DuckDB and MinIO for a Modern Data Stack

The modern data stack is a set of tools used for handling data in today's world, but its precise definition is a subject of debate. It's easier to describe what it isn't: it's not the vertical-scaling monolithic approach favored by big software companies of the past. Instead, the stack is made up of specific, high-quality tools that are each good at one particular aspect of working with data. The specificity and modularity of components is why the modern data stack often appears shape-shifting – solutions are always dropping in and out as technology and requirements change. Despite this constant change, the stack typically includes tools for integrating, transforming, visualizing and analyzing data.
In the past, data stack applications were engineered to gobble up data and lock it into their ecosystems, but those days are over and today’s data stack, regardless of its components, operates by manipulating data wherever it lives, granting control and access back to the users. Modern data stack applications must be capable of working with data everywhere, whether that be in the public clouds, private clouds, bare-metal infrastructure or edge computing environments. Isolated data silos invented by software companies hoping for retention is a thing of the past.
In this model, there is a place for DuckDB, an analytics engine disguised as an open source OLAP database. DuckDB offers analysts, engineers and data scientists the chance to extract meaningful insights swiftly without the need for lengthy or complicated extract and loading steps. They can do enterprise grade analytics and data exploration on their data without it ever moving.
MinIO and DuckDB
Increasingly, enterprises use MinIO as primary storage for databases like DuckDB. Several synergies make them an ideal combination for the modern data stack:
- Performance: In data-intensive workloads, top-tier performance is non-negotiable. MinIO sets the bar as the fastest object storage solution available, ensuring that data access and retrieval are lightning-fast. When integrated with DuckDB, this performance boost enhances the efficiency of data analytics and processing.
- Scale: MinIO's scalability through Server Pools is the perfect match for DuckDB's growth capabilities. As data requirements expand, MinIO's ability to seamlessly scale ensures that storage infrastructure can effortlessly accommodate these evolving needs.
- Designed for OLAP Workloads: DuckDB is purpose-built for Online Analytical Processing (OLAP) workloads, making it an ideal choice for analytical tasks. When coupled with MinIO's storage capabilities, it forms a robust foundation for managing and analyzing large datasets efficiently.
- Simplicity: Both MinIO and DuckDB adhere to the principle of simplicity. DuckDB, with its feather light, no-dependency, single-file build, is easy to set up. MinIO's straightforward software-first design complements this simplicity.
- Control: Leveraging DuckDB to query over your data in MinIO without moving it, means you can keep complete control over it. Data never leaves the safety of your IAM-secured and encrypted MinIO storage and never gets siloed in proprietary infrastructure.
- Flexibility: You can deploy DuckDB anywhere there is a working C++11 compiler. MinIO can be deployed to public clouds, private clouds, bare-metal infrastructure or edge computing environments. With these tools in your stack, you’re never locked into an environment.
- Modern: The modern data stack is cloud-native. MinIO was born in the cloud and designed to run on baremetal and Kubernetes from its inception. Your data is everywhere – shouldn’t your analytics engine be too?
DuckDB Overview
What sets DuckDB apart is its exceptional speed and versatility, enabling users to swiftly process and analyze large datasets. This speed is the result of DuckDB’s columnar-vectorized query execution engine. Vectorized processing is a significant departure from the query processing models of the past, and the result of this change has been significantly enhanced query performance.
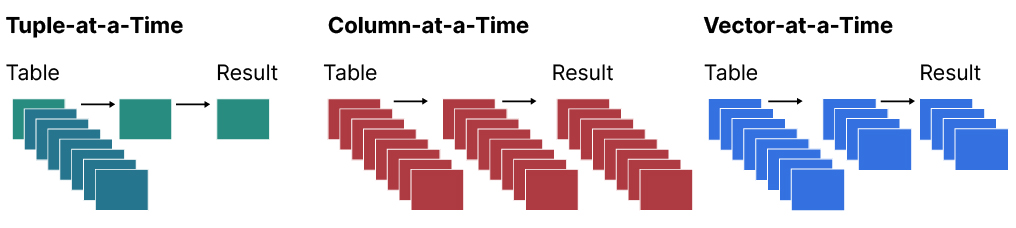
Overview of query processing models:
- Tuple-at-a-time: Used by databases like PostgreSQL, Oracle and MySQL. Tuple-at-a-time processing means one row of data at a time.
