Build Data Pipelines with SAP Data Intelligence Cloud, SAP HANA Cloud and MinIO

Extensions, integrations and openness characterize today’s leading enterprise database and analytics software, aka the data stack. Today’s data stack is dynamic, modular and API-driven. It is also elastically scalable because compute is decoupled from storage, and that storage is S3-compatible object storage. Scalability and openness go hand in hand with the general trend of replacing legacy file and block storage with modern object storage such as MinIO. Data in many different sources in many different formats pours into the data lakehouse where the S3 API makes it easy for applications to read and write.
SAP HANA’s in-memory, multi-modal data management engine takes full advantage of the capabilities of underlying hardware, similar to the way MinIO also takes full advantage of underlying hardware, making it a powerful extension to the SAP HANA ecosystem. SAP Data Intelligence Cloud is a cloud-based distributed data management solution. It is the data orchestration layer of the SAP Business Technology Platform.
This blog post provides a tutorial to build data pipelines from MinIO to SAP Data Intelligence Cloud and finally to SAP HANA Cloud. First, I’ll discuss how to build a connection from MinIO to SAP Data Intelligence Cloud where data will be imported and transformed to be fed into SAP HANA Cloud. I’ll show how to do this with SAP HANA Cloud, SAP HANA database, although the procedure for working with SAP HANA on-premise is the same – all configurations are in SAP Data Intelligence Cloud.
Multi-Source Data and the SAP Cloud Ecosystem
SAP Data Intelligence Cloud is designed to be a single gateway to all of your data, regardless of where or how it is stored, be it in the cloud, on-premise, in SAP HANA Cloud or SAP HANA on-premise. In a hybrid configuration, multiple data sources are configured and connected via SAP Data Intelligence to a SAP HANA Cloud, SAP HANA database instance. On-premise SAP HANA and SAP HANA cloud share tables via Smart Data Integration (SDI) and Smart Data Access (SDA).
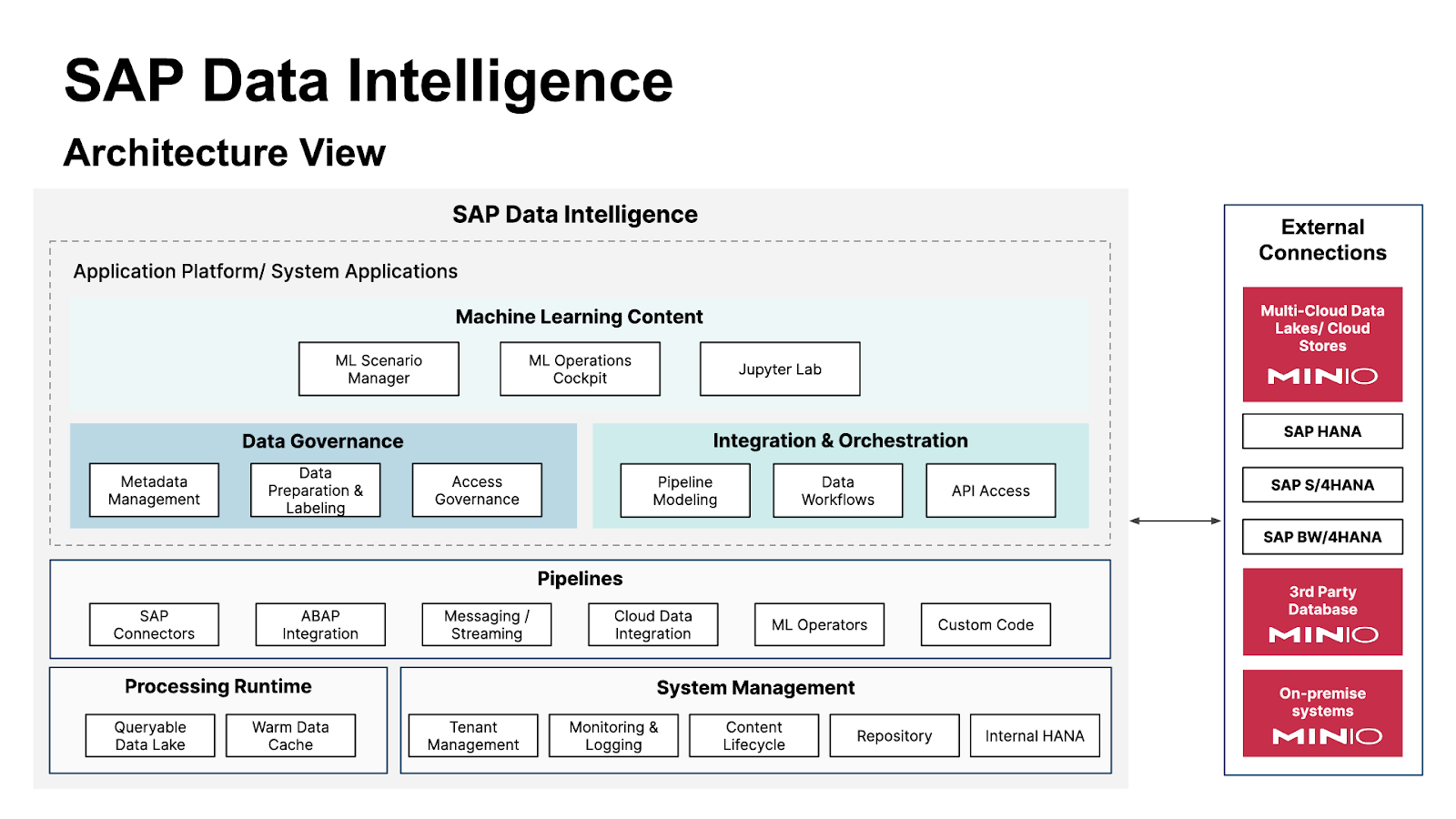
Configure SAP Cloud Connections
Let's turn to the technical details. Below you will find a tutorial on how to import data from MinIO into SAP Data Intelligence Cloud and then into SAP HANA Cloud, SAP HANA database. Please note that we're just focused on plumbing here – simply connecting data sources to SAP HANA Cloud is not the end of this journey, you will have to optimize query performance and that is out of the scope of this post.
We're going to build a pipeline to load data in .csv files into SAP HANA Cloud. We'll create a database table and load the data in .csv files into this newly created table which resides in the HDI container. SAP HANA Deployment Infrastructure (HDI) containers hold database development artifacts for all key SAP HANA platform database features.

The first task that must be completed is to gather information about your MinIO bucket and data. You can import both individual or multiple .csv files or complete SAP schemas that have previously been exported from a SAP HANA Cloud, SAP HANA database.
If you do not already have MinIO installed, please do so. Make sure to note the API endpoint address, access key, secret key and bucket/path because you'll need to enter them when you create a connection in SAP Data Intelligence.
In a browser, log in to the MinIO Console, navigate to the Buckets tab and click Create Bucket +.
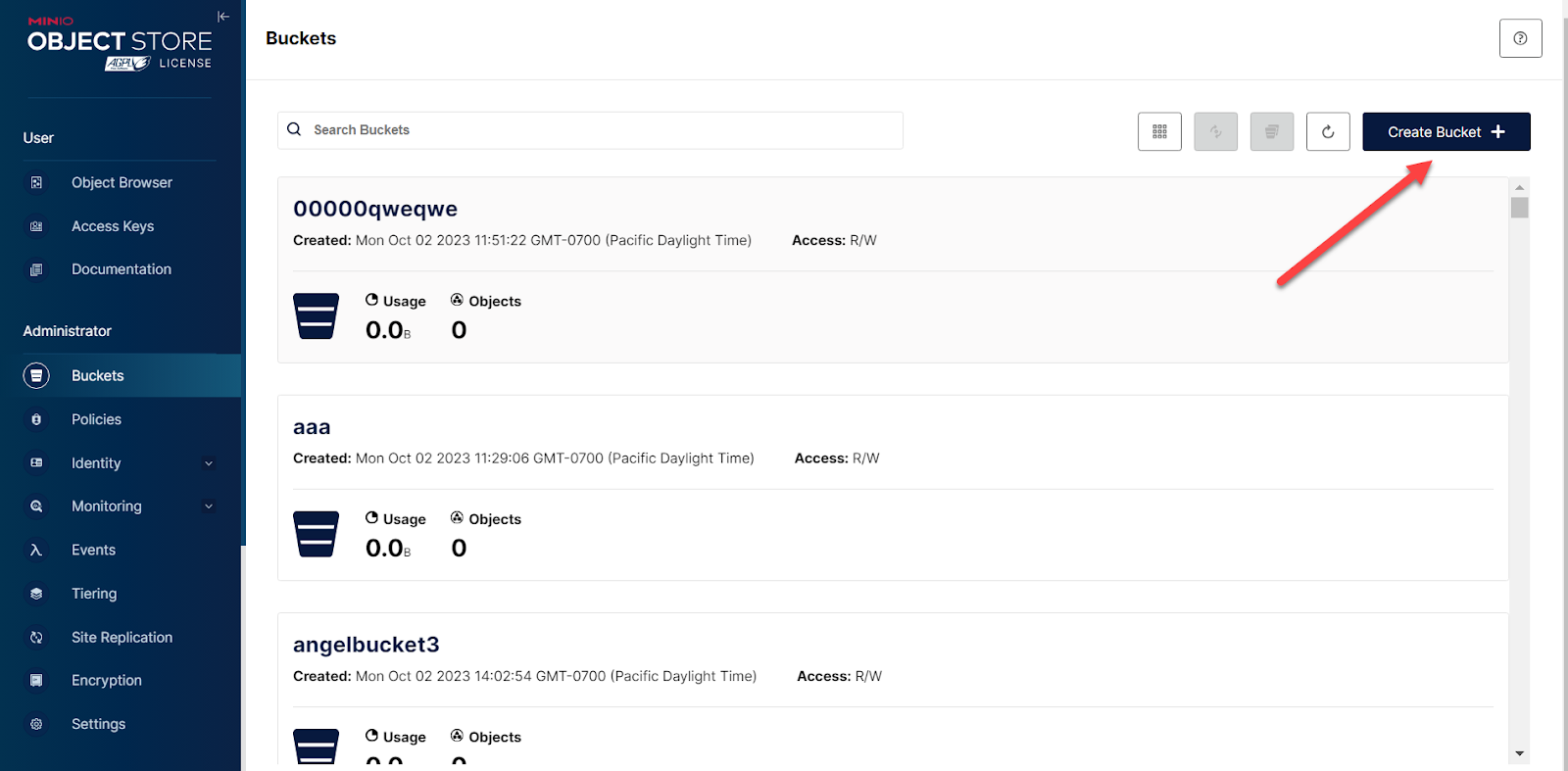
Type the bucket name and, if you wish, check the boxes to enable the bucket policy.
