Best Practices for Kubernetes Object Storage

Kubernetes initially gained popularity as the go-to platform for deploying and orchestrating containerized workloads on distributed systems, but the platform is proving to provide much more than orchestration. Kubernetes is rapidly becoming a primary control and management point for enterprises because of its ability to treat infrastructure as code.
Kubernetes Architecture and Object Storage
Kubernetes was developed to automate application deployment, scaling and management, providing a software controlled infrastructure that abstracts away the intricacies of the underlying hardware. Kubernetes verifies that software is running properly on hardware, and when hardware fails, software is simply moved somewhere else. Hardware is simply a set of abstractions that are offered to applications as resources. These abstractions are then managed within the unified interface of Kubernetes.
Applications, broken down into microservices, run as portable and independently deployable containers. The desired state of workloads is declared and Kubernetes ensures that the actual state is the desired state, automatically troubleshooting and remediating failures, many times by simply restarting an unresponsive container. Containers must be immutable and stateless to prevent data loss or corruption when restarting. Immutable containers save data and configuration information outside of the container when state is needed.
Object Storage That Scales
Kubernetes achieves massive scale by running portable containers without dependency on underlying hardware and software. Portable containers can’t rely on local storage hardware because it isn’t portable. Storage doesn’t need to be local when applications can access data over a fast datacenter network.
This is easier said than done in enterprise environments. Kubernetes is problematic for legacy storage formats like file and block that commonly run on SAN and NAS appliances. Those storage types rely on POSIX, but POSIX was built for local access and hits a wall as data and requirements from modern analytics applications to analyze that data grow exponentially. Even locally, POSIX metadata contention and corruption can occur with too many concurrent parallel file operations.
Distributed object storage doesn’t face the limitations presented by POSIX. Object storage does not provide edit functionality, and therefore gains the benefits of sequential I/O and simpler locking mechanisms. On a fast network, a distributed object storage system will outperform a legacy POSIX-compliant file system, especially when addressing concurrent parallel requests.
Object storage overcomes the limitations and complexities of working with external file and block storage and Kubernetes. The best object storage is much like Kubernetes itself - distributed, decoupled, declarative and immutable.
In order to provide the most functionality for DevOps and time saving for IT, Kubernetes-native object storage is managed, secured and automated through Kubernetes itself, enabling workloads across private, multi-, hybrid and public cloud environments.
Kubernetes Native Object Storage with MinIO
We moved MinIO inside the Kubernetes framework to simplify and automate provisioning, securing and ongoing management of buckets and objects. We also added a suite of features to simplify the deployment of Kubernetes-native object storage, especially for multi-tenant environments.
The MinIO Kubernetes Operator encapsulates all critical DevOps tasks into software that is used to create and manage large object storage infrastructure independent of the underlying hardware. The MinIO Kubernetes Plugin extends the familiar kubectl command set to add a straightforward set of sub-commands to create, configure and manage MinIO deployments on Kubernetes.
The Operator Console is a graphical user interface that is so simple that anyone in the organization can create, deploy and manage object storage. This truly enables self-service object storage for the enterprise.
