
The Modern Datalake is one-half data warehouse and one-half data lake and uses object storage for everything. The use of object storage to build a data warehouse is made possible by Open Table Formats OTFs) like Apache Iceberg, Apache Hudi, and Delta Lake, which are specifications that, once implemented, make it seamless for object storage to be used as the
Read more

With all the talk in the industry today regarding large language models with their encoders, decoders, multi-headed attention layers, and billions (soon trillions) of parameters, it is tempting to believe that good AI is the result of model design only. Unfortunately, this is not the case. Good AI requires more than a well-designed model. It also requires properly constructed training
Read more

Boundary helps record SSH sessions to meet compliance and improve security requirements. These sessions are then stored on MinIO for fast retrieval for auditing purposes in case of a data breach incident.
Read more

Databricks' acquisition of Tabular, founded by the creators of Apache Iceberg, underscores the importance of open frameworks in modern data lake design. Open frameworks ensure interoperability, flexibility, and simplicity, benefiting those leveraging data for AI.
Read more

Migrate from Hitachi Content Platform (HCP) to MinIO using the HCP-to-MinIO tool. Migration is a no-brainer given how MinIO offers modern, scalable, high-performance storage optimized for AI.
Read more

In this blog, we will demonstrate how to use MinIO to build a Retrieval Augmented Generation(RAG) based chat application using commodity hardware.
Read more
tl;dr:
In this post, we will explore four technical reasons why AI workloads rely on high performance object store.
1. No Limits on Unstructured Data
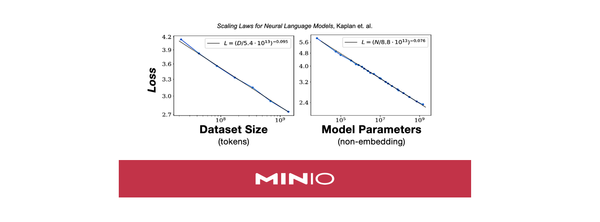
In the current paradigm of machine learning, performance and ability scales with compute, which is really a proxy for dataset size and model size (Scaling Laws for Neural Language Models, Kaplan et. al.). Over
Read more

This post first appeared on The New Stack on June 3rd, 2024.
I previously wrote about the modern data lake reference architecture, addressing the challenges in every enterprise — more data, aging Hadoop tooling (specifically HDFS) and greater demands for RESTful APIs (S3) and performance — but I want to fill in some gaps.
The modern data lake, sometimes referred to as
Read more

Dell ECS's “Data Movement”, also called copy-to-cloud is a feature introduced in ECS 3.8.0.1 that allows you to copy objects from Dell ECS to MinIO which is rather popular with customers and prospects who are modernizing their storage stack to support their AI data infrastructure requirements.
Read more

Unlock Snowflake's potential by integrating external tables with MinIO. Seamlessly query external data without migration, boost analytics, save costs, and simplify access. This setup provides real-time insights and maximizes your infrastructure investment for both MinIO and Snowflake.
Read more

What has become clear over the past couple of years is that the public cloud, for all of its benefits, doesn't deliver cost savings at scale. It delivers productivity gains, to a point, but it will not reduce your costs. There is goodness in the public cloud as it offers an incredibly powerful value proposition—infrastructure available immediately,
Read more

In this blog post, we’ll show you how to set up MinIO to work with Keycloak. But broadly it should also give you an idea of how OIDC is configured with MinIO so you can use it with anything other than Keycloak, here we just use it as an example.
Read more

Streamline your data processing capabilities, ensuring high-quality data management and secure operations. This integration not only enhances workflow automation but also leverages the advanced functionalities of MinIO and Tailscale, providing a powerful solution for modern data processing needs.
Read more

Snowflake's support for external tables has seen significant updates since our last blog post on how to extend your Snowflake implementation with MinIO. External tables allow users of Snowflake to treat data in object storage like MinIO as a read-only table in Snowflake without migration. Snowflake's ongoing enhancements to their external table functionality clearly demonstrate the
Read more

Whether you are on-prem or in the Cloud, you want to ensure in the cloud operating model processes are set up in a homogenous way. This tutorial will give you a full overview of how you can surface MinIO audit logs in ElasticSearch so they can be searchable.
Read more

We are excited to announce our first technical certification, the MinIO Certified Administrator - Practitioner. The MinIO certified professional program is designed to validate an individual's practical skills administrating MinIO. For the practitioner level exam, candidates will need working knowledge of all core features and capabilities including deployment, bucket creation, versioning, life cycle management, replication, encryption, and authentication,
Read more

Discover how MinIO Catalog optimizes resource utilization. With real-time insights from powerful GraphQL queries, MinIO Catalog helps organizations streamline storage, cut costs, and enhance data security. Learn to manage your data efficiently and make smarter decisions.
Read more

In my previous post on MLRun, we set up a development machine with all the tools needed to experiment with MLRun. Specifically, we used a docker-compose file to create containers for the MLRun UI, the MLRun API Service, Nuclio, MinIO, and a Jupyter service. Once our containers started, we ran a simple smoke test to ensure everything was working correctly.
Read more

MinIO’s co-founder and CEO AB Periasamy was recently featured on the AI in Business Podcast where he had a rich conversation with Matthew DeMello—Senior Editor at Emerj—about AI infrastructure and object storage for enterprises.
In this blog post, we take you through an abridged version of what was discussed. Let’s get into it.
AB and Matthew
Read more







