Deepseek-style Reinforcement Learning Against Object Store

Tl;dr: We train a small LLM to become good at reasoning with reinforcement learning (similar to the process that led to Deepseek R1) all against AIStor AIHub, an on-premises model repository. Based on the great GRPO demo by will brown.
Motivation:
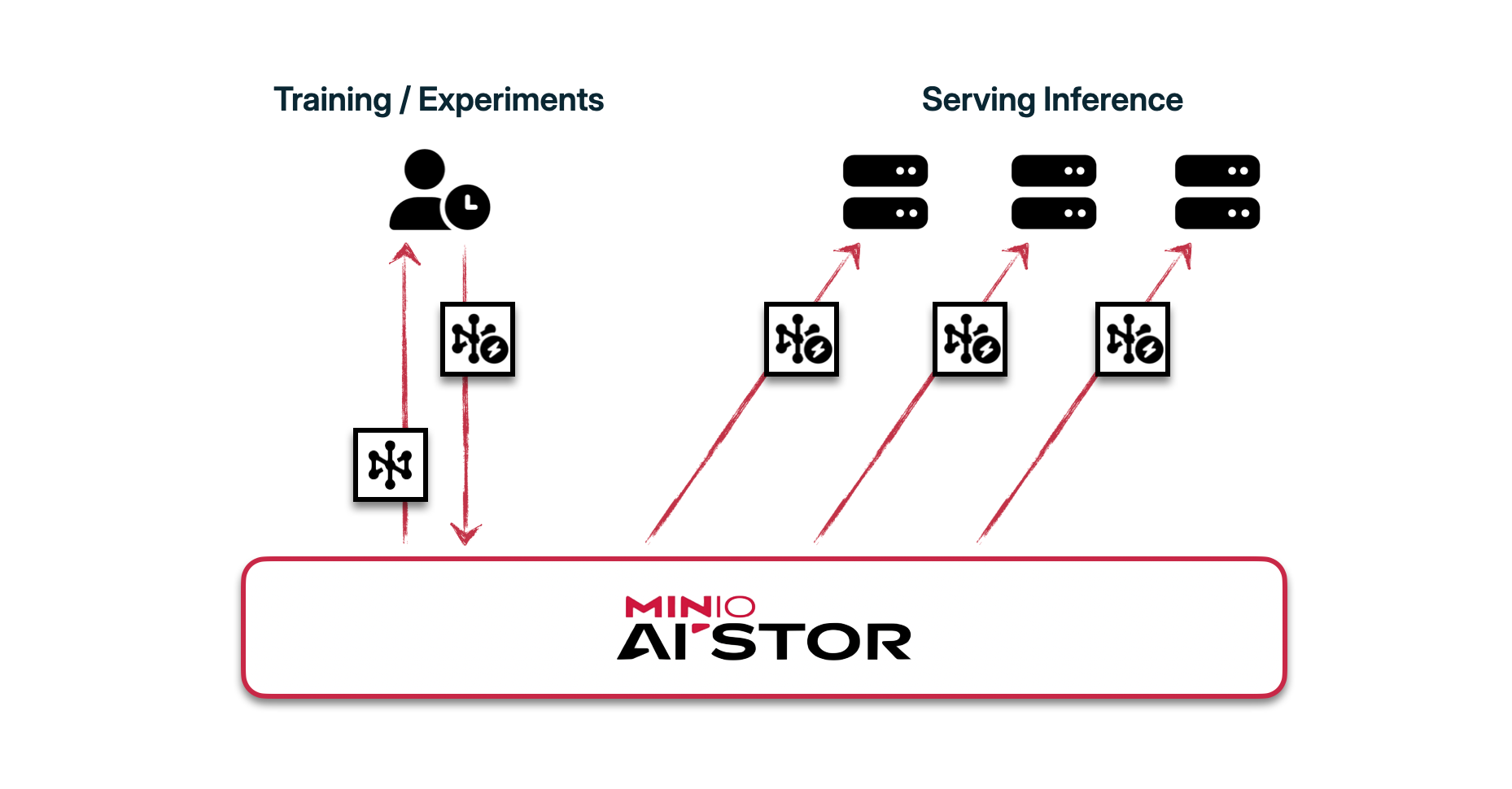
A growing requirement for teams is the need for an organized, secure, "single source of truth" for all their models and datasets. This is contrasted with the widespread adoption of public model and dataset repositories and APIs (most notably, HuggingFace). AIStor AIHub was created with this conundrum in mind. AIHub allows enterprises to create and consume their own dataset and model repositories on the private cloud (or in air-gapped environments) without changing a single line of code. In other words, by giving themselves a common model and dataset "zoo", organizations drastically reduce experimentation overhead, time-to-value with AI, and external dependencies for critical training and inference workloads.
