Benchmarking MinIO vs. AWS S3 for Apache Spark

Apache Spark is a framework for distributed computing. It provides one of the best mechanisms for distributing data across multiple machines in a cluster and performing computations on it.
Spark achieves this by constructing data structures called RDDs (Resilient Distributed Datasets). RDDs allow data to be broken into disparate chunks and processed independently of one another. The individual chunks can then be combined to create the final results. When data is provided to Spark, it automatically constructs these data structures from it. This allows programmers to write application logic and reap the benefits of Spark’s parallelism without any extra effort.
When Spark divides RDDs into independent chunks, each of the chunks are loaded, processed and modified in parallel with every other chunk. This leads to a large number of connections to the storage backend, followed by proportionally large amounts of data transfer over the network. The performance of the underlying storage is critically important to reap the benefits provided by Spark.
This article discusses the performance of MinIO as a storage backend for Spark, evaluated under heavy pressure from the benchmarking workload - TPC-H™ benchmark.
The TPC-H™ benchmark
Data provided to Spark is best parallelized when there is a schema imposed on it. In order to test the limits of the underlying storage, we chose a benchmark with a consistent schema. The TPC-H benchmark is based on 8 interrelated datasets. The size of the dataset is based on a scaling factor. We set the scaling factor to 1000, which generated a dataset of 1TB.
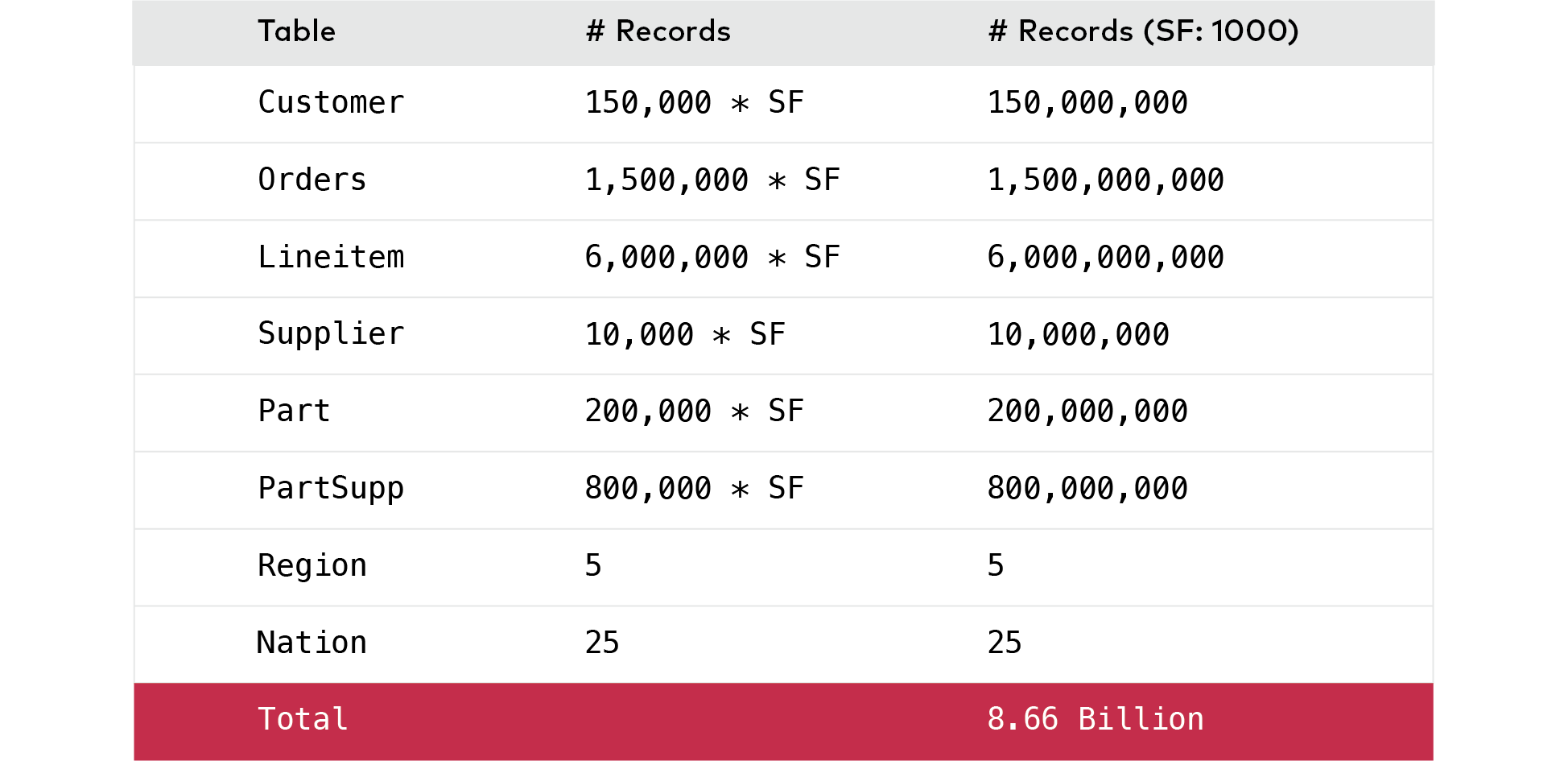
The 1TB dataset was generated, formatted in ORC (Optimized Row Columnar) format, and stored in a MinIO bucket. Converting to this format automatically compresses the data, which shrunk the data size to 273 GB.
Spark MinIO Architecture
The massive size of the dataset required a large cluster to effectively handle this scale. We chose 8 nodes of high-performance, compute optimized instances (c5n.18xlarge) on AWS for running Spark. We chose 8 nodes of high-performance, storage optimized instances (13en.24xlarge) for MinIO. These instances both are connected to 100 Gbe network links.
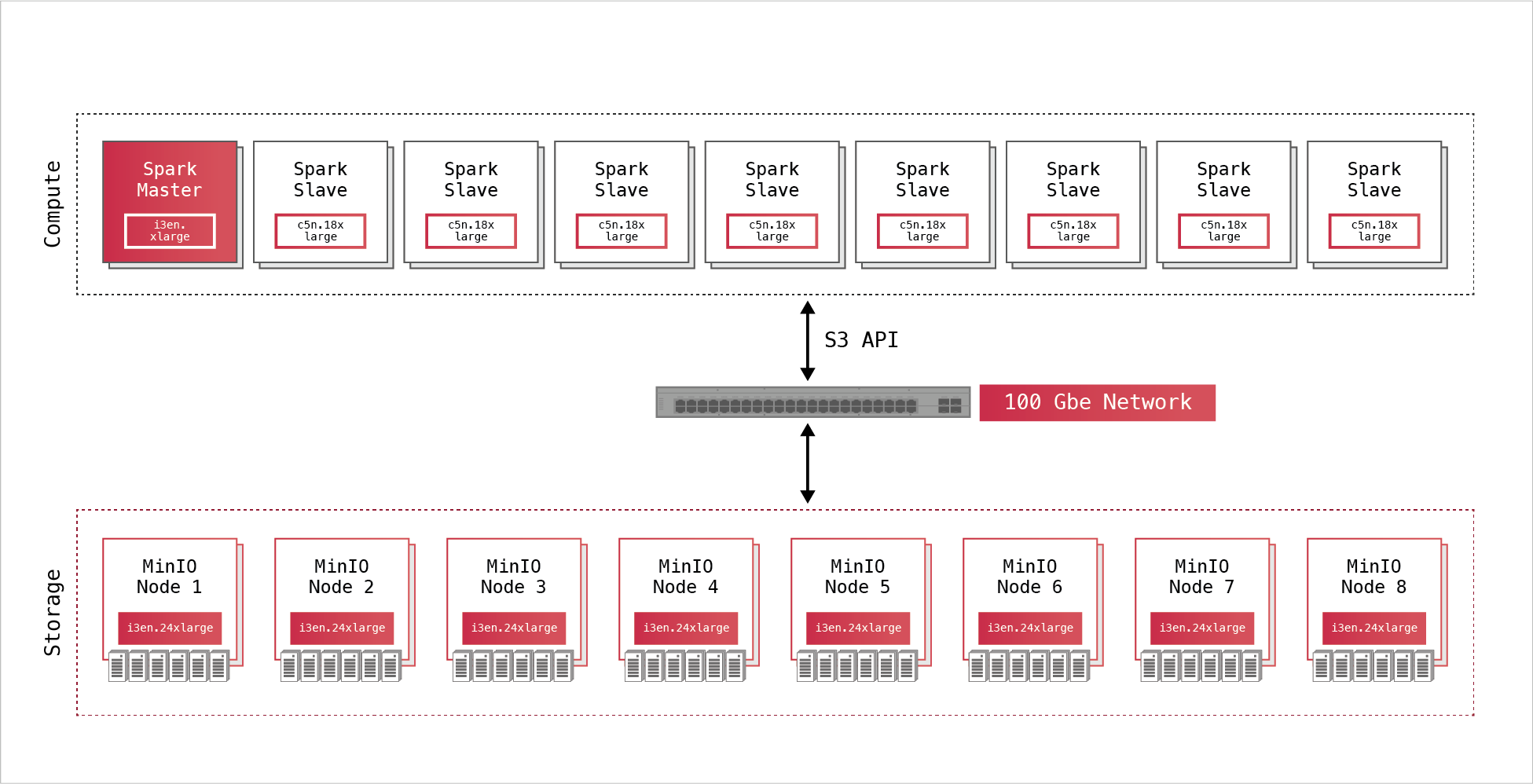
The table below details the hardware running this architecture.

