Object Management for AI/ML
Introduction
In a few previous posts on AI/ML, I mentioned that one of the benefits of MinIO is that you have tools for Versioning, Lifecycle Management, Object Locking, Object Retention and Legal Holds. These capabilities have a variety of uses. You may need a simple way to keep track of training experiments. You could also use these features to tag and save the versions of models that are deployed to production. Finally, you may be working toward something more complicated, like General Data Protection Regulation (GDPR) compliance. If this is the case, you will need to ensure data is not accidentally deleted and that data does not live longer than it should.
In this post, I’ll explore these concepts further and show you how to set them up using code. Specifically, I’ll show you the code you can add to your machine learning workflows to enable these features for training sets, validation sets, test sets, configuration, and models themselves.
When I am done, you will have a collection of functions to add to your projects if you wish to take advantage of these features. You can find a Jupyter Notebook with all my code here.
Let’s start with versioning.
Versioning
Versioning is conceptually easy to understand. If an object of the same name already exists in your bucket, don’t delete the old one in favor of the new one. Rather, save the old version for future reference if needed. The new version becomes the default version for all GET requests.
You may be tempted to use a Git repository for storing your datasets and models. However, I think we have all made the mistake of downloading a ton of data to a folder within our repository - forgetting to update `.gitignore` - and then watching our push fail due to data constraints on the repository. Git was not designed for versioning large objects - especially the ones that are being used these days for ML/AI. Fortunately, MinIO was designed for large objects. We like large objects (and small objects – we don’t discriminate), and you can keep as many versions as you wish of them.
Versioning is configured at the bucket level. The code below shows how to create a bucket and set it up for versioning.
Let’s create another function for uploading datasets to a bucket. Since Pandas data frames are the de facto standard for working with training, validation and test sets - I’ll create a function that streams a data frame from memory to MinIO. This is shown below.
You may want to save your models to MinIO too. The function below will stream a PyTorch model to a MinIO bucket.
Finally, it's not uncommon to have all the parameters you need to create and train your model in a dictionary. These parameters are usually referred to as hyperparameters. Let’s create one more helper function to save hyperparameters to our version-enabled bucket.