- Column-at-a-time: Used by Pandas this model is faster than tuple-at-at-time processing, but becomes a problem when the data is larger than memory.
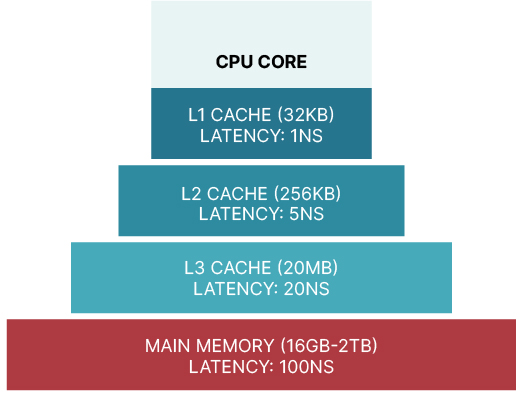
- Vector-at-a-time: Used by DuckDB, this approach finds a middle ground between the two other models. Queries are processed in batches of data consisting of collections of vectors which each contain a fixed amount of values from the columns. This model delays the materialization of values from multiple columns into tuples (or rows) until the very end of the query plan. The result is an efficient use of in-cache operations, by keeping the data in queries as much as possible in the very fast L1 and L2 Cache (see image below).
DuckDB’s versatility comes in the form of features. For a database built for speed, it also offers surprisingly comprehensive support for complex queries and functions. It has speed, but also depth.
Limitations
When you head to the racetrack, you bring a high performance car. You don't take your family-friendly, but very versatile SUV. While we may not usually think of ducks as high-performance, that is exactly what DuckDB is for - fast queries on large data sets. It is the racecar of databases - you can't fit anything in it, it seats two, your golf clubs might not even fit in the back, but it is perfect for the racetrack. The features it lacks don’t detract from its strengths. This minimalism is a central design principle in the containerized world of the modern data stack.
However, it's essential to know DuckDB's limits. DuckDB isn't designed for transactional workloads, which makes it inappropriate for high-concurrency write scenarios. DuckDB offers two concurrency options: one process can both read and write to the database, or multiple processes can read-only simultaneously.
Another aspect to consider is the absence of user management features, rendering DuckDB more suited for individuals rather than collaborative team environments, which may require user access controls and permissions.
Despite these limitations, DuckDB shines in analytical tasks, provided they align with its strengths and intended use.
MotherDuck: Taking DuckDB to New Heights
MotherDuck is a managed service for DuckDB that can productionalize DuckDB for you. It takes DuckDB beyond its single-machine installation and into the cloud, essentially transforming it into a multiplayer experience. By utilizing MotherDuck, you can further scale DuckDB without relinquishing control over your data. That being said, there is no reason not to think about DuckDB from a production lens. MotherDuck is built upon DuckDB's production ready core strengths of speed and efficient data processing. Importantly, everything described here should also seamlessly apply when working with MotherDuck.
Installing DuckDB
Installation instructions can be found in DuckDB’s documentation. Others have documented how to containerize DuckDB, some have bundled it together with helpful tools like dbt and Python. Whether or not you use these extensions depends on your SLA and preferences. These images and others are on Docker Hub.
For a local deployment, perhaps for the purposes of this tutorial or for development and testing, download the binary for your operating system. MacOS users can use Homebrew package manager to add the DuckDB CLI to your PATH.
However you install, launch DuckDB by calling the duckdb CLI command.
$ duckdb
v0.8.1 6536a77232
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.Install the httpfs extension, which will allow you to read data from MinIO.
INSTALL httpfs;
LOAD httpfs;Installing MinIO
For the purpose of this tutorial, I’m deploying a Single-Node Single-Drive MinIO Server using Docker. Single-Node Single-Drive is appropriate for early development, evaluation, or learning and teaching like in this tutorial. Instructions for deploying in this way can be found here and here.
