The Case for Embedding Delta Sharing into Object Storage

Modern AI and analytics workflows rarely stay in one place. Data lives on-premises, in private clouds, and across public cloud platforms. Compute happens wherever it makes the most sense for cost, performance, data freshness or compliance. The challenge has always been making these distributed environments work together without creating operational or security headaches or adding expense and complexity by duplicating data.
Databricks has established itself as a leader in cloud-based AI/ML workloads, earning recognition as a Leader in the Gartner Magic Quadrant for Data Science and Machine Learning Platforms for four consecutive years and in the Gartner Magic Quadrant for Cloud Database Management Systems for five consecutive years. But for many enterprises, the data that fuels these workloads lives on-premises, often for good reasons: regulatory requirements, data sovereignty, cost optimization, or simply because that's where it was created.
Today, most teams bridge this gap by building custom pipelines to copy, sync and move around data in and out of the cloud. But, this approach adds cost and complexity.
There's a better way. By embedding Delta Sharing directly into on-premises object storage, organizations can make on-prem data a first-class participant in AI/ML and analytics workflows in the cloud without adding infrastructure or duplicating data.
The Current State of Delta Sharing
Delta Sharing is an open protocol, or REST API, for secure, real-time data sharing developed as part of the Delta Lake project under the Linux Foundation. It allows data providers to share tables with recipients who can then query that data, in place, using their preferred tools. While Delta Sharing originated in the Delta Lake project, the protocol itself is format-agnostic and can expose tables stored in any lakehouse format, including both Delta Lake and Apache Iceberg. The protocol is read-only by design, which makes it well-suited for scenarios where data integrity is a priority.
The ecosystem of compatible tools is broad. While recipients primarily access shared data through Databricks, other platforms such as Apache Spark, Trino, Power BI, Tableau, and Python with pandas also support the protocol. This openness is one of Delta Sharing's strengths: data providers share once, and recipients use whatever tools they prefer.
Because Delta Sharing operates at the protocol level rather than the storage format level, organizations would be able to share tables regardless of whether they use Delta Lake, Apache Iceberg, or a mix of both. This flexibility would be essential for enterprises that have standardized on different formats across teams or are in the process of migrating between them.
