Machine Learning Pipelines with Kubeflow and MinIO on Azure

Learn how to run Kubeflow on Azure Kubernetes Service with MinIO.
Read moreA collection of 94 posts tagged with "Operator's Guide"
Learn how to run Kubeflow on Azure Kubernetes Service with MinIO.
Read moreLearn how MinIO uses identity access management to protect objects stored across clouds.
Read more
One of the key requirements driving enterprises towards cloud-native object storage platforms is the ability to consume storage in a multi-data center setup. Multiple data centers provide resilient, highly available storage clusters, capable of withstanding the complete failure of one or more of those data centers. Multi-data center support brings private and hybrid cloud infrastructure closer to how the public
Read more
With the introduction of Apache Arrow, language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations, MinIO data lakes can be much more powerful. This article explains how to make use of Apache Arrow by using ArrowRDD.
Read more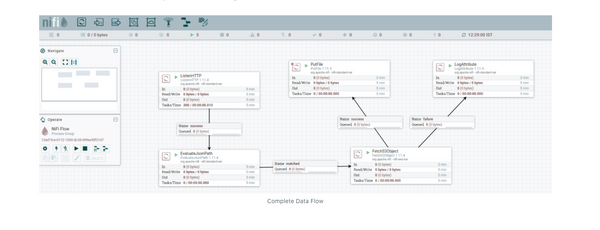
Apache Nifi is one of the most popular open source data flow engines available today. Nifi supports almost all the major enterprise data systems and allows users to create effective, fast, and scalable information flow systems. Creating data flow systems is simple with Nifi and there is a clear path to add support for systems not already available as Nifi
Read more
We are living in a transformative era defined by information and AI. Massive amounts of data are generated and collected every day to feed these voracious, state-of-the-art, AI/ML algorithms. The more data, the better the outcomes. One of the frameworks that has emerged as the lead industry standards is Google's TensorFlow. Highly versatile, one can get started
Read more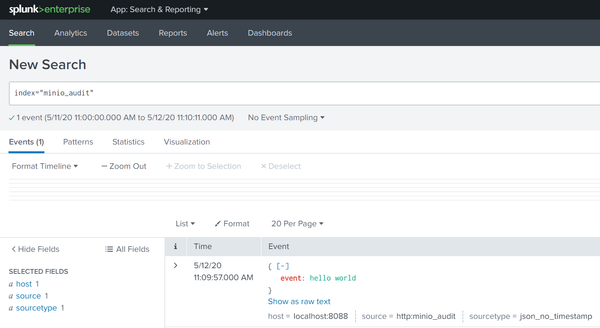
Overview MinIO and Splunk have a symbiotic relationship when it comes to enterprise data. Splunk uses MinIO in its Digital Stream Processor. MinIO is a Splunk SmartStore endpoint. In this post we explain how to use Splunk's advanced log analytics to help understand the performance of the MinIO object storage suite and the data under management. A quick
Read more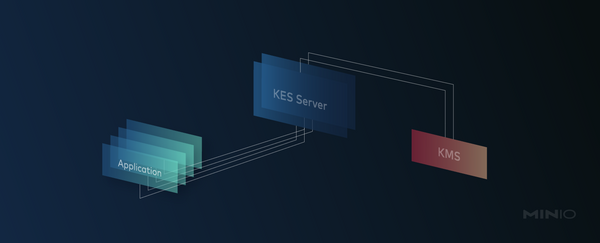
KES is a stateless and distributed key-management system for high-performance applications. We built KES as the bridge between modern applications - running as containers on Kubernetes - and centralized KMS solutions. Therefore, KES has been designed to be simple, scalable and secure by default.
Read more
With the announcement that MinIO was Veeam Ready for Object last week we felt it would be helpful to circle back and talk about an additional use case. In our first post we covered backups of VMware ESX. An equally popular use case is Veeam Backup for Office (VBO). The Office backup market is massive. Even with the advent of
Read more
Veeam's V10 release adds object storage support in a big way. Find out how these two software stacks play together to deliver performance oriented backup and restore.
Read more
As data has grown, so has the challenge associated with moving it. Indeed, the bandwidth costs to migrate a PB of data out of AWS would be more than keeping it there for years. Still, customers often need to move large amounts (100s of TBs up to PBs) with some frequency. Amazon knows this and has, in their intensely customer
Read more
We approach things differently here at MinIO. When we started in 2014, we questioned everything about the object storage market as we built our product - thinking more like a data company than a storage company. We did it from scratch, using engineering first principles, an extraordinary attention to detail and a relentless pursuit of simplicity. We paid careful attention
Read more
One of the key challenges in any digitization journey is the adoption of machine learning techniques. Given the explosion of tools and frameworks, it can be difficult
Read more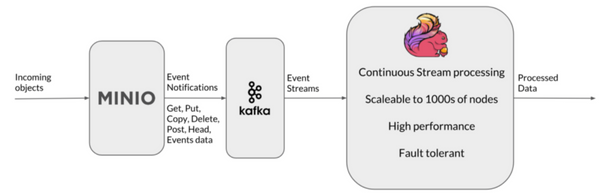
How to use Apache Flink to build a private cloud data pipeline for a variety of use cases.
