Why Your Enterprise AI Strategy Is Likely to Fail in 2024: Model Down vs. Data Up

I suspect some folks will accuse me of clickbait titling. Others will say, that’s not really a reach - most folks will fail in their initial AI attempts but it doesn’t matter and the learnings are worth it. On some level both are right - but I think WHY enterprises will fail is worth exploration and may allow some of our readers to at least reassess before they go too far.
Enterprise AI strategies will fail in 2024 because they are focused on models, not on data. It matters far less what you choose for your foundational model than the data it is trained on. Your selection of a vector database matters very little on the margin if your data and data infrastructure are built on faulty foundations.
This may seem self-evident, but we talk to enterprises, really big enterprises with lots of smart people, and we can tell you with certainty that organizational momentum has resulted in some of those enterprises thinking model down vs. data up. It is a critical mistake.

You have to start with the data. Build a proper data infrastructure. Then think about your models.
If the thought process is to buy some GPUs and reuse your existing data infrastructure you are going to fail. Your existing data infrastructure is likely a bunch of SAN/NAS appliances. They don’t scale. The result is that you will be training on a fraction of your company’s data and you will get a fraction of the value. A chain is as strong as its weakest link - and your AI/ML infrastructure is only as fast as your slowest component. If you train machine learning models with GPUs, then your weak link may be your storage solution. Keith Pijanowski calls it the “Starving GPU Problem.” The Starving GPU problem occurs when your network or your storage solution cannot serve training data to your training logic fast enough to fully utilize your GPUs.
We are getting a little ahead of ourselves. Let’s start with what your data should look like.
- Complete and Correct: You can call this “clean” data if you would like. The level of cleanliness can significantly impact the underlying calculations and vector representations in LLMs. A high-quality corpus is critical for fine-tuning and RAG. It must include documents/content that represent correct and truthful representations of the organization to generate the correct outputs. This has implications for training efficiency. Incomplete datasets can hinder the model's learning process, leading to inefficient training and poor generalization to new data. Finally, there is bias amplification. Incorrect data, especially if systematically biased, can lead to the amplification of biases within the model, affecting fairness and ethical considerations.
- Expansive: This gets at having enough data. If your infrastructure is causing you to artificially limit the amount and/or type of data you can use, it will limit the value you generate. In retrieval-augmented generation for example, having extensive data allows the LLM to pull from a vast repository of information, enabling it to provide more nuanced and informed answers, similar to consulting a well-stocked library. The same applies to using AI for log analytics. Yes, the majority of time the value is in recent data, but that doesn’t mean that value does not extend to older, larger windows of data. Your infrastructure decisions impact your model outputs if they limit the amount of data you can analyze.
- Recency: While we just talked about longer windows and more data - there is obviously a limit to that. That data cannot be so out of date that it is no longer valid. Domain specific expertise matters here. For example, for dynamic fields like technology, finance, or current events, data older than 6-12 months might be considered too old. In contrast, for stable or historical domains, data several years old can still be valuable (there is limited new information on the Peloponnesian War for example). It's essential to align the data's age with the LLM model's specific use case and the rate of change in the relevant domain.
- Consistency: Data consistency refers to the uniformity, accuracy, and reliability of data across a dataset. It ensures that the data remains unaltered throughout its lifecycle, from collection to processing and analysis, providing a stable and coherent basis for AI models to learn from and make predictions. For LLMs, inconsistent data can disrupt the learning of linguistic patterns, leading to inaccurate text generation or comprehension. For approaches like topological data analysis, which analyzes data's shape and structure, inconsistency can skew topological insights, affecting the interpretation of complex datasets. Essentially, consistent data is akin to a stable foundation for a building, ensuring the AI's "structure" stands firm and functions correctly.
- Unique: Data uniqueness matters to an LLM because it ensures a diverse training set, enhancing the model's ability to generalize and understand varied contexts. Unique data points prevent overfitting to repetitive information, allowing the LLM to develop a broader understanding and generate more creative, accurate responses. It also enables fine-tuning of the model and for RAG.
