From Tables to Relationships: Visualizing Iceberg Data as a Graph

Relationships matter, especially when you’re working with complex, interconnected data in a data lakehouse. PuppyGraph is a high-performance graph compute engine that lets you query structured data as a graph, making it easy to uncover relationships and patterns without moving your data into a separate graph database. When combined with Apache Iceberg, Project Nessie for table management, and MinIO AIStor for object storage, you get a fully integrated, cloud-native stack for secure, versioned, graph-based analytics. All this functionality and the whole stack can be containerized and deployed anywhere: on-prem, in the public clouds, in colos or in data centers.
This tutorial walks you through getting started with setting up an Iceberg data lakehouse using PuppyGraph to query and visualize your data in MinIO as a graph.
What is a Graph Database?
A graph database models data as nodes and edges rather than rows and tables. This structure makes it ideal for querying relationships. Those relationships could be its customer behavior, fraud detection, supply chain optimization, or even social behavior graphs. Graph databases come in two major flavors: RDF (Resource Description Framework) and property graphs. RDF is schema-driven and primarily used in semantic web contexts. Property graphs, on the other hand, are more flexible and intuitive, supporting arbitrary attributes on both nodes and edges.
PuppyGraph is a property graph engine. It supports Gremlin and Cypher query languages, integrates directly with tabular data sources like Iceberg, and avoids the heavyweight infrastructure typical of traditional graph databases.
Graphs without Migration
Traditionally, leveraging compute required moving data. The past was burdened by tightly coupled compute and storage which meant that if you wanted to actually do anything with your data, it had to be ingested into this or that proprietary platform. Locked in with very little chance of escape.
Modern compute, like PuppyGraph allows your to query over your data in object storage without migration. Creating a centralized source of truth, but not locking you in to this or that engine. This pattern reduces complexity, preserves data integrity and keeps the architecture future forward.
AIStor and Graphs
MinIO AIStor provides the object storage foundation for this architecture. It delivers high-throughput performance on standard hardware, which makes it a strong fit for data-intensive workloads such as graph analytics. AIStor supports both S3 Select and S3 Express APIs. In recent benchmarks, the AIStor S3 Express API delivered more than twice the throughput for standard operations, enabling fast reads directly from storage, particularly for large objects.
Using AIStor for graph infrastructure allows teams to store structured and unstructured data in the same scalable, versioned object store that supports the rest of the data lakehouse. This avoids unnecessary data movement and reduces system complexity. Everything is accessible through a single, consistent Global Console.
AIStor is built for Kubernetes. It can be deployed with standard infrastructure-as-code workflows and scales predictably across cloud, on-prem, and edge environments. This consistency is essential for organizations that require reproducibility, automation, and operational control. The below tutorial is a proof of concept of that deployability, creating an entire graph analytics infrastructure from scratch within a single Docker container that takes seconds to spin up.
Prerequisites
To get started with the tutorial, you will need Docker. You can download Docker from here.
Please ensure that docker compose is available. The installation can be verified by running: docker compose version
Getting Started
Create a docker-compose.yaml and paste in the following:
services:
spark-iceberg:
image: tabulario/spark-iceberg
container_name: spark-iceberg
networks:
iceberg_net:
depends_on:
- minio
- nessie
volumes:
- ./warehouse:/home/iceberg/warehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
minio:
image: quay.io/minio/minio
container_name: minio
networks:
iceberg_net:
ports:
- 9000:9000
- 9001:9001
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_REGION=us-east-1
entrypoint: >
/bin/sh -c "
minio server /data --console-address ':9001' &
sleep 5;
mc alias set myminio http://localhost:9000 admin password;
mc mb myminio/my-bucket --ignore-existing;
tail -f /dev/null"
nessie:
image: ghcr.io/projectnessie/nessie:0.104.1
container_name: nessie
networks:
iceberg_net:
ports:
- 19120:19120
environment:
- nessie.version.store.type=IN_MEMORY
- nessie.catalog.default-warehouse=warehouse
- nessie.catalog.warehouses.warehouse.location=s3://my-bucket
- nessie.catalog.service.s3.default-options.region=us-east-1
- nessie.catalog.service.s3.default-options.endpoint=http://minio:9000/
- nessie.catalog.service.s3.default-options.path-style-access=true
- nessie.catalog.service.s3.default-options.access-key=urn:nessie-secret:quarkus:nessie.catalog.secrets.access-key
- nessie.catalog.secrets.access-key.name=admin
- nessie.catalog.secrets.access-key.secret=password
- nessie.server.authentication.enabled=false
puppygraph:
image: puppygraph/puppygraph:stable
container_name: puppygraph
networks:
iceberg_net:
environment:
- PUPPYGRAPH_USERNAME=puppygraph
- PUPPYGRAPH_PASSWORD=puppygraph123
ports:
- "8081:8081"
- "8182:8182"
- "7687:7687"
depends_on:
- spark-iceberg
networks:
iceberg_net:To start up the services, run the command: docker compose up -d.
