Anomaly Detection from Log Files: The Performance at Scale Use Case

Driving competitive advantage by employing the best technologies separates great operators from good operators. Discovering the hidden gems in your corporate data and then presenting key actionable insights to your clients will help create an indispensable service for your clients, and isn’t this what every executive wishes to create?
Cloud-based data storage (led by the likes of Amazon S3, Google Cloud Storage and Azure Blob Storage) has replaced traditional file and block storage due to its simplicity and scalability. I remember my friend Dr Peter Bramm (founder of Luster) talking about the intergalactic file system in the late 1990s, which was an object storage platform, but the complexity of the system limited its deployments to large DOE/DOD clusters. The explosive growth of data and the simplicity of Amazon’s S3 protocol changed the storage landscape and today object storage is primary storage for everything from databases to analytics and AI/ML workloads.
Cloud-based object storage made it easy for organizations to move their data into the cloud, however the economics of public cloud deployments require constant attention. Ballooning bill syndrome has led many organizations to intiate data repatriation from public clouds. Given MinIO’s compatibility with AWS S3 (and GCP/Azure) we have become the object storage of choice for organizations seeking more control over their deployments (on-premise as well as in a public cloud). The proof can be found in the data - MinIO has more than 1.3B Docker pulls to date and is doing nearly 1M a day.
For MinIO’s largest enterprise customers (think hundreds of petabytes) we have started to see some patterns emerge. In this blog, I will highlight a particular use case, anomaly detection from log files, that runs across three of the world's largest enterprises: a credit card payment processor, a leading cyber security company and a cloud hyperscaler. This use case highlights real-time machine learning on structured data to detect anomalies.
The Enterprise Data Strategy
Before we get into machine learning it is important to have a common understanding of the three stages of an enterprise data pipeline: ingestion, storage and consumption.
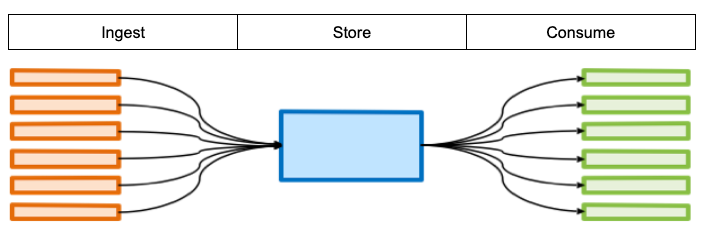
Data ingestion in this case refers to the input pipeline from a wide variety of sources such as transactional applications or batch processes which includes ETL (Extract, Transform and Load) and ELT (Extract, Load and Transform) feeds.
Data storage should be viewed as a shared asset across the enterprise with appropriate identity and access management policies applied. By consolidating enterprise data in one place, an organization can be assured that a single source of truth exists for the data without expensive and unnecessary replication (that necessitates data reconciliation, expensive).
Data consumption should focus on the delivery of trusted data to consumers on demand. A broad set of analytics tools and machine learning algorithms may be applied to drive analytics as insights are delivered to the consumer.
A logical view of this data pipeline with MinIO may look as follows:
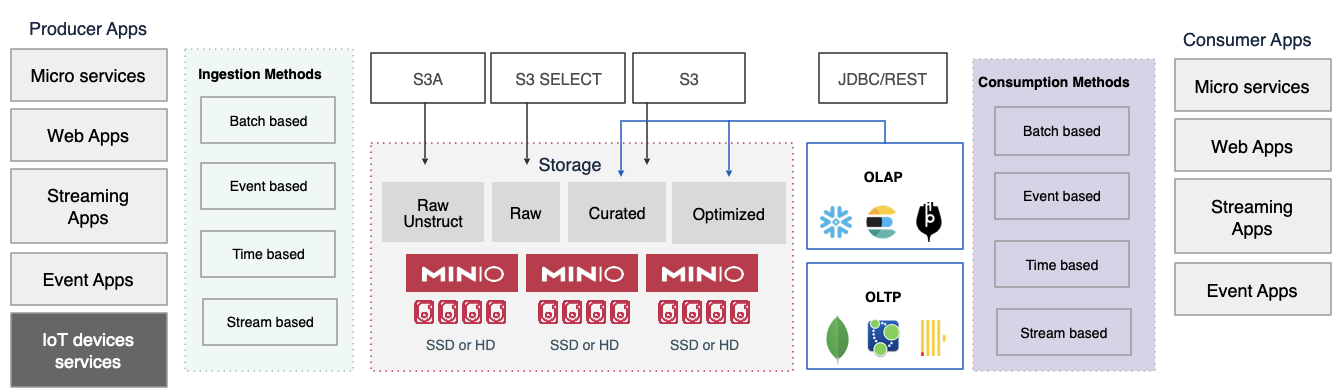
Log Analytics
Modern enterprises generate hundreds of terabytes of data every day from various logs (server messages, network devices, applications and user transactions). These logs may provide insights into errors, access patterns, database health or hundreds of other types of complex IT environments. These logs are an essential part of operations for corporate security (usually under the CISO org) and other enterprise IT organizations to deliver critical services.