To start a rootless Docker container, run the following. It’s always a best practice to change the password.
mkdir -p ${HOME}/minio/data
docker run \
-p 9000:9000 \
-p 9090:9090 \
--user $(id -u):$(id -g) \
--name minio1 \
-e "MINIO_ROOT_USER=ROOTUSER" \
-e "MINIO_ROOT_PASSWORD=CHANGEME123" \
-v ${HOME}/minio/data:/data \
quay.io/minio/minio server /data --console-address ":9090"To set up MinIO for production, refer to the Deploy MinIO: Multi-Node Multi-Drive guide. When you navigate to the MinIO Console, you’ll be prompted to create a bucket.
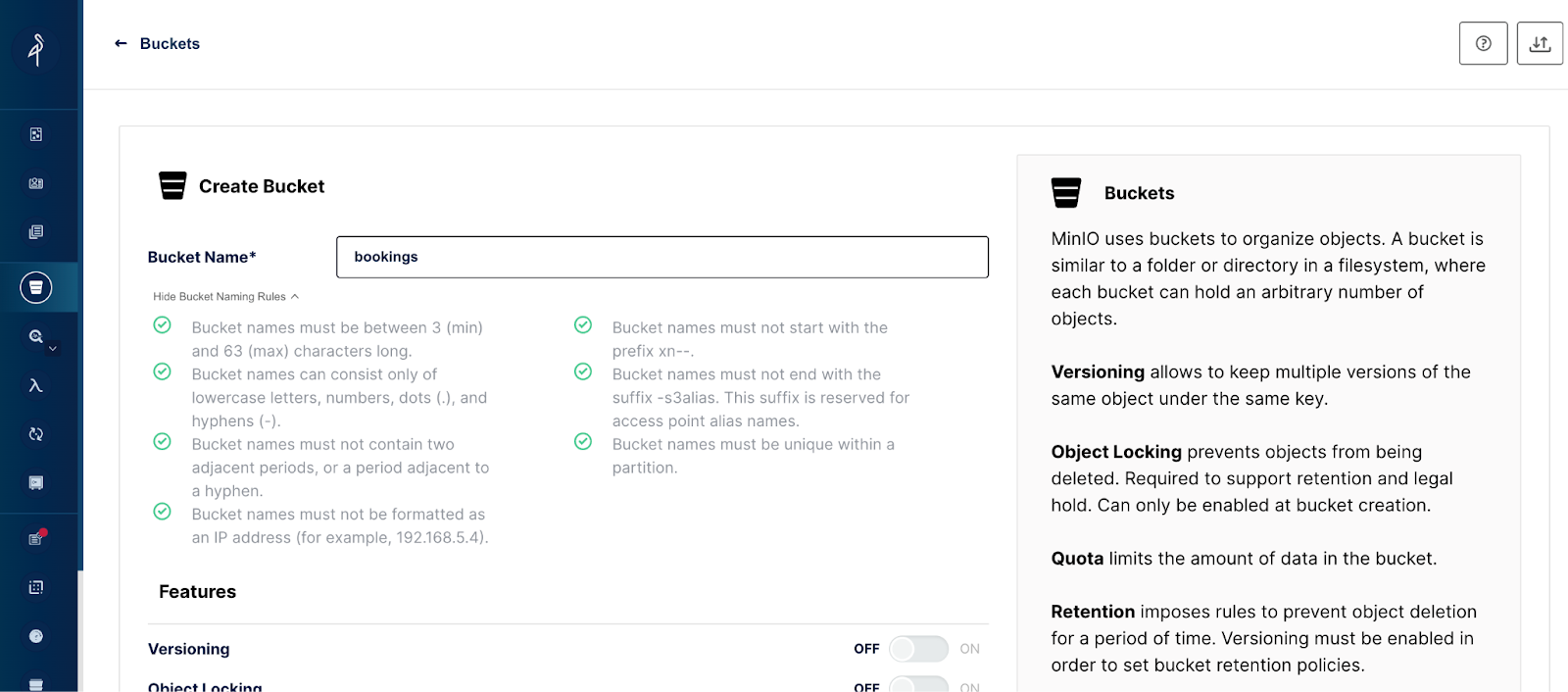
Create a memorable and descriptive bucket name for your tutorial. I’m naming mine: bookings. Check out the bucket naming rules included in the tooltip in the image below.
Dataset
The dataset for this tutorial is booking information for two hotels. Download the dataset and then load the file into MinIO. You can use the MinIO Console or the MinIO Client, mc.