However, current Delta Sharing deployments typically require a standalone Delta Sharing server. In practice, this often means additional components: reverse proxies for security, sidecar services for authentication, and custom integration logic to connect everything together. Each of these adds operational overhead. There's another service to deploy, secure, patch, monitor, and maintain.
The result is that sharing data from on-premises storage to cloud compute is possible, but the path to get there is complex. For organizations that want to enable hybrid analytics without building out significant new infrastructure, this complexity can be a barrier.
What Changes with Native Delta Sharing Embedded into Object Storage
Object storage is the foundational layer of modern data lakehouses. It's where the data lives. The question is: why not make that layer work harder for modern workloads by centralizing infrastructure, security, and governance in one place?
Steps have already been taken to embed lakehouse APIs directly into on-premises and hybrid object storage. What would it look like if other critical lakehouse components such as Delta Sharing were embedded directly into on-premises object storage?
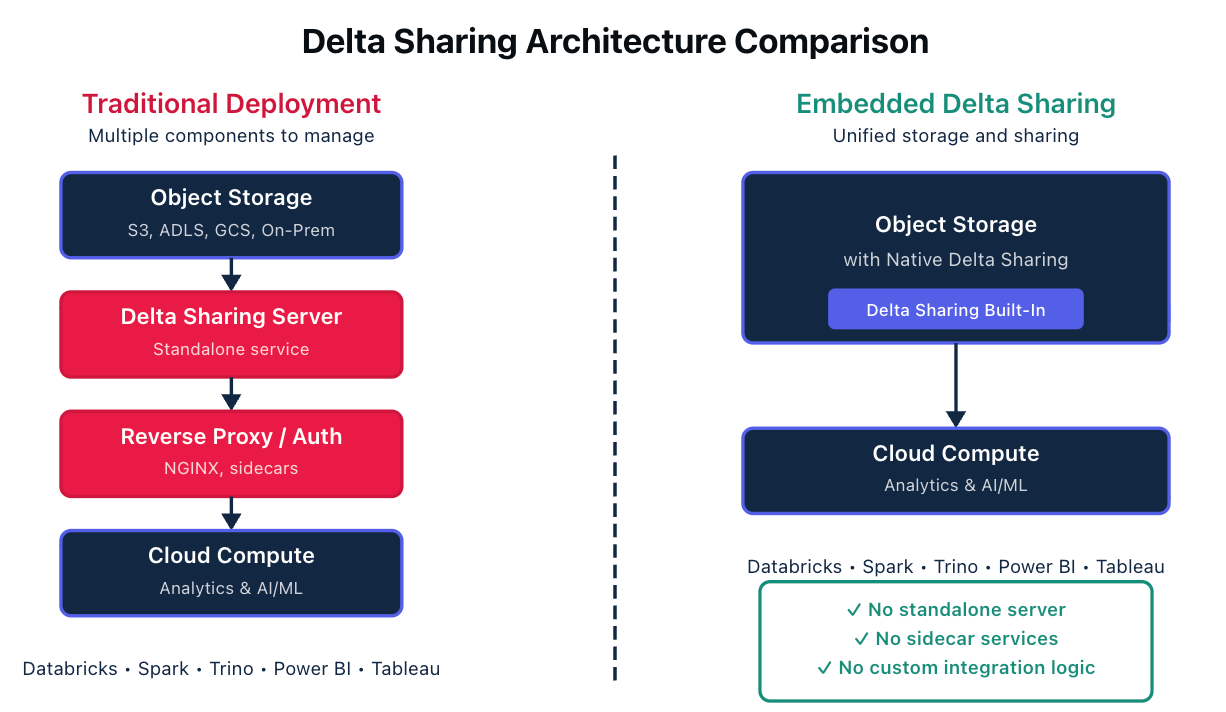
To begin with, rather than deploying a separate sharing server alongside your storage, embedding requires that the sharing capability would become native to the storage platform itself. Shares would be defined, secured, and published from the same system that stores the data.
Key Benefits of this Architecture
Simplified Architecture
Every additional component in a data architecture is something that needs to be deployed, configured, secured, and maintained. When Delta Sharing is embedded into object storage, you would eliminate an entire layer of infrastructure. There would be no standalone Delta Sharing server to manage. No sidecar services. No custom integration logic. No separate governance plane that needs to stay synchronized with your storage policies.
Storage and sharing would become unified in a single system. Platform and infrastructure teams would have fewer moving parts to manage. The operational burden would drop, and there would be fewer potential points of failure between your data and the tools that need to access it.
Eliminate Data Duplication
One of the most common patterns in hybrid analytics is copying data from on-premises systems to cloud storage so that cloud-based tools can access it. This works, but it comes with costs: storage costs for maintaining two copies, compute costs for running sync jobs, and operational costs for managing the pipelines that keep everything in sync.
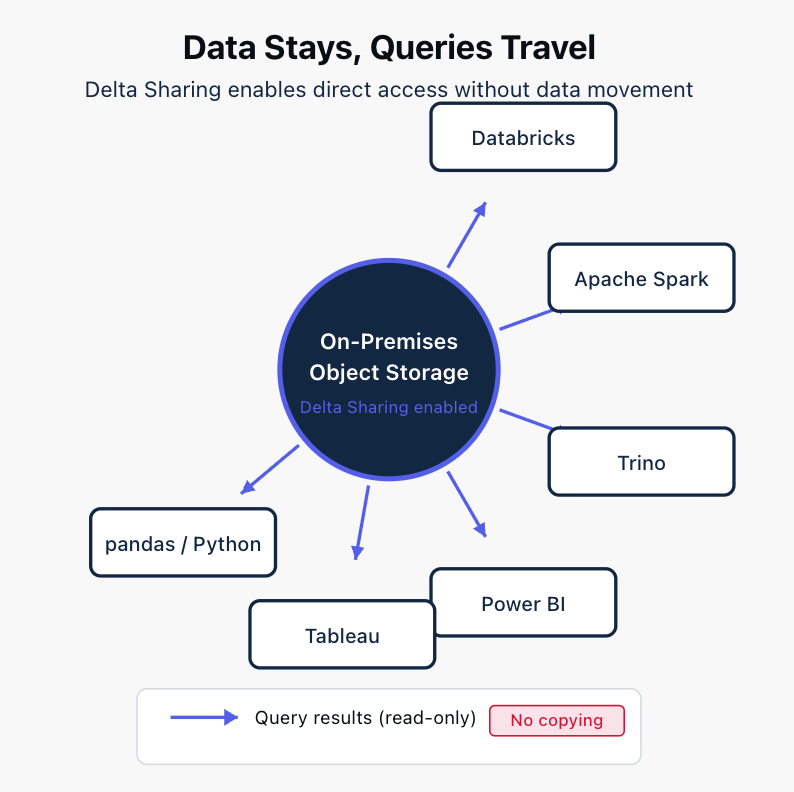
With embedded Delta Sharing, on-premises data could be accessed directly by compute engines, whether those engines run in Databricks, on-premises Spark clusters, or anywhere else. There would be no need to copy or sync data between environments. The data would stay where it is, and query results would flow to wherever they're needed.
