Achieving Your Data Strategy with MinIO

In the Harvard Business Review's recent How Companies Think About Data, Leandro DalleMule and Thomas H. Davenport present "a framework for building a robust data strategy that can be applied across industries and levels of data maturity." The framework draws on their experience at AIG, a global insurance company where Mr. DalleMulle is CDO, combined with a study of a handful of other large companies and how they use data to support managerial decision-making and improved financial performance.
The framework includes a strategy that enables superior data management and analytics, two must-haves in order to derive the most value from corporate data. The framework is designed to help companies clarify the primary purpose of their data and execute the right steps for strategic data management.
In the framework, data can serve an "offensive" or "defensive" purpose and businesses must make trade-offs between these purposes and between control and flexibility. Data defense and offense have different business objectives and ways of working with data.
Data defense exists to minimize business risk – ensuring regulatory compliance, detecting and addressing fraud and building applications to prevent inventory loss and theft. The goal of data defense is to ensure the integrity and security of data used by an enterprise's systems by "identifying, standardizing and governing authoritative data sources…in a single source of truth."
Data offense, in contrast, focuses on supporting business objectives and typically includes activities that generate customer insights (analytics and modeling) or integrate customer and other data to support decision-making. Data offense typically falls under sales and marketing, while data defense falls under legal, financial, compliance and IT.
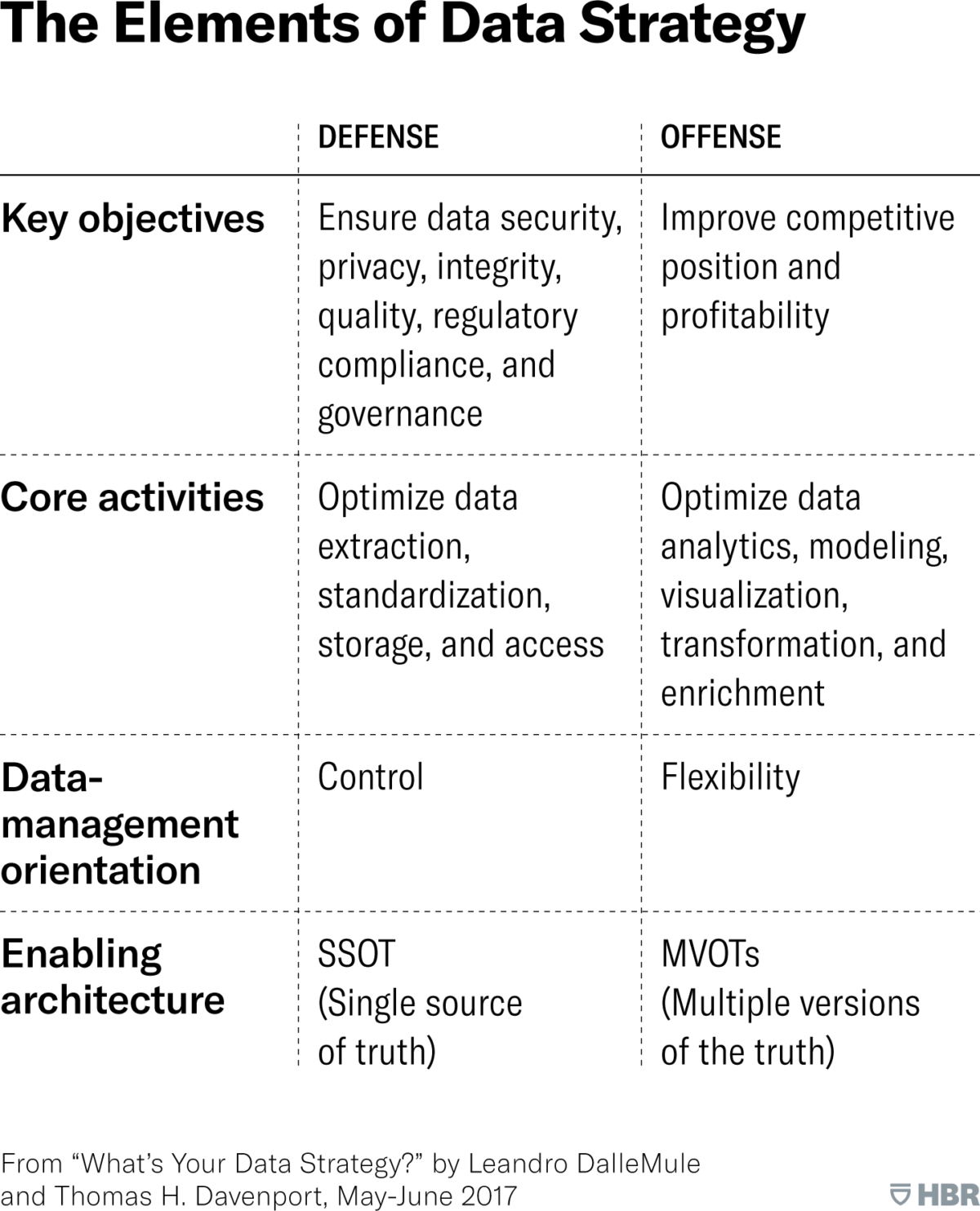
Every company needs both offense and defense to succeed, however, "the two compete fiercely for finite resources, funding and staff." In order to make the greatest use of data, both need to be balanced. Herein lies the greatest challenge for CDOs and other C-level executives – to establish the appropriate trade-offs between offense and defense and to balance them in support of the company's overall strategy. Balancing offense and defense often keys on balancing data control and flexibility – more control means defense and more flexibility means offense.
