Accelerating Issue Resolution With A Modern Data Lakehouse Built on MinIO AIStor

Executive Summary
AMD, a global leader in high-performance computing, graphics, and semiconductor technologies, faced challenges with its internal engineering systems. Their systems, including ServiceNow, Jira, GitHub repositories, telemetry pipelines, and infrastructure logs, were developed independently over time, but they were deeply interconnected. This created data silos that obscured the connections across the engineering lifecycle, hindering AMD's agility in engineering, development, and management necessary to meet evolving company and market demands..
AMD tackled this challenge by launching a cutting-edge enterprise Data Intelligence Platform. This platform automatically links system issues back to their root cause, allowing for a complete trace of the problem chain. This includes identifying the corresponding GitHub commit, infrastructure components, owner history, and the ultimate origin of the issue.
The solution involves a modern data lakehouse built on MinIO AIStor, utilizing a GraphRAG engine. This engine connects tickets, code, logs, and telemetry into a graph-aware data intelligence layer that empowers both human teams and AI agents to reason across diverse systems, ultimately delivering faster, more cost-effective results and improving overall business productivity.
Outcome:
- Zero‑ETL approach, reducing pipeline complexities and duplicate stores; where one Iceberg OTF and a robust ONS foundation that now serves both SQL and graph analytics for faster, more accurate results.
- Agents and workflows reason over live enterprise data; the system connects intelligence across systems, not just collects data, resulting in faster issue resolution.
AIStor is the data foundation of this data lakehouse architecture, storing raw data, logs, and telemetry and serving Iceberg tables that power SQL, graph, and agent reasoning without replicating data.
The Challenge
Large enterprises operate with deeply interconnected processes where information flows across dozens of systems at every stage, ticketing tools like ServiceNow, source-code platforms like GitHub, CI/CD pipelines, monitoring systems, infrastructure inventories, identity directories, logging, alerting systems and more. Because each system captures only a fragment of the overall truth, it becomes extremely difficult to perform root-cause analysis or trace cascading failures across this maze of disconnected data. A seemingly small issue in one system can ripple across teams and technologies, yet the team must manually stitch together context from siloed logs, commits, incidents, owners, and infrastructure components. This fragmentation slows response times, increases operational risk, and forces organizations into reactive firefighting rather than proactive intelligence.
Some specific pain points encountered were:
- Relational joins struggled with multi‑hop questions (e.g., issue → component → engineer → previous fix); sharply increasing complexity and latency issues.
- Traditional graph databases required ETL and data duplication out of the lake, plus separate infrastructure, which was impractical for production.
The Vision
They decided to launch an enterprise Data Intelligence Platform, so a problem in one system (e.g., ServiceNow) would automatically relate to its corresponding GitHub commit, infrastructure component, and owner history in order to speed issue resolution. Key elements of this desired state were:
- Core technology requirements: query data in place, sub‑second traversal latency, and direct integration with LangChain for agentic workflows.
- An enterprise “knowledge graph” that turns AMD’s internal data into connected, living context for humans and agents to be more productive.
- AI-driven reasoning across systems (tickets, logs, telemetry, code, components, owners) to drive issue determination.
- Natural‑language questions → operational answers via agents.
- No data movement; one open data foundation for SQL, graph, and AI.
Solution
AMD utilized a GraphRAG engine on a data lakehouse built on MinIO AIStor for the object-native (ONS) data storage layer and the embedded open table format (OTF) based on Apache Iceberg to connect tickets, code, logs, and telemetry into a graph‑aware data intelligence layer, enabling both teams and AI agents to reason across systems faster and with less complexity.
The stack keeps all data in place and eliminates duplicate stores: MinIO AIStor serves as the unified object store, with Apache IcebergTM (Nessie catalog) for open tables, Dremio for SQL, PuppyGraph for GraphRAG on Iceberg, and LangChain + Microsoft AutoGen orchestrating agents (using Claude Opus 4 as the agent LLM and GPT‑4o as the critic LLM).
Workloads & Footprint:
- Central storage in MinIO AIStor; Apache Iceberg tables organized and versioned by Nessie; Spark for data optimization; Dremio for SQL and copy/merge operations.
- PuppyGraph connects directly to Iceberg to enable the graph foundation required for RAG in place.
