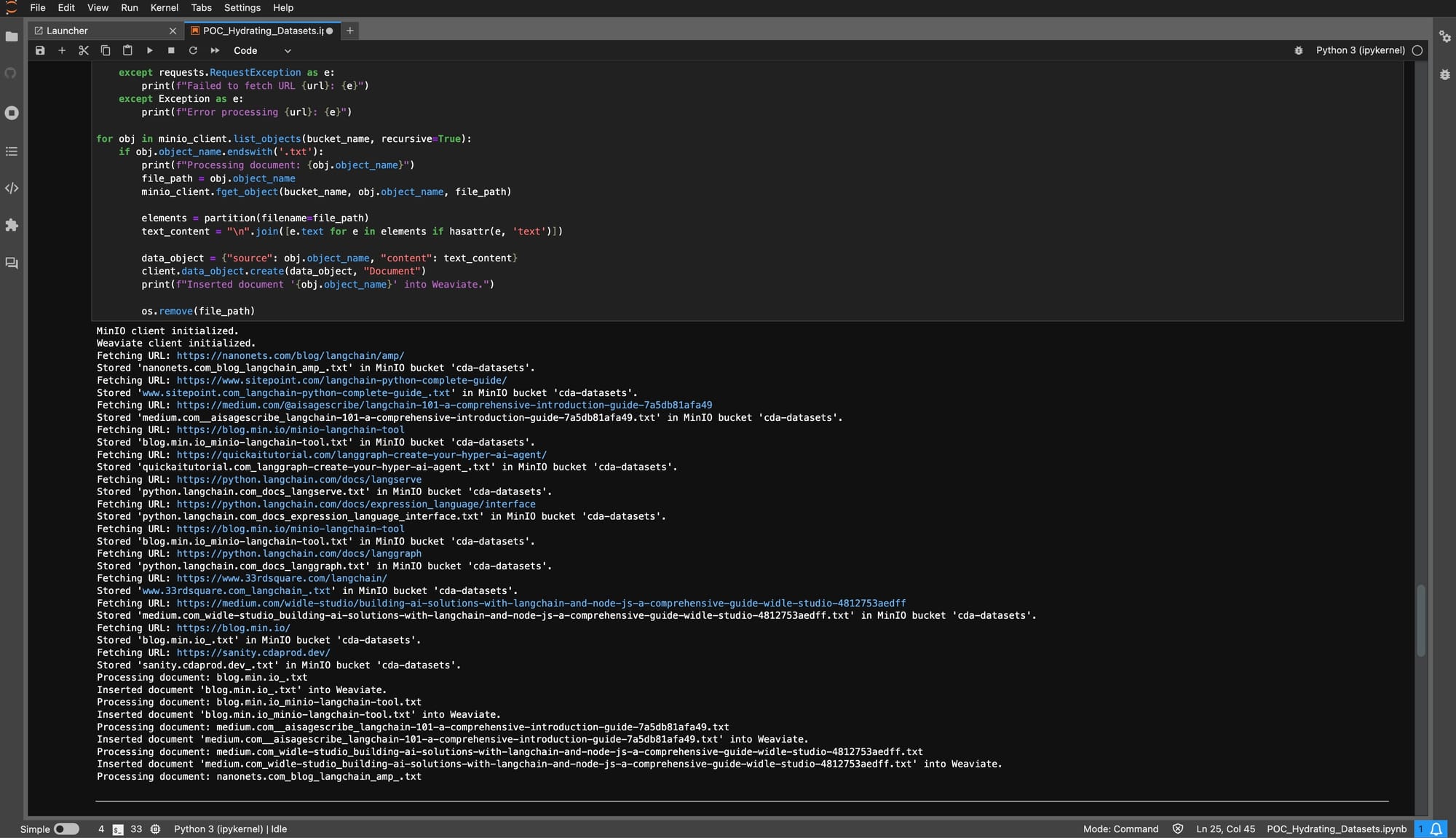
This phase is required for augmenting the data with Weaviate’s advanced search capabilities and securing it within an efficient storage system. The Python code snippet outlines a systematic approach for importing transformed data, specifically text files, into Weaviate from MinIO.
The process not only showcases the seamless integration between the storage and search platforms but also highlights the practical application of the Dual ETL pipeline in enhancing data accessibility and analytical readiness.
|
for obj in minio_client.list_objects(bucket_name, recursive=True): |
This segment of the pipeline emphasizes the transformation of static data into dynamic, searchable assets within Weaviate. By embedding the data within Weaviate’s contextually aware environment, it unlocks the potential for nuanced query capabilities and data-driven insights. This step encapsulates the essence of the Dual ETL approach—leveraging the combined strength of MinIO’s scalable storage and Weaviate’s intelligent search to foster a data ecosystem that is both robust and responsive to analytical queries.
Querying Weaviate—Finalizing Our Data Process
The concluding phase in our data pipeline employs Weaviate’s semantic search capabilities, querying the transformed data to extract meaningful insights.
