Metrics with MinIO using OpenTelemetry, Flask, and Prometheus

Observability is all about gathering information (traces, logs, metrics) with the goal of improving performance, reliability, and availability. Seldom it's just one of these that would pinpoint the root cause of an event, more often than not it's when we correlate this information to form a narrative is when we’ll have a better understanding.
In the last few blogs on observability, we went through how to implement tracing in MinIO and sending MinIO logs to ElasticSearch. In this blog post we’ll talk about metrics.
From the start MinIO has not only focused efforts on performance and scalability, but also on observability. MinIO has a built-in endpoint /minio/v2/metrics/cluster that Prometheus can scrape and gather metrics from. You can also publish events to Kafka and trigger alerts and other processes to run that are dependent on action performed within MinIO. Finally you can bring all of these metrics together in a pretty dashboard on Grafana and even kick off alerts.
Cloud-native MinIO integrates seamlessly with cloud-native observability tools like OpenTelemetry. We’ll use the same OpenTelemetry API that we used for traces for metrics, just with different sets of exporters and functions.
To give you a feel for the observability process and the depth of information available, we’re going to build a small flask Python application and visualize it in Grafana
- We’ll launch MinIO, Prometheus and Grafana containers.
- Write a sample Python app using OpenTelemetry to gather various types of metrics such as counters and histograms.
- Perform operations on MinIO using MinIO SDK.
- Build a Docker image for the sample application we wrote.
- Visualize the metrics scraped by Prometheus in our Grafana dashboard.
We’ll walk you through the entire process step by step.
Launching infrastructure
Similar to the last blog, we’ll use a Python application that we write from scratch, except this time we’ll send metrics instead of sending traces.
MinIO
There are several ways to install MinIO in various environments. In this blog post we’ll launch MinIO with Docker, but in production please be sure to install in a distributed setup on Kubernetes.
Create a directory on your local machine where MinIO will persist data
Launch the MinIO container using Docker
Note: Keep a copy of the credentials used above; you will need them later to access MinIO.
Verify you can access MinIO by logging in using a browser through http://localhost:9001/ with the credentials used to launch the container above.
Prometheus
The metrics we collect from our application need to be stored somewhere. Prometheus is that store in this case, but OpenTelemetry supports other exporters as well.
Start by creating a file called prometheus.yml with the following contents
Make a note of the - targets: ['metrics-app:8000']; later when we launch the app in a Docker container, we’ll set the hostname to metrics-app to match the target.
Launch the Prometheus container
Make a note of the hostname and ports above; you’ll need those later when configuring the data source in Grafana.
Grafana
Did you know that Grafana originally started as a fork of Kibana? In this example we're going to use Grafana to provide the visualization for the metrics we collected and stored with MinIO above. By visualizing in Grafana, we can see the patterns emerge that we would otherwise not see by looking at just numbers or logs.
Launch the Grafana container
Access it via browser http://localhost:3000 and follow the instructions below to setup the Prometheus datasource.
Flask application
Previously we wrote a Python application to send traces but this time we’ll write a Flask web app in Python to have a better understanding of the integrations. Flask is a Python web framework that helps us easily build simple web facing or API applications. In this example we are just showing a stripped down version so that we can demonstrate the techniques succinctly.
Instrumenting metrics
We’ll go ahead and paste the entire Flask application here and then dissect it to delve deeper into the code base on how we instrument the metrics.
Create a file called app.py and paste the following code
Flask is the web framework that serves our route
In order for the server to scrape our metrics, we need to start a Prometheus client. For now just import the package.
For doing the MinIO operations, import the minio package as well.
OpenTelemetry is the framework that standardized the metrics we send to Prometheus. We'll import those packages as well.
The Prometheus client is what exposes the metrics we collect to the Prometheus scraper.
As a reminder, the port should match the configuration in prometheus.yml.
Create a metric type counter that will allow us to send whole number values. Here we are counting the number of visits to the app. Counters can count things like
- The number of API visits
- The number of page faults with each process
In addition to page visits, we would also like to know how long it took for the request; for that we’ll create a metric type histogram. In this instance, we are measuring the inbound request time in milliseconds, but we can display other metrics such as
- Object size being uploaded to a specific MinIO bucket
- The duration it took for the object to be uploaded
Initialize the MinIO client
Initialize Flask App and OpenTelemetry metrics instrumentation
In def before_request_func(): we are doing two things
- A counter function to increment by one every time someone visits any of the routes
- A start time to check the load times in milliseconds
In def after_request_func(): we are capturing the end time of the request and passing the delta to record the histogram
These metrics are encapsulated within these before/after decorators so that we keep the code DRY. You can add any number of additional routes and they will automatically have our custom metrics instrumented.
Last but not least, some sample routes doing some operations using the MinIO Python SDK. The cURL calls for these would look something like this
curl http://<host>:<port>/makebucket/aj-testcurl http://<host>:<port>/removebucket/aj-test
As you can see, our app is very simple, and that is the whole point of it. We want to give you an idea of the foundation but you can take this and run with it and add your own instrumentation.
