Erasure Coding 101

Erasure coding is a key data protection method for distributed storage systems. This blog post explains how erasure coding satisfies enterprise requirements for data protection and how it is implemented in MinIO.
Data Protection and Hardware Failure
Data protection is essential in any enterprise environment because hardware failure, specifically drive failure, is common.
Traditionally, different types of RAID technologies or mirroring/replication were used to provide hardware fault tolerance. Mirroring and replication rely on one or more complete redundant copies of data - this is a costly way to consume storage. More complex technologies such as RAID5 and RAID6 provide the same fault tolerance while reducing storage overhead. RAID is a good solution for data protection on a single node, but fails to scale due to time consuming rebuild operations required to bring failed drives back online.
Many distributed systems use 3-way replication for data protection, where the original data is written in full to 3 different drives and any one drive is able to repair or read the original data. Not only is replication inefficient in terms of storage utilization, it is also operationally inefficient when it recovers from failure. When a drive fails, the system will place itself in read-only mode at reduced performance while it fully copies an intact drive onto a new drive to replace the failed drive.
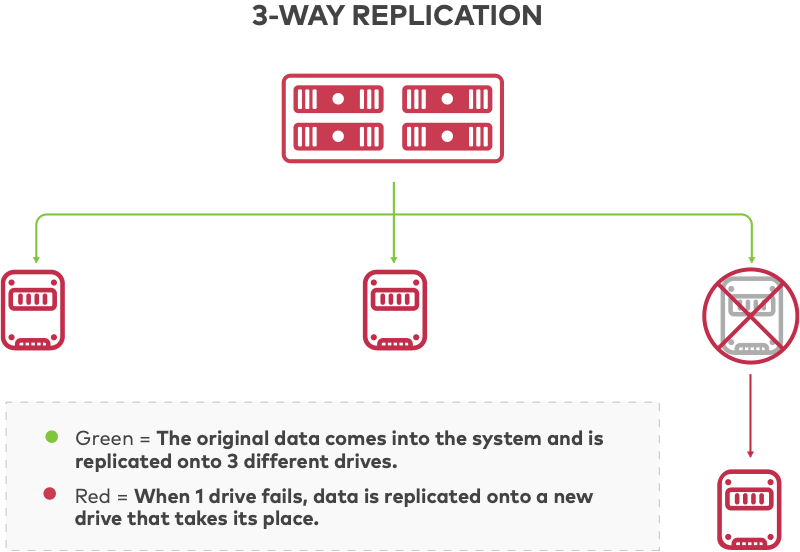
Related: Object Storage Erasure Coding vs. Block Storage RAID
Why Erasure Coding Is Important for Data Protection
Erasure coding is applied to data protection for distributed storage because it is resilient and efficient. It splits data files into data and parity blocks and encodes it so that the primary data is recoverable even if part of the encoded data is not available. Horizontally scalable distributed storage systems rely on erasure coding to provide data protection by saving encoded data across multiple drives and nodes. If a drive or node fails or data becomes corrupted, the original data can be reconstructed from the blocks saved on other drives and nodes.
Erasure coding is able to tolerate the same number of drive failures as other technologies with much better efficiency by striping data across nodes and drives. There are many different erasure coding algorithms, and Maximum Distance Separable (MDS) codes such as Reed-Solomon achieve the greatest storage efficiency.
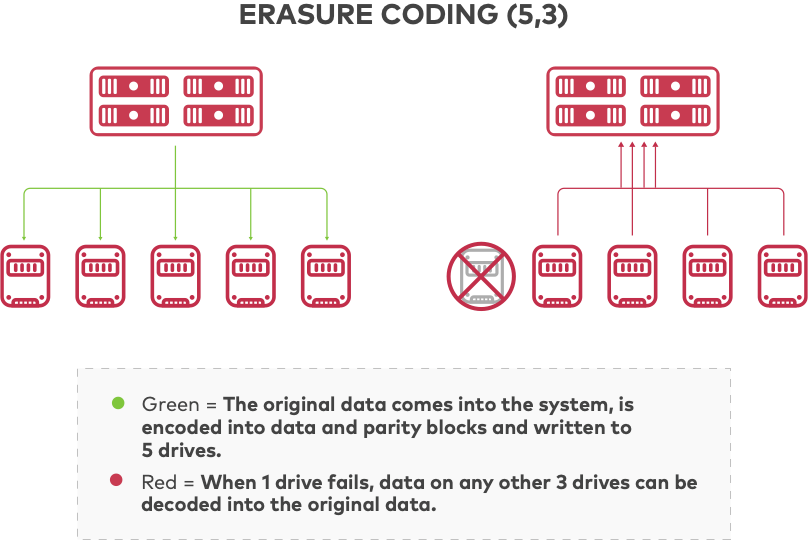
In object storage, the unit of data to be protected is an object. An object can be stored onto n drives. If k indicates potential failure, then k < n, and with MDS codes the system can guarantee to tolerate n - k drive failures, meaning that k drives are sufficient to access any object.