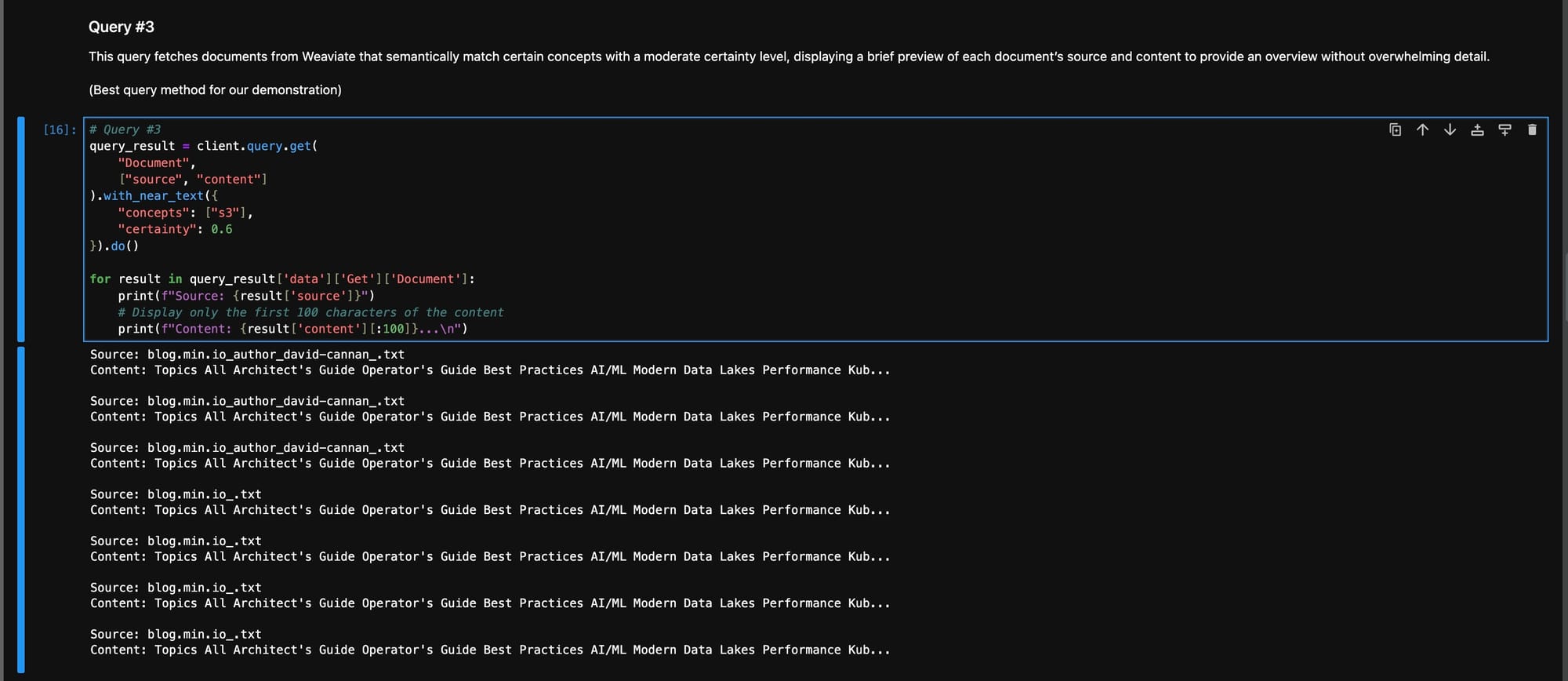
This process translates the structured data into practical, actionable intelligence.
|
query_result = client.query.get( |
The Python code demonstrates a targeted search within Weaviate, retrieving documents that semantically match given concepts with a defined level of certainty.
This functionality exemplifies the practical power of our Dual ETL pipeline—turning complex data into comprehensible and useful information ready for business applications.
As we wrap up our exploration of the Dynamic ETL pipeline, enhanced by the essential capabilities of Unstructured-IO, it’s clear that we’re standing at the cusp of a data management revolution. The journey through the intricate processes of transforming unstructured web data into a treasure trove of structured information has been nothing short of transformative. With Unstructured-IO’s auto-partitioning, MinIO’s storage solutions, and Weaviate’s AI capabilities, we have unveiled a pathway that not only simplifies data management but also unlocks deeper, more actionable insights than ever before.
Enhancing ETL Processes with Unstructured-IO Connectors
In the development of our proof of concept, several approaches were evaluated to ensure a streamlined and efficient implementation, aiming for minimal lines of code. The Unstructured-IO Weaviate connector presents a promising avenue for enhancing data processing workflows.
The connectors are particularly adept at managing batch processing, ensuring data conforms to predefined schemas, and simplifying error handling mechanisms. This makes it an invaluable tool for projects that require scalable, efficient, and reliable data handling capabilities, especially in complex or data-intensive environments. Its potential utility in such scenarios underscores the importance of considering diverse tools and methods to optimize data pipeline development and operational efficiency.
The integration of Unstructured-IO within our Dynamic ETL pipeline isn’t just a technical approach; it’s a methodology that sparks the way for data analysis and AI technologies. By turning unstructured data into an organized, searchable repository, we’re not only enhancing current analytical capabilities but also laying the groundwork for emerging AI methodologies that promise to redefine what’s possible in data-driven decision-making.
Invitation to Innovate and Collaborate
It is clear that the potential for innovation at this point is limitless, and the impact on industries ranging from healthcare to finance is yet to be fully realized. We invite you, the developers, data engineers, and visionaries, to join us in this adventure. Whether it’s by customizing the pipeline to suit niche requirements or exploring new applications for these tools, your contributions are the key to unlocking the next level of data-driven breakthroughs.
In the end, it’s not just about the data or the technology; it’s about the connections we forge, the insights we uncover, and the impact we create.
If you’ve been inspired by the possibilities of Dynamic ETL, intrigued by the capabilities of Unstructured-IO, or simply wish to share your thoughts and ideas, we’re here for you.
Reach out to us on Slack and drop us a message. Let’s continue this conversation and together, shape the future of data management!






