Automated Data Prep for ML with MinIO's SDK

The significance of efficient and automated data preparation in machine learning cannot be overstated and is often encapsulated in the familiar axiom, "Garbage in, Garbage out." This underscores the critical role that data quality plays in determining the success of a machine-learning model.
As datasets expand in both size and complexity, the demand for robust pipelines becomes increasingly paramount. These pipelines are necessary to ensure the quality and accuracy of machine learning models.
A game-changing aspect for enterprises is the ability to develop and deploy data preparation pipelines on the edge. This capability improves flexibility and scalability, enabling machine learning engineers to deploy pipelines on diverse platforms — from personal hardware to data centers managed by districts or branch offices, even extending to telco closets. The scalability allows these pipelines, as demonstrated in this tutorial, to start small and seamlessly scale up on any commercial hardware.
This tutorial serves as a guide for constructing robust data pipelines using MinIO, a high-performance, open-source S3-API compatible object storage system, and MinIO’s Python SDK.
In the current landscape of heightened data privacy concerns, establishing internal controls is non-negotiable. This tutorial places a strong emphasis on best practices for safeguarding sensitive information throughout the data preparation process.
Follow along to establish your foundation on these central tenets, as we navigate the intricacies of automated data preparation, edge deployment and data privacy considerations.
Prerequisites
Before getting started, ensure that you have the following prerequisites installed on your system:
If you are starting from scratch, you can install both with the Docker Desktop installer for your platform. You can check if you have if you have Docker installed by running the following command:
docker-compose --versionStart Up MinIO
To get started, clone the tutorial git repository.
In a terminal window, cd into the minio-ml-data-prep directory in the repository and run the following command:
docker-compose up minioWhen you execute this command, it starts the MinIO service, making the MinIO server accessible at the configured ports and endpoints defined in the docker-compose.yml file.
In a browser, navigate to http://127.0.0.1:9001 and log into the MinIO Console with the default credentials: username minioadmin and password minioadmin.
Create Buckets
With MinIO running in one terminal window, open a second one and navigate to the minio-ml-data-prep directory again. Execute the following command:
docker-compose up init-minioThis command executes the Python script init-minio.py. This script interacts with the MinIO server using the MinIO Python SDK and is responsible for creating two buckets, raw and clean, if they do not already exist.
Here's a breakdown of what the script does:
- Bucket Creation Function:
- The
create_bucket_if_not_existsfunction checks if a specified bucket exists. If the bucket does not exist, it creates the bucket usingmake_bucketand prints a success message. If the bucket already exists, it prints a message indicating that the bucket is already present.
- The
- Create Raw and Clean Buckets:
- The script then calls the
create_bucket_if_not_existsfunction twice, once for therawbucket and once for thecleanbucket. This ensures that both buckets are created if needed.
- The script then calls the
- Error Handling:
- The script includes error handling using a
try-exceptblock to catch and print anyS3Errorthat might occur during bucket creation. This ensures that the script gracefully handles potential issues like network problems or incorrect credentials.
- The script includes error handling using a
Navigate to http://127.0.0.1:9001 to check to see that the raw and clean buckets have been successfully created.
Generate Data and Populate the Buckets
Next, in a terminal window execute the following command:
docker-compose up generate-dataThis command executes a Python script, generate-and-upload-fake-data.py, that generates fake data that contains personal identifying information (PII), saves it as Parquet files locally, and then uploads these files to a MinIO raw bucket, demonstrating a basic data ingestion process into a MinIO object storage system.
Here is a further breakdown of what the script is doing:
- Generating Fake Data:
- The
generate_fake_datafunction creates a dictionary containing various fake data fields using the Faker library. Fields include name, email, address, phone number, social security number (SSN), random string, random number, and employee details like position, department, salary, and hire date.
- The
- Saving Data as Parquet:
- The
save_as_parquetfunction takes the generated fake data and saves it as a Parquet file. It converts the data into a Pandas DataFrame, then into a Pyarrow table, and finally writes it as a Parquet file in thedatadirectory.
- The
- Uploading to MinIO:
- The
upload_to_miniofunction uploads a local Parquet file to a MinIO bucket. It calculates the file size, opens the file in binary mode, and uses the MinIO client to upload the object to the specified bucket with the given object name.
- The
- Generating and Uploading Multiple Files:
- The
generate_and_upload_to_miniofunction iterates a specified number of times (default is 10) to generate fake data, save it as Parquet files, and upload them to the MinIO raw bucket.
- The
- Specify MinIO Raw Bucket:
- The script specifies the MinIO raw bucket name as
raw.
- The script specifies the MinIO raw bucket name as
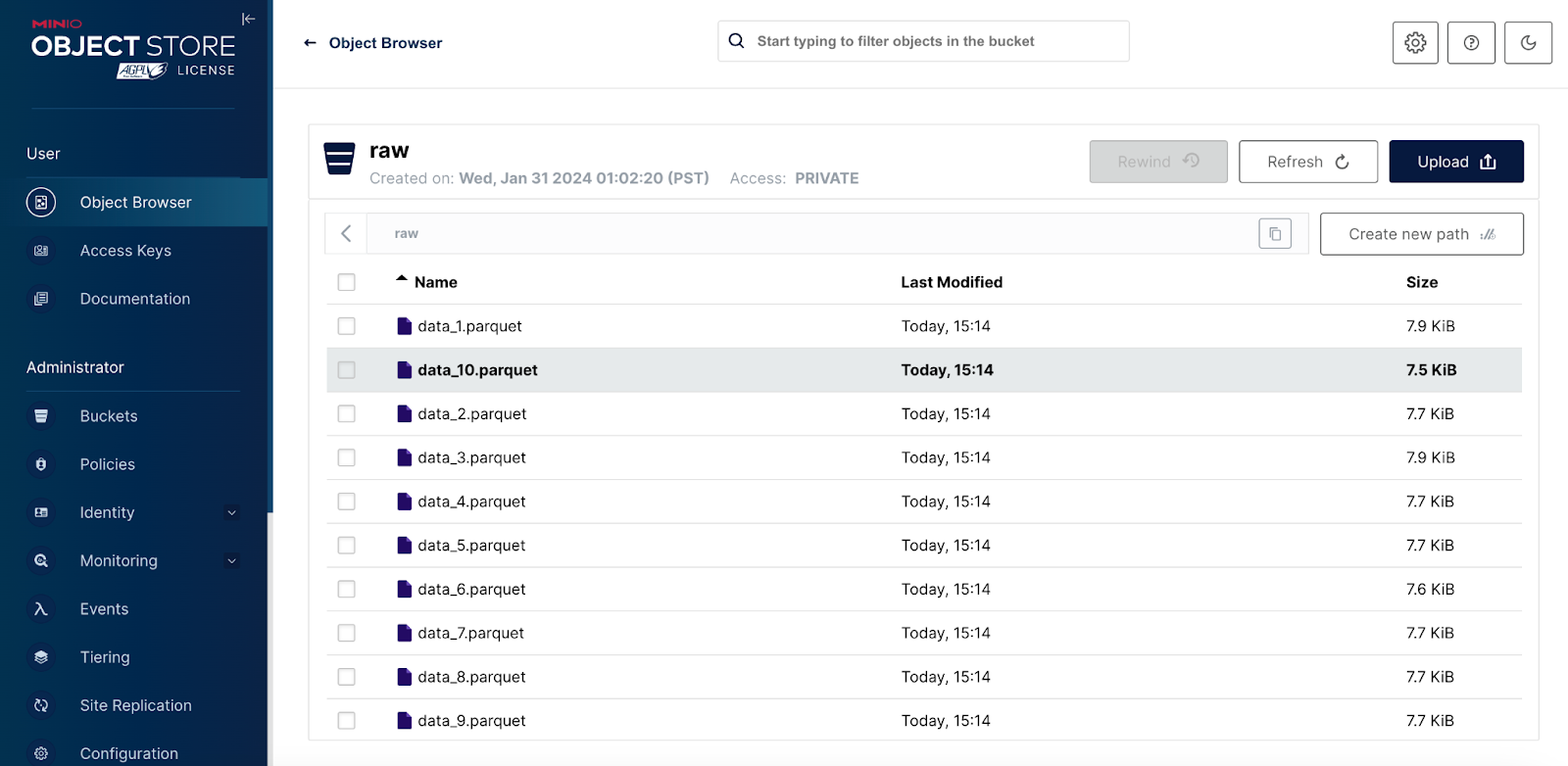
Navigate to http://127.0.0.1:9001 to check to see that the raw buckets have been successfully populated with data.
Transform your Data
Execute the following command to clean your generated data:
docker-compose up data-transformThis command executes a script that automates the process of scrubbing personally identifiable information. It reads the data stored in the raw MinIO bucket and then uploads the scrubbed data to the clean bucket. This demonstrates an important data privacy step in a data preparation workflow
- The
scrub_piifunction takes a Pandas DataFrame (data) and removes personally identifiable information (PII) fields such as name, email, address, phone number, and SSN.
Scrubbing and Uploading to MinIO:
- The
scrub_and_upload_to_miniofunction iterates over a specified number of files (default is 10). For each file, it does the following:- Downloads the Parquet file from the raw bucket on MinIO to a local directory.
- Reads the Parquet file into a Pandas DataFrame.
- Applies the
scrub_piifunction to remove PII from the DataFrame. - Converts the scrubbed DataFrame back to a Pyarrow table.
- Writes the scrubbed Table to a new Parquet file in a local directory.
- Upload the scrubbed Parquet file to the
cleanbucket on MinIO.

