AIStor Integration with NVIDIA NIM™

Building upon AIStor's robust AI capabilities, MinIO's PromptObject has been enabling users to interact with their data through natural language queries as described here. PromptObject transforms how users interact with stored objects by allowing them to ask questions about their data's content and extract information using natural language—eliminating the need to write complex queries or code. Today, we're expanding these capabilities by adding support for NVIDIA NIM™, providing users with a powerful, GPU-accelerated option for AI model deployment and management directly from the Global Console. This integration enhances PromptObject's existing features by bringing NVIDIA's optimized inference capabilities to your data layer, creating new possibilities for how users can leverage AI to interact with their stored data. Let's dive into how this integration works and its benefits.
Understanding NVIDIA NIM
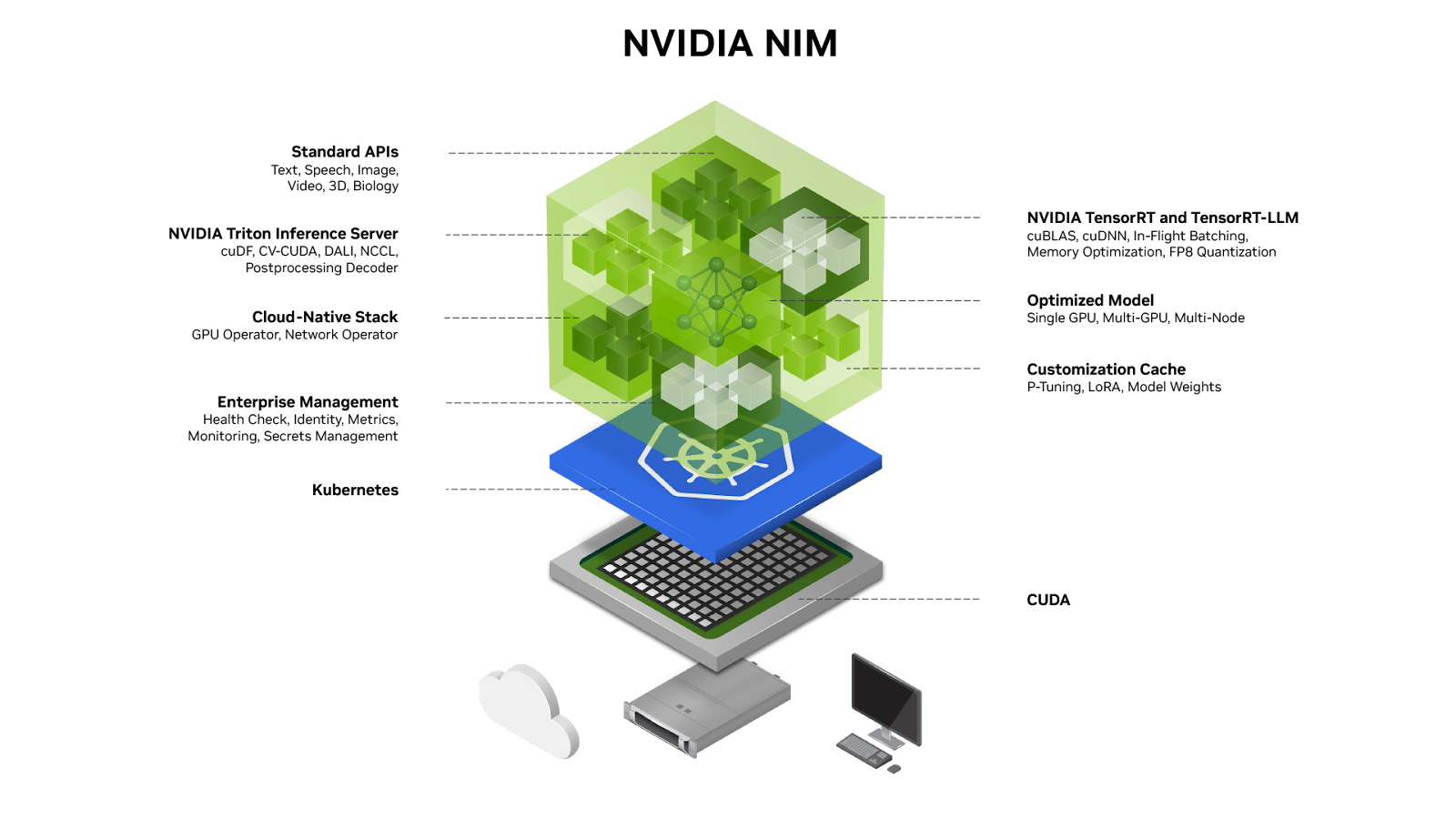
NVIDIA NIM, part of NVIDIA AI Enterprise, is a set of easy-to-use microservices designed for secure, reliable deployment of high-performance AI model inferencing across workstations, data centers, and the cloud. These prebuilt containers support a broad spectrum of AI models—from open-source community models to NVIDIA AI Foundation models, as well as custom AI models. NIM microservices are deployed with a single command for easy integration into enterprise-grade AI applications using standard APIs and just a few lines of code. Built on robust foundations, including inference engines like NVIDIA Triton Inference Server™, TensorRT™, TensorRT-LLM, and PyTorch, NIM is engineered to facilitate seamless AI inferencing at scale, ensuring that you can deploy AI applications anywhere with confidence. Whether on-premises or in the cloud, NIM is the fastest way to achieve accelerated generative AI inference at scale.