But why do teams actually want a "organized, secure, single source of truth" for all their models and datasets"?
(1) Datasets are often proprietary (especially for tuning models).
(2) Rapid experimentation depends on reliable access to different models and datasets across the organization.
(3) Models used for and produced from these experiments are often proprietary.
(4) Desire to reduce third-party dependency for inference serving infrastructure.
In this post, we go over a very common workflow for teams working on reasoning models. We tune a small open source LLM to become good at reasoning using RL, against a dataset and model stored on-premises on AIHub. And we do it all with commonly-used libraries like trl and transformers (see: no code changes).
How AIHub Works
The only change that is needed to have your RL experimentation code point towards AIHub, your on-premises model and dataset repository, is setting an environment variable. Specifically:
HF_ENDPOINT=<your-aistor-aihub-endpoint>
Authentication is also supported on AIHub, in which case you will also have to set the following environment variable:
HF_TOKEN=<your-aihub-token>
Note: You can make an authenticated request to AIHub with your AIStor credentials to get a token.
With these environment variables set, code that uses transformers, datasets, trl, vllm, etc. (HuggingFace-using libraries) will point to your on-premises model and dataset repository built out on top of AIStor. Developer friendly. Enterprise friendly.
AIHub resides on a bucket of your choosing. On my AIStor deployment, AIHub was initialized on top of a bucket I named "ai-central" .
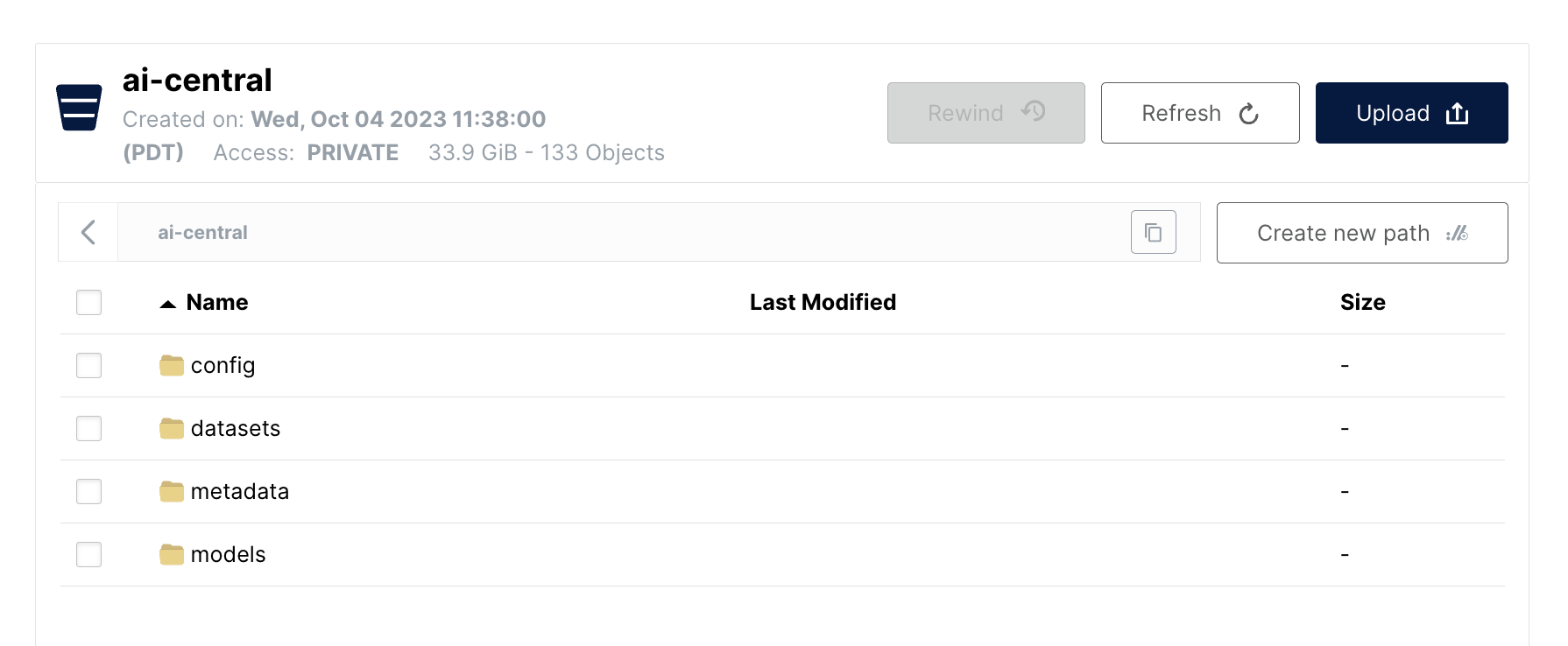
