Object Storage Erasure Coding vs. Block Storage RAID

Regardless of what and where it is, valuable data must be safeguarded against loss and corruption. Protecting greater and greater volumes of data is no easy task for enterprise storage admins. Data protection isn’t a check box - there are important differences between protection technologies and how they are implemented. It’s critical to understand how the differences affect your data and the systems that work with it.
This blog post compares two data protection technologies, block-level RAID and object storage erasure coding, that share some similarities but are in fact very different. For the purposes of this discussion, I use RAID to mean the standard block-level implementations by controller hardware or software or by OS drivers, not ZFS or some proprietary SAN solution. Similarly, by erasure coding I mean MinIO erasure coding that stripes data and parity across drives and nodes.
RAID (redundant array of independent disks) is a widely implemented technology for protecting data on a block level against corruption and loss. The goal is to improve performance and protect data while virtually combining drives to increase capacity. Performance improvements come from placing data on multiple disks and then running I/O operations in parallel. Data protection results from storing data redundantly across multiple disks so one or more can fail without data loss. There are many different RAID levels but they all mirror or stripe data and sometimes parity across multiple drives on a single server or storage array. RAID typically protects block level storage and is implemented on a controller between a storage array and a file system. RAID controllers, which can be hardware or software, manage the details and expose the multiple physical disks in an array as a single drive to the operating system.
It’s helpful to think of RAID levels along a continuum of performance vs. capacity. RAID 0 simply involves striping data across disks allowing the use of 100% of capacity. RAID 1 mirrors data between 2 or more disks to optimize for read performance while dramatically decreasing capacity. RAID 5 stripes data blocks and distributes parity across drives to be able to recover from failure. RAID 6 stripes data blocks and distributes double parity across drives in order to be able to provide fault tolerance for two failed drives. RAID 10 (or RAID 1+0) creates a striped set of mirrored drives.
Although commonly implemented, RAID suffers from several shortcomings that become significant sources of pain in large-scale object storage implementations. One I have personally suffered through is lengthy rebuilding periods. In a configuration such as RAID 6, when a drive fails, it is physically taken out of service, replaced with a new one and the RAID controller rebuilds the existing block-level data onto the new drive. At 10+ TB, today’s drives have much greater capacity than when RAID was introduced in 1987 and they can take hours or even days to be rebuilt. All of the drives in an array are at risk until the failed drive is replaced because of the decrease in redundancy. Rebuilding a drive is I/O intensive for the RAID controller and all of the drives in an array, resulting in a decrease in available performance and an increased risk of hardware failure for the drives still in service. This can lead to severe complications like new drive failures or new silent data corruption that occurs while attempting to rebuild a RAID array. It’s not a good feeling to sit in front of a console watching drives fail while listening to users complain about downtime.
RAID is a block-layer technology that was designed for a single-server environment. We don’t live in a single-server or a single appliance or even a cascading appliance object storage world. We run distributed object storage to grow capacity in a high-performance and fully protected way. RAID has no context of objects. RAID can’t heal objects saved on drives distributed across multiple nodes - in fact, it doesn’t heal objects at all, it heals blocks so you’ll have to heal an entire drive if an object gets corrupted.
Storage admins typically configure RAID controllers to scan drives looking for corrupt blocks at regular intervals, perhaps every two weeks or monthly. Performance is decreased across the entire array during this scan. There are other performance degradations that are caused by RAID architecture. Even though there are many disks in an array, this improves performance of a single read stream but concurrent reads result in poor random I/O performance. How could they when the OS thinks it’s reading from and writing to a single drive. A JBOD is capable of independent reads and writes, not RAID.
RAID was simply not built for large scale object storage deployments.
The Better Path: MinIO Erasure Coding
MinIO implements erasure coding on an object level in a distributed fashion and can reconstruct objects in the event of hardware failure without sacrificing performance or incurring downtime. Erasure coding is better suited for object storage than RAID because objects are immutable blobs that get written once and read many times. MinIO makes use of Intel AVX512 instructions to fully leverage host CPU resources across multiple nodes for fast erasure coding. A standard CPU, fast NVMe drives and a 100 Gbps network supports writing erasure coded objects at near wire speed.
Like RAID 5 (parity 1) and RAID 6 (parity 2), MinIO relies on erasure coding (configurable parity between 2 and 8) to protect data from loss and corruption. Erasure coding breaks objects into data and parity blocks, where parity blocks support reconstruction of missing or corrupted data blocks. MinIO distributes both data and parity blocks across nodes and drives in an erasure set. With MinIO’s highest level of protection (8 parity or EC:8), you may lose up to half of the total drives and still recover data. MinIO combines multiple erasure sets into a single namespace in order to increase capacity and maintain isolation.