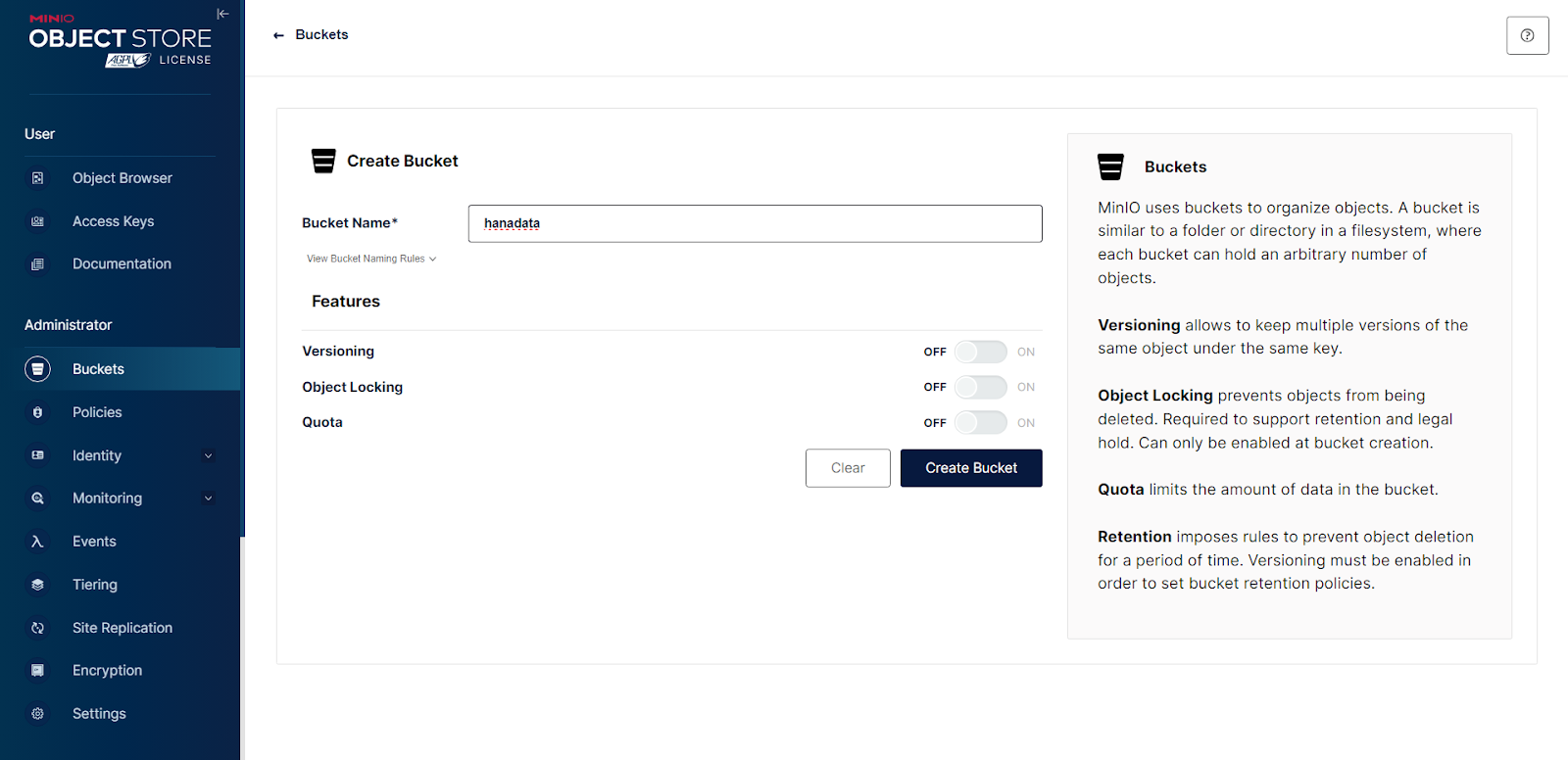
After creating your bucket, create a folder to contain your data.
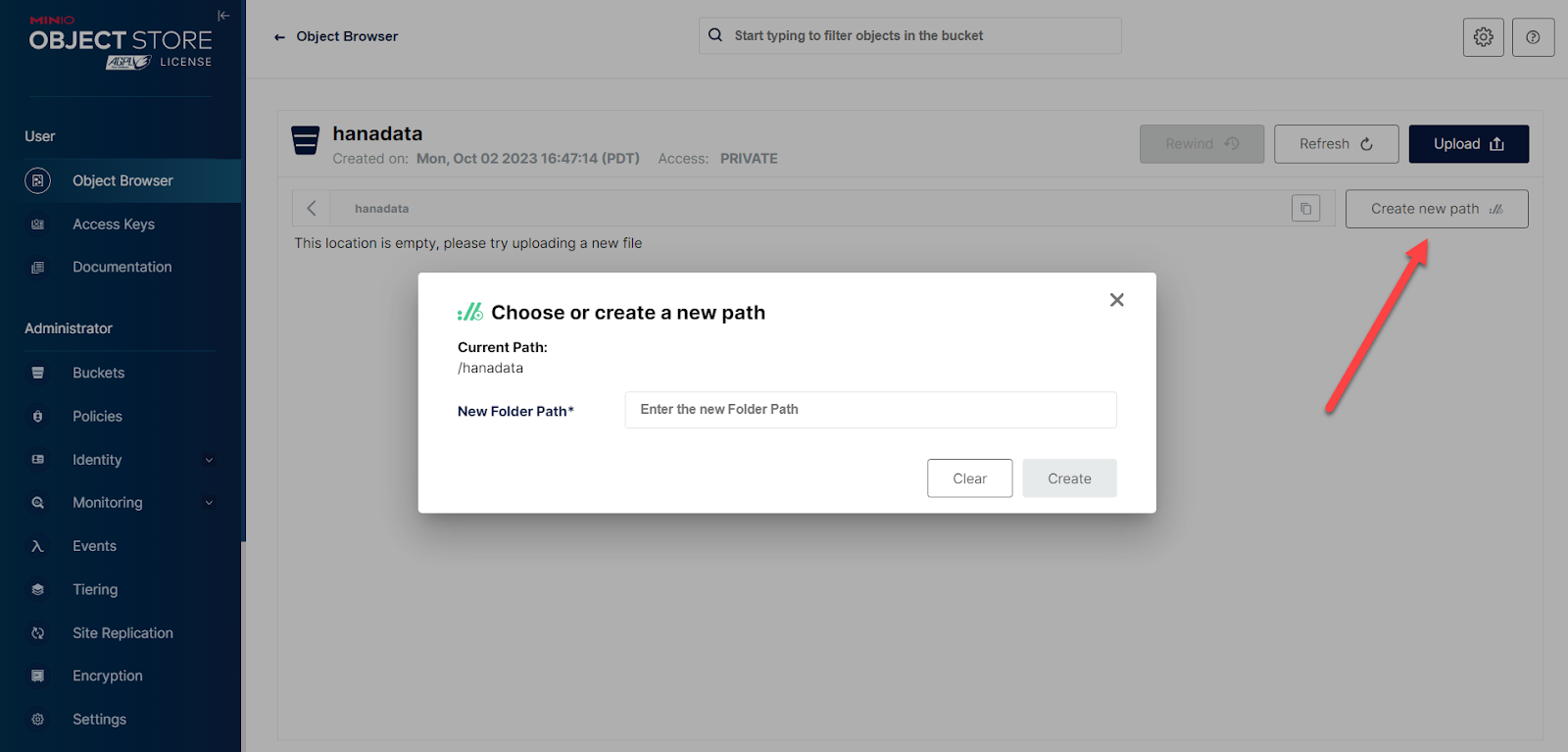
And then click to upload a .csv file from your local filesystem to import.
