Enterprise AI Infrastructure Made Easy with AIStor and NVIDIA GPUs

Modern enterprises seeking to leverage AI capabilities often face a significant hurdle: the complex deployment and management of GPU infrastructure in their Kubernetes environments. MinIO's AIStor addresses this challenge head-on by integrating the NVIDIA GPU Operator, revolutionizing how organizations deploy and manage GPU resources for AI workloads. Through automated GPU setup, driver management, and resource optimization, this integration transforms what was once a complex, multi-step process into a streamlined deployment that can be achieved with a single command. The result is an enhanced AIStor platform that brings powerful AI capabilities directly to your data layer, allowing organizations to focus on leveraging AI rather than managing infrastructure.
The Challenge of GPU Management
Organizations face multifaceted challenges when managing GPU infrastructure, both in traditional environments and especially in containerized platforms like Kubernetes:
- Driver Complexity
- Different GPU models require specific driver versions
- Driver compatibility with various operating systems
- Complex kernel dependencies and interactions
- System stability issues from driver conflicts
- Rolling updates across heterogeneous environments
- Resource Management
- Manual GPU discovery and allocation is error-prone
- Complex GPU memory management requirements
- Need for efficient multi-tenant isolation
- Resource fragmentation leading to underutilization
- Fair scheduling across diverse workloads
- Additional complexity in Kubernetes for resource quotas and limits
- Operational Overhead
- Manual installation and configuration of CUDA toolkit
- Complex monitoring and metrics collection setup
- Time-consuming troubleshooting processes
- Maintaining consistency across different environments
- Container runtime configuration for GPU access
- Kubernetes-specific challenges:
- Node labeling and tainting for GPU workloads
- Pod scheduling and affinity rules
- Integration with cluster autoscaling
The challenges are particularly amplified in Kubernetes environments, where organizations must bridge the gap between container orchestration and GPU management while maintaining production-grade reliability and performance.
Understanding NVIDIA GPU Operator Architecture
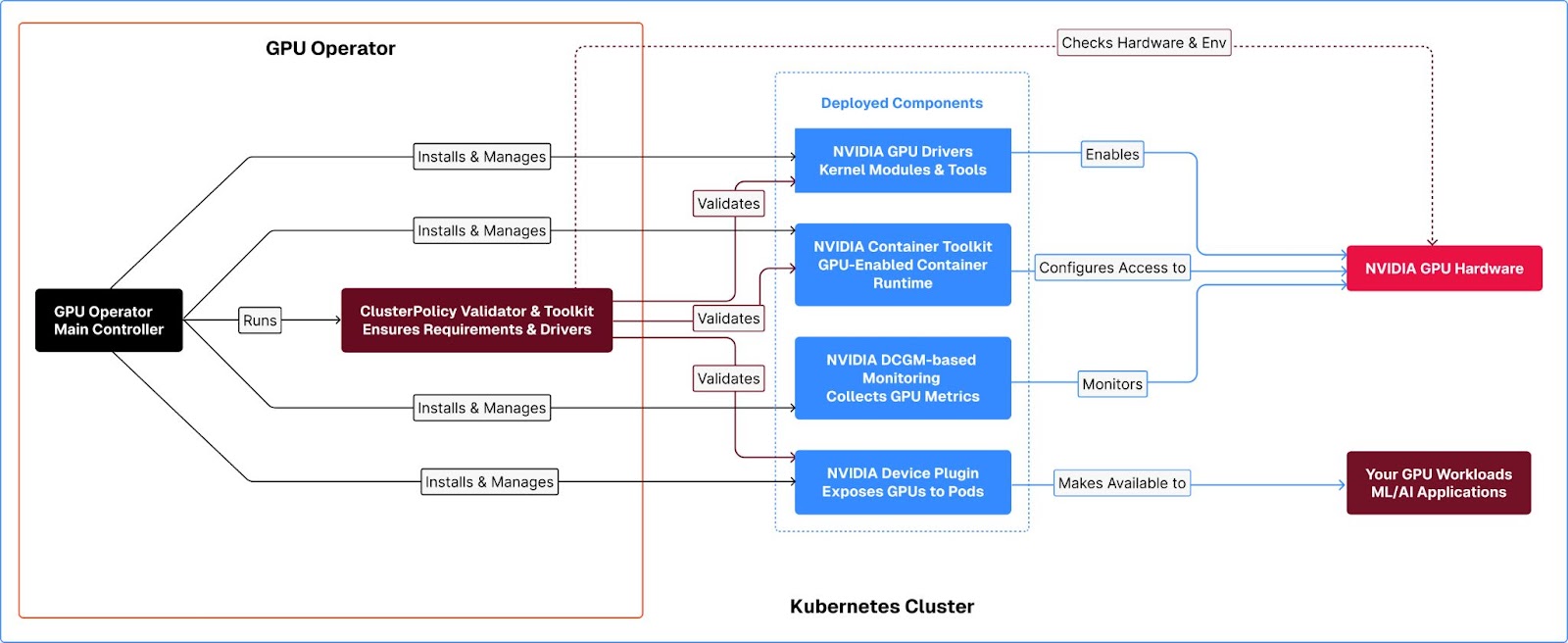
The NVIDIA GPU Operator is built on the Kubernetes Operator Framework and provides a comprehensive automation solution for GPU management. Let's explore its architecture and components:
- NVIDIA Drivers (DRV)
The driver component is fundamental to GPU operations. It:
- Manages the low-level interaction between the operating system and NVIDIA GPUs
- Handles automatic driver installation and updates on Kubernetes nodes
- Provides the necessary kernel modules for GPU access
- Manages driver lifecycle including version compatibility and updates
- Enables features like RDMA for high-speed data transfer when needed
- Container Runtime (RT) with NVIDIA Container Toolkit
This component enables containers to utilize GPU resources by:
- Providing the necessary hooks and configurations for container runtimes (Docker, containerd)
- Managing GPU access permissions and device mounting in containers
- Handling GPU resource allocation and isolation
- Setting up the NVIDIA runtime environment inside containers
- Configuring proper driver paths and libraries for containerized applications
- Device Plugin (DP)
The device plugin is crucial for Kubernetes integration:
- Advertises GPU resources to the Kubernetes scheduler
- Manages GPU resource allocation and tracking
- Handles GPU discovery and health monitoring
- Enables fine-grained control over GPU allocation to pods
- Supports advanced features like MIG (Multi-Instance GPU) configuration
- Provides device ID management and visibility control
- Monitoring and Validation Components
These components provide observability and ensure proper operation:
DCGM Exporter:
- Collects GPU metrics (utilization, memory, temperature, etc.)
- Exposes metrics in Prometheus format
- Enables monitoring and alerting integration
- Provides real-time GPU health and performance data
- Supports cluster-wide GPU resource monitoring
Validator:
- Verifies proper installation and configuration of all components
- Checks GPU health and availability
- Validates driver and toolkit compatibility
- Ensures proper setup of all GPU operator components
- Helps troubleshoot deployment issues
Each of these components works together to provide a complete GPU management solution in Kubernetes, handling everything from driver installation to monitoring and resource management.
Setup
In our Example deployment we have 8 storage Nodes and 1 GPU node in the Kubernetes cluster. Run the below command to view your kubernetes cluster.
Once executed, you should see something like the image below:
To set up MinIO AIStor, all the user has to do is run the below command in their terminal with the right access to the kubernetes cluster.