Considering an object that is M bytes in size, the size of each coded object is M / k (ignoring the size of metadata). Compared to the N-way replication shown above, with erasure coding configured for n = 5 and k = 3, a distributed storage system could tolerate the loss of 2 drives, while improving storage efficiency by 80%. For example, for 10 PB of data replication would require more than 30 PB of storage, whereas object storage would require 15-20 PB to securely store and protect the same data using erasure coding. Erasure coding can be configured for different ratios of data to parity blocks, resulting in a range of storage efficiency. MinIO maintains a helpful erasure code calculator to help determine requirements in your environment.
Overview of MinIO Erasure Coding
MinIO protects data with per-object, inline erasure coding (official MinIO documentation for reference) which is written in assembly code to deliver the highest performance possible. MinIO makes use of Intel AVX512 instructions to fully leverage host CPU resources across multiple nodes for fast erasure coding. A standard CPU, fast NVMe drives and a 100 Gbps network support writing erasure coded objects at near wire speed.
MinIO uses Reed-Solomon code to stripe objects into data and parity blocks that can be configured to any desired redundancy level. This means that in a 16 drive setup with 8 parity configuration, an object is striped across as 8 data and 8 parity blocks. Even if you lose as many as 7 ((n/2)–1) drives, be it parity or data, you can still reconstruct the data reliably from the remaining drives. MinIO’s implementation ensures that objects can be read or new objects written even if multiple devices are lost or unavailable.
MinIO splits objects into data and parity blocks based on the size of the erasure set, then randomly and uniformly distributes the data and parity blocks across the drives in a set such that each drive contains no more than one block per object. While a drive may contain both data and parity blocks for multiple objects, a single object has no more than one block per drive, as long as there is a sufficient number of drives in the system. For versioned objects, MinIO selects the same drives for data and parity storage while maintaining zero overlap on any one drive.