Open SAP Data Intelligence Cloud, or sign up for a free trial.
From the SAP Data Intelligence Launchpad, click Connection Management, the first tile shown below
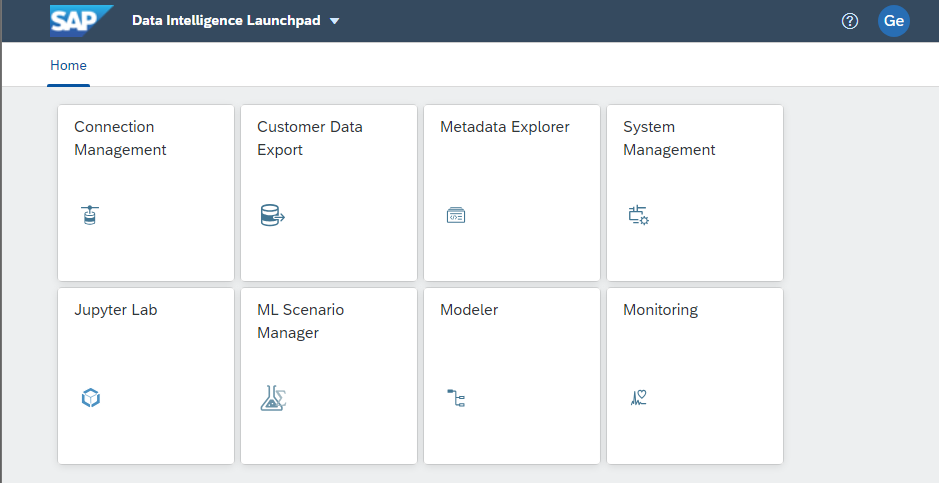
We will create two connections – one between MinIO and SAP Data Intelligence Cloud and one between SAP Data Intelligence Cloud and SAP HANA Cloud.
First, let's build the connection for MinIO. Start by clicking the blue plus sign next to the search box.
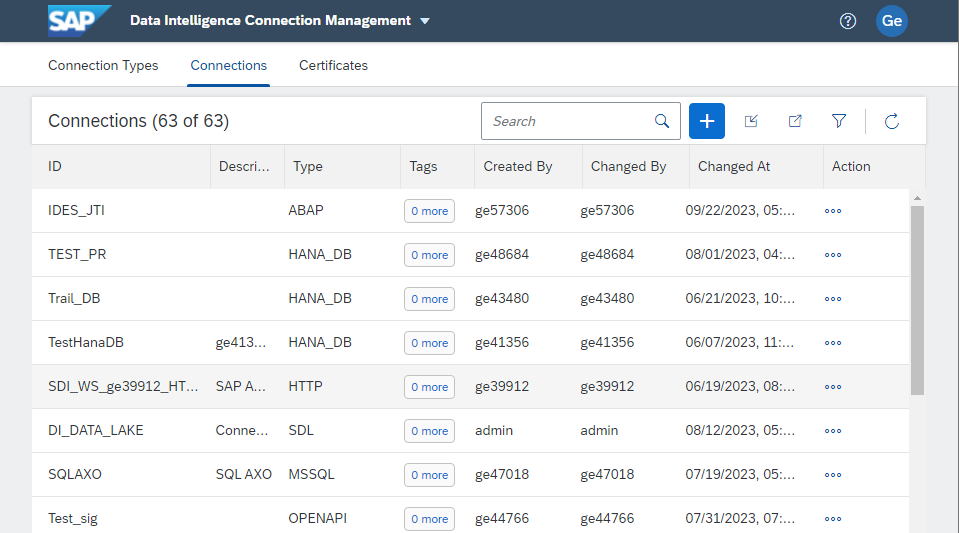
Choose S3 for Connection Type, give your connection a name and a description and fill in Connection Details for your MinIO bucket.
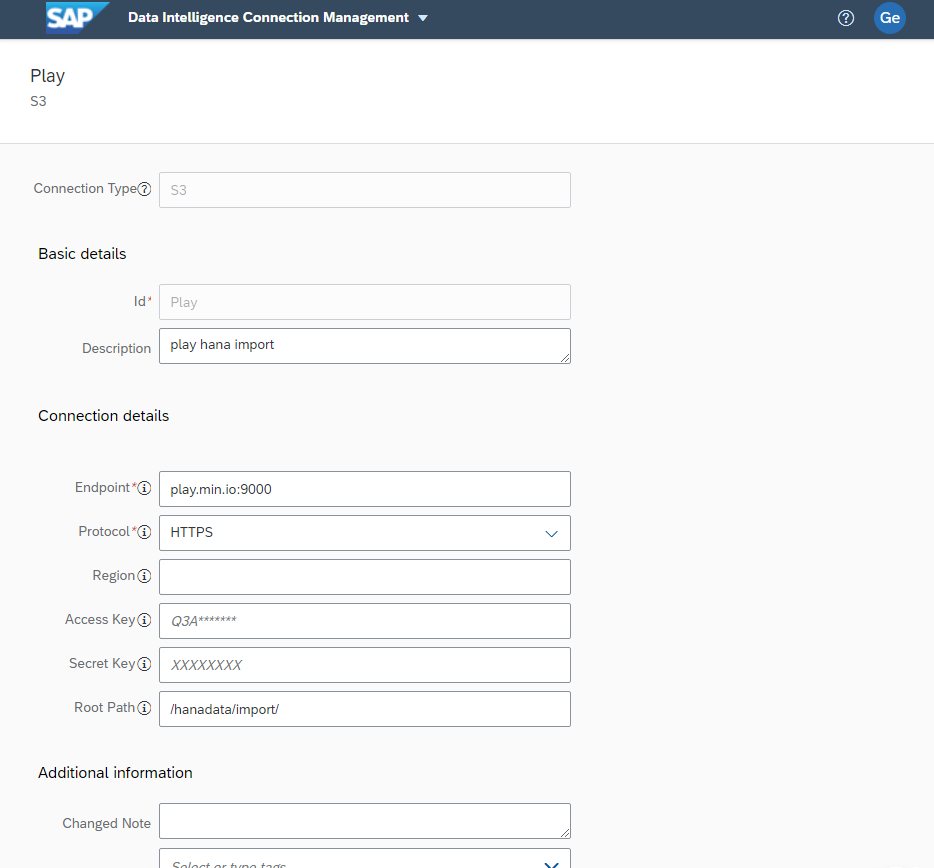
Make sure to click Test Connection to verify settings and then Save.
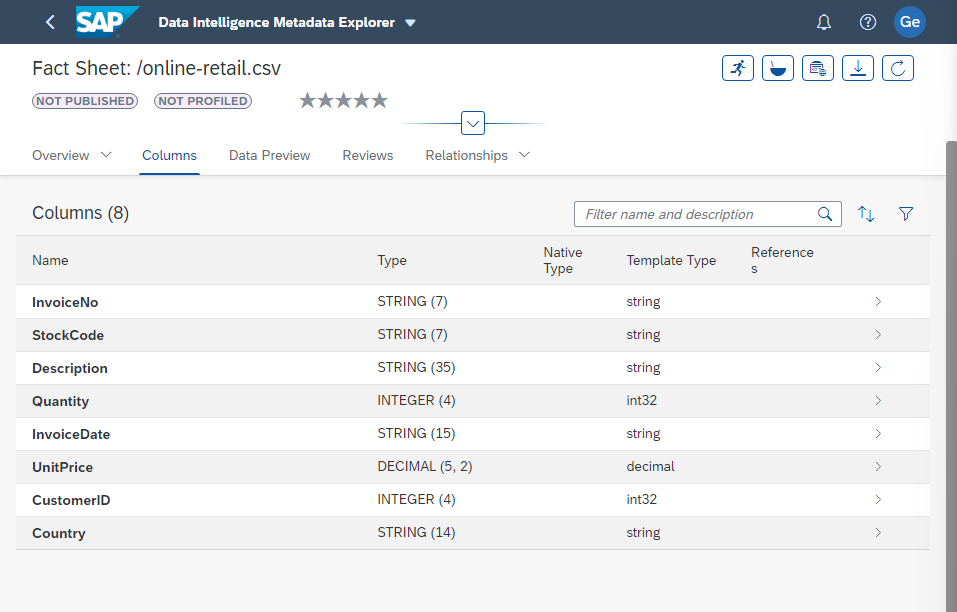
Let's verify that the connection is in order. Return to the SAP Data Intelligence Launchpad and click the Metadata Explorer tile, then click Browse Connections. Scroll to or search for the connection you just created, in my example I have used "Play". Click on your MinIO Connection. You will see all of the files saved in your MinIO bucket. Select the file you wish to import, click the three dots at the bottom right of the tile and select View Fact Sheet to see detailed information about the data it contains. You can also start data profiling, preparing and publishing data. Pretty cool stuff, and super easy to connect to MinIO.
