Spelunk through your AI data infrastructure with Splunk

In this post we explain how to use Splunk's advanced log analytics to help understand the performance of AIStor and the data under management.
Read moreA collection of 126 posts tagged with "AI/ML"
In this post we explain how to use Splunk's advanced log analytics to help understand the performance of AIStor and the data under management.
Read more
The modern enterprise defines itself by its data. This requires a data infrastructure for AI/ML as well as a data infrastructure that is the foundation for a Modern Datalake capable of supporting business intelligence, data analytics, and data science. This is true if they are behind, getting started or using AI for advanced insights. For the foreseeable future, this
Read more
The team at Insight Partners just released their State of Enterprise Tech report for 2024. There is a lot to consume in the 60+ slides, but we cherry picked the things that should be interesting to our audience - and frankly there is a lot of interesting stuff. I will leave the survey methodology stuff for you to consume, but
Read more
An embedding subsystem is one of four subsystems needed to implement Retrieval Augmented Generation. It turns your custom corpus into a database of vectors that can be searched for semantic meaning. The other subsystems are the data pipeline for creating your custom corpus, the retriever for querying the vector database to add more context to a user query, and finally,
Read more
One of the reasons that MinIO is so performant is that we do the granular work that others will not or cannot. From SIMD acceleration to the AVX-512 optimizations we have done the hard stuff. Recent developments for the ARM CPU architecture, in particular Scalable Vector Extensions (SVE), presented us with the opportunity to deliver significant performance and efficiency gains
Read more
With all the talk in the industry today regarding large language models with their encoders, decoders, multi-headed attention layers, and billions (soon trillions) of parameters, it is tempting to believe that good AI is the result of model design only. Unfortunately, this is not the case. Good AI requires more than a well-designed model. It also requires properly constructed training
Read more
Migrate from Hitachi Content Platform (HCP) to MinIO using the HCP-to-MinIO tool. Migration is a no-brainer given how MinIO offers modern, scalable, high-performance storage optimized for AI.
Read more
In this blog, we will demonstrate how to use MinIO to build a Retrieval Augmented Generation(RAG) based chat application using commodity hardware.
Read more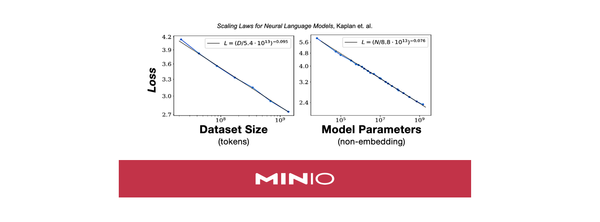
tl;dr: In this post, we will explore four technical reasons why AI workloads rely on high performance object store. 1. No Limits on Unstructured Data In the current paradigm of machine learning, performance and ability scales with compute, which is really a proxy for dataset size and model size (Scaling Laws for Neural Language Models, Kaplan et. al.). Over
Read more
This post first appeared on The New Stack on June 3rd, 2024. I previously wrote about the modern data lake reference architecture, addressing the challenges in every enterprise — more data, aging Hadoop tooling (specifically HDFS) and greater demands for RESTful APIs (S3) and performance — but I want to fill in some gaps. The modern data lake, sometimes referred to as
Read more
Do you know the secret to some of the best AI models out there? It's the amount of data they had access to on which they could be trained on. For AI/ML models Fast accessible Data is King. Let me emphasize, it's not just Data, but fast accessible Data.
Read more
Dell ECS's “Data Movement”, also called copy-to-cloud is a feature introduced in ECS 3.8.0.1 that allows you to copy objects from Dell ECS to MinIO which is rather popular with customers and prospects who are modernizing their storage stack to support their AI data infrastructure requirements.
Read more
Streamline your data processing capabilities, ensuring high-quality data management and secure operations. This integration not only enhances workflow automation but also leverages the advanced functionalities of MinIO and Tailscale, providing a powerful solution for modern data processing needs.
Read more
Whether you are on-prem or in the Cloud, you want to ensure in the cloud operating model processes are set up in a homogenous way. This tutorial will give you a full overview of how you can surface MinIO audit logs in ElasticSearch so they can be searchable.
Read more
In my previous post on MLRun, we set up a development machine with all the tools needed to experiment with MLRun. Specifically, we used a docker-compose file to create containers for the MLRun UI, the MLRun API Service, Nuclio, MinIO, and a Jupyter service. Once our containers started, we ran a simple smoke test to ensure everything was working correctly.
Read more
MinIO’s co-founder and CEO AB Periasamy was recently featured on the AI in Business Podcast where he had a rich conversation with Matthew DeMello—Senior Editor at Emerj—about AI infrastructure and object storage for enterprises. In this blog post, we take you through an abridged version of what was discussed. Let’s get into it. AB and Matthew
Read more
MLOps is to machine learning what DevOps is to traditional software development. Both are a set of practices and principles aimed at improving collaboration between engineering teams (the Dev or ML) and IT operations (Ops) teams. The goal is to streamline the development lifecycle, from planning and development to deployment and operations, using automation. One of the primary benefits of
Read more
In this tutorial, we'll deploy a cohesive system that allows distributed SQL querying across large datasets stored in Minio, with Trino leveraging metadata from Hive Metastore and table schemas from Redis.
Read more
When a MinIO Modern Datalake deployment is extended by adding a new server pool, by default it does not rebalance objects. Lets dive deep and learn how to rebalance smoothly without affecting cluster operations.
Read more
Implementing KES within Kubernetes in a stateful configuration ensures the persistence of encryption keys through pod lifecycle events and restarts. This setup offers resilience especially in environments where relying on external KMS is not an option or preferred.
Read more