The table below provides examples of erasure coding in MinIO with configurable data and parity options and accompanying storage usage ratios.
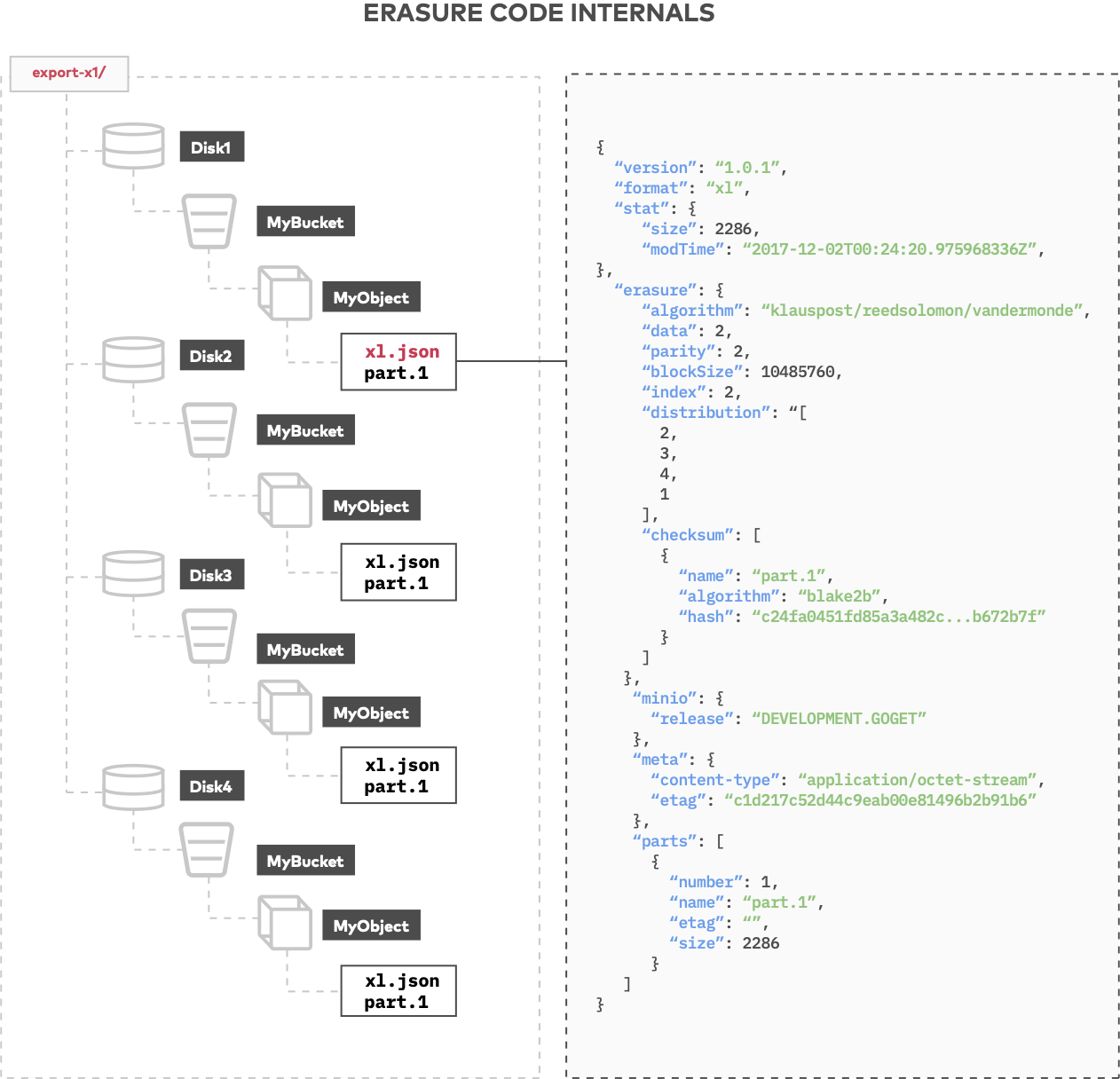
The back end layout of MinIO is actually quite simple. Every object that comes in is assigned an erasure set. An erasure set is basically a set of drives, and a cluster consists of one or more erasure sets, determined by the amount of total disks.
Let’s take a look at a simple example to understand the format and the layout used in MinIO.
It’s important to note that the format is about the ratio of data to parity drives - whether we have four nodes with a single drive each or four nodes with 100 drives each (MinIO is frequently deployed in dense JBOD configurations).
We can configure our four nodes with 100 drives each to use an erasure set size of 16, the default. This is the logical layout, and it is part of the definitions of the erasure coding calculations. Every 16 drives is one erasure set made up of 8 data and 8 parity drives. In this case, the erasure set is based on 400 physical drives, divided equally into data and parity drives, and can tolerate the loss of up to 175 drives.

MinIO’s XL metadata, written atomically with the object, contains all the information related to that object. There is no other metadata within MinIO. The implications are dramatic - everything is self-contained with the object, keeping it all simple and self-describing. XL metadata indicates the erasure code algorithm, for example two data with two parity, the block size, and the checksum. Having the checksum written along with the data itself allows MinIO to be memory optimized while supporting streaming data, providing a clear advantage over systems that hold streaming data in memory, then write it to disk and finally generate a CRC-32 checksum.