At an individual machine level, Linux provides a service called Systemd-journald. The Systemd-journald service collects and stores logging data (this information comes from a variety of sources such as kernel log messages, system logs, audit logs, network logs, etc). Linux provides a framework for any application to point to this service and log events as appropriate.
In the past, IT teams had to manually aggregate these logs from multiple sources and search for patterns to discover operational issues. As the complexity of the enterprise evolved, the manual process of searching through these logs to derive intelligence became impossible. This gave rise to the next generation of log analytics led by organizations/projects like Splunk, ELK or Humio. The details of the inner workings of these projects is beyond this blog but suffice to say that collection of logs from hundreds of thousands of sources into centralized repositories and then filtering, searching and visualization of this data became critical to cyber security. The above tools help an organization deliver operational intelligence, referring to the ability to gain insights by analyzing machine-generated data. The operational intelligence tools give users the ability to run complex queries against the aggregated data and visualize and report on the findings. Think about hundreds of thousands of systemd-journald logs aggregated in one place delivering real-time intelligence.
The growth of log data was unlike anything the enterprise had seen previously and because the gems of knowledge were few and far between but highly valuable - they collected every bit of log data possible. This forced the operational intelligence tools to store the log data in cloud storage like Amazon S3, because no single server deployment could manage the data volumes that were starting to appear. For example, Palo Alto Networks created a logging tool called Panorama which collects logs from their next-generation firewalls and has a default storage of 500GB for their virtual appliance. The storage was almost obsolete as soon as it shipped. According to an IDC study published in 2021, 61% of enterprises gather 1TB+ of security log data per day. Since log data for a large organization can very quickly saturate all available storage of any single appliance, cloud-based storage of log data became a necessity. All operational intelligence tools that we have evaluated come with native S3 object storage support and require a simple configuration variable to be updated.
Given that the cloud is an operating model - not a place, MinIO has become the S3 object storage platform of choice for many enterprises. There are a number of reasons but the most frequently mentioned include:
- MinIO provides 100% S3-compatible storage both on-premise and in all public clouds (not only in Amazon).
- Data repatriation from public cloud storage to on-premise storage has picked up steam due to cost considerations, especially due to data egress charges when data is accessed or moved out of the cloud.
- A significant amount of enterprise data is produced on the edge and moving it to public cloud storage is time-consuming (and expensive).
- Latency-sensitive applications may benefit from data locality controls closer to the enterprise applications.
The Case For Real-Time ML and Anomaly Detection
Real-time anomaly detection, primarily using machine learning, has emerged as a killer use case for MinIO. Anomaly detection identifies data points or events that don’t fit normal business patterns. It is used to solve problems across a variety of businesses, such as fraud detection, medical diagnosis, network intrusion detection and manufacturing defect detection. Machine learning makes it possible to automate anomaly detection across large data sets, in real-time.
Before the rise of machine learning, businesses relied on a series of rules to filter suspected anomalies out of operational data, but these techniques yield too many false positives and are too resource-intensive (meaning slow) so they cannot analyze the huge volume of data collected every day. Detecting outliers in the massive volume of structured (transactions) and unstructured (text, video, audio, images) data is no small task. There is simply no way to detect anomalies at this scale and speed without machine learning.
The work of detecting anomalies isn’t simply to detect the anomaly in a subset of data, it becomes highly useful if you can detect anomalies on streaming data in real-time. Meaning the volume of data is massive. The rigorous demands of real-time analysis requires access to tools that can perform at scale. As we have written, it is easy to be performant on TBs of data, far more challenging to be performant on PBs or EBs of data. That is the class of challenge presented by anomaly detection in log files.