If successful, you should get a message that looks like this:
[+] Running 5/5
✔ Network puppygraph-spark_iceberg_net Created 0.0s
✔ Container nessie Started 0.6s
✔ Container minio Started 0.6s
✔ Container spark-iceberg Star... 0.4s
✔ Container puppygraph Started 0.5sNavigate to http://localhost:9001 to log in to MinIO with the username and password of admin:password to see that a bucket called my-bucket has been automatically created for you.
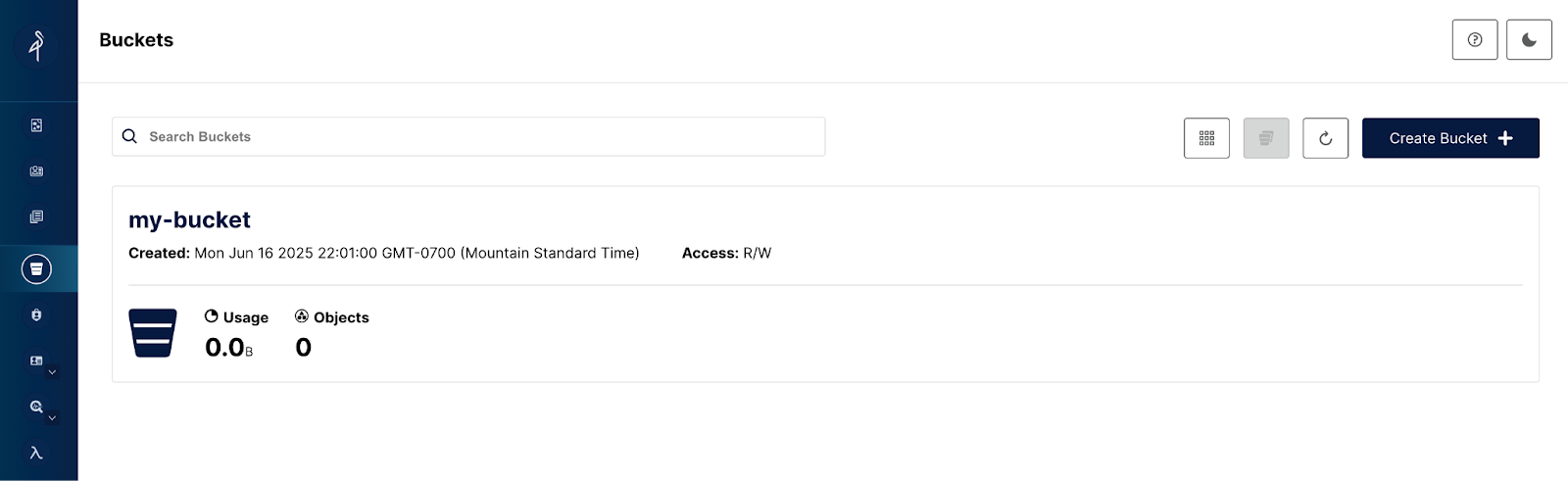
Create Data
Run the following command to open up a spark shell:
docker exec -it spark-iceberg spark-sql \
--conf spark.sql.catalog.demo=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.demo.uri=http://nessie:19120/iceberg/ \
--conf spark.sql.catalog.demo.warehouse=s3://my-bucket/ \
--conf spark.sql.catalog.demo.type=restOnce your SQL shell is created, run the following to create and insert data into four tables: person, software, created_info, knows
CREATE TABLE person (
id VARCHAR,
name VARCHAR,
age int
);
INSERT INTO person VALUES
('v1', 'marko', 29),
('v2', 'vadas', 27),
('v4', 'josh', 32),
('v6', 'peter', 35);
CREATE TABLE software (
id VARCHAR,
name VARCHAR,
lang VARCHAR
);
INSERT INTO software VALUES
('v3', 'lop', 'java'),
('v5', 'ripple', 'java');
CREATE TABLE created_info (
id VARCHAR,
from_id VARCHAR,
to_id VARCHAR,
weight double
);
INSERT INTO created_info VALUES
('e9', 'v1', 'v3', 0.4),
('e10', 'v4', 'v5', 1.0),
('e11', 'v4', 'v3', 0.4),
('e12', 'v6', 'v3', 0.2);
CREATE TABLE knows (
id VARCHAR,
from_id VARCHAR,
to_id VARCHAR,
weight double
);
INSERT INTO knows VALUES
('e7', 'v1', 'v2', 0.5),
('e8', 'v1', 'v4', 1.0);Add Nessie to Puppygraph
Log into PuppyGraph at http://127.0.0.1:8081/ PuppyGraph with the credentials puppygraph:puppygraph123.