With all these functions in place, you could use the function below to save an entire experiment either before or after it is run.
Here I am putting the experiment name into the path of each object. Feel free to implement schemes of your own if you wish.
After saving two experiments using the code below, your bucket would look like the screenshot below.
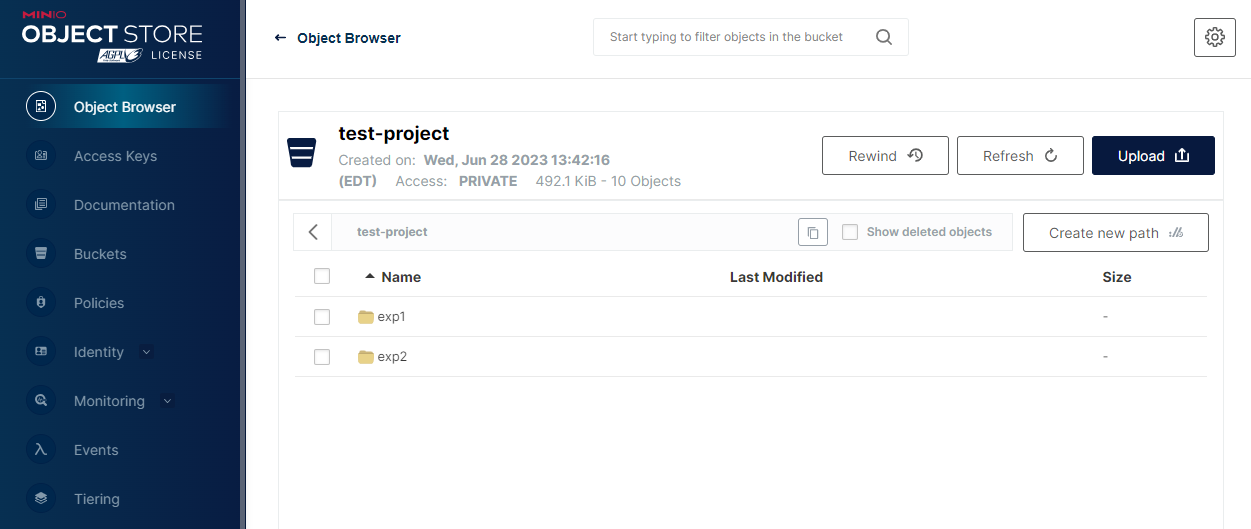
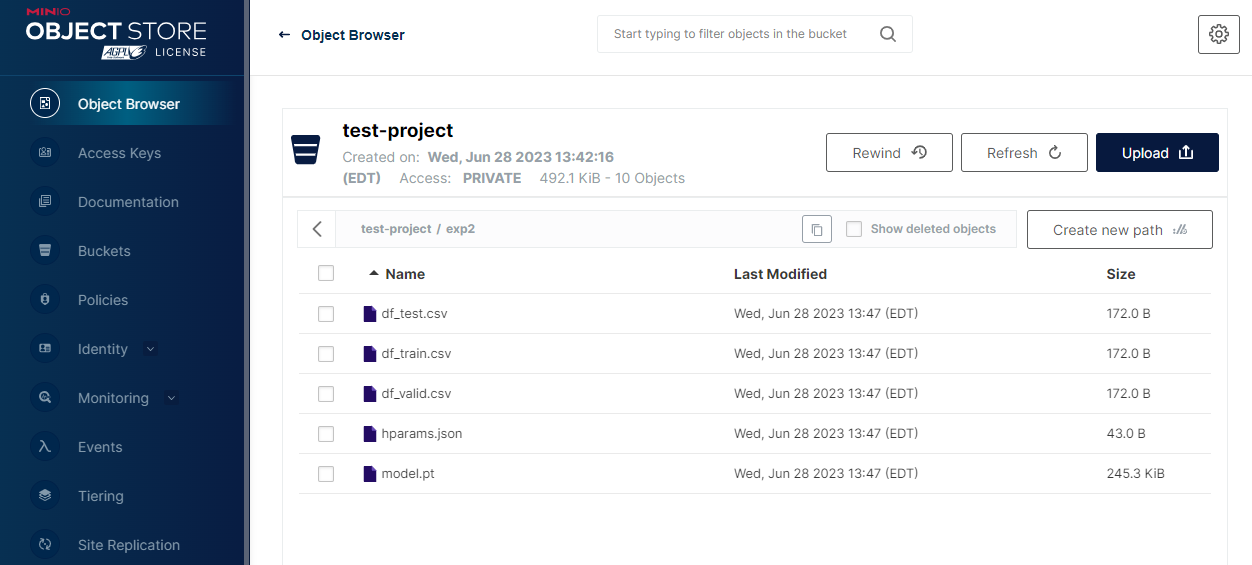
Each path (experiment) would contain the following objects.
Bucket Lifecycle Management
As you run more and more experiments, saving your training set, validation set, test set, and model, you will eventually get to a state where you have versions of these artifacts that you really do not need to keep around anymore. MinIO has Lifecycle Management capabilities that automate the removal of expired objects in a bucket. This can be done programmatically, as shown below.
The code above applies a single rule to a bucket that will automatically delete any object in the bucket that is older than the specified number of days. You are not limited to only one rule per bucket. You can have as many as you need. Also, notice that each rule has a filter.
MinIO Lifecycle Management can also transition objects from one cluster to another. Let’s say you have two object storage clusters, as shown below. In this configuration, we have MinIO set up as a hot tier (high-speed storage) and one of the cloud providers as a warm tier (slower storage but cheaper). Using a Transition rule, you can move objects to cheaper storage once they reach a certain age. The code to set this up is also shown below. If you wish to transition objects then you will need to set up the connection information to the warm tier within your hot tier. You can read about how to do that at: Object Lifecycle Management.

If you do not require governance or compliance on your AI/ML data, then versioning and lifecycle management may be all you need. However, if you are building models in a regulated industry, then consider object locking, object retention and legal locks to make sure your data does not get accidentally deleted. These three capabilities are discussed in the next three sections.
Bucket Level Object Locking
The purpose of Object Locking is to prevent the accidental deletion of an object during a specified time period. This is different from Lifecycle Management. Lifecycle Management will remove or transition an object after it reaches a certain age. Lifecycle Management does not prevent the accidental deletion of an object. This is the purpose of Object Locking. MinIO provides several ways to lock objects. In this section, I want to focus on setting up an entire bucket for Object Locking.