My colleagues at MinIO have blogged about ML flow and anomaly detection in detail so I won’t bore you with details, however, you can look at these blogs.
I read somewhere, “an anomaly is an occurrence of input that when passed through a properly trained auto-encoder results in a high MSE (Mean Squared Error) between what the auto-encoder predicts and the ground truth (the input vector in this case). This high MSE indicates the likelihood of the input vector not being similar to the examples the autoencoder was trained on. It is different in some meaningful way - it is an anomaly. Not good, not bad, just meaningfully different from the data the autoencoder was trained on”.
Enterprises rely on MinIO when selecting object storage to support anomaly detection for the following reasons:
- High-performance ingestion to capture relevant real-time data without delay
- High-performance read operations to enable security/fraud protection with automated machine learning analysis, real-time search and alerting.
- The ability to scale linearly to keep up as ingestion and analysis requirements grow.
- High availability, fault tolerance and data durability to ensure that the anomaly detection system continues to provide protection when the unexpected happens.
- Rolling updates to perform non-disruptive upgrades and patches
- PB+ capacity to collect and retain the data needed from a growing number of sources. The more data the system stores, the more information machine learning algorithms can leverage in differentiating between normal and anomalous events
- Strong encryption in transit and at rest that does not compromise performance
- IAM and PBAC to protect the anomaly detection system from potential malfeasance
Client Use Cases
The three clients I referenced at the beginning of this blog have data ingestion rates of 10TB/day to 100TB/day. The data ingestion rate is increasing at approximately 30% to 100% per year for each one of these clients. Each one of these clients was leveraging HDFS-based storage for log aggregation in the past, however, they decided to move away from that legacy architecture for the following reasons:
- Only a subset of the modern AI/ML stack supported HDFS because almost all the modern applications have adopted a S3 object storage first strategy.
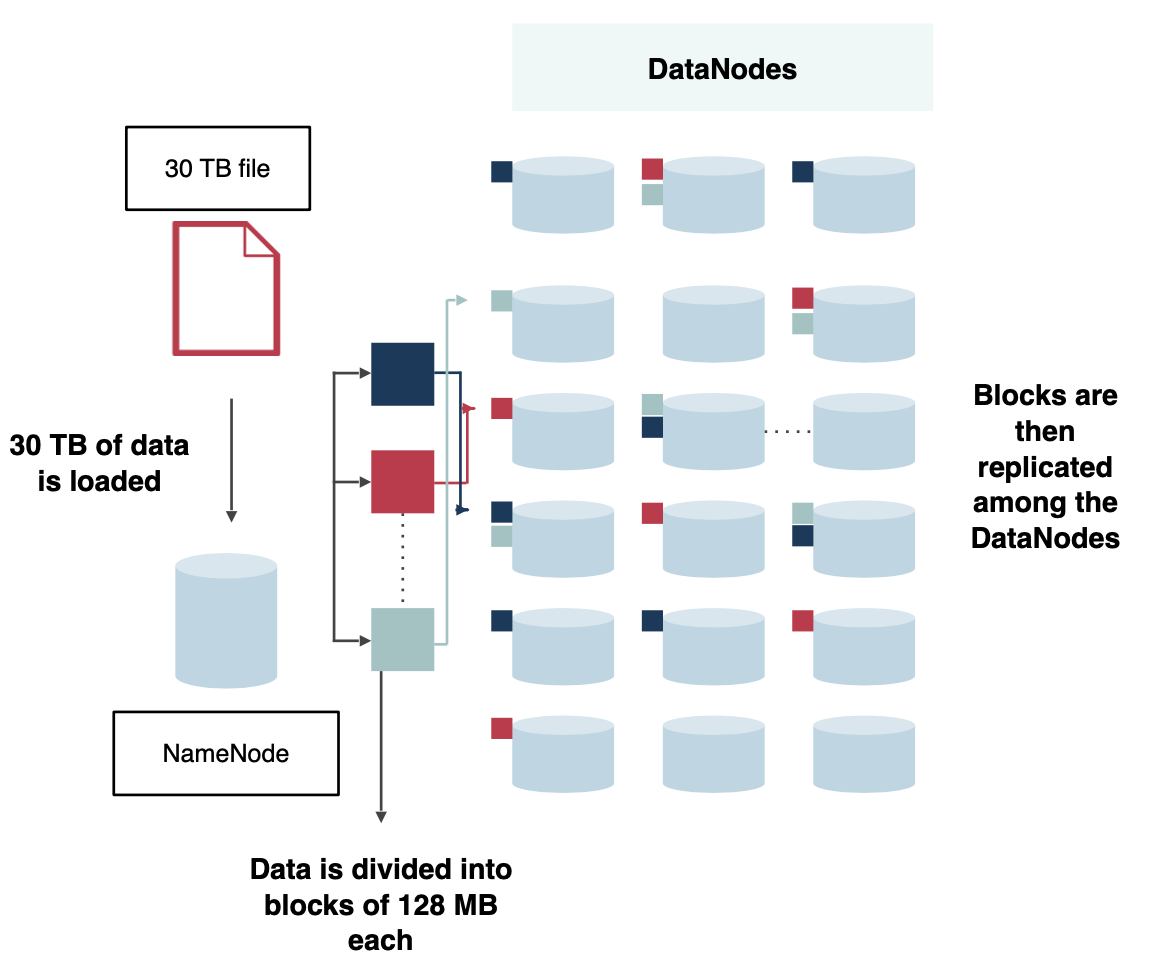
- The ratio of raw storage vs usable storage for HDFS (in the best case) was at least 33% more than the equivalent failure tolerance on MinIO-based object storage.