This would eliminate the version drift that inevitably occurs when data exists in multiple locations. There would be one source of truth, and all consumers would see the same data.
Faster Time-to-Insights
Traditional data sharing approaches typically require copying and moving terabytes of data before analysis can begin, adding hours of transfer time and creating a stale snapshot the moment it lands. Delta Sharing eliminates this replication step, letting analytics tools query live data directly.
When Delta Sharing is embedded in the storage layer itself, queries wouldn’t route through a separate server. Fewer hops would mean lower latency and faster time-to-insights. Analysts and data scientists work with current data rather than waiting for exports or working with snapshots that are already out of date.
Control and Cost Optimization
When you control the storage layer, you control your own data. Hybrid sharing would become a way to reduce cloud spend by keeping data on-premises while still enabling cloud-based analytics. You would get the flexibility of modern AI/ML tools without surrendering control of your data or paying to store it twice.
This is particularly valuable for organizations with significant data volumes or strict data residency requirements. The data would stay where it needs to be for regulatory, cost, or operational reasons, while still participating fully in cloud-based workflows.
Unified Table and Share Lifecycle
Managing data assets would become simpler when the table lifecycle and share lifecycle are handled together. This is especially valuable for organizations that also use an embedded Iceberg catalog, where table metadata and sharing policies can be managed in a coordinated way.
When you update a table, those changes would be immediately reflected in shares. There would be no separate process to update sharing configurations or propagate changes to a different system. The mental model is straightforward: manage your tables, and sharing follows automatically.
Storage-Level Enforcement
Delta Sharing is read-only by design. When that read-only guarantee is enforced at the storage layer, you would get a level of assurance that's difficult to achieve when access controls are applied upstream in compute services.
Compute services can be misconfigured. Permissions can drift. By enforcing access controls where the data physically lives, you would reduce the risk that a misconfiguration somewhere in the compute layer will expose data inappropriately. The storage layer would become the authoritative source for what can be accessed and how.
Native to the Data Lakehouse Ecosystem
In order to maintain lakehouse capability, the embedded Delta Sharing would have to be validated against the Delta Sharing 1.0 specification using the public spec tests and client libraries. This validation is important, because it would mean that enterprises can operationalize the same table across multiple engines and environments. A financial analyst using Power BI, a data scientist using Databricks, and an engineering team using Spark can all access the same shared table through their preferred tools. The storage layer handles the sharing; each consumer uses what works best for them.
Compatibility is the foundation of the lakehouse ecosystem, and it would be important for any implementation of Delta Sharing to embody this principle.
Use Cases: Who Would Use Embedded Delta Sharing?
The pattern of keeping data on-premises while enabling cloud-based analytics would apply across many scenarios. Organizations could publish on-premises data products to Databricks workspaces without duplication, making curated datasets available to data science teams without copying terabytes to cloud storage. Business units could query live data from BI tools like Power BI and Tableau, working with current information rather than stale exports. Hybrid AI/ML workflows would benefit when training data, feature stores, or model artifacts live on-premises but need to be accessible from cloud-based notebooks. And for compliance-sensitive workloads like financial transactions or security telemetry, where data must remain on-premises for regulatory or operational reasons, Delta Sharing would provide read-only access that satisfies both governance requirements and the analytics team's need for modern tooling.
The Future is an API
We believe Delta Sharing should converge directly into object storage. The architectural benefits are clear: no separate sharing servers, no sidecar services, no custom integration code to maintain. On-premises data would become a first-class citizen in the data lakehouse, accessible to any tool that supports the Delta Sharing protocol.
For compliance-sensitive workloads like financial transactions and security telemetry, this approach would provide the access that analytics teams need while maintaining data integrity at the source. Data would stay where it must for regulatory or operational reasons, but it would participate fully in modern analytics workflows.
We think the object storage industry should adopt this approach, and we're eager to see it become a standard capability. Watch this space.