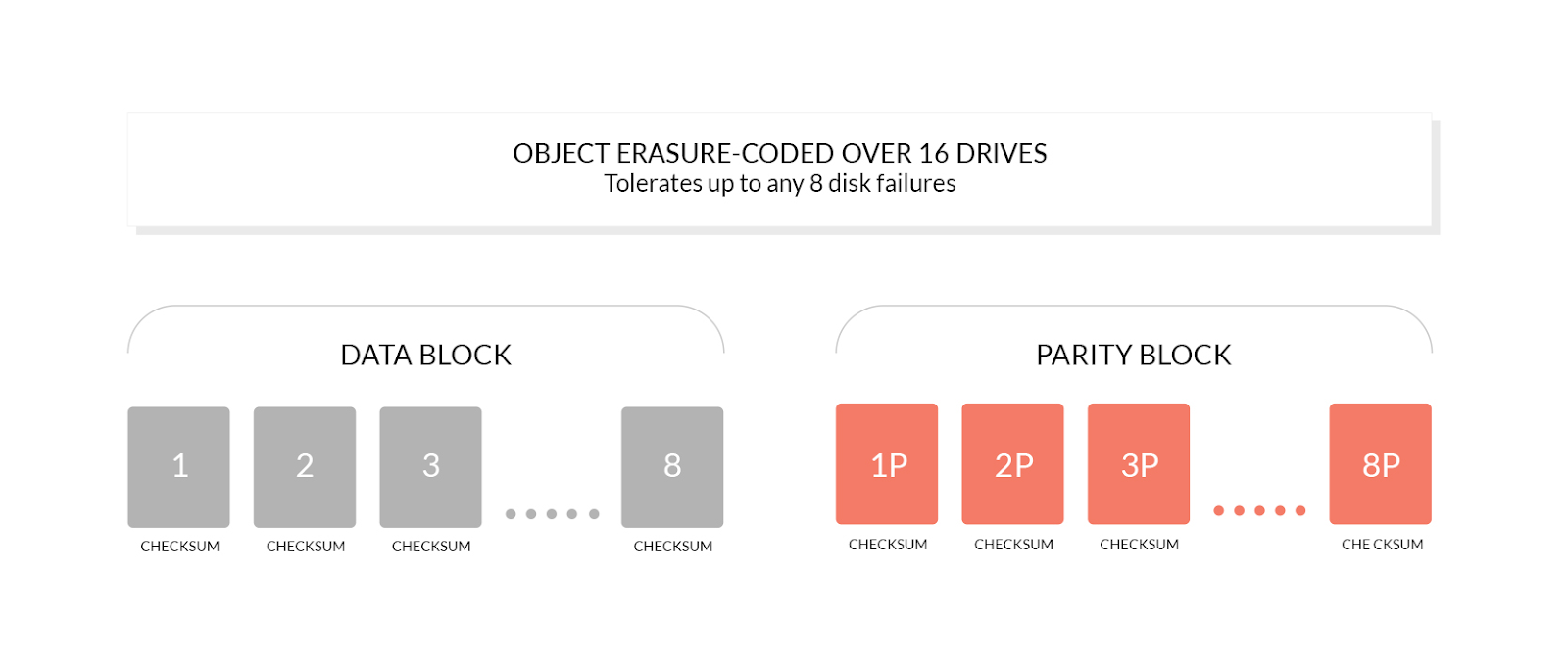
MinIO uses a Reed-Solomon algorithm to split objects into data and parity blocks based on the size of the erasure set, then randomly and uniformly distributes the data and parity blocks across the drives in a set such that each drive contains no more than one block per object. While a drive may contain both data and parity blocks for multiple objects, a single object has no more than one block per drive, as long as there is a sufficient number of drives in the system. For versioned objects, MinIO selects the same drives for data and parity storage while maintaining zero overlap on any one drive.
We use the EC:N notation to refer to the number of parity blocks (N) in an erasure set. The number of parity blocks controls the degree of data redundancy. Higher levels of parity allow for greater fault tolerance at the cost of total available storage. While you can control the EC stripe size, the default for 16 drives is EC:4 which results in 12 data blocks and 4 parity blocks per object. If you have large numbers of small objects (think KB), then a smaller stripe size can provide better performance. We chose the default stripe size to balance protection and performance. Parity blocks occupy storage in the deployment, reducing the amount of storage available for data blocks, but it’s worth it because they can reconstruct the object if a data block is lost or corrupted, decreasing the likelihood of losing an object.

Not only does MinIO erasure coding protect objects against data loss in the event that multiple drives and nodes fail, MinIO also protects and heals at the object level. The ability to heal one object at a time is a dramatic advantage over systems such as RAID that heal at the volume level. A corrupt object could be restored in MinIO in seconds vs. hours in RAID. If a drive goes bad and is replaced, MinIO recognizes the new drive, adds it to the erasure set, and then verifies objects across all drives. More importantly, reads and writes don’t affect one another to enable performance at scale. There are MinIO deployments out there with hundreds of billions of objects across petabytes of storage.
MinIO protects against BitRot, or silent data corruption, which can have many different causes such as power current spikes, bugs in disk firmware and even simply aging drives. MinIO uses the HighwayHash algorithm to compute a hash on read and verify it on write from the application, across the network and to the storage media. This process is highly efficient - it can achieve hashing speeds over 10 GB/sec on a single core on Intel CPUs - and has minimal impact on normal read/write operations across the erasure set.
Learn More About MinIO Erasure Coding
The easiest way to learn more about MinIO erasure coding is to play around with our erasure code calculator. You can enter different values for the number of servers, number of drives per server and drive capacity as well as erasure code stripe size and erasure code parity to determine usable capacity and failure tolerance.