Build and deploy app
We wrote the app, now we need to build the app as a Docker image so we can deploy it alongside our other infrastructure so everything can talk to each other.
Create a file called Dockerfile and add the following contents
We need to install all the packages we are importing in our app. Create a file called requirements.txt with the following contents
Build the App with the name ot-prom-metrics-app which we’ll use later as the image name to launch the container with.
Launch the app container with the image we just created on port 5000.
Test by making a bucket using the following curl command.
Now that we have all the pieces deployed, it's time to observe these in Grafana.
Observing metrics
We have an app deployed that can generate some metrics, a data store (prometheus) to keep these metrics, and Grafana for historical views and context.
Grafana queries
Login to Grafana and follow the instructions below
You’ll notice none of our metrics are in there. That is because either you have not made any call against the flask app routes or it was made more than five mins ago. Technically you should see the curl call register that you made in the previous section if you expand the time frame of the visibility, but no matter, let’s make a test call again and then check.
Refresh the Grafana page and follow the instructions below
Well wasn’t that fun? Let’s do some more fun stuff, by doing multiple calls but staggering them. Each subsequent call will take a second longer. In other words, the first call will take one second, the second call will take two seconds, the third call will take three seconds and so on. Go ahead and run the command below.
In Grafana click Run query once the above command is done executing. The result should look something like this, notice on the far right? That is our 11 requests or however many you made.
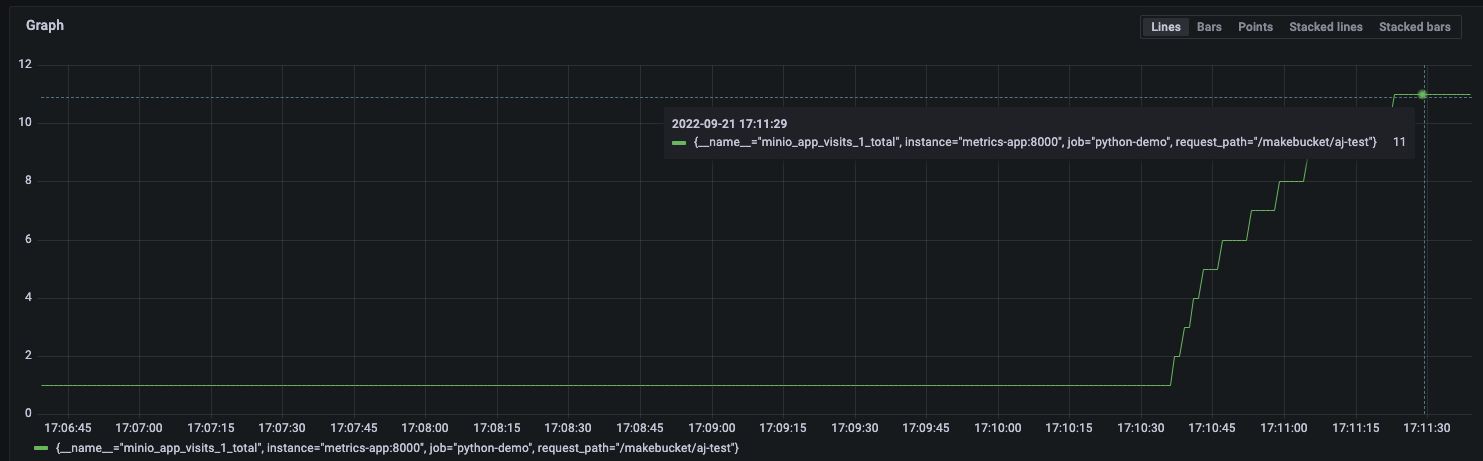
While that was fun and now we know the amount of total visits to the application we don’t know at what rate those visits are being made: Were they one per second? A few every second? This is where the range functions come in handy. Follow the instructions below
Now you have a simple application which you can use to build upon further instrumentation as you see fit. Some of the other common use cases are
- Monitor the size of the objects uploaded
- Monitor the rate at which number of objects are being fetched
- Monitor the rate at which objects are being downloaded
These are just a few examples; the more you instrument, the more observability you’ll have.
Final Thoughts
Observability is multi-faceted; you will often have to look at a combination of traces, metrics, and logs to determine the root cause. You can use Chaos Engineering tools such as Gremlin, ChaosMonkey and the like to break your system and observe the pattern in the metrics.
For example, perhaps you are collecting your HTTP request status and generally you see 200s all the time but suddenly you see a spike of 500s. You go take a look at the logs and you notice a deployment took place recently or a database went down for maintenance. Or, if you are monitoring object storage performance metrics you can correlate any server side issues with this data. It's these types of events that often cause the most pain and having visibility in these cases is paramount.
If you would like to learn more about Chaos Engineering or have a cool implementation of metrics in your MinIO application, reach out to us on Slack! We’d love to see what you have.






