Apache Iceberg as the Foundation for Enterprise AI Data: Why MinIO Made Tables Native In AIStor

Enterprises have spent years struggling with proprietary data formats across lakehouses and databases. In the recent past multiple open table formats have been competing to become the industry standard. That era is finished. Apache Iceberg has emerged as the standard for organizing large-scale enterprise data. Every major engine now offers Iceberg support: Snowflake, Trino, Dremio, Starburst, Spark and more have embraced it.
This is not a matter of opinion, it is consensus. Iceberg won because it was designed for object stores and ensures transactional consistency at scale, without the legacy baggage of filesystems. For enterprises, this means one thing: if you want a future-proof foundation for AI and analytics, it starts with Iceberg.
From Databases to Object Stores: The Road to Iceberg
Relational databases like Oracle and PostgreSQL brought ACID reliability, but large-scale analytics made them costly and slow. Data warehouses improved scale but stayed rigid and struggled with diverse data like logs and sensor streams. Hadoop’s HDFS was the next step, storing petabytes on commodity hardware and introducing MapReduce for parallel compute and Hive for SQL-on-files. This era unlocked big data but came with tight compute–storage coupling, inefficiency, and vendor lock-in.
The breakthrough came with object stores. By decoupling compute from storage, it allowed teams to scale each independently, cut costs, and run infrastructure more flexibly. Object stores became the backbone of modern data lakes. Yet analytics teams still needed reliable table semantics, setting the stage for Apache Iceberg.
Why Iceberg Became Essential
Hive-style directory tables were simple, but also primitive, and were thus ultimately not able to address modern lakehouse needs. They worked tolerably on Hadoop HDFS but broke down on object stores. Given legacy filesystem baggage, tables could show partial states, surface orphaned files, or become corrupt under concurrent jobs. Performance was also poor as the query engines tried to emulate filesystem behaviors on top of object APIs. The result was unreliable analytics, failed ETL pipelines, and downstream business risks like bad dashboards, delayed compliance, or customer-facing errors.
The challenge was clear: data lakehouses needed database-grade reliability at massive scale. Transactions in the modern era are not row updates but long-running, distributed operations involving thousands of large and small objects in Parquet, ORC, or Avro-like formats, often across multiple engines. Classic database engines could not handle this.
Apache Iceberg solved the problem with a metadata layer and a set of APIs that provide ACID transactions, versioned snapshots, schema evolution, and O(1) metadata operations. Proven at Netflix scale and adopted across the industry, Iceberg became the foundation for all enterprise data.
Enterprise AI Needs all the Data, not Just Some of it
Analytics teams have long thought of Iceberg as a format for structured data. But AI doesn’t stop at tables. Agentic systems need to connect transactions with documents, call logs, images, and video. They need to traverse every form of enterprise knowledge, not just the slice that fits neatly into rows and columns.
Iceberg makes this possible. Tables are not just rows of numbers as they can also hold references to unstructured objects alongside the structured context that makes them meaningful. A support call transcript tied to the customer record. A product image linked to its SKU. A compliance document bound to the transaction it governs.