"ai-central" .When your client code (i.e. transformers, trl, datasets, vllm, etc.) calls for a model or dataset that is not already present on AIHub, it is one-time fetched from the public model repository. However, subsequent calls to load that model or dataset will only be between your client code and on-premises AIHub. This ultimately enables: (1) rapid experimentation with all the latest models and datasets out there, (2) same developer experience for reusing and working with proprietary models/datasets as with public models/datasets, and (3) no third-party dependency when loading/serving models for inference.
Approach
Now, here's the basic approach we will take:
- Load base model from AIHub onto GPU
- Pre-process dataset
- Define rewards for reinforcement learning
- Configure training parameters
- Train
- Save new checkpoint to AIHub
Training the Reasoner
Note: This code is based on the GRPO demo by will brown. Accordingly, this will also work against HuggingFace as well (just leave HF_ENDPOINT unset).
Here, we train the Qwen2.5-0.5B-Instruct model on the GSM8K dataset (more details on this dataset below) to develop reasoning behavior in a format we want. Generally, a heuristic for the GPU memory requirement for LLM training at full precision is ~20 GB of GPU memory per one billion parameters. Accordingly, this was run on a machine with an NVIDIA A100 GPU.
The code for this post is provided at the repository here.
Here's the entire training script, followed by some notes on what's going on here. Run this script with the environment variable HF_ENDPOINT=<your-aistor-aihub-endpoint> pointing to your AIHub endpoint.