Then, run the below command to configure access to the global console.
Now, go to http://localhost:8444/. You should be greeted to the License page where you can enter your AIStor license key as seen in the image below:
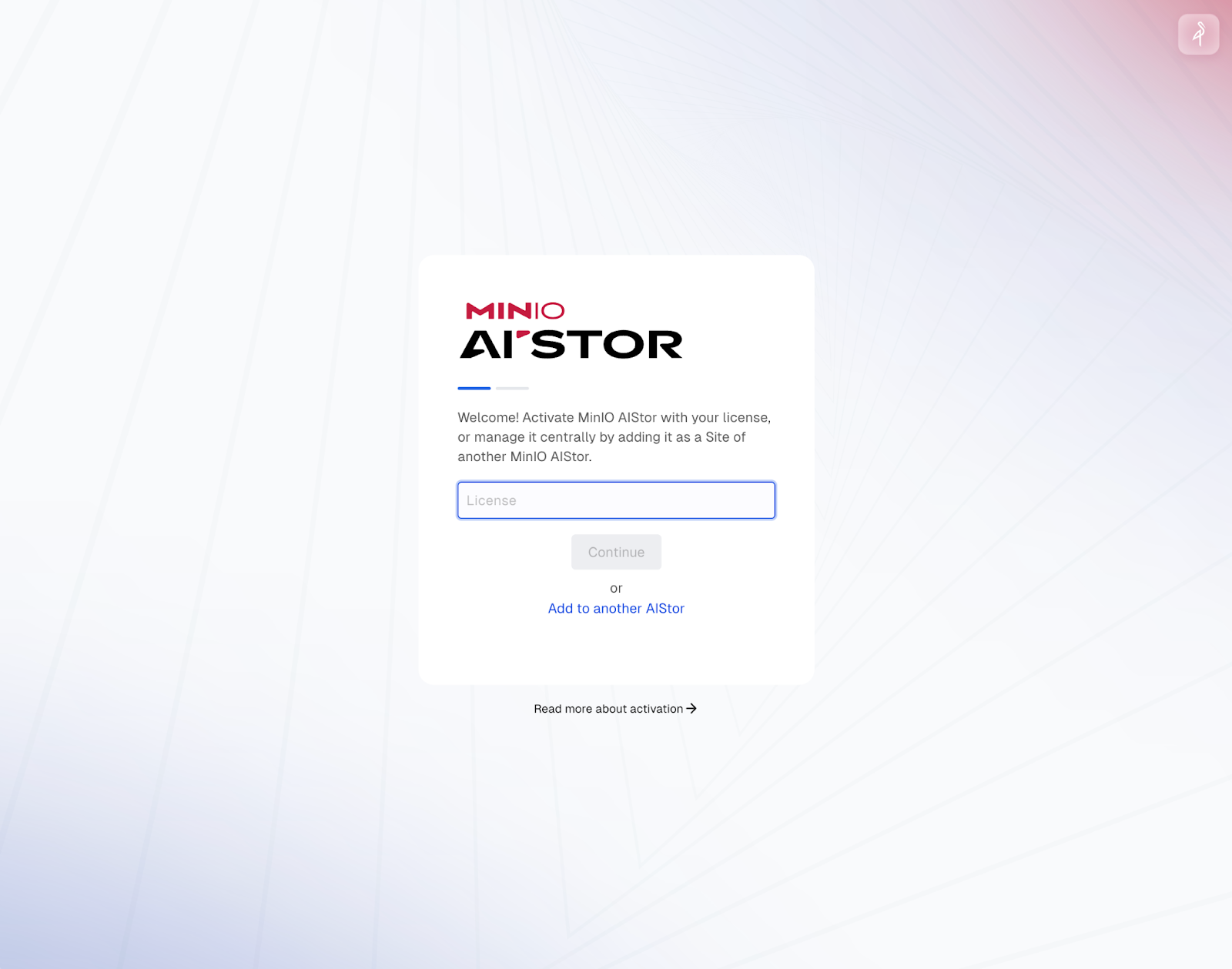
After you enter a valid license key, you can create an admin account:

Once the setup is completed successfully, run the following command.
Note: Change the node name in the above command to the name of your GPU node.
You should see something like what is shown below:
The key thing to note here is the nvidia.com/gpu key that shows that the AIStor has successfully setup the NVIDIA GPU Operator and the label “nvidia.com/gpu” is made available for us to enable PromptObject API that needs GPU based inference server to be setup later on or any other AI based workloads that needs GPUs.
If you run the same command on storage nodes you will not be seeing the GPU specific key.
Note: Change the node name in the above command to the name of your node.
You will see the below output:
With just one command we are able to set up both the AIStor and GPU Operator successfully.
Key Benefits of Integrated GPU Operator Deployment
- Automated AI Infrastructure
- Zero-touch GPU setup for inference workloads
- Automatic scaling based on inference demands
- Built-in high availability and failover
- Data Locality Optimization

- Eliminates data movement overhead
- Reduces latency for inference operations
- Optimizes GPU resource utilization
- Simplified Management
- Single command deployment
- Automated updates and maintenance
- Integrated monitoring and scaling
Conclusion
The integration of AIStor with NVIDIA GPU Operator represents a significant advancement in AI infrastructure management. By automating complex tasks and providing seamless integration between storage and compute resources, organizations can focus on their AI workloads rather than infrastructure management.
This solution addresses key challenges in both GPU and data management, providing a robust foundation for AI workloads at scale. The automated setup and optimized data paths bring AI to where data is, and comprehensive management capabilities make it an ideal choice for organizations looking to streamline their AI infrastructure. If you would like to explore this subject further with a demo, visit https://min.io and request a demo. As always, if you have any questions join our Slack Channel or drop us a note at hello@min.io.