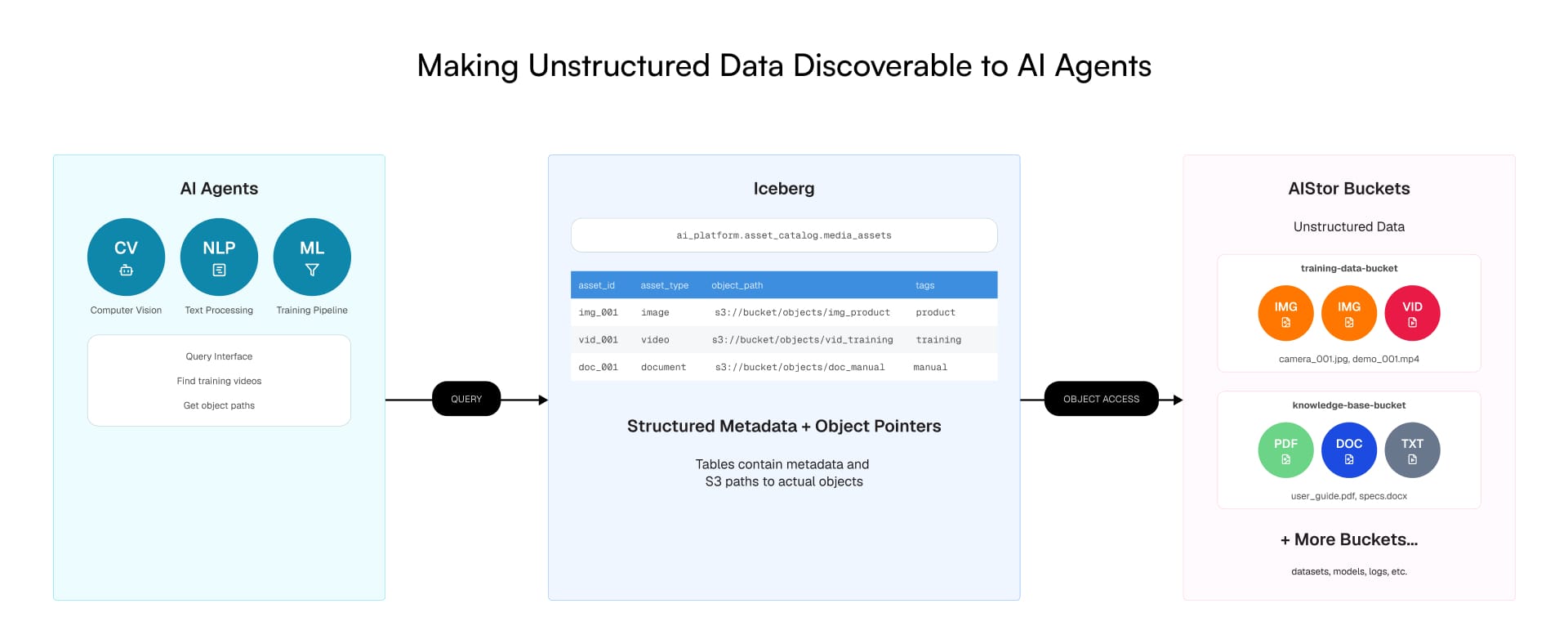
This is how enterprises move from fragmented systems to a single, coherent enterprise AI data fabric, queryable, governable, and ready for AI.
Bringing Structured Tabular Data Directly to the Object Store
When the Iceberg Catalog API is built-in to the object store, tables become as native as objects. The Iceberg catalog is no longer a separate service and database to deploy, but rather an integral part of the object store itself. The built-in catalog is designed for exascale, with high concurrency and transaction requirements. External catalogs can also continue to be supported.
Amazon recognized this and it is why they introduced S3 Tables, folding Iceberg into its S3 managed cloud object storage offering to eliminate external catalog infrastructure. Enterprises building on-prem want the same capability, and they do not want to operate three subsystems for every Iceberg workload. They want that simplicity on their own terms, in an environment they completely control, and with an object-native solution that works at the scale of AI data.
But they have had no option to achieve this on-prem, until today: MinIO has made Iceberg tables as native as objects inside AIStor with a built-in Iceberg Catalog REST API.
Finally, a Unified Foundation for all AI Data
Iceberg has already become the standard for analytics. Its next role is even more important: to become the foundation for enterprise AI data. By unifying structured and unstructured data into a single, governable model, Iceberg allows enterprises to prepare for agentic AI without tearing apart their existing infrastructure.
This is the bridge from today’s analytics to tomorrow’s AI. With Iceberg, enterprises don’t just standardize their data. They make all of it, from tables, logs, images, audio, to documents, part of the same foundation. Finally, all data becomes AI data.
Read our detailed technical blog on AIStor Tables.
Want to learn more about AIStor Tables?
AIStor Tables is currently in tech preview. If you’d like to discuss details or explore your use case, submit the form below to connect directly with one of our engineers.






