Understanding the Difference Between Business Catalogs and Iceberg REST Catalogs

When people hear the word "catalog" in data conversations, confusion often follows. That's because two very different tools share the same name: business catalogs like Collibra and Atlan, and technical catalogs like the Iceberg REST Catalog. Understanding what each does, and where each belongs in your architecture, can save you from costly design mistakes.
What Business Catalogs Do
Business catalogs exist to help humans find, understand, and trust data across an organization. Think of them as a searchable directory that answers questions like: What data do we have? Who owns it? What does this column actually mean? Is this dataset approved for use in financial reporting?
Tools like Collibra and Atlan excel at this work. They store business definitions, track data lineage, manage governance policies, and connect data assets to the teams responsible for them. A business analyst might use a business catalog to discover which customer datasets exist, understand how "customer lifetime value" is calculated, and verify that a table has been certified for use in executive dashboards.
These catalogs span your entire data landscape. They might reference tables in a data warehouse, files in a data lake, reports in a BI tool, and datasets in third-party SaaS applications. Their value comes from providing a single place where anyone in the organization can search across all these systems.
What the Iceberg REST Catalog Does
The Iceberg REST Catalog serves a fundamentally different purpose. It tracks the physical state of Apache Iceberg tables so that query engines can read and write data correctly.
When you create an Iceberg table, the data files live in object storage like Amazon S3 or Google Cloud Storage. But a query engine needs to know more than just "the data is somewhere in this bucket." It needs to know the current table schema, which files contain active data (versus deleted records), how the table is partitioned, and what snapshots exist for time travel queries.
The Iceberg REST Catalog maintains this technical metadata. When Spark, Trino, or Flink queries an Iceberg table, they first consult the catalog to understand the table's current state, then go directly to object storage to read the relevant files.
Why the Distinction Matters
These catalogs operate at different levels of abstraction and serve different audiences.
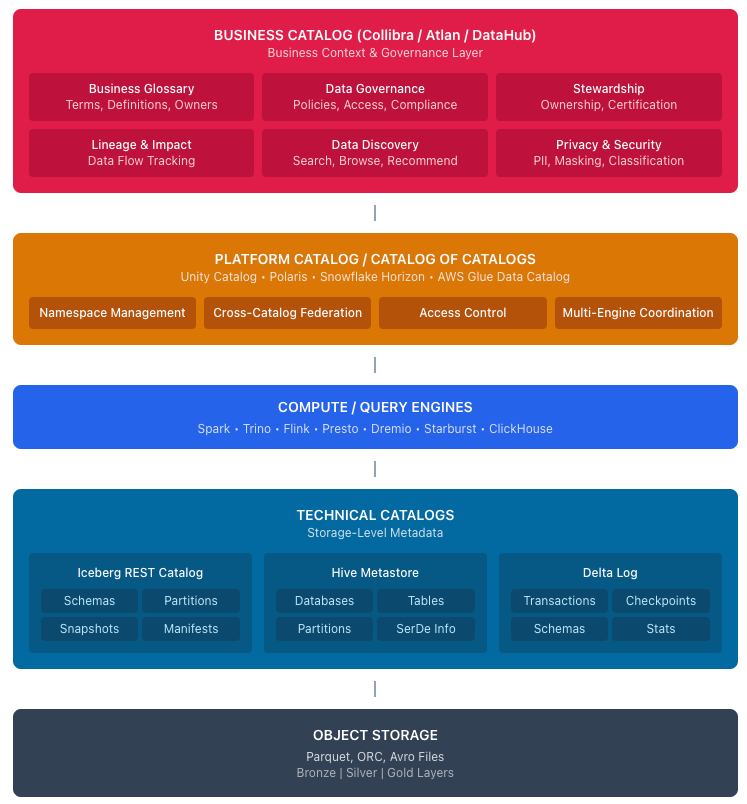
Business catalogs work at the organizational level. They help people navigate data by providing context that exists outside any single storage system. The definition of "active customer," the data steward responsible for sales data, and the policy governing PII access are all concepts that span multiple databases, warehouses, and lakes.
Iceberg REST Catalogs work at the storage level. They track the physical reality of files in object storage: which Parquet files make up a table, what schema version applies to each file, and how to resolve concurrent writes without corruption.
Why Embedding an Iceberg REST Catalog in Object Storage Makes Sense
Given this distinction, embedding an Iceberg REST Catalog directly into object storage is a natural architectural choice for several reasons.
First, the catalog and the data it describes already live in the same place. Iceberg tables are collections of data in object storage. The catalog metadata points to those files. Keeping them together eliminates network hops and reduces the operational complexity of managing a separate catalog service.
Second, the Iceberg REST Catalog has a narrow, well-defined scope. It manages tables within a specific storage environment. This bounded responsibility makes it a good fit for embedding, because the catalog's concerns align precisely with the storage system's boundaries.
Third, many organizations are moving toward cloud-native architectures where object storage serves as the foundation for analytics. Embedding the Iceberg REST Catalog into this layer lets storage become a more complete platform for data lakehouse workloads, without requiring teams to provision and maintain additional infrastructure.
Catalog of Catalogs: The Rise of Platform Catalogs
As organizations adopt lakehouse architectures, a middle layer has emerged between technical catalogs and business catalogs. Platform catalogs occupy this space, federating multiple technical catalogs into a unified view within their respective ecosystems.
Databricks Unity Catalog connects to external catalogs like AWS Glue and Hive Metastore through Lakehouse Federation. Apache Polaris provides an open-source Iceberg REST implementation with multi-catalog federation. Snowflake Horizon unifies governance across Snowflake's native and external Iceberg tables. AWS Glue Data Catalog serves as the central metadata repository for AWS analytics services.
These tools solve a real problem: data engineers no longer need to track which tables live in which underlying catalog. Platform catalogs provide unified views, consistent access controls, and lineage tracking across federated sources.
Yet platform catalogs remain bound to their ecosystems. None was designed to catalog assets in your CRM, index reports in your BI tool, or manage business definitions that span departments. They serve technical users who need to query data, not business users who need to understand what data means.
This is why organizations often run three layers of catalog:
Technical catalogs like Iceberg REST implementations handle physical bookkeeping for tables in object storage. They answer: what is the current state of this table?
Platform catalogs like Unity Catalog, Polaris, Snowflake Horizon, and AWS Glue federate technical catalogs and add governance controls. They answer: what tables can I access from this platform, and what are the rules?
Business catalogs like Collibra and Atlan sit at the organizational layer, spanning platforms. They answer: what data exists across our entire organization, what does it mean, and should I trust it?
Each layer serves a different audience at a different scope. Understanding where each belongs helps you design architectures that play to each tool's strengths.
Making the Layers Work Together
The word "catalog" appears throughout modern data architecture, but the tools behind that word serve fundamentally different purposes. Technical catalogs manage physical table state for query engines. Platform catalogs federate technical catalogs and enforce access policies within an ecosystem. Business catalogs provide organizational context that helps people find, understand, and trust data across all systems.
These layers complement rather than compete with each other. The key is understanding where each catalog belongs. Place technical catalogs close to storage, where their narrow scope aligns with system boundaries. Let platform catalogs federate within their ecosystem without expecting them to reach beyond it. Keep business catalogs at the organizational layer, where they can connect the dots across every platform and storage system in your data estate.
When you stop treating "catalog" as a single concept and start recognizing the distinct layers, the architecture decisions become clearer.