Putting It All Together
In the command line window where you launched DuckDB, you can use the DuckDB CLI to interact with the database. Use your MinIO username and password as your S3 Access Key and S3 Secret Key. If anyone could possibly reach your machine to attack it, you should change these values. MinIO ignores region, but you can set the region to ‘us-east-1’ when a value is needed, as in this case. Remove the ‘http’ from your endpoint and remember that your port number should be the port number for the MinIO S3-API, not the console. Very critically, make sure that your s3_url_style is set to ‘path’.
INSTALL httpfs;
LOAD httpfs;
SET s3_region='us-east-1';
SET s3_url_style='path';
SET s3_endpoint='play.min.io:9000';
SET s3_access_key_id='***' ;
SET s3_secret_access_key='***';With these settings, you’re ready to begin querying your data. First make a table with the bookings data. Here’s another great DuckDB feature, in order to create a table, you don’t need to spend time defining your schema.
CREATE TABLE bookings AS SELECT * FROM read_csv_auto('s3://bookings/hotel_bookings.csv', all_varchar=1);Start by querying over the data in MinIO to get a sense of its size and structure.
SELECT COUNT(*) AS TotalRows from bookings;
┌───────────┐
│ TotalRows │
│ int64 │
├───────────┤
│ 119390 │
└───────────┘SELECT column_name FROM information_schema.columns WHERE table_name = 'bookings';
┌────────────────────────────────┐
│ column_name │
│ varchar │
├────────────────────────────────┤
│ hotel │
│ is_canceled │
│ lead_time │
│ arrival_date_year │
│ arrival_date_month │
│ arrival_date_week_number │
│ arrival_date_day_of_month │
│ stays_in_weekend_nights │
│ stays_in_week_nights │
│ adults │
│ children │
│ babies │
│ meal │
│ country │
│ market_segment │
│ distribution_channel │
│ is_repeated_guest │
│ previous_cancellations │
│ previous_bookings_not_canceled │
│ reserved_room_type │
│ assigned_room_type │
│ booking_changes │
│ deposit_type │
│ agent │
│ company │
│ days_in_waiting_list │
│ customer_type │
│ adr │
│ required_car_parking_spaces │
│ total_of_special_requests │
│ reservation_status │
│ reservation_status_date │
├────────────────────────────────┤
│ 32 rows │
└────────────────────────────────SELECT DISTINCT(market_segment) FROM bookings;
┌────────────────┐
│ market_segment │
│ varchar │
├────────────────┤
│ Direct │
│ Corporate │
│ Online TA │
│ Offline TA/TO │
│ Complementary │
│ Groups │
│ Undefined │
│ Aviation │
└────────────────┘Expand and Operationalize Your Analysis with Python
Official DuckDB API wrappers include C, Python, R, Java, Node.js, WebAssembly/Wasm, ODBC API, Julia and the CLI, which we already explored.
This quick Python script will get you started on building some key data exploration metrics outside the CLI. I’ve switched file format to Parquet to show off more key DuckDB capabilities.
You can find this script here - in our Github repository.
The data in my parquet file looks like this:

Here is the output from the script:
Number of rows in data: 4
Number of nulls in 'Insect': 0
Number of nulls in 'Order_of_Insects': 0
Number of nulls in 'Habitat': 0
Number of nulls in 'Predatory': 0
Number of nulls in 'Units': 0
Summary statistics for 'Units':
Min: 1
Max: 9
Average: 4.5
Standard Deviation: 3.415650255319866
Don't Be a Sitting Duck
This blog post showed you how to configure DuckDB to read data from MinIO and then run some exploratory queries. DuckDB is a great little tool for quick data analysis. There’s a lot more that you can do with DuckDB and MinIO. For example, DuckDB could be used along with Object Lambda to automatically execute SQL queries against data in MinIO. For example, the execution of a cleaning script could be set to the event notification of new, raw data entering a MinIO bucket. The sky's the limit for the enterprise integrations possible between MinIO and DuckDB.
As you dip your webbed feet into DuckDB and MinIO, feel free to connect with us on our Slack channel. We'd love to hear about your experiences, and if you have any questions, don't hesitate to reach out.