- The number of nodes necessary to run an HDFS cluster and Full Time Engineers to maintain it was 300% more than what was needed for MinIO. One of the smaller deployments of 9.4 PB requiring 98 data Nodes for HDFS (plus additional name nodes, etc) was boiled down to 32 total MinIO nodes (inclusive of nodes needed for data center fault tolerance).
- HDFS pricing was a factor in these decisions as well.
The following diagrams show a typical deployment architecture for HDFS vs MinIO
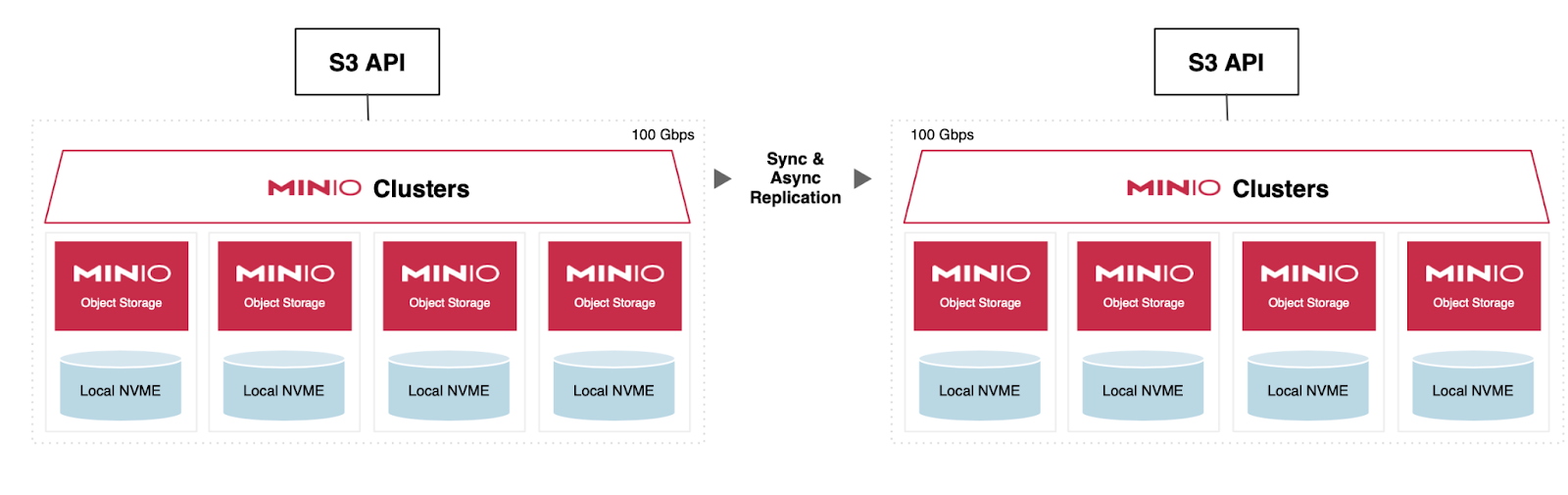
These deployments typically require data ingestion using Kafka (all links are to additional content on our blog) for streaming data and NiFi or Spark for batch data. MinIO also has native FTP/SFTP server capabilities for legacy applications. A typical Splunk log ingestion pipeline may look as follows:
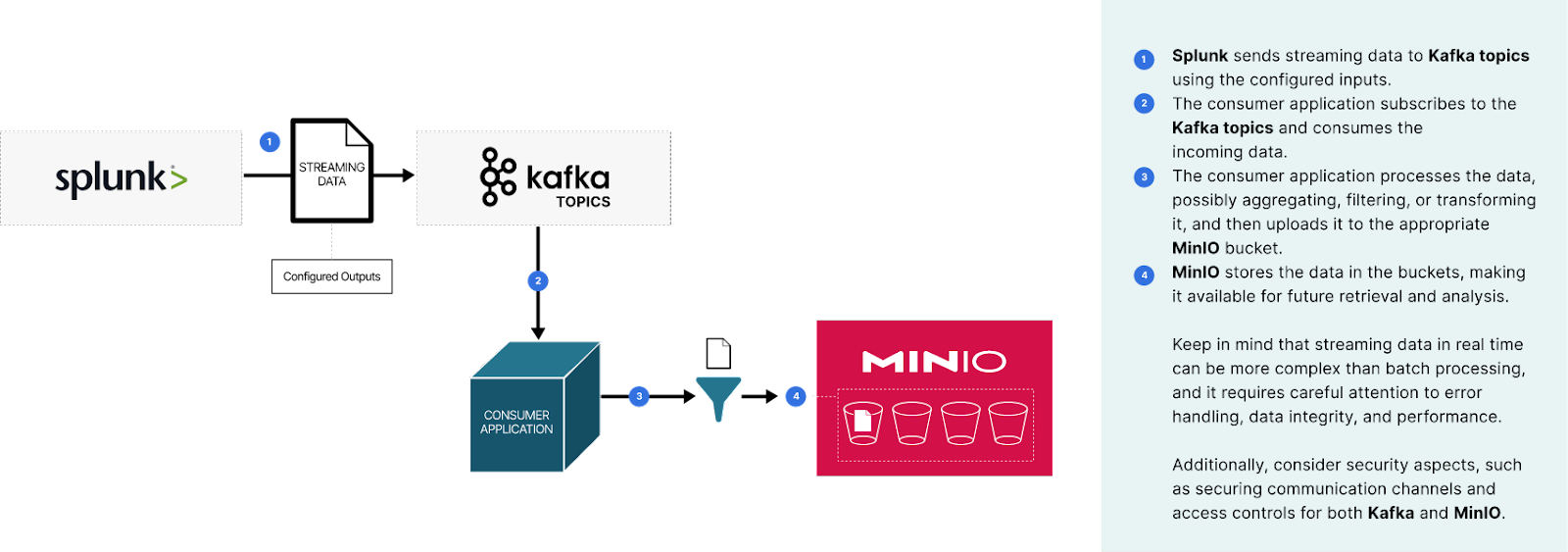
As the exact implementation details can vary based on the specific technologies and requirements, it's essential to consult the official documentation of Kafka, MinIO, and Splunk Add-ons to ensure you're following best practices and utilizing the latest features and capabilities.
Results
So what did this approach yield for the customer? In one case, the client has stopped feeding Amazon S3’s service - pointing their log data to MinIO instead. The volume in this case is so significant (hundreds of PBs) that the change improved the entire gross margin of the business by hundreds of basis points. In another case, following their migration off of HDFS, the client was able to reduce infrastructure costs (as measured by servers) by 84%. This included both the disaggregation of storage and compute, coupled with better performance from the compute nodes and better density on the storage notes. Workload performance increased by more than a 1/3rd and the FTE needed to manage it was reduced by 87%. In the third use case, the client has seven global data centers activated with over 10PBs of production data. The shift from HDFS generated a footprint reduction of 50% on hardware and a headcount reduction of 60% in what was needed to manage it. Given the size of the deployment the savings are well into the seven figures - per year.
Summary
Moving the enterprise away from HDFS and onto object storage for anomaly detection of log files can deliver massive performance, cost and manageability benefits. More importantly, this use case can be found in almost any enterprise. If you would like to go deeper, hit us up at hello@min.io and we can share additional use case details. If you want to try it for yourself, download MinIO here and get started immediately.






