Building Performant Data Infrastructure with Apache Arrow and MinIO
There is a lot of momentum around Apache Arrow these days. A favorite of developers and data practitioners, its use in business-critical applications has grown considerably and data driven organizations like Dremio, InfluxData, Snowflake, Streamlit, and Tellius are all heavily invested. The drivers of this adoption are superior interoperability, simpler data architectures, greater speed and efficiency, more choice of tools and freedom from vendor lock-in based on the Apache license.
Despite the momentum, Arrow is still a little misunderstood. While the team at Voltron Data now has a pretty sizable warchest to change that perception and grow the recognition, there is some work to do there. Our good friend Ravishankar Nair did a piece a few years ago, but we wanted to add a little context and streamline the instructions in this post.
Apache Arrow improves the speed of data analytics by creating a standard columnar memory format that any computer language can understand. Apache Arrow performance allows for the transfer of data without the cost of serialization (the process of translating data into a format that can be stored). Apache Arrow is a standard that can be implemented by any computer program that processes memory data.
Arrow has grown beyond its initial focus on storing columnar data in memory. It has multiple subprojects, including two query engines. Again, having the commercial influence of the Voltron Data team to prioritize enterprise features will strengthen the overall project.
Integrating MinIO and Arrow
Let’s turn our attention to running Arrow in conjunction with MinIO.
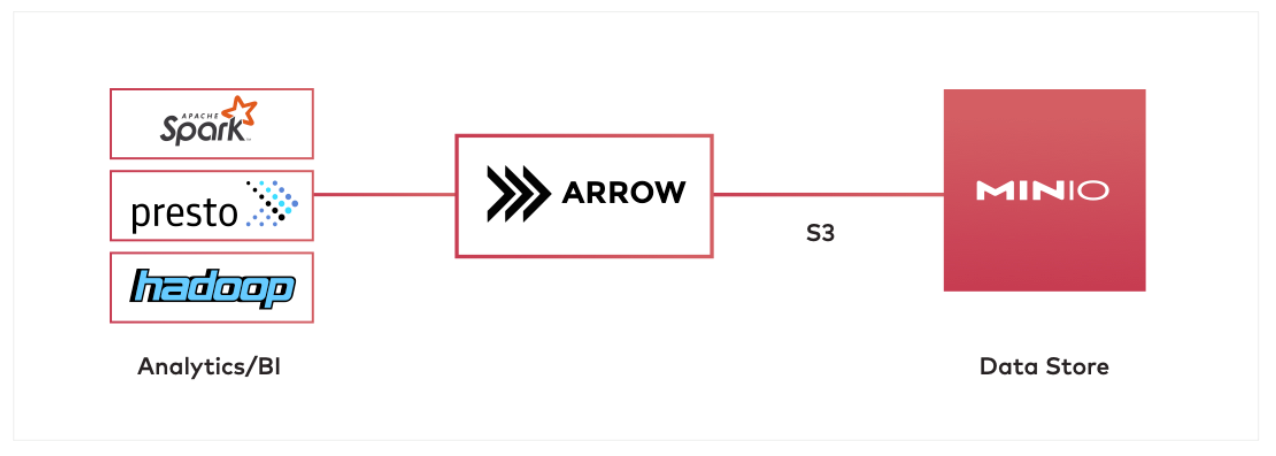
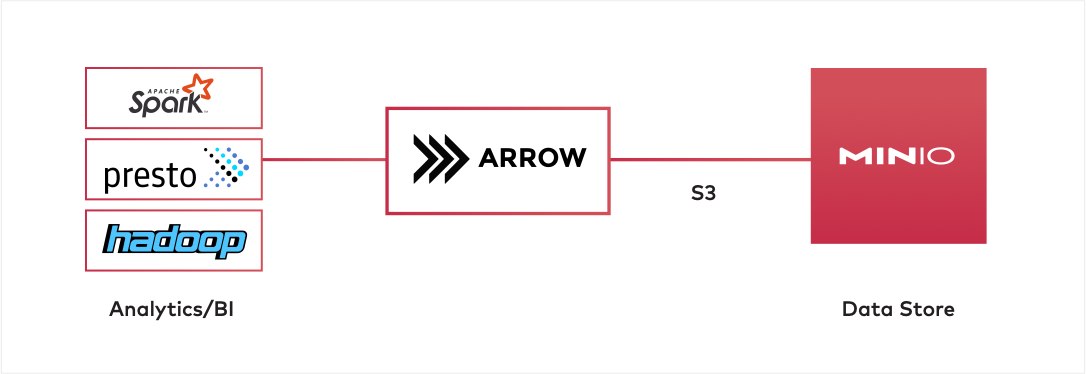
In an architecture with MinIO and Arrow, MinIO would serve as the data store, and Spark or Hadoop as the data processor. Apache Arrow would be used in the middle to transform/load large amounts of data from MinIO and into Spark/Hadoop. Apache Arrow can speak the S3 protocol to communicate with MinIO.
Example Use Case: Convert a file from CSV to parquet - a highly optimized columnar data format for fast queries
Here is the flow for the use case:
- Arrow loads a CSV file from MinIO using the S3 protocol
- Arrow converts the file to parquet format in-memory
- Arrow stores the parquet formatted data back into MinIO
Spark/Presto can then fetch the parquet data directly from MinIO for further processing. Here’s how to run this setup yourself:
Run MinIO using Docker
The quickest way to get started with MinIO is using Docker. The command to run:
This sets up MinIO in standalone mode i.e., a single-node deployment of MinIO. This deployment includes an integrated web GUI, called Console. When this command is run, MinIO’s data API will be available at port 9000, and the Console UI will be available at port 9001.
Create a Bucket and Upload Data
Let’s open up the MinIO console by visiting 127.0.0.1:9001 in a browser.

In the MinIO Console:
- Navigate to the buckets section in the left hand menu bar
- Click on [Create Bucket +] button on the right hand side. Name the new bucket as ‘testbucket’.
- Once it is successfully created, upload this file to it - [username.csv].
Install PyArrow
Run this command to install pyarrow:
Use pyarrow to read data from MinIO
- Import necessary modules
- fs: includes S3Filesystem utility
- csv: for parsing CSV files
- parquet: includes methods to convert CSV to parquet format
2. Connect pyarrow to MinIO using S3Filesystem:
Make sure the arguments passed to S3Filesystem exactly match the command line arguments in the docker command to run MinIO
3. Read the CSV file
4. Convert it to parquet
5. Verify that the parquet file was created
- Navigate back to the MinIO console
- Go to Buckets on the left menu bar
- Choose ‘testbucket’ and [Browse files] in it
- Ensure that ‘username.parquet’ has been created
That's it. You are ready to read and query at speed.
Conclusion
In this article, we introduced the importance of Apache Arrow and the role it plays alongside MinIO in creating high performance data infrastructure that scales. The example use case and setup shows how Arrow can be used to load data from MinIO, transform it and store it back in MinIO for later processing by Spark, Presto and anything requiring performance at scale.
If you have any questions about this setup, reach out to us at dev@min.io and look out for more articles about MinIO, Apache Arrow and more from the Big Data ecosystem!