If you need Object Locking on a bucket, you must configure this when the bucket is created. The code below will create a bucket that is capable of Object Locking. Notice the `object_lock` named parameter of the `make_bucket` method. The default value for this parameter is `false.` If you forget to explicitly set this parameter to `true` when you create a bucket, then there is no way to edit the bucket later and set it. You will need to delete the bucket and create it again.
Another important fact about the code above is that turning on Object Locking automatically enables Versioning. You have to have Versioning to use Object Locking.
Once you have a bucket capable of Object Locking, you need to specify the lock duration. This is done using the `set_object_lock_config`. The function below packages this up for you.
This method specifies the number of days (or years) a lock should be in place for all objects added to the bucket. You also specify the Retention Mode, which is either GOVERNANCE mode or COMPLIANCE mode. The mode dictates who can override the lock. Users with the `s3:BypassGovernanceRetention` permission can modify a GOVERNANCE-locked object, lift the lock, or change the duration. Nobody can change a COMPLIANCE-locked object. Not even the MinIO root user.
If you forgot to set the `object_lock` parameter to true when you created your bucket, then you will get an error message similar to the message shown below when setting the object lock configuration.
S3Error: S3 operation failed; code: InvaidRequest, message: Bucket is missing ObjectLockConfiguration, resource: /test/train.csv, request_id: 176CDC35EF0AF792, host_id: e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855, bucket_name: test, object_name: train.csv
To recap - we created a bucket with `object_lock=True` - this automatically enabled Versioning for the bucket. Next we set the lock duration, and set the Retention Mode.
Let's discuss what happens when an attempt is made to delete an object when Retention Mode is enabled. If an attempt is made to delete a specific version of an object, then the attempt will fail. The error message below shows the error that shows up in the MinIO Console when a delete is attempted.
Object, ‘train.csv (Version ID-fb61ba31-4fca-4ab4-963a-ad98275bde4f) is WORM protected and cannot be overwritten
WORM stands for Write-Once-Read-Many which is a data storage technique for providing immutable storage.
However, if the user has `s3:BypassGovernanceRetention` privileges and the retention mode is GOVERNANCE, then the delete will be successful.
If an unversioned delete is requested, the delete will succeed. This may seem non-intuitive, but remember that when versioning is enabled, an unversioned delete causes a zero-byte delete marker to be added as the most recent version of the object. The object is not really deleted. In the MinIO Console’s object browser, you can see all objects with this marker by clicking the `Show deleted object` check box.
The zero-byte delete marker can be deleted, restoring the object – even when the bucket has locking in place.
Finally, the helper function below is useful when you need to get the object-locking configuration for a bucket.
If you would like to specify a lock on a specific object, then that is possible too. This is known as Object Retention. I’ll show this next.
Individual Object Retention
Object Retention allows you to specify locking on an individual object. This is shown in the function below, which will set the retention of an existing object.
Notice that Object Retention differs slightly from Object Locking, which is set at the bucket level. Here you specify a `retain_until_date` as opposed to a duration (or age).
Everything else is the same as locking at the bucket level, the bucket in which the object resides must have been created with the `object_lock` parameter set to true. Also, the different retention modes work the same way as described in the previous section.
Legal Holds
Just like the other locks, Legal Holds prevent new versions of an object from being created, and they prevent the existing object from being deleted. However, they are indefinite as there is no `duration` or `retain_until_date` specified when creating a legal hold. A user with the `s3:PutObjectLegalHold` permission will need to lift the legal hold before the object can be deleted or a new version added.
Here is the code to set a legal hold on an object.
Legal Holdscan only be used on buckets with the `object_lock` parameter set to true -- which also enables versioning. All three features that prevent accidental deletion work the same way with respect to bucket requirements and unversioned deletes. Object Locking, Object Retention and Legal Holds all require the `object_lock` parameter to be set when the bucket is being created, which also enables Versioning on the bucket. Unversioned deletes will succeed because you are really not deleting - you are just adding a 0-byte marker which can be deleted to restore the object.
Summary
In this post, I described the following MinIO features and implemented them in the context of AI/ML.
- Versioning
- Lifecycle Management
- Object Retention
- Object Locking
- Legal Holds
These features can help you track experiments, version models, and meet the compliance requirements of a regulatory organization. It is important to note that while I described these features in the context of AI/ML, they can be used for anything - data analytics, managing objects on an edge network, and managing large-scale backups.
You can find the code here. If you have questions or you want to share your results, then drop us a line at hello@min.io or join the discussion on our general Slack channel.