NIM Deployment Lifecycle
NIM follows a straightforward deployment lifecycle that ensures efficient model deployment and initialization. Below is the official flow from NVIDIA's documentation showing how NIM containers operate:

Reference: NVIDIA NIM Documentation
This lifecycle illustrates several key aspects of NIM deployment:
- Container Initialization: Begins with a simple docker run command
- Intelligent Model Management: Checks for local model availability before downloading
- NGC Integration: Automatic model downloading from NVIDIA NGC when needed
- API Compatibility: Launches an OpenAI-compatible REST API server for standardized access
MinIO AIStor's integration with NIM automates this entire lifecycle, handling the container deployment, model management, and API setup through its intuitive interface.
Key benefits of NIM include:
- Pre-optimized inference engines powered by NVIDIA TensorRT and TensorRT-LLM
- Industry-standard APIs for straightforward integration
- Optimized response latency and throughput for specific GPU configurations
- Support for model customization and fine-tuning
AIStor's Integration with NIM
MinIO's AIStor simplifies AI-powered interactions with stored objects through the NVIDIA NIM microservices integration. Both services run within the same Kubernetes cluster, providing seamless integration while allowing external access through standard APIs. Here's the core workflow:
- Go to the Object Store where you want to enable PromptObject.
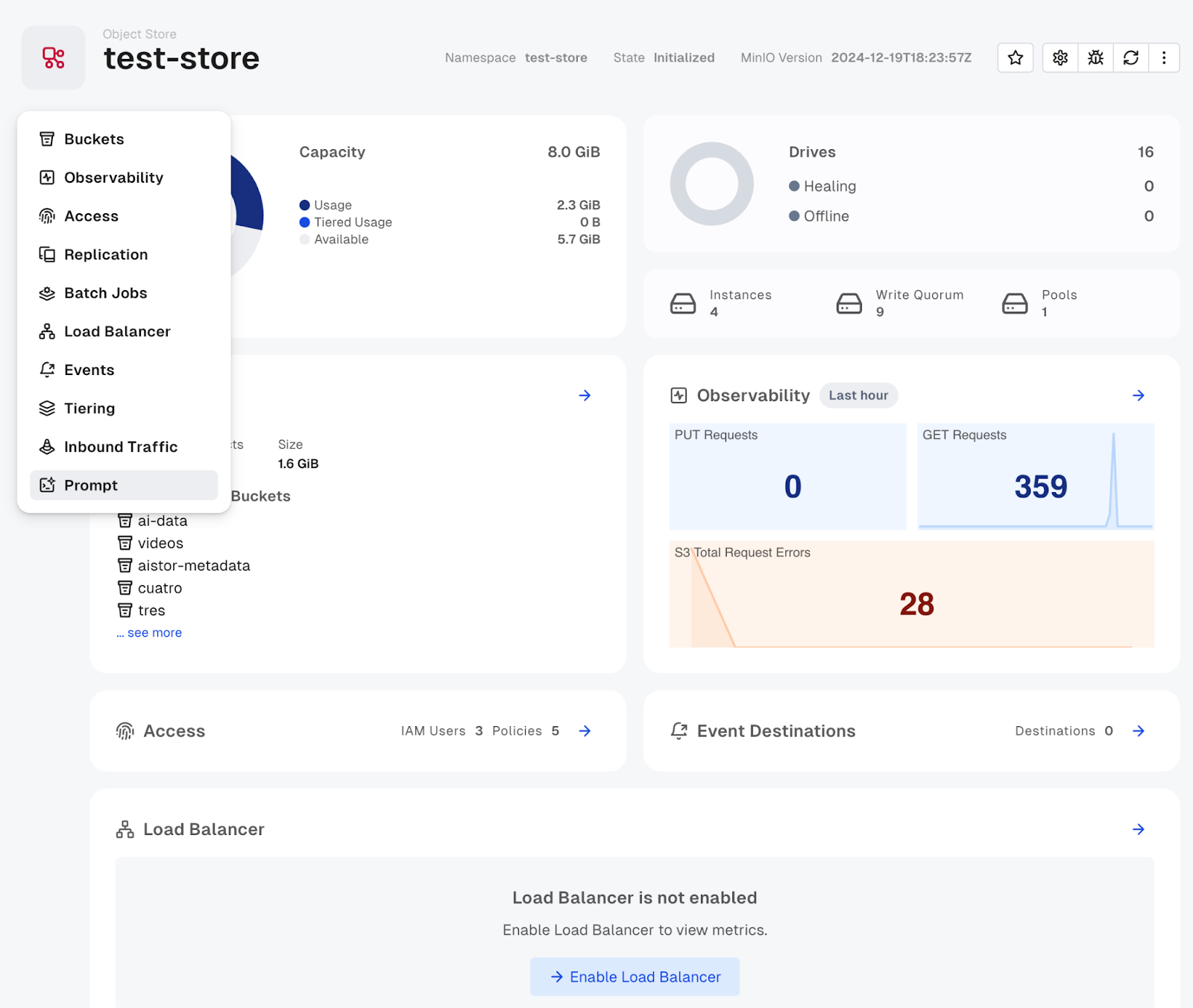
- Click the Enable Prompt Object button.
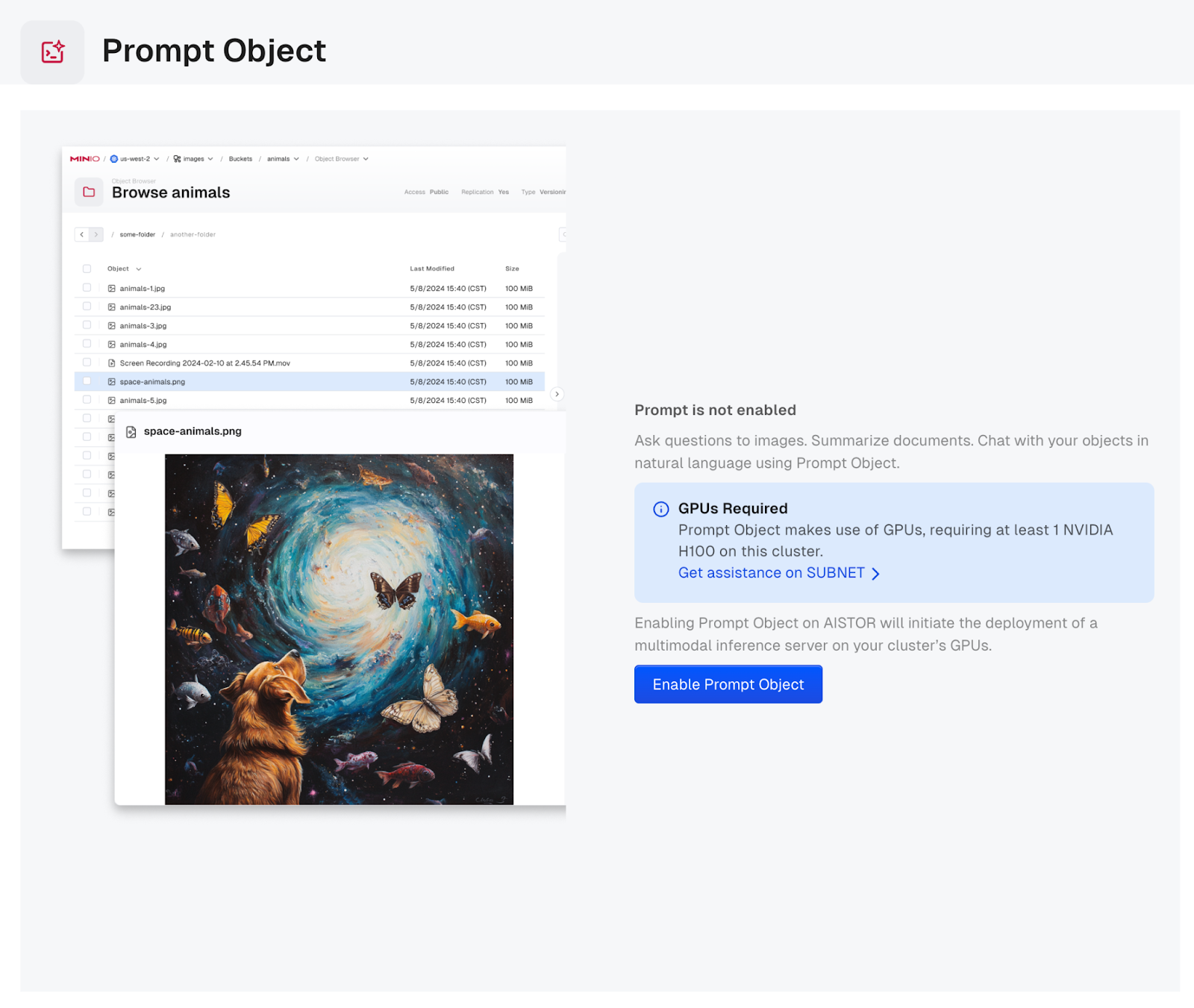
- Configure the NIM Inference Settings: AIStor offers 2 options here.
- Deploy NIM microservices in your own Kubernetes cluster using official NIM prebuild image as shown below:
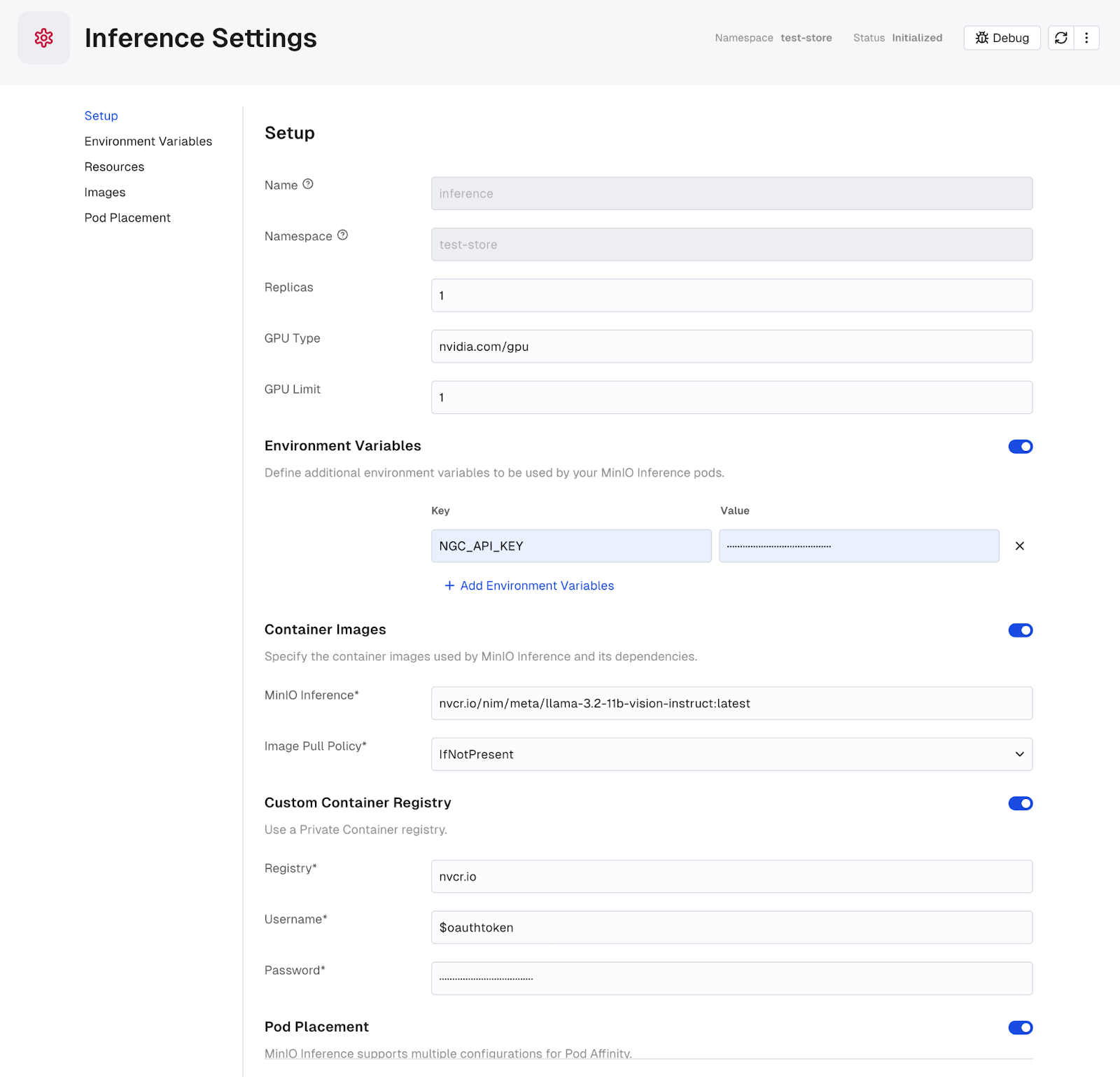
In this step, you will need to provide the necessary configuration details for deploying the NIM container. This includes specifying the GPU type, replica count, resource limits, container image, and environment variables. Once done, click the Save button.
