Beyond File and Block Storage in Kubernetes

At the beginning of the decade, the total data in the world added up to 2 zettabytes. It has grown to 59 zettabytes today. In a matter of 10 years, it has grown 30-fold.
Unstructured data
The majority of data that exists today are photos, videos or some kind of point-in-time events. These kinds of data do not have an inherent structure to them. They are also called unstructured data.
Since the structure of data is not known upfront, it is much easier to replace an object of data entirely than to edit a part of it. This form of data, where it is never edited, but only created and replaced, is called immutable data.
Since edits are not conducted on such data, it is harder to corrupt. Immutability indirectly increases durability.
Evolution of Hardware
In addition to durability of the data itself, the durability and scale of hardware also has evolved to support the exponential growth of data. For instance, the fastest commercially available network links went up from 40 Gbit/s to 100 Gbit/s from 2010–2020.
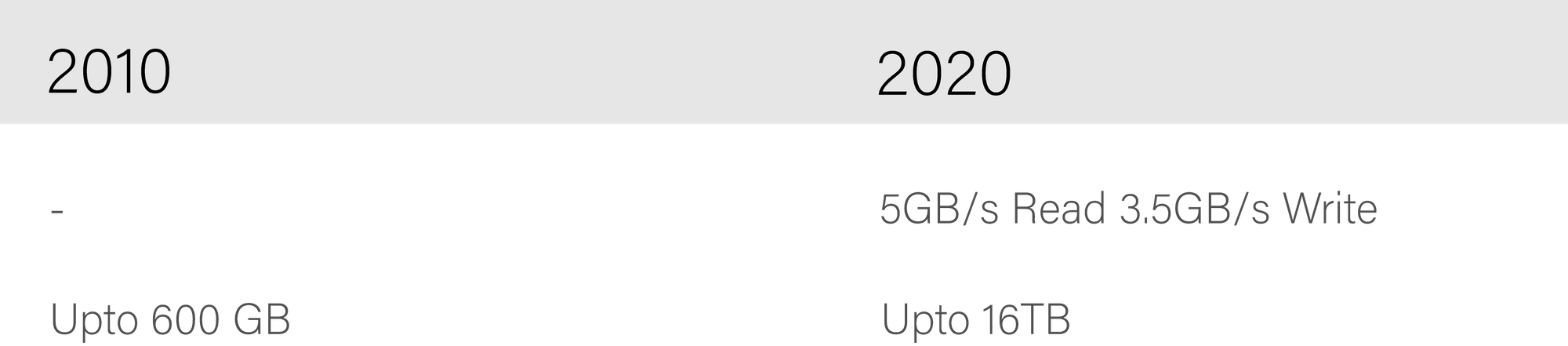
The world of storage has also shown similar growth. The maximum write speed of top-of-the-shelf NVMe SSD is about 5 Gbyte/s read and 3.5 Gbyte/s write. In Gbit, read and write speeds are 40 Gbit/s and 28 Gbit/s.

Comparing the fastest data transfer speed between network hardware and storage hardware, it is clear that network is faster than storage.
Scale
In order to address the extreme scale, the faster networking hardware, along with the ability to obfuscate a cluster of machines behind a single endpoint makes it better to store data over the network, rather than on local drives.
This form of storage over the network where data objects are treated as immutable blobs is also known as object storage.
Applications that store data over the network get to enjoy the benefits of storing NO data locally — i.e. they become stateless.
Stateless
Stateless applications are requisite step for cloud migration and successful cloud operations. Stateless applications are easier to provision, easier scale, and easier to handle in case of failures.
Object storage is the key enabler for stateless applications. Transitively, Object storage is one of the key enablers for cloud migration.
Kubernetes
Currently (November 2020), Kubernetes only supports file and block storage — both of which are forms of local storage. The CSI (Container Storage Interface) standard is the mechanism that Kubernetes supports for file and block storage. CSI acts as bridge between file or block stores, and containers.
In case of object storage, the primitives imposed by CSI do not apply. The unit of allocation in object storage is a bucket. Bucket is a collection of objects housed under a single endpoint.
In order to support object storage, my team and I have introduced the Bucket API to Kubernetes. This API will serve two purposes:
- Interface for object storage vendors to kubernetes
- Standard mechanism for applications to consume object storage
In its current state, it supports 4 operations
- CreateBucket
- DeleteBucket
- GrantAccess
- RevokeAccess
The names are self-explanatory. Any vendor that satisfies the above 4 operations can become Bucket API compatible. The proposal for BucketAPI was officially accepted on the 20th of Oct 2020, and it is planned to reach alpha status in the v1.21 release of Kubernetes.
Though in its early stages, this effort is a step in the right direction. As an official up-and-coming feature in Kubernetes, we are excited to welcome everybody to participate in its development.

Please reach out to me at sid@min.io, or reach out to any of my peers in the BucketAPI working group. You can also join us on our weekly briefings on Thursdays at 10AM PST.