This is an effective starting point for “clean” data. What is next are your data infrastructure choices. It is absolutely imperative that the data infrastructure enables your data - not constraints it. Your data infrastructure cannot “force” you to only look at data that comes in row and columns. Your data infrastructure cannot limit what you can glean from videos or log files. It has to enable.
Here is a reference architecture for a Modern Datalake. Use it for AI and more.
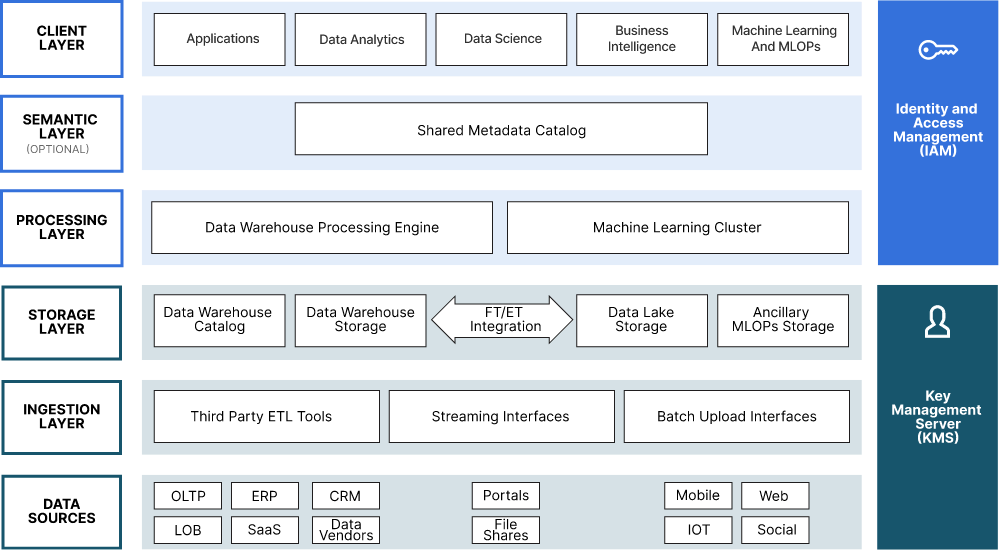
You can start to fill this in with logos if you like. One of the advantages of using someone like MinIO is that the entire ecosystem will work right out of the box. MLflow, Tensorflow, Kubeflow, PyTorch, Ray - you get the picture.
The point here is that you want ALL of your data in a single repository (appropriately replicated). It enables better governance, access control, and security.
That requires something highly scalable and something that can handle diverse types of data. That would be an object store (a modern one, again, appliances don’t have much utility here).
You want something performant (throughput and IOPS) and here again, a modern object store is the answer. You want something simple - because scale requires simplicity. You want something software-defined. The scale you need requires commodity hardware to make the economics work. Appliances are a terrible choice.
You want something you control. This is your data, it is the basis on which your entire AI effort depends. You cannot outsource it to someone who could be competing with you in a few quarters time. Build the AI Modern Datalake you control.
You want something that is cloud-native. Kubernetes is the operating system of the cloud operating model. Data infrastructure that is native to containerization and orchestration is effectively a requirement.
This requires a solution that can replicate (active-active) across datacenters and geos.
There may be requirements to house some data in country and that needs to be accommodated too. The point should be clear, that the data requirements define the infrastructure requirements and that informs the frameworks/models. Not the other way around. Companies that start from the data and work up will be successful. That is the foundation on which a functional AI strategy is built. Frameworks and models are important but the alpha and omega is the data. We are building for a data first world, in fact we have been doing so for the better part of a decade now. It is why the AI ecosystem works out of the box with us. To learn more, check out our AI and ML solution page. It goes deep into the features, capabilities and performance that has made us a choice for AI architects around the globe.