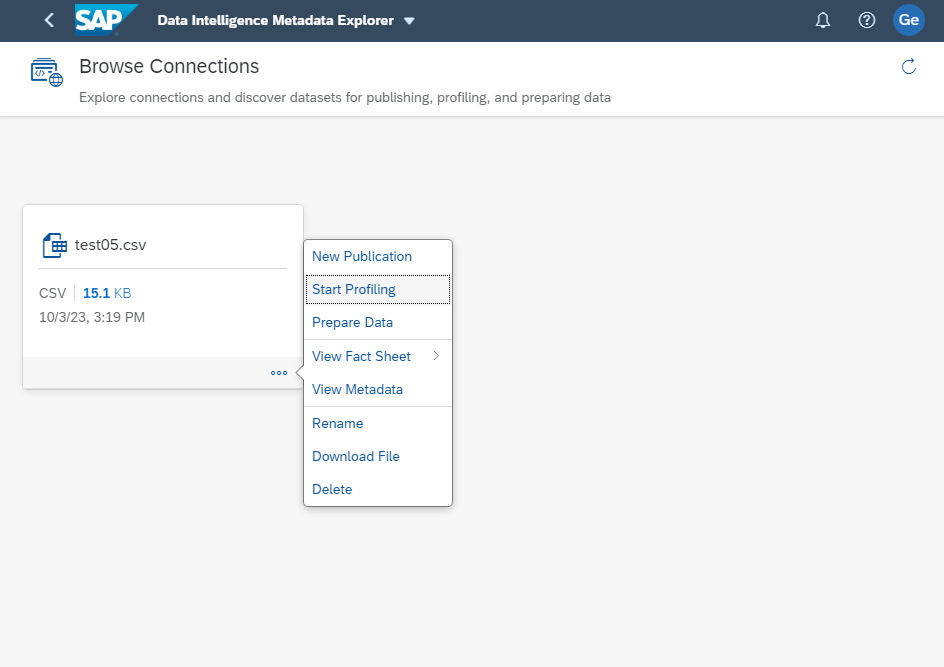
Next, we'll create the HDI container that will house the SAP HANA table. Log in to SAP HANA Cloud. If you are not a current customer, then sign up for a free trial. To provision a SAP HANA Cloud, SAP HANA Database instance, please follow Provision an Instance of SAP HANA Cloud, SAP HANA Database.
You must have SAP HANA Cloud Administration Tools installed. You must also have enabled Cloud Foundry. You must also have SAP HANA deployed to Cloud Foundry in the dev space and allow access from external IP addresses.
Open SAP BTP Cockpit and navigate to your subaccount, then choose Services, then Service Marketplace. Choose SAP HANA Schemas & HDI Containers (please note that trial users must choose SAP HANA Schemas & HDI Containers - Trial), then click the blue Create button.
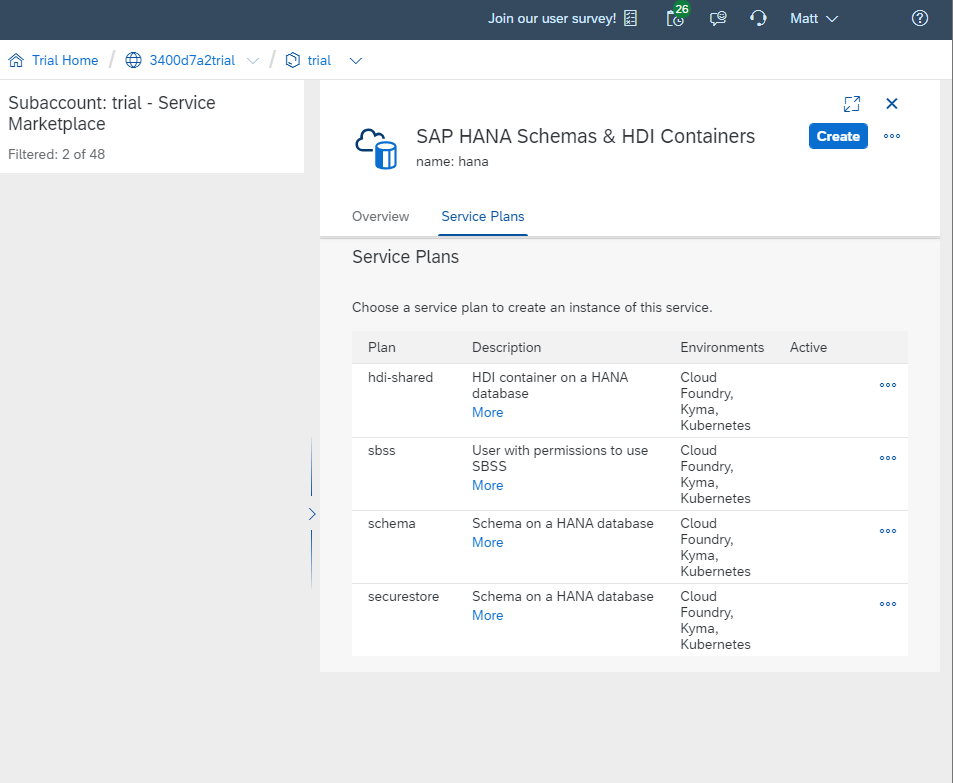
Choose a service plan from the dropdown and then enter a name for it. You'll do this first with Schema and then with HDI-Shared.
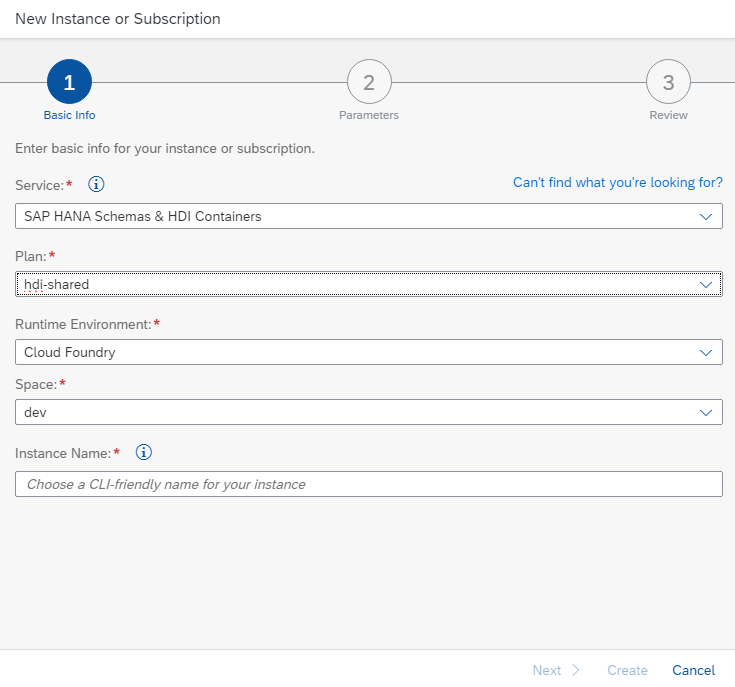
After you name each instance, click Create and watch as it is created.
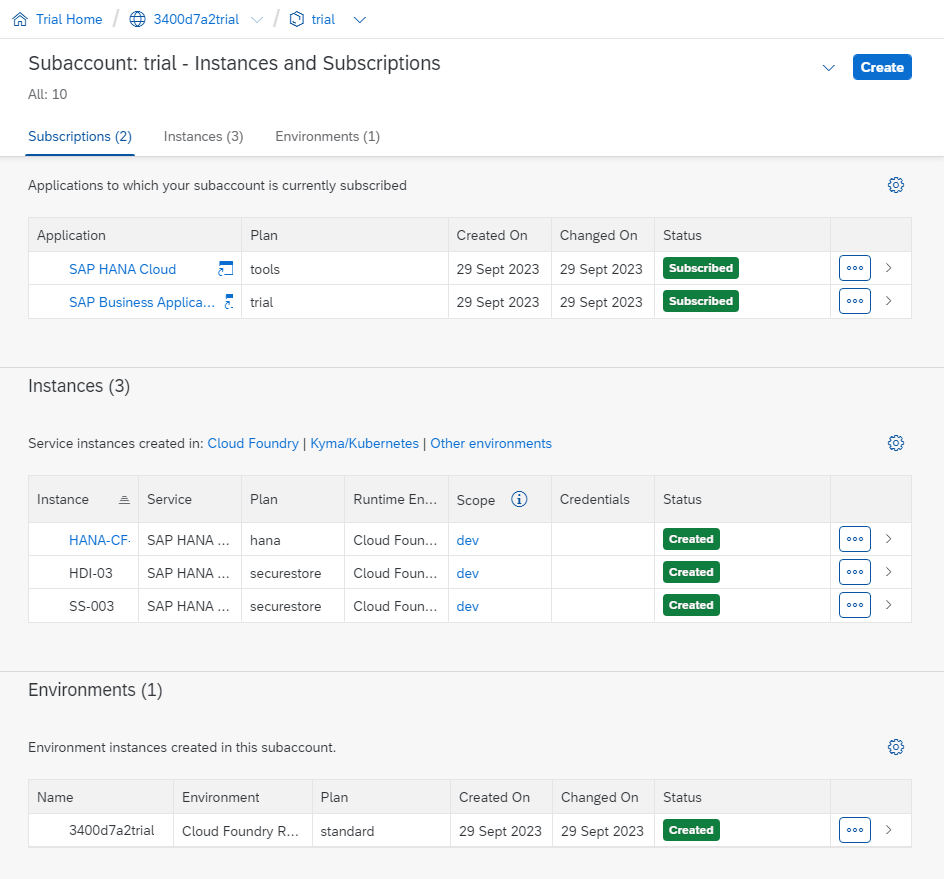
After these service instances are created, they will appear in the BTP Cockpit under Services > Instances and Subscriptions. You should see green boxes that say Created for each instance, providing you with a warm feeling of accomplishment.
