Data Migration from HDFS to MinIO

Migrate data from HDFS to MinIO and enjoy the benefits of cloud-native architecture.
Read more
Migrate data from HDFS to MinIO and enjoy the benefits of cloud-native architecture.
Read more
The push to standardize Object Storage in Kubernetes has gained significant momentum in the recent months. The new standard, named COSI for Container Object Storage Interface, strikes a similar chord to CSI — a well known standard for consuming storage in Kubernetes. In this article, I’ll dive into COSI, its architecture, and how it fits alongside CSI. Finally, I’ll
Read more
At the beginning of the decade, the total data in the world added up to 2 zettabytes. It has grown to 59 zettabytes today. In a matter of 10 years, it has grown 30-fold. Unstructured data The majority of data that exists today are photos, videos or some kind of point-in-time events. These kinds of data do not have an
Read more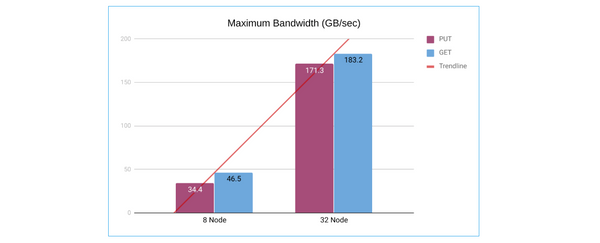
MinIO provides the best-in-class performance as we have repeatedly shown in our previous benchmarks. In those benchmarks, we chose the highest-end hardware and measured if MinIO could squeeze out every bit of the resources afforded it. This proved two key points: 1. Ensuring that MinIO utilizes the maximum possible CPU, Network, and Storage available. 2. Ensuring that MinIO is NOT
Read moreThe fact that MinIO is fast is not a secret. We routinely publish our benchmarks and have put out comparision work against HDFS and AWS (Spark + Presto) in addition to our HDD and NVMe numbers. We recently discovered the availability of large NVMe instances on AWS. Larger than we have ever seen in fact. We procured 32 units of i3en.
Read more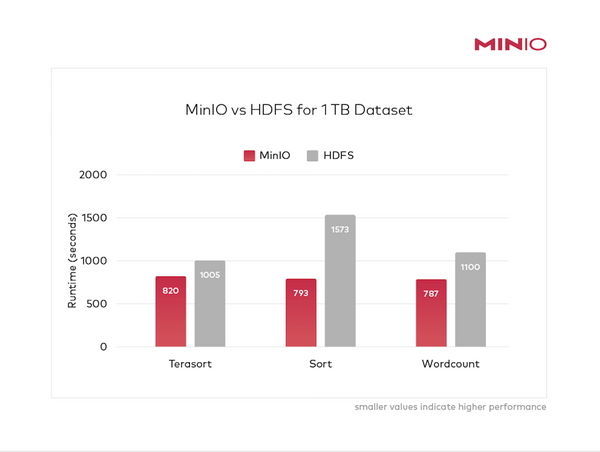
Few would argue with the statement that Hadoop HDFS is in decline. In fact, the HDFS part of the Hadoop ecosystem is in more than just decline - it is in freefall. At the time of its inception, it had a meaningful role to play as a high-throughput, fault-tolerant distributed file system. The secret sauce was data locality. By co-locating
Read more
Apache Spark is a framework for distributed computing. It provides one of the best mechanisms for distributing data across multiple machines in a cluster and performing computations on it. Spark achieves this by constructing data structures called RDDs (Resilient Distributed Datasets). RDDs allow data to be broken into disparate chunks and processed independently of one another. The individual chunks can
Read more
The growth of Presto in the enterprise is a function of its speed, SQL compatibility, extensibility and enterprise feature set. While initially designed to speed up Hadoop, the success of the project has led to much broader adoption - on S3, Cassandra, MySQL, and more. Presto allows for data queries that traverse data stores and locations - a big plus
Read more
Well written software is fast software. When MinIO was conceived it was designed from scratch to be simple, to scale (because simple things scale better) and to be fast. Simplicity and scale have their own subjective and objective measures - but fast is generally a numbers game. When you take well-written, fast software and pair it with fast hardware the
Read more
High performance object storage is one of the hotter topics in the enterprise today. On the one hand, object storage has become an indispensable part of the enterprise storage strategy (public or private cloud) - carrying the vast, vast majority of the enterprise burden when measured in TBs or PBs. On the other hand, object storage has traditionally served a
Read more