Spark Setup
Spark was optimized to utilize as many connections to MinIO as needed. This was achieved by setting the following parameter

Additionally, we found the following settings led to the best query performance

Benchmark Results
The time taken for each of the 22 TPC-H™ queries is presented below:
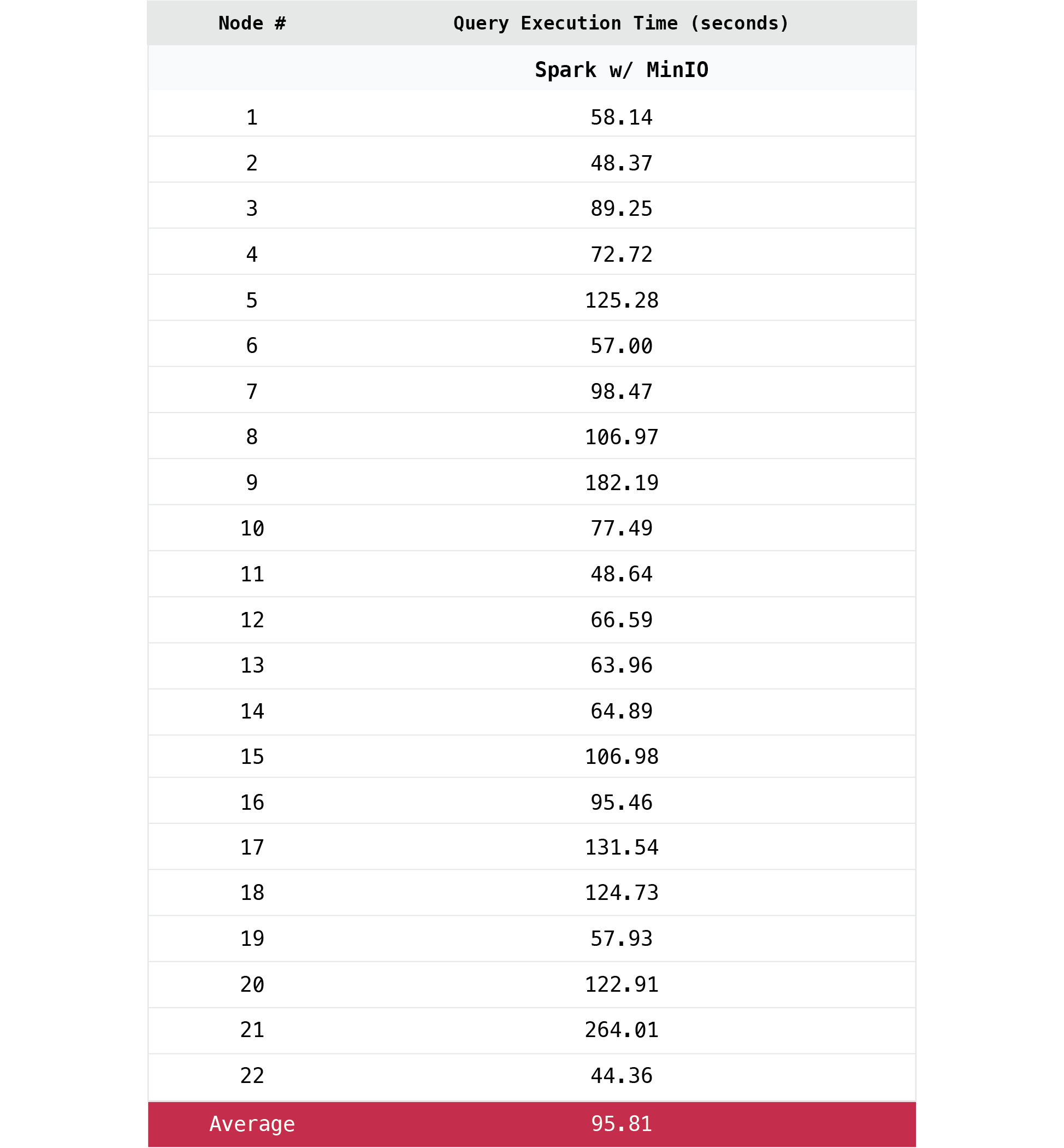
A chart summarizing the above results is shown below:

Comparing MinIO to Amazon S3
The same benchmark tests were run against data stored in Amazon S3 using the same hardware for Apache Spark. It should be noted that MinIO is strictly consistent, whereas Amazon S3 in only eventually consistent. The performance was largely the same with some queries slower than MinIO and others faster - and overall in favor of MinIO. A graph summarizing the query times comparing MinIO and S3 for Apache Spark workloads is presented below:

What we find in the comparison is that MinIO outperforms AWS both in aggregate and in the majority of queries. More importantly, both offer a level of performance that was previously considered beyond the capabilities of object storage. Now, the inherent benefits of object storage (scalability, resiliency, cost) can be combined with outstanding performance across large scale, high performance, data-intensive workloads in private cloud environments.
If you have any questions, please contact me at sid@min.io or hit up the technical request form at the bottom of the page. For the full details, you can find the paper here.