Taking A Look
If you want to take a deeper look at your files to make sure that they are being transformed properly, you can run the following script on one of the files downloaded from MinIO.
You can download files either programmatically or through the Console.
import pandas as pd
import pyarrow.parquet as pq
def print_parquet(file_path, num_rows=5):
# Read Parquet file into a pyarrow Table
table = pq.read_table(file_path)
# Extract a Pandas DataFrame from the Table
df = table.to_pandas()
# Set display options to show all columns without truncation
pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
# Print the first few rows of the DataFrame
print(df.head(num_rows))
# Specify the path to your Parquet file
parquet_file_path = "path/to/your/file.parquet"
# Print the first 5 rows of the Parquet file with tidy column display
print_parquet(parquet_file_path)When you run the script on a clean.parquet file you’ll see an output from the terminal that looks like the following:

Shut it Down
When you’re ready to remove your containers, volumes, and generated data, run the following command:
docker-compose downExpand on What You’ve Built
This tutorial has walked you through the essential aspects of automated data preparation for machine learning using MinIO's SDK.
Now, as you've built and explored these data pipelines, consider how you can expand on this foundation. Explore ways to integrate additional data sources, implement advanced transformations, or enhance the privacy and security measures in place. This tutorial serves as a launchpad, encouraging you to innovate and customize these pipelines according to the unique needs and challenges of your machine-learning projects.
Continue to explore the capabilities of MinIO's SDK and object storage systems, experiment with different types of data, and stay updated with the latest advancements in the field. By building upon what you've learned in this tutorial, you are well on your way to mastering the art of automated data preparation for machine learning.
Drop us a line at hello@min.io or in our Slack channel with any questions or comments. Happy coding!