Note: You can get the NGC_API_KEY from the NVIDIA NGC Docs by following the instructions. In the example above we are using the meta/llama-3.2-11b-vision-instruct that uses 1 GPU resource to get started. You can get a list of all the supported models from here and the GPU requirements for these models here. Since we already have the NVIDIA GPU Operator installed as part of the AIStor setup (see the AIStor GPU support blog for more details) in the cluster, AIStor can leverage the GPU resources to run the NIM container.
b. NVIDIA Hosted NIM Service
If you don’t have GPUs available, you can get started by making use of NVIDIA’s hosted NIM servers by enabling Use External Inference toggle in AIStor Global console and providing the OpenAI API compatible endpoint (https://integrate.api.nvidia.com/v1). You will also need to provide the NGC API Key as OPENAI_API_KEY and the MODEL environment variable that will be the default model used by PromptObject.

- Go to the Object Browser and select the object you want to interact with.
- Click on the button to start interacting with the object using natural language.
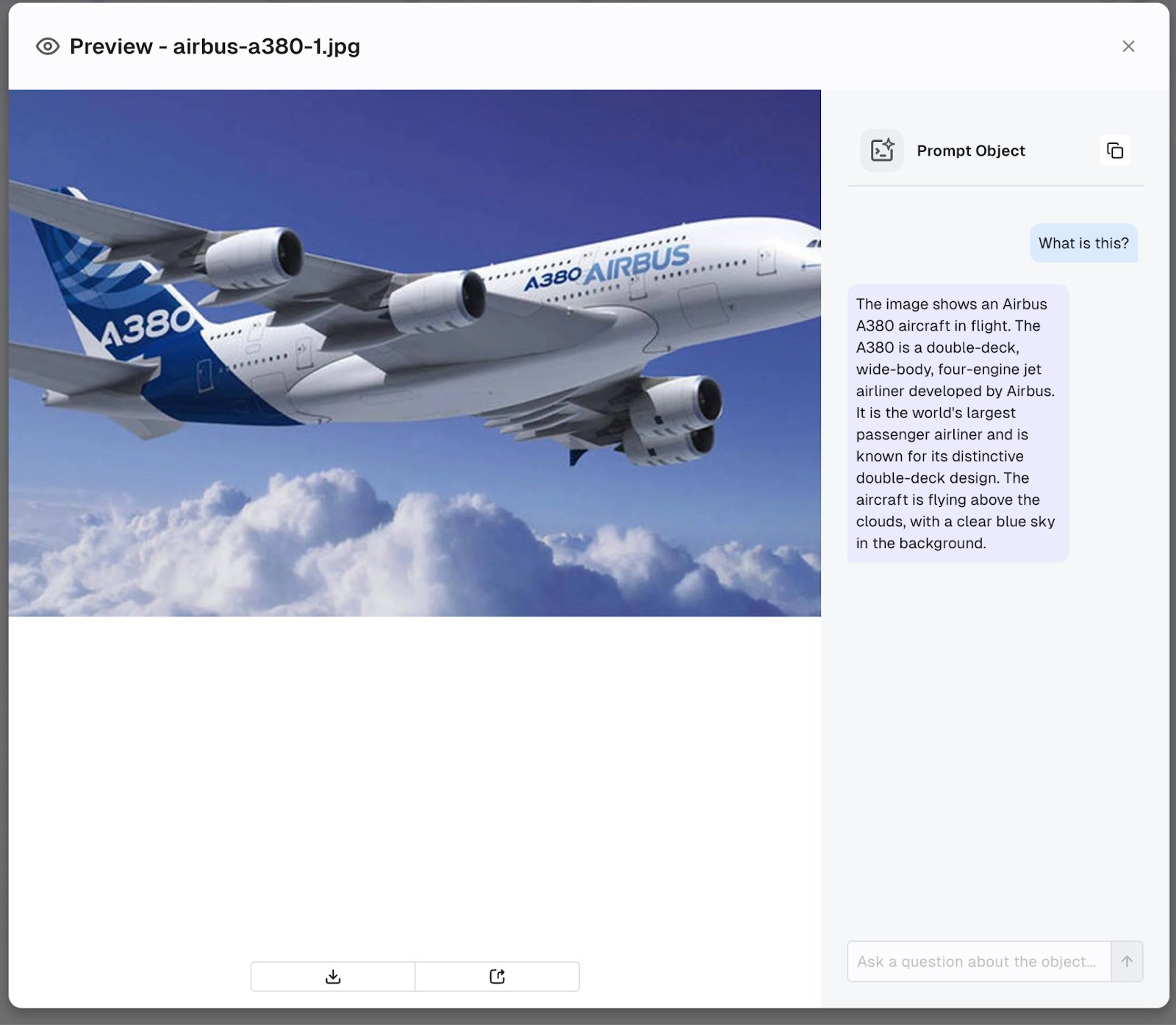
Apart from this, you can use the `PromptObject` API via MinIO SDKs outside the K8s cluster, as shown in the flow diagram below:
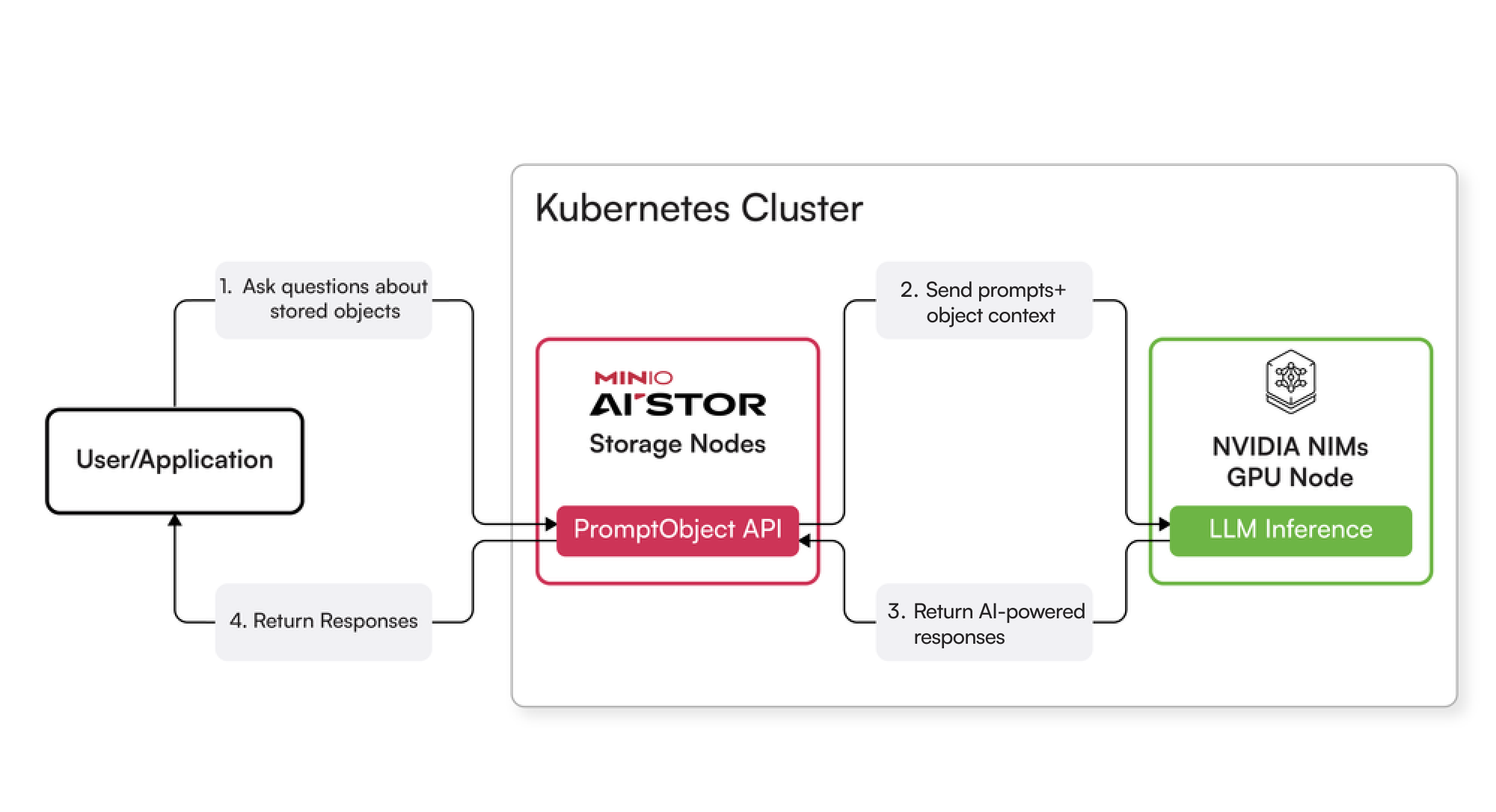
This deployment architecture enables:
- Unified management of both storage and AI services within Kubernetes
- Secure and efficient internal communication between AIStor and NIM microservices
- Easy external access through standard S3-compatible APIs
- Scalable infrastructure that can grow with your needs
Benefits for Users
This integration brings several key advantages:
- Simplified Deployment
- One-click deployment of AI models
- No additional infrastructure setup required
- Integrated with existing MinIO authentication
- Optimized Performance
- Hardware-optimized inference using TensorRT
- Reduced latency for real-time applications
- Efficient resource utilization