- LangChain translates natural‑language prompts and Microsoft AutoGen manages multi‑agent workflows with Claude Opus 4 (agent LLM) and GPT‑4o (critic LLM).
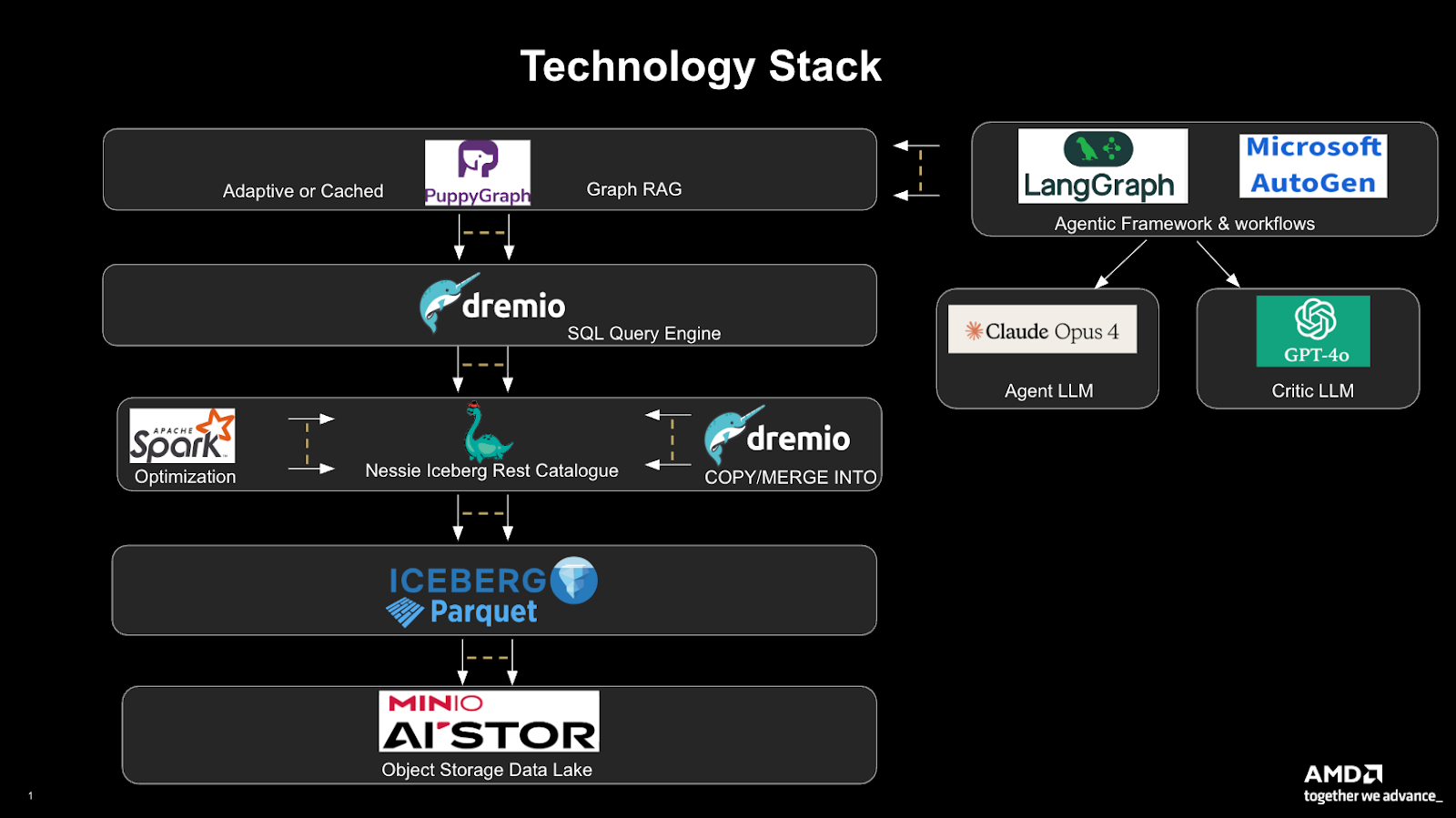
Architecture:
- MinIO AIStor as the data lakehouse for raw data, logs, telemetry.