Return to the SAP Data Intelligence Cloud and create a new connection to connect to our new HDI container. You can get connection details by viewing the SAP HANA Database instance and selecting Connections. You need the SQL Endpoint, port and your credentials.
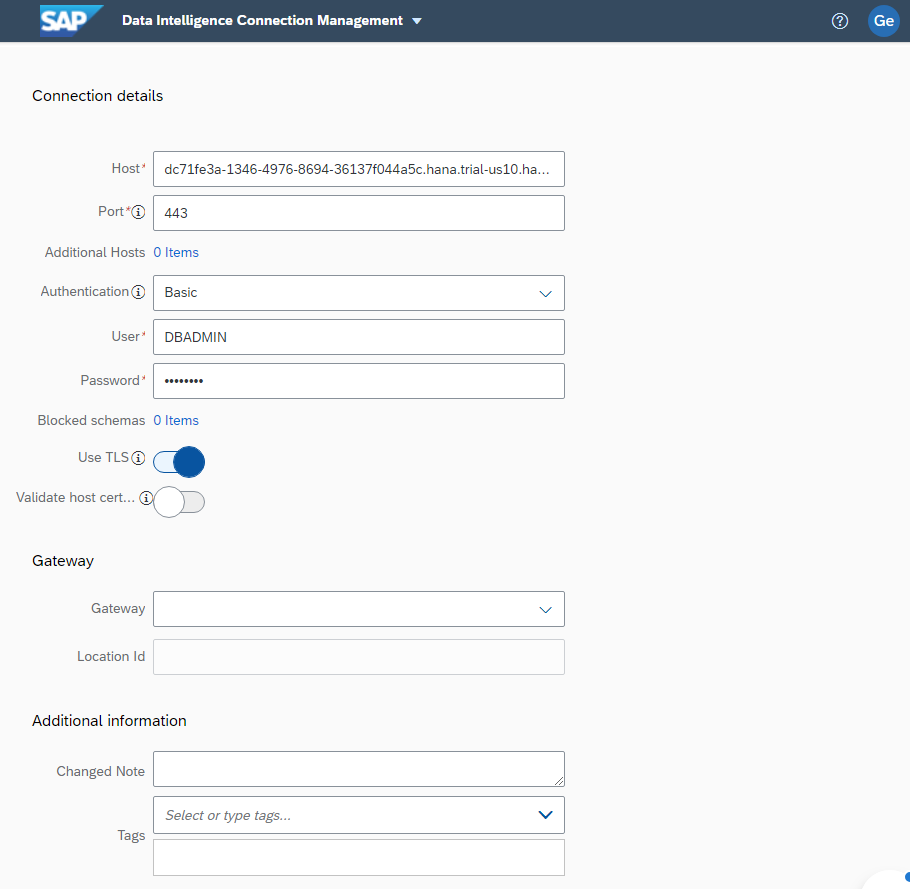
Make sure to click Test Connection to validate your configuration and then Create.
Configure a Pipeline With SAP Data Intelligence Modeler
The next step is to create a graph, or pipeline, that consists of a number of operators that you configure to build a specific process and then connect using input and output ports. The combination of ease of use, power and customization really impressed me. There's way too much to SAP Data Intelligence Modeler to do it justice in a paragraph, please see the Modeling Guide for SAP Data Intelligence.
Navigate back to the SAP Data Intelligence Launchpad and click on the Modeler tile. You see a workspace in front of you into which we'll drag and drop Operators from the menu on the left and then link and configure them.
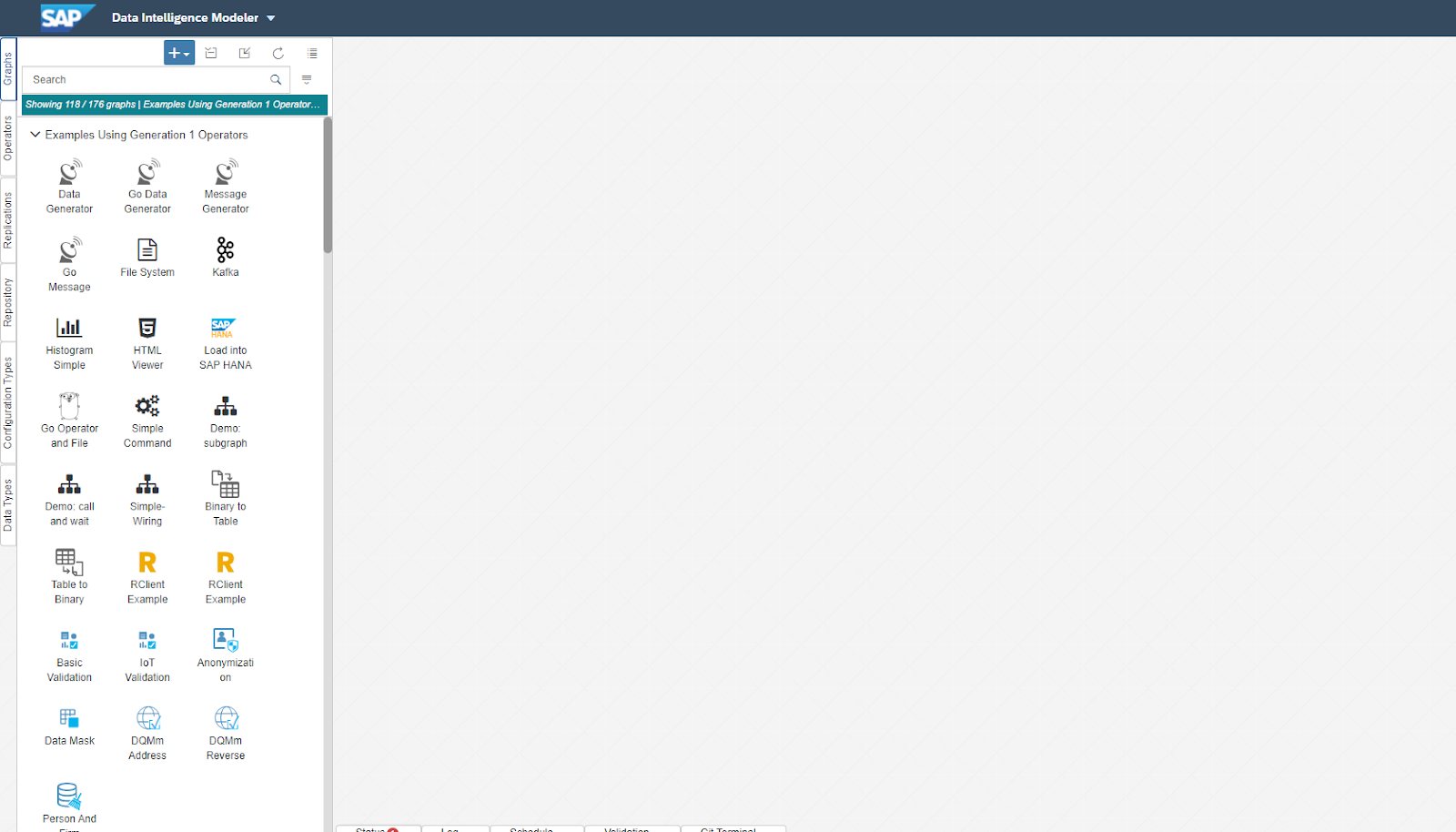
Click the big blue plus sign and then select Use Generation 1 Operators to create a new graph.