Many enterprises have approached data as something that must be controlled, with access given reluctantly, yet "these top-down approaches are not well suited to supporting a broad data strategy." Instead, "a more flexible and realistic approach" is to build a single source of truth (SSOT) and multiple versions of the truth (MVOT). The SSOT exists to hold all data and MVOTs exist to manage data and provide limited access to those who require it.
As a result of their research, Dallemule and Davenport conclude that the concept of an SSOT "is fully grasped and accepted by IT and across the business." More importantly though, "the idea that a single source of truth can feed multiple versions of the truth (such as revenue figures that differ according to the users' needs) is not well understood."
Enterprises require flexible architectures that allow single and multiple versions of the truth to support data offense and defense. Having no SSOT creates data chaos as teams create and store data in silos. The process is inefficient and expensive and typically results in a general distrust in the accuracy of the organization's data. Companies with dozens of data sources, each similar but slightly different, each relied on by a different business unit, lack an SSOT and therefore lack confidence in their data. The authors present a simple case study where a manufacturer leveraged AI tools to sift through various data silos and assemble an SSOT that could be accessed by multiple business units. In the first year, the new SSOT created $75 million in benefits. Another large finserv company consolidated nearly 130 data silos around the world into an SSOT. The resulting decrease in operating expenses yielded a 190% ROI within two years.
To see the SSOT-MVOT system at work, the authors present a global asset management company where marketing and finance both produced monthly reports on ad spending. Marketing reported on the ad's effectiveness while finance reported on spending when the invoices were paid. This is an example of MVOTs derived from an SSOT, and the reports contain different numbers, but each is accurate in context. This is a natural result of a process that involves an SSOT and the controlled data transformations needed to build an MVOT.
Data Lakes Bring Data Strategies to Life
Without cloud-native object storage, it is nearly impossible to build an efficient and controlled SSOT-MVOT data architecture. Traditional data warehouses, such as Hadoop, that store structured enterprise data hierarchically on a filesystem cannot accommodate today's massive volume of data.
In contrast, the data lake is used to store unlimited amounts of structured, semi-structured and unstructured data – database tables, open format tables, spreadsheets and even audio and video files.
The data lake is the ideal platform for the controlled yet flexible SSOT-MVOT architecture for which Dallemule and Davenport advocate. This is, in fact, consistent with the architectures that we see our customers implement when modernizing their data platforms. A central data lake – the SSOT – is fed with detailed data, down to the level of individual transactions if desired, from all over the enterprise.
Data in the SSOT is queried, aggregated, transformed and enriched – there are infinite options in the cloud-native world – to create MVOTs. Both are stored in the data lake, secured and protected against loss or corruption, and available to any app that speaks S3.
Successful Data Lakes are Built on MinIO
Customers buy MinIO in order to embrace cloud-native technologies and leave behind legacy storage technologies like file and block, SAN and NAS. Using S3-API-compatible MinIO as a storage layer enables all kinds of infrastructure pluses, such as disaggregation of storage and compute, versioning/continuous data protection, fault tolerance, massive concurrency, infinite scalability, zero downtime and a better developer experience. Please see The Architects Guide to the Modern Data Stack for more details regarding the importance of a cloud-native S3 backend.
High-performance object storage like MinIO is used as the primary storage for data and the applications that work with it. Examples include Neon, Snowflake, Warpstream, Dremio, Apache Druid, LanceDB, Motherduck, Bauplan and Datadog. Please see Object Storage is Primary Storage for more examples of this widely implemented architecture.
The fundamental advantage of this architecture is that there is complete disaggregation of storage and compute, enabling fault tolerance and elastic scaling with Kubernetes. Enterprises use MinIO to build their own private clouds, with MinIO's erasure coding providing more efficient data durability than legacy methods like replication and RAID.
A properly designed and implemented MinIO deployment is highly available, infinitely scalable, immutable and highly durable. Building on top of MinIO as a persistence layer creates compelling cost advantages. Not only can enterprises leverage open-source software, they also no longer need to overprovision as a result of decoupling storage and compute.
Bring Your Data Strategy to Life
Building on top of MinIO gives you everything developers need to create the analytics and AI/ML apps that your business needs to excel. All of the functionality that we built into MinIO that makes it cloud-native and Kubernetes-native simplifies life for DevOps teams. They can now tap into the same features and architecture that the leading database, analytics and AI/ML service providers use. This has given rise to new paradigms in enterprise data usage and has resulted in the next generation of data-intensive startups.
Legacy architectures built around SAN and NAS, file, block and HDFS cannot compete with the availability, durability, performance and scalability of on-premise MinIO. With the recent focus on serverless computing, it's also important to note that there is no serverless computing without MinIO and the S3 API.
Startup or enterprise, the way to the future is a modular, composable cloud-native data stack built on top of open table formats like Apache Iceberg and Delta, leveraging open file formats like Parquet and open memory formats like Apache Arrow. Building on MinIO drastically simplifies the data lake and the applications that access it.
Download MinIO today and see how easy it is to build a cloud-native on-premise data lake. Then join our community Slack, ask questions and show off what you've built.