import re
import torch
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from trl import GRPOConfig, GRPOTrainer
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
XML_COT_FORMAT = """\
<reasoning>
{reasoning}
</reasoning>
<answer>
{answer}
</answer>
"""
def extract_xml_answer(text: str) -> str:
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
def extract_hash_answer(text: str) -> str | None:
if "####" not in text:
return None
return text.split("####")[1].strip()
# uncomment middle messages for 1-shot prompting
def get_gsm8k_questions(split = "train") -> Dataset:
data = load_dataset('openai/gsm8k', 'main')[split] # type: ignore
data = data.map(lambda x: { # type: ignore
'prompt': [
{'role': 'system', 'content': SYSTEM_PROMPT},
{'role': 'user', 'content': x['question']}
],
'answer': extract_hash_answer(x['answer'])
}) # type: ignore
return data # type: ignore
dataset = get_gsm8k_questions()[:3]
# Reward functions
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
q = prompts[0][-1]['content']
extracted_responses = [extract_xml_answer(r) for r in responses]
print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
def int_reward_func(completions, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def soft_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def count_xml(text) -> float:
count = 0.0
if text.count("<reasoning>\n") == 1:
count += 0.125
if text.count("\n</reasoning>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1])*0.001
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001
return count
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]
model_name = "Qwen/Qwen2.5-0.5B-Instruct"
output_dir="outputs/Qwen-0.5B-GRPO"
run_name="reasoner/Qwen-0.5B-GRPO-gsm8k"
training_args = GRPOConfig(
output_dir=output_dir,
run_name=run_name,
learning_rate=5e-6,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_ratio = 0.1,
lr_scheduler_type='cosine',
logging_steps=1,
bf16=True,
per_device_train_batch_size=16,
gradient_accumulation_steps=4,
num_generations=16,
max_prompt_length=256,
max_completion_length=200,
num_train_epochs=1,
save_steps=100,
max_grad_norm=0.1,
log_on_each_node=False,
use_vllm=True,
vllm_gpu_memory_utilization=.3,
vllm_device="cuda:0",
report_to="none",
push_to_hub=True,
hub_model_id=f"{run_name}",
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
trainer = GRPOTrainer(
model=model,
processing_class=tokenizer,
reward_funcs=[
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
int_reward_func,
correctness_reward_func],
args=training_args,
train_dataset=dataset,
)
print(trainer.accelerator.num_processes)
trainer.train()
The Training Objective
Our objective is to train our LLM to become better at elucidating its reasons for coming up with a particular answer. In other words, we would like the LLM to answer a question with reasoning followed by the answer. In addition to just being a pretty cool behavior, models like OpenAI o1 and Deepseek-R1 (and its predecessor R1-Zero) have demonstrated that reasoning has led to powerful emergent behaviors like "self-verification, reflection, and generating long CoTs" (Deepseek). This is an active area of research, but here we specifically use Deepseek-style Group Relative Policy Optimization (GRPO).
Data Pre-processing
The dataset that we are using to train the reasoner, is the GSM8K dataset from OpenAI. Check it out here. The dataset contains pairs of high quality grade school math word problems and their corresponding detailed answers. The answers in the GSM8K dataset are formatted like:
<steps> #### <final answer>
We do some mild pre-processing in get_gsm8k_questions to extract the final answer for use in the RL routine.
Reward definitions (an aside on GRPO)
Next, we define the reward functions that will be used to guide the RL routine. You can think of this as defining behaviors we want to reward during training, by giving "points" when desired behavior occurs and giving no points otherwise. This latter point is one of the big differences in the GRPO approach compared to previous approaches. In GRPO, the rewards are strict (points when desired behavior is strictly met, no points otherwise). As an example, a behavior we want to steer our model towards is, producing responses that are formatted like:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
During training, if the model's output matches this format, we would like to reward that with 0.5 "points" as defined in strict_format_reward_func(). However, we also want to make sure that the model continues to maintain correctness, which we reward handsomely as defined in correctness_reward_func().
Initial model
The initial model we will be training is Qwen2.5-0.5B-Instruct. I have used this model in previous experiments within my organization's private cloud, so it automatically already resides on AIHub. As a result, further model load requests, whether for training of inference, will now be served from your private cloud.
With HF_ENDPOINT pointing to our AIHub, we fetch the model from AIHub into our process and load it onto the GPU with standard transformers code like:
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
).to("cuda")
Creating the trainer and running it!
The trl library provides helpful abstraction for configuring and running the GRPO RL routine (GRPOConfig and GRPOTrainer). To ensure that the resulting reasoner model is saved to AIHub for further experimentation or deployment for inference, I set push_to_hub=True. This is all there is to it. As mentioned above, the HF_ENDPOINT environment variable has to be pointing to AIHub, otherwise this routine will attempt to push the model to a public cloud repository on HuggingFace.
With all this in place, we can start the RL training routine:
~/sid/dev$ HF_ENDPOINT=<my-aihub-endpoint> HF_TOKEN=<my-token> uv run grpo_script.py
INFO 02-28 01:46:17 init.py:207] Automatically detected platform cuda.
INFO 02-28 01:46:25 config.py:549] This model supports multiple tasks: {'embed', 'classify', 'score', 'reward', 'generate'}. Defaulting to 'generate'.