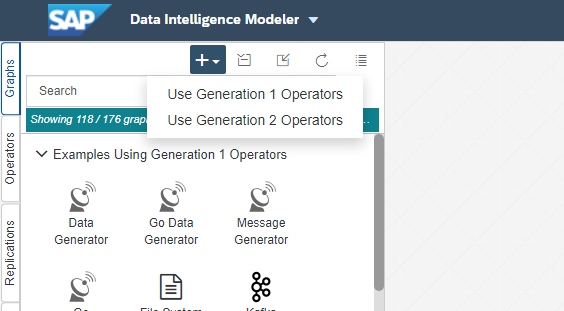
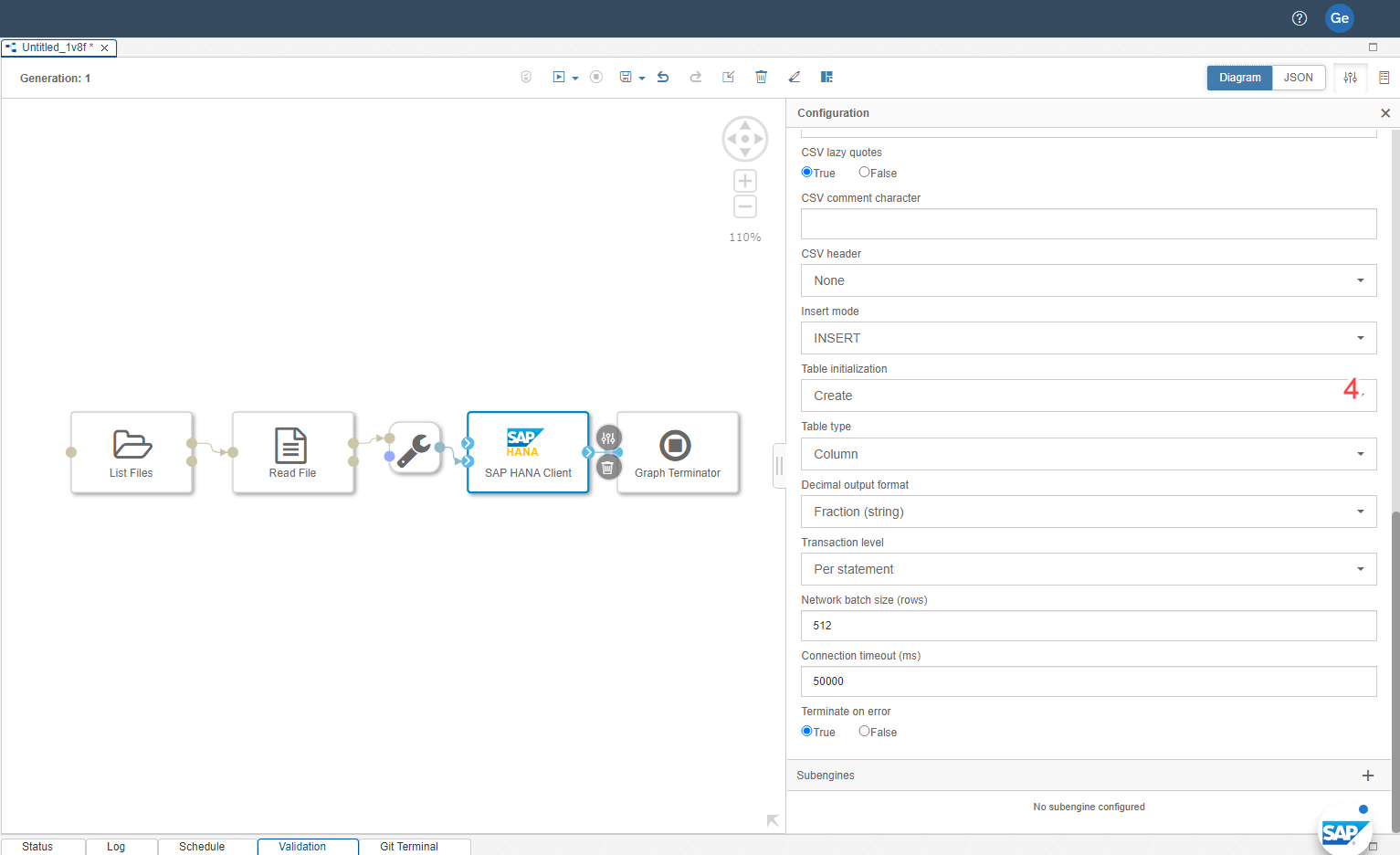
We're going to add the following Operators: Read File, List File, File Converter - To String Converter, SAP HANA Client, Graph Terminator. Search for those under the Operator tab to the left and double-click each one to add it to the workspace (we'll arrange and connect next). Your workspace should now look like this
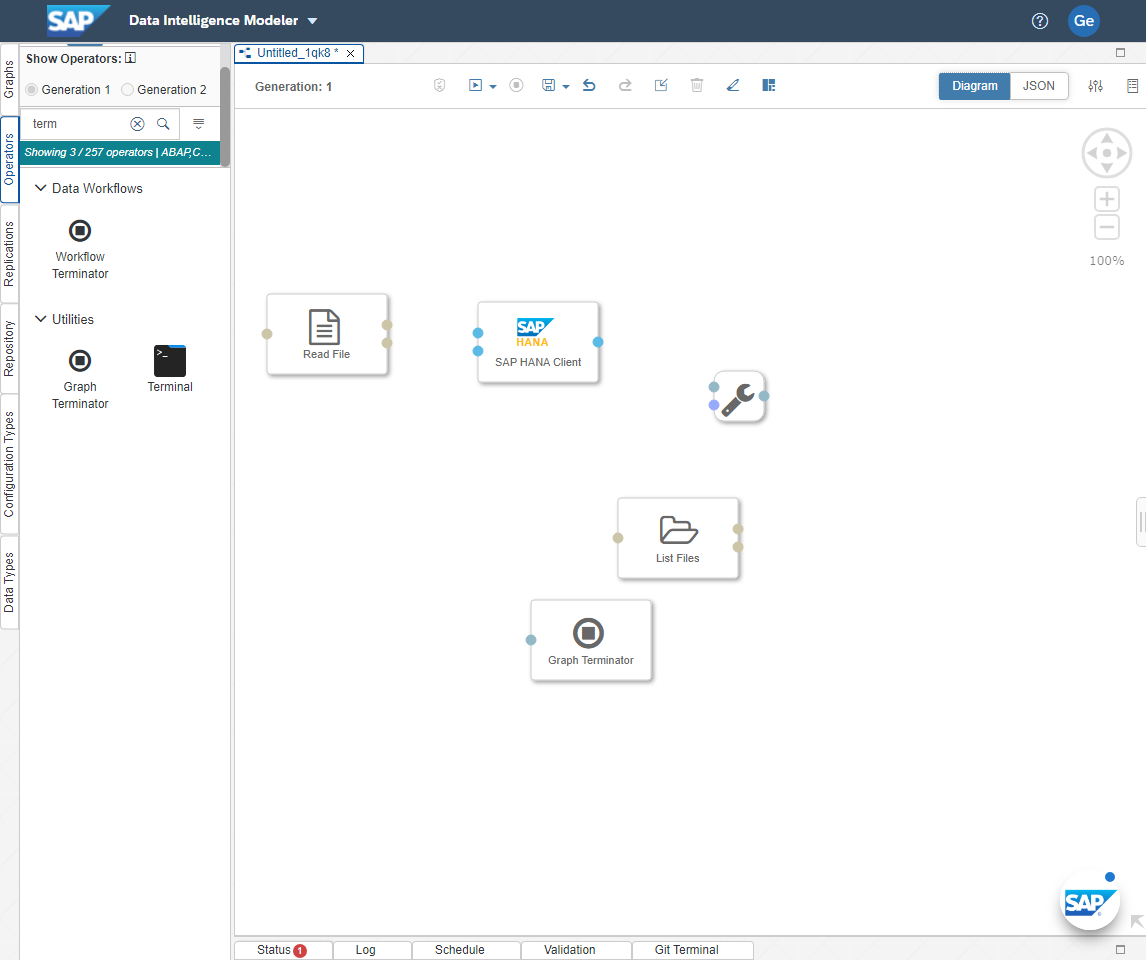
First, we will move List Files and Read File to the beginning of the graph, followed by File Converter, SAP HANA Client and Graph Terminator.