Read more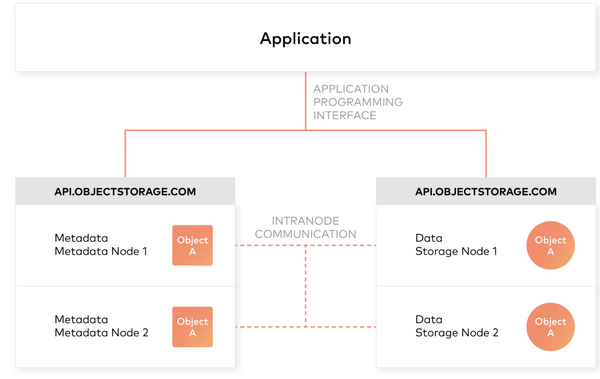
In this post we’ll learn more about object storage, specifically Minio and then see how to connect Minio with tools like Apache Spark and Presto for analytics workloads.
Read more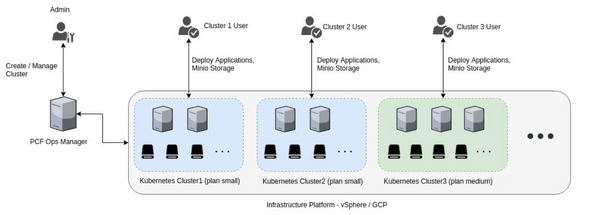
In this post, we learn about Pivotal Container Service deployment and how to use the pks command line tool to create and manage Kubernetes clusters. We also saw how to deploy Minio once your PKS Kubernetes cluster is set up and running.
Read more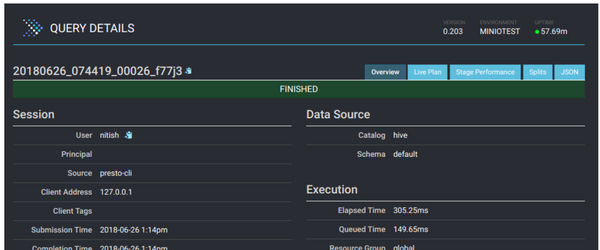
In this post, we learn about why and how Presto is becoming the tool of choice when querying large datasets from platforms like MinIO. We then learn the steps to setup and deploy Presto on private infrastructure.
Read more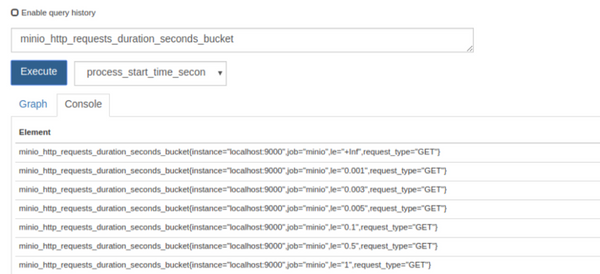
Minio now has built-in support for exporting Prometheus compatible data on an unauthenticated endpoint. This enables Prometheus monitoring for Minio server deployments without sharing server credentials and eliminates the need to run an external Prometheus exporter.
Read more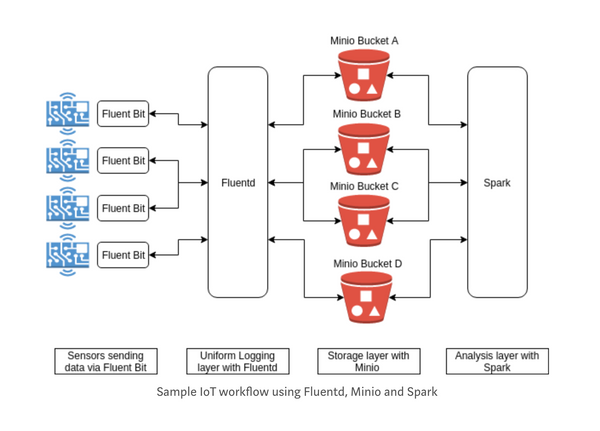
One of the major requirements for success with IoT strategy is the ability to store and analyze device and sensor data. As IoT brings thousands of devices online everyday, the data being generated by all these devices combined is reaching staggering levels. > Storing the IoT data in a scalable yet cost effective manner, while being able to analyze it
Read moreSome our community members have repeatedly asked for Backblaze B2 Cloud Storage and MinIO integration [1] [https://github.com/minio/minio/issues/4072] . B2 is competitively priced and has a huge fan following. We also heard from Backblaze team that they are actively expanding their B2 cloud storage service. We added experimental support for Backblaze B2 backend in MinIO to
Read more