INFO 02-28 01:46:25 llm_engine.py:234] Initializing a V0 LLM engine (v0.7.3) with config: model='Qwen/Qwen2.5-0.5B-Instruct'...
...
To demonstrate the behavior that our newly created model ends up learning, here is an example.
At the beginning of the training routine, the model is not keen on following the desired reasoning format:
Question:
Every Monday to Friday morning, Alice walks 10 miles through a large grass field to get to school. To avoid the hot afternoon sun on her way home, she walks 12 miles through a forest. When she gets home on Friday, how many miles will she have walked that week?
Answer:
110
Response:
Alice walks 10 miles each morning from Monday to Friday, so she walks a total of 5 * 10 = 50 miles by Friday morning.
The forest walks are different, but 12 miles through the forest are covered on Friday evening and the following Friday morning, converting this to miles, she walks 12 * 2 = 24 miles by Friday evening after the forest walks.
By the following Friday, Alice walks the 10 miles from Monday to Friday over a total of 5 + 2 = 7 days.
So over the entire week, Alice will have walked a total of 24 miles from Friday evening to Friday morning.
Notice that the model's response does not obey the reasoning-followed-by-answer format we want it to develop. Also, we notice that the answer is way off.
In contrast, this is a sample towards the end of the training routine:
Question:
Steve finds 100 gold bars while visiting Oregon. He wants to distribute his gold bars evenly to his 4 friends. If 20 gold bars were lost on the way back to San Diego, how many gold bars will each of his 4 friends get when he returns?
Answer:
20
Response:
<reasoning>
Steve initially finds 100 gold bars and wants to distribute them evenly to his 4 friends. After 20 gold bars are lost, he has \(100 - 20 = 80\) gold bars left to distribute.
Therefore, each of Steve's 4 friends will get \(80 \div 4 = 20\) gold bars.
So, each of his 4 friends will get \(20\) gold bars when he returns.
</reasoning>
<answer>
20
</answer>
Notice that the desired format is met perfectly and the answer is correct. Big difference!
The New Model
.
..
...
....
.....
{'loss': 0.1154, 'grad_norm': 18.625, 'learning_rate': 0.0, 'rewards/xmlcount_reward_func': 0.19140625, 'rewards/soft_format_reward_func': 0.0, 'rewards/strict_format_reward_func': 0.0, 'rewards/int_reward_func': 0.1953125, 'rewards/correctness_reward_func': 0.21875, 'reward': 0.60546875, 'reward_std': 0.7295257151126862, 'completion_length': 118.921875, 'kl': 2.883904218673706, 'epoch': 1.0}
{'train_runtime': 7453.3799, 'train_samples_per_second': 1.003, 'train_steps_per_second': 0.251, 'train_loss': 0.07686217568939345, 'epoch': 1.0}
100%|███████████████████████████████████████████████████████████| 1868/1868 [2:04:13<00:00, 3.99s/it]
~/sid/dev$The final output of the RL training routine.