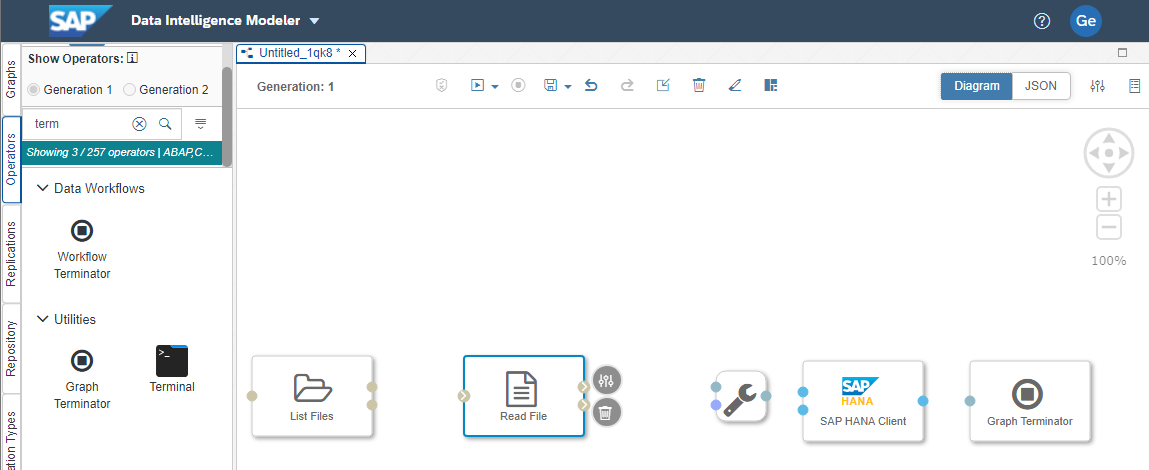
Open the configuration of List Files (the top circle to the right of the Operator), set List to Once, then choose the connector you built to MinIO and configure the Path for your file path. You can Validate the configuration and then save it.
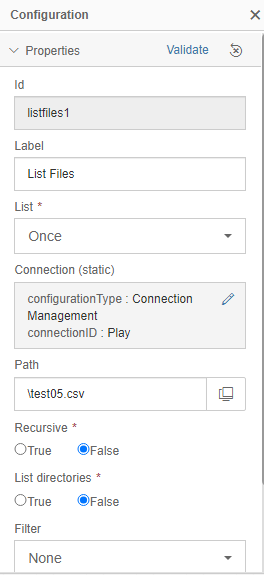
Configure Read File as follows:
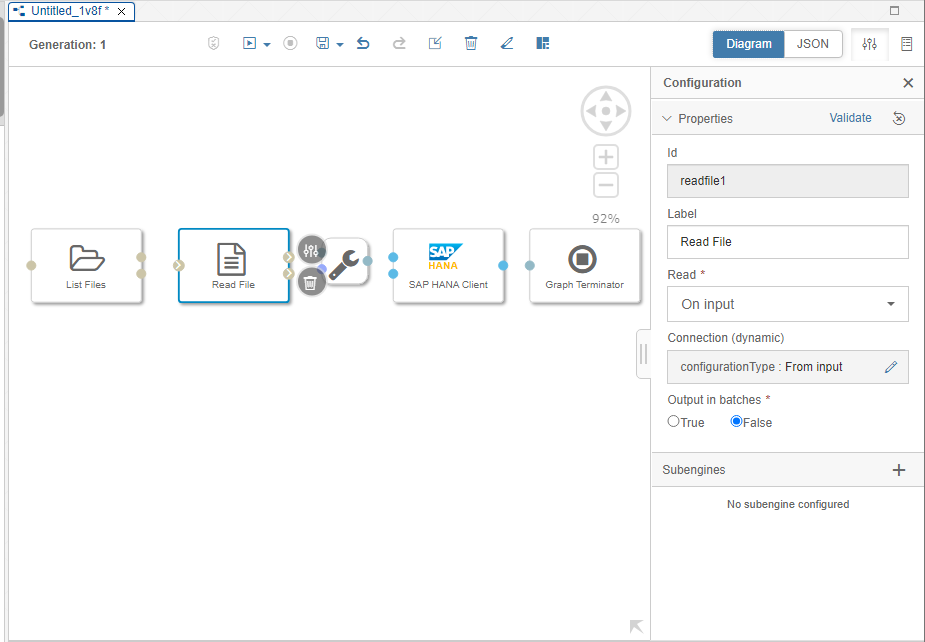
Connect the output port of each Operator to the input port of the next Operator. Click on the output port and drag it onto the input port. When you're done, your graph should look like this:
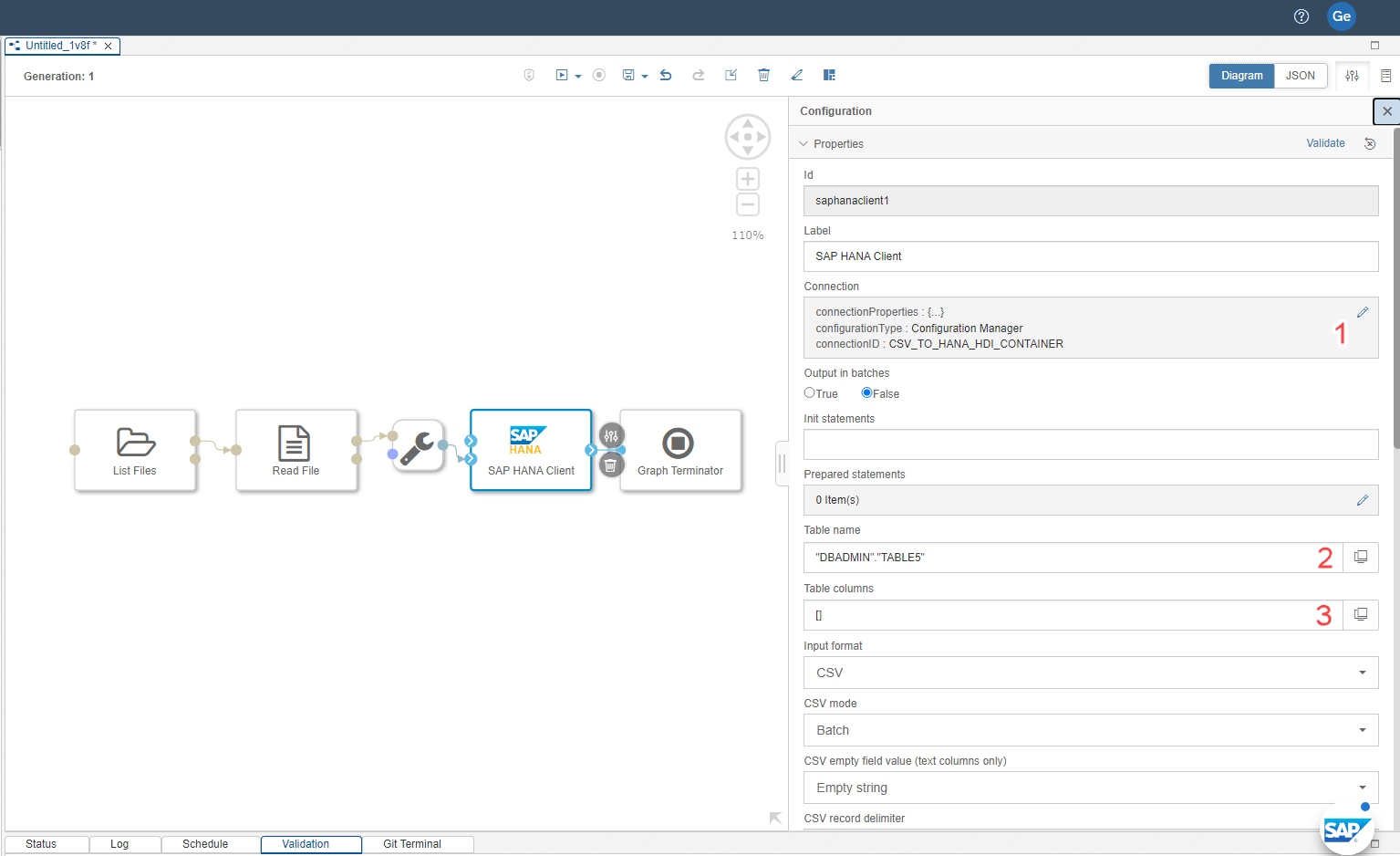
The last step is to configure the SAP HANA Client Operator. Click on that Operator and make the following changes (see screenshots below):
- Change the configured connection to your HDI container.
- Provide the database schema and table name as "Schema"."TABLE"
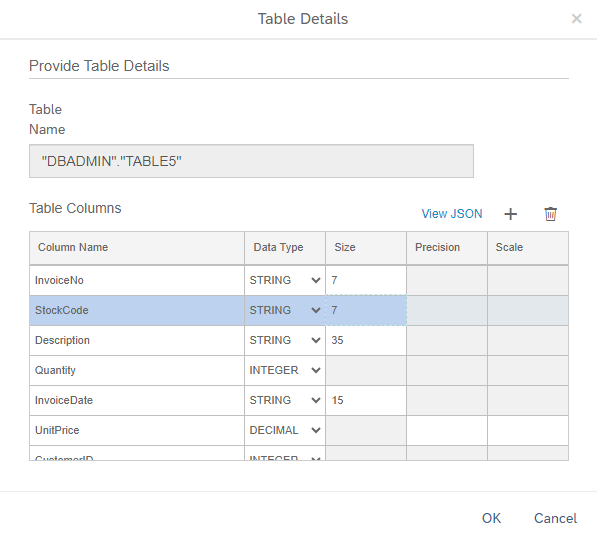
- Define columns and data types
- For Table initialization, choose "Create" to create the table in SAP HANA.
To configure table columns, clicking the browse icon will open the Table Details window where you can enter column names and data types. You can return to the SAP Data Intelligence Metadata Explorer and open a Fact Sheet on the file you're importing. Then click on Columns and now you can enter these names and types into the Table Details window.