- Apache Iceberg provides open tables (schema evolution, time travel); Nessie supplies the Iceberg REST catalog with version control and atomic branching.
- Spark handles optimization and preprocessing to keep Iceberg performant.
- Dremio powers SQL and copy/merge operations for federated access.
- PuppyGraph exposes a zero‑ETL graph query engine that connects directly to Iceberg, executes Cypher in place, and virtualizes the knowledge graph from Iceberg tables.
- LangChain translates natural‑language prompts (e.g., “Which systems are most affected by repeated outages?”) into executable Cypher; Microsoft AutoGen coordinates multi‑agent workflows using Claude Opus 4 (agent) and GPT‑4o (critic).
Data Flow:
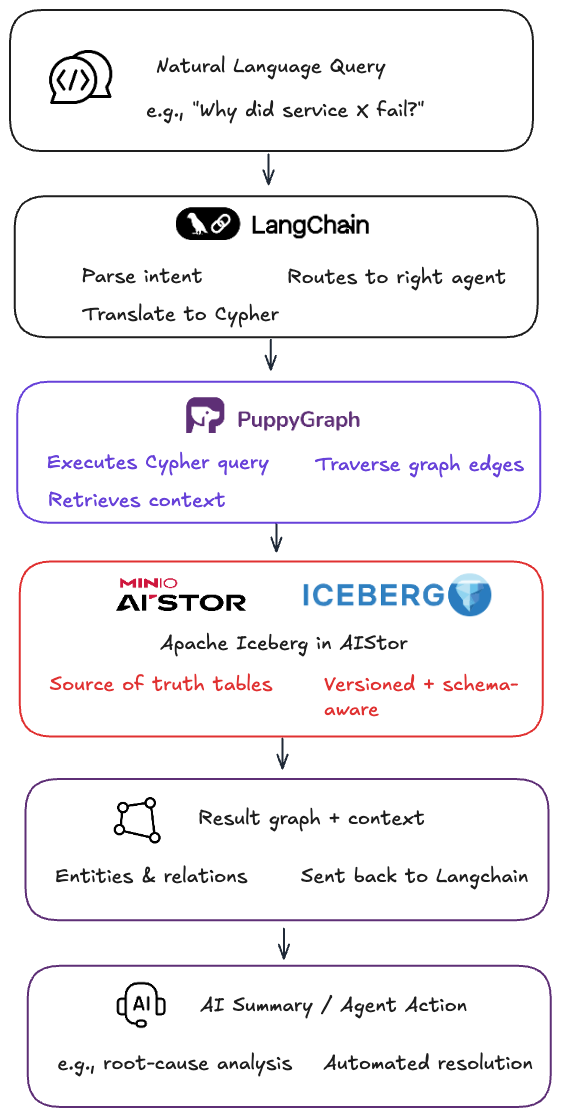
- Data stored in AIStor and organized into Iceberg tables.
- Nessie catalogs/versions tables; Spark optimizes and updates.
- Dremio enables fast SQL and merge ops across Iceberg datasets.
- PuppyGraph connects directly, requiring no ETL or a separate graph database, and executes Cypher traversals.
- LangChain converts NL prompts and routes via Microsoft AutoGen.
- Claude Opus 4 and GPT‑4o provide reasoning and validation, returning contextual answers to dashboards/chat.
Results & Outcomes
- Data movement: Eliminated ETL pipelines and duplicate stores by running graph directly on Iceberg in MinIO AIStor.
- Foundation: The unified Iceberg layer now powers both Dremio SQL and Cypher graph queries, providing one foundation for analytics, graph reasoning, and AI.
- Agents: With Claude Opus 4 and GPT‑4o in a feedback loop, results are validated/refined before surfacing in dashboards or chat.
These outcomes stem from query‑in‑place on open tables stored in AIStor. This keeps data versioned and schema‑aware while serving SQL and graph without duplication.
Editor’s note:
This case study is based on the talk “GraphRAG on Iceberg” presented by Rajdeep Sengupta, Director of Systems Engineering at AMD, during the Bay Area Apache Iceberg Meetup on October 1, 2025 in San Francisco., which is also discussed in this article
You can watch the full recording here:
To learn more about how MinIO AIStor can help your organization, contact us using the button below or download a trial version of AIStor here