- Direct Model Access
- Seamless access to NVIDIA's optimized AI models
- Support for custom fine-tuned models
- Automatic model optimization for available GPU resources
- Enhanced Security
- Integrated authentication
- Secure model deployment
- Container security features
- Scalability
- Kubernetes-native scaling
- Multiple replica support
- Resource-aware deployment
Real-World Applications
The integration enables several powerful use cases:
- Document Analysis
- Natural language querying of stored documents
- Automatic content summarization
- Semantic search capabilities
- Media Processing
- Automated image and video analysis
- Content classification
- Feature extraction
- Data Insights
- Interactive data exploration
- Automated report generation
- Pattern recognition
Conclusion
MinIO's integration of NVIDIA NIM into AIStor represents a significant step forward in making AI capabilities more accessible within object storage systems. By simplifying the deployment and management of AI models while maintaining high performance and security, this integration enables organizations to more effectively leverage their stored data for AI-powered insights and automation.
The combination of MinIO's efficient object storage, the PromptObject API's natural language capabilities, and NVIDIA's optimized inference services creates a powerful platform for organizations looking to implement AI capabilities within their existing storage infrastructure. To learn more about the PromptObject capabilities check out these topics: Chat With Your Objects Using the Prompt API and Talk to Your Data: Transforming Healthcare with AI-Powered Object Storage. If you want to go deeper and get a demo, we can arrange for that as well. As always, if you have any questions join our Slack Channel, or drop us a note at hello@min.io.
References
- NVIDIA NIM Documentation: https://developer.nvidia.com/nim
- MinIO AIStor Documentation: https://min.io/product/aistor/prompt-ai
- NVIDIA TensorRT: https://developer.nvidia.com/tensorrt