Save your model and then run it.
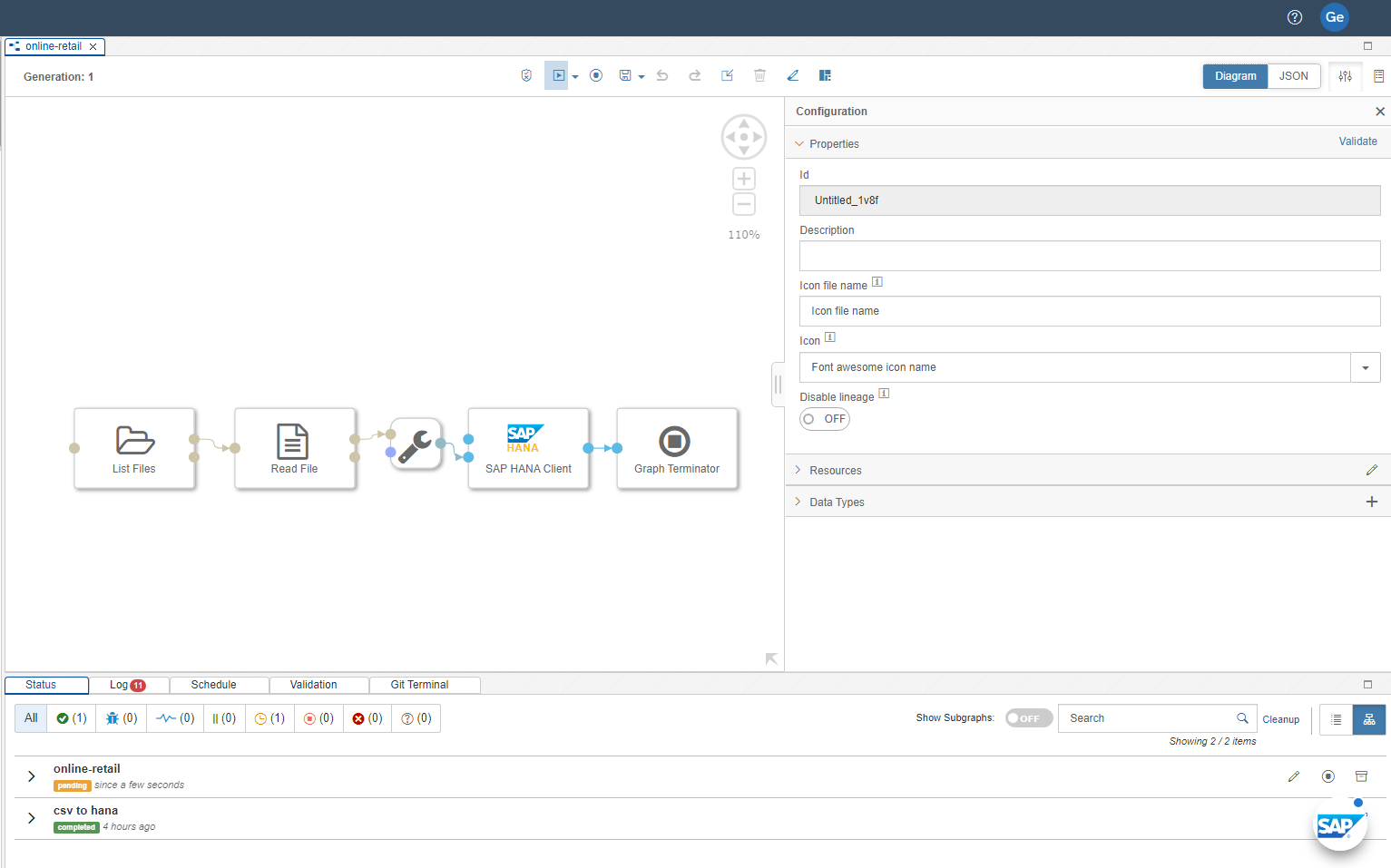
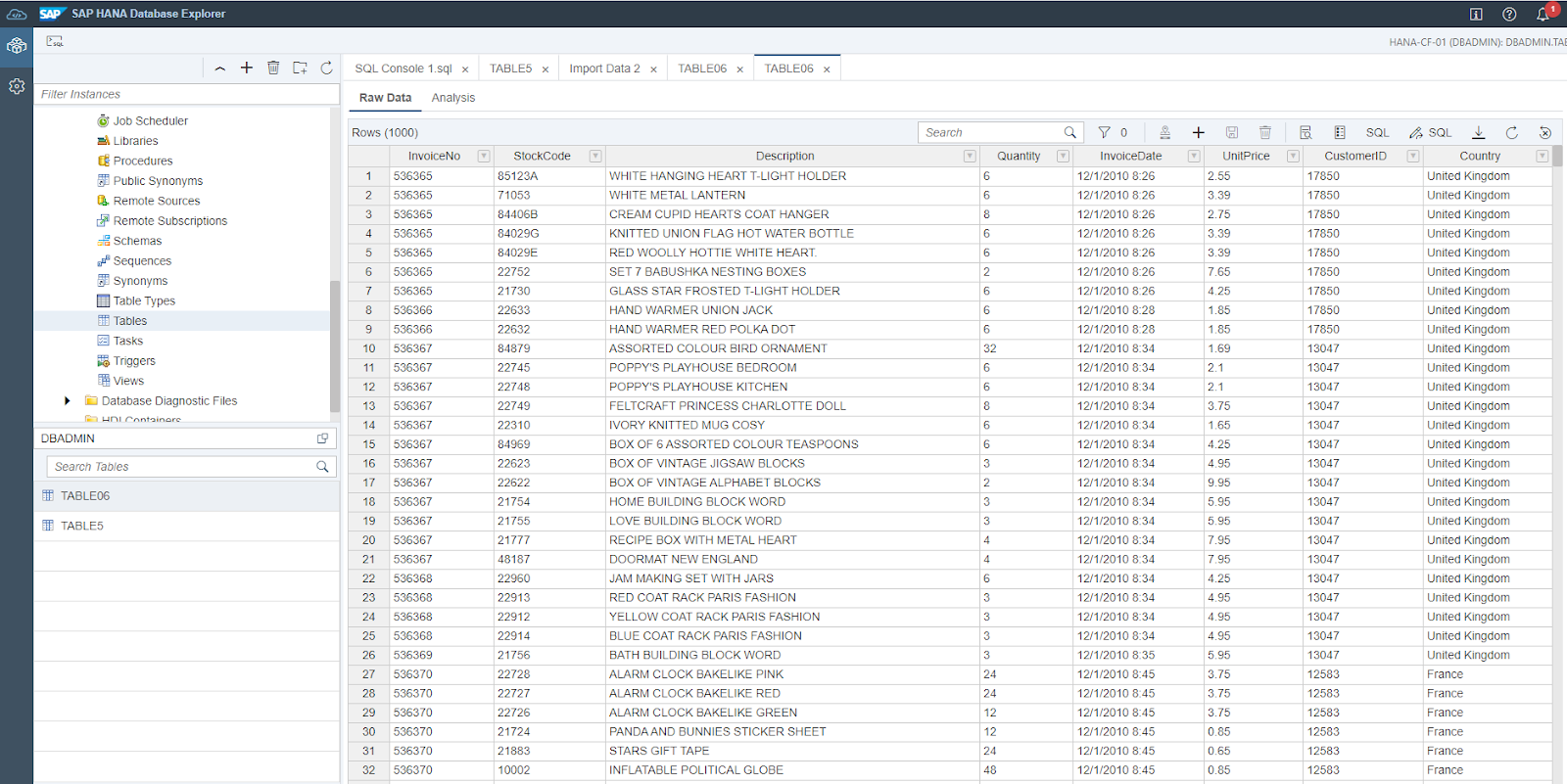
After running the model, make sure that there are no errors by clicking on the Status tab. If there are no errors, go back to the SAP BTP Cockpit, select your SAP HANA Cloud instance, click the three dots and select Open in SAP HANA Database Explorer. Browse to the SCHEMA and TABLE you imported data into, then right-click the table name and select Open Data to give your data a quick look to verify that everything worked.
Analytics and Machine Learning Without Limits
Combining MinIO with SAP Data Intelligence Cloud and SAP HANA Cloud provides enterprises with a flexible and scalable way to work with data from almost any source and in any format you can think of. Enterprises that have embraced the SAP ecosystem can build and maintain data pipelines for any data type, profile it, apply machine learning and import it into SAP HANA database for analytics and dashboarding.
A good way to make the most of data from IoT devices, network telemetry, web/application usage or anything else is to build a data lakehouse on MinIO, and then use cloud-native integrations to connect to any machine learning and analytics software. Use MinIO Object Lambda to pre-process data, tier hot and warm data and replicate data where it is needed across the multi-cloud.
Download MinIO and join our Slack community. Don't forget to check out MinIO How-To's on YouTube.