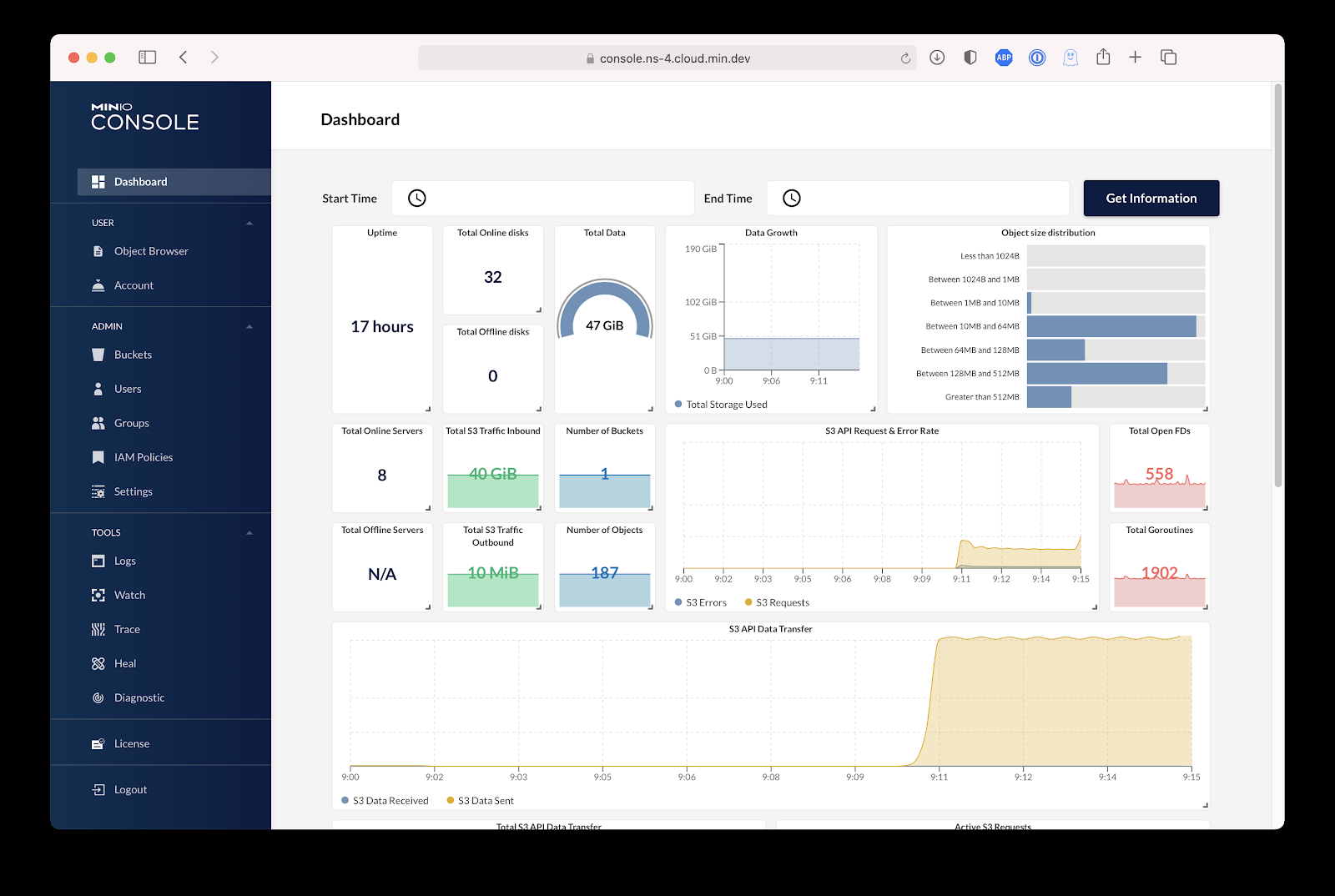
The MinIO Console provides the same power and simplicity of our mc CLI in an intuitive browser-based GUI that features a dashboard that visualizes industry standard monitoring via Prometheus and the MinIO metrics endpoint.