The RL routine has concluded. Since HF_ENDPOINT pointed to your AIHub, this ensured that the new model repository is created on AIStor and that the new checkpoint's files are pushed there. Let's verify it by checking the bucket ("ai-central")that AIHub is on top of, under the prefix corresponding to this new model ("models/sid/Qwen-0.5B-GRPO-gsm8k/main"):
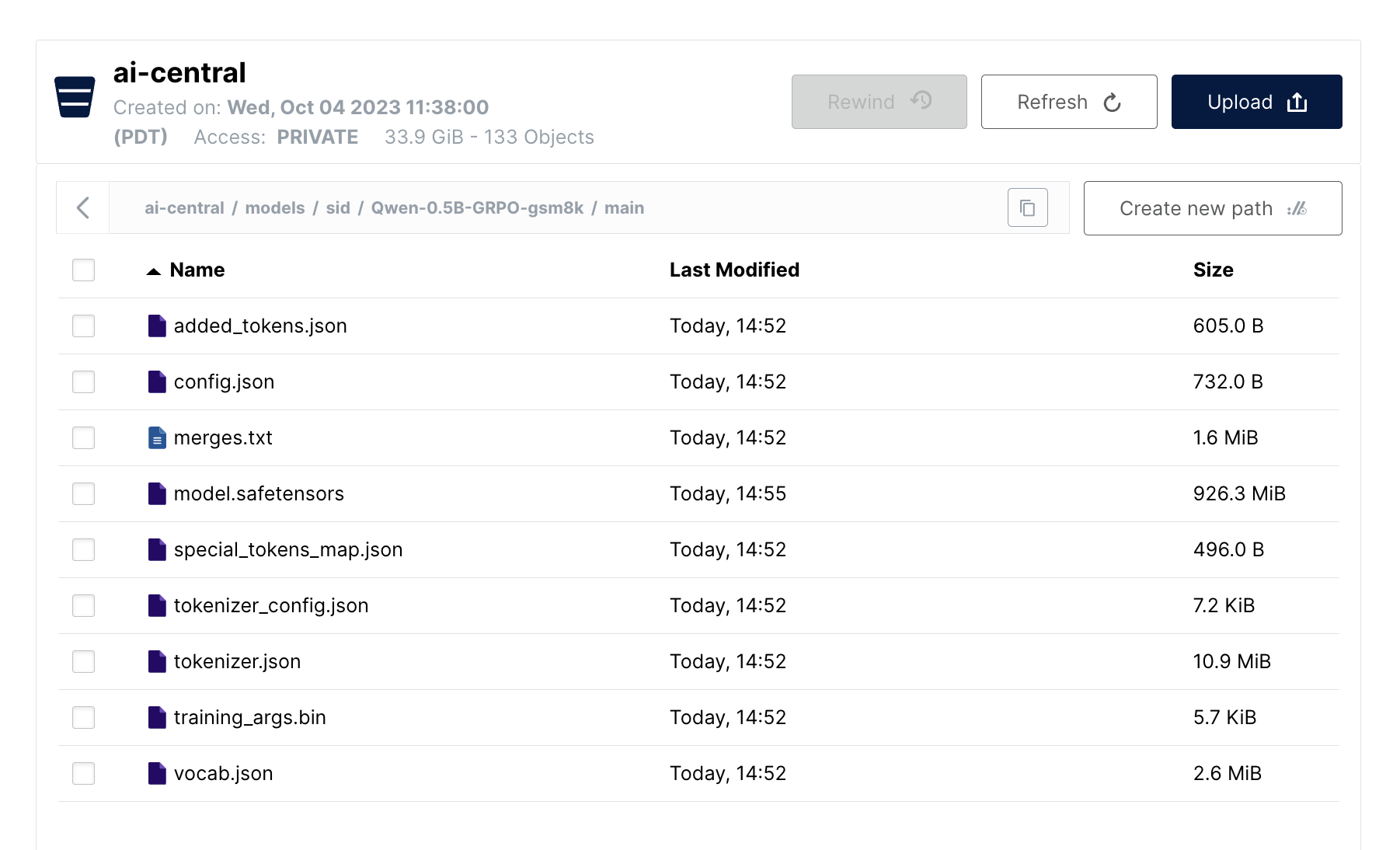
Now, this reasoner model is available to the entire organization to experiment with or load for inference, all without breaking out of your private cloud or forfeiting ownership of the model serving process.
Closing Thoughts

The benefits of post-training scaling are driving organizations to create their own reasoning models on proprietary data. Imagine an organization tuning an open source model on their customer service call logs in order to make a highly capable, problem-solving co-pilot for customer service teams. Imagine then, that they reliably load these newly saved models for inference, without worrying about public cloud model repository outages. All the while, imagine that this organization can keep their models easy to experiment with and build applications around, using libraries developers love like transformers, trl, and more. With AIHub, we can do more than just imagine 🙂.
AIHub enables organizations to keep their AI experimentation and infrastructure on-premises, while still affording their developers the freedom and power of established frameworks.
As always, if you have any questions join our Slack Channel or drop us a note at hello@min.io.