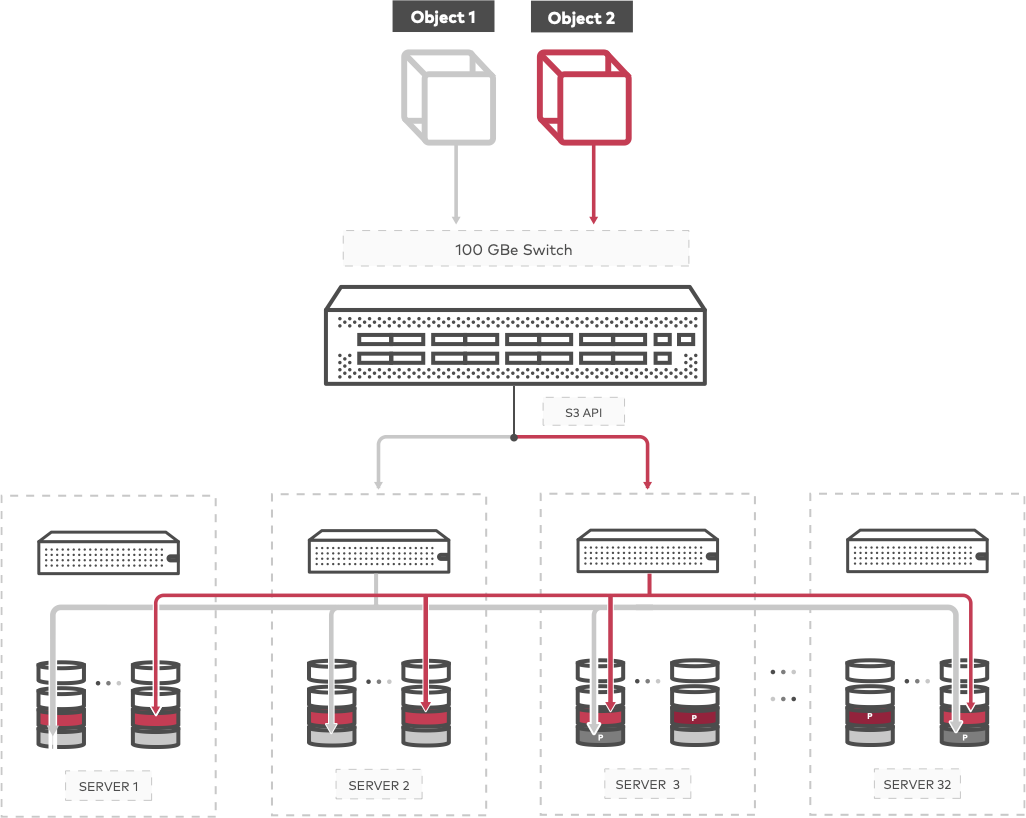
When a large object, ie. greater than 10 MB, is written to MinIO, the S3 API breaks it into a multipart upload. Part sizes are determined by the client when it uploads. S3 requires each part to be at least 5 MB (except the last part) and no more than 5 GB. An object can have up to 10,000 parts based on the S3 specification. Imagine an object that is 320 MB. If this object is broken into 64 parts, MinIO will write the parts to the drives as part.1, part.2,...up to part.64. The parts are of roughly equal size, for example, the 320 MB object uploaded as multipart would be split into 64 5 MB parts.
Each part that was uploaded is erasure coded across the stripe. Part.1 is the first part of the object that was uploaded and all of the parts are horizontally striped across the drives. Each part is made up of its data blocks, parity blocks and XL metadata. MinIO rotates writes so the system won’t always write data to the same drives and parity to the same drives. Every object is independently rotated, allowing uniform and efficient use of all drives in the cluster, while also increasing data protection.
To retrieve an object, MinIO performs a hash calculation to determine where the object was saved, reads the hash and accesses the required erasure set and drives. When the object is read, there are data and parity blocks as described in XL metadata. The default erasure set in MinIO is 12 data and 4 parity, meaning that as long as MinIO can read any 12 drives the object can be served.
Benefits of Erasure Coding and MinIO’s Implementation
Erasure coding has several key advantages over other technologies used for data protection in distributed systems.
There are several reasons why erasure coding is better suited for object storage than RAID. Not only does MinIO erasure coding protect objects against data loss in the event that multiple drives and nodes fail, MinIO also protects and heals at the object level. The ability to heal one object at a time is a dramatic advantage over RAID that heals at the volume level. A corrupt object could be restored in MinIO in seconds vs. hours in RAID. If a drive goes bad and is replaced, MinIO recognizes the new drive, adds it to the erasure set, and then verifies objects across all drives. More importantly, reads and writes don’t affect one another, enabling performance at scale. There are MinIO deployments out there with hundreds of billions of objects across petabytes of storage.
The erasure code implementation in MinIO results in improved operational efficiency in the datacenter. Unlike replication, there is no lengthy rebuilding or re-synchronizing data across drives and nodes. It may sound trivial, but moving/copying objects can be very expensive, and a 16TB drive failing and being copied across the datacenter network to another drive places a huge tax on the storage system and network.
If this blog post piqued your curiosity, we have a longer Erasure Coding Primer available. Download MinIO and start protecting data with erasure coding today.