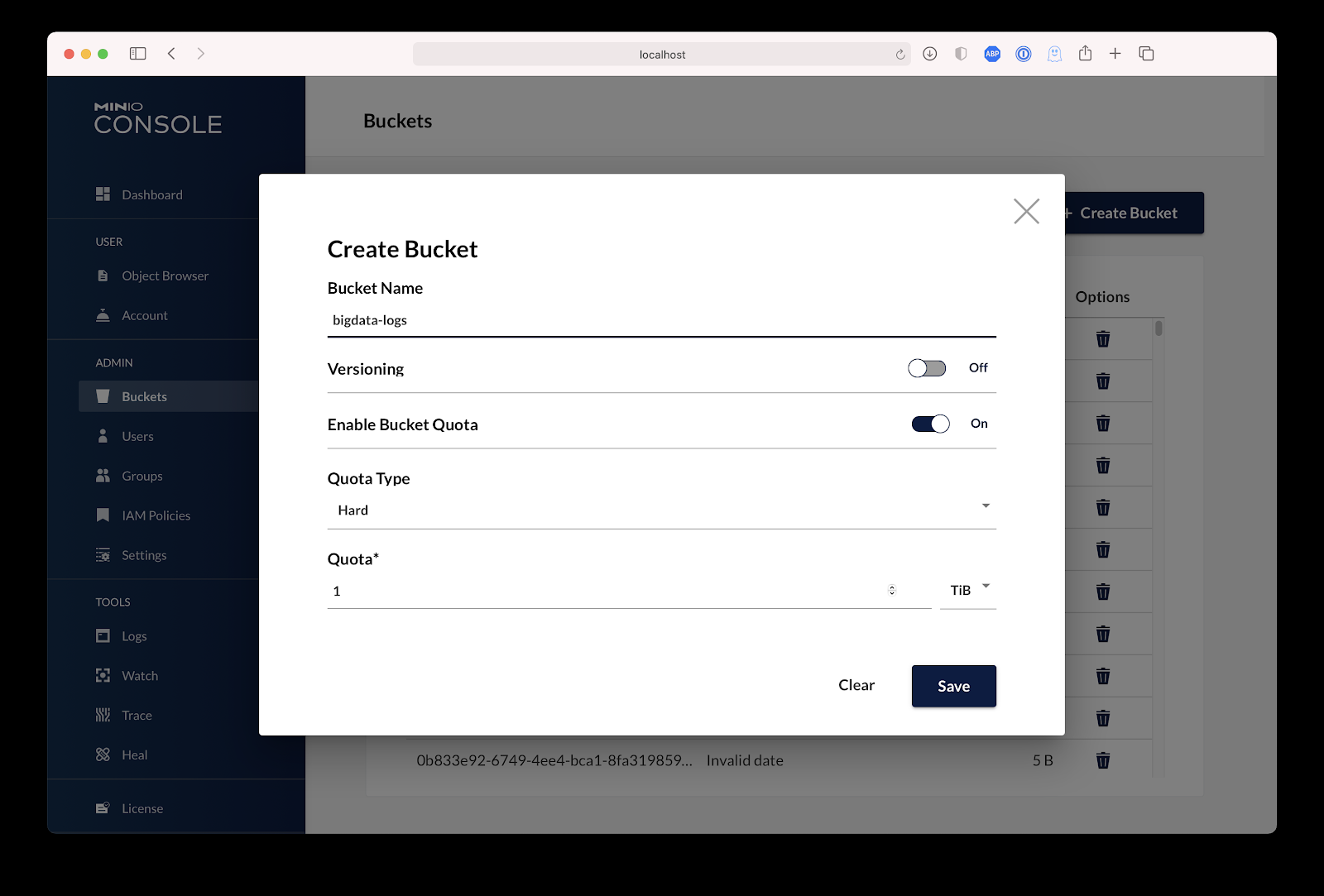
IT admins now have a streamlined point-and-click experience for managing object storage through Kubernetes without having to write Helm charts or YAML. The browser-based interface simplifies processes such as configuring and managing buckets, users and groups, and their policies and settings. New users and buckets can be added manually or with a few clicks through OpenID Connect and ActiveDirectory/LDAP.
Experience Object Storage Excellence
MinIO’s high-performance, Kubernetes-native object storage suite delivers a consistent and efficient experience for enterprise IT and DevOps teams running Kubernetes. MinIO runs anywhere and everywhere, including Red Hat OpenShift, VMware Tanzu, SUSE, HP Ezmeral, Azure AKS, Google GKE, Amazon EKS, and stock upstream Kubernetes. More than 58% of the Fortune 500 relies on MinIO in one form or another to provide the object storage layer in public, private, multi-, hybrid cloud and at the edge.
Download MinIO and try it out for yourself. Get started with our tutorial, Simplifying Object Storage as a Service with Kubernetes and MinIO’s Operator.