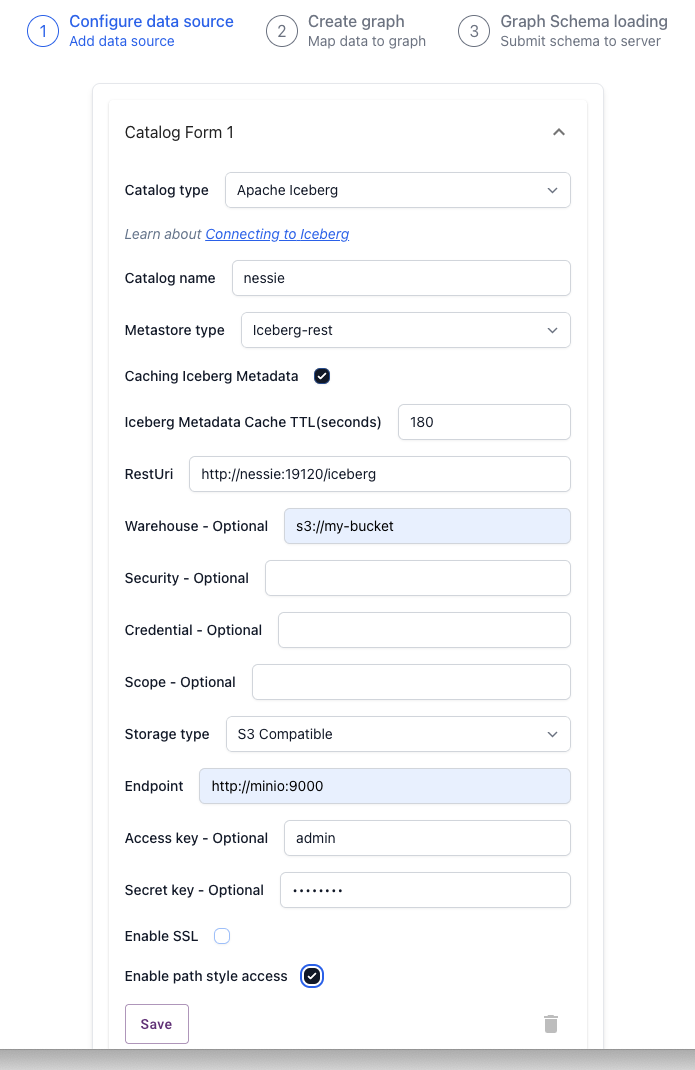
Click on Create graph schema to create a new graph schema. Fill out the following to add Nessie as a data source:
Catalog type: Apache Iceberg
Catalog name: nessie
Metastore type: iceberg-rest
RestURi: http://nessie:19120/iceberg
Warehouse - Optional: s3://my-bucket
Storage Type: S3 Compatible
Endpoint: http://minio:900
Access key - Optional: admin
Secret Key: password
Enable Path Style Access: Check
Create a Schema
Nodes
Schemas are built from nodes that consist of tables. Follow the on screen directives to create the first node for the person table. Allow PuppyGraph to select the ID.
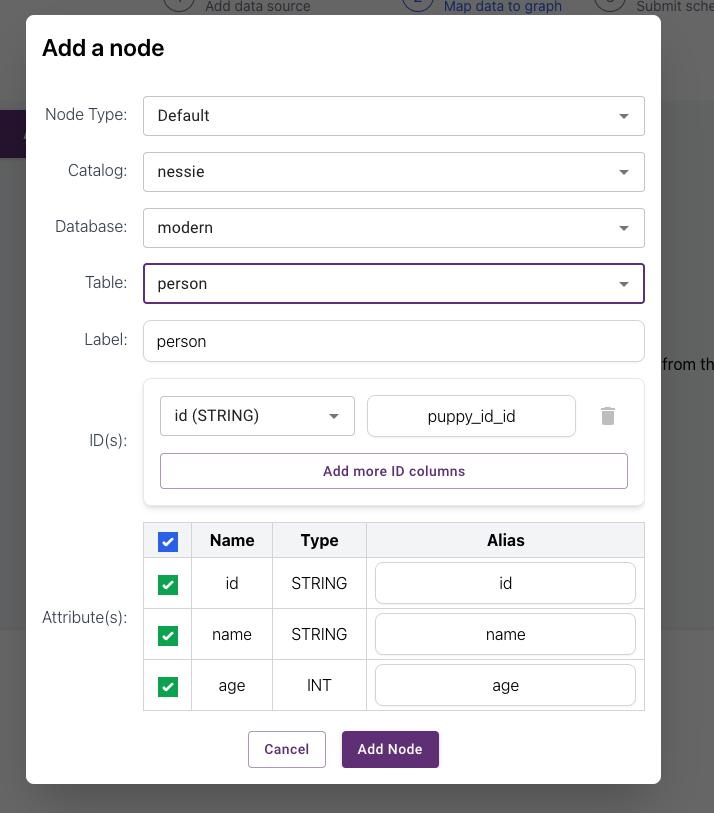
Add the remaining tables: created, knows, and software.
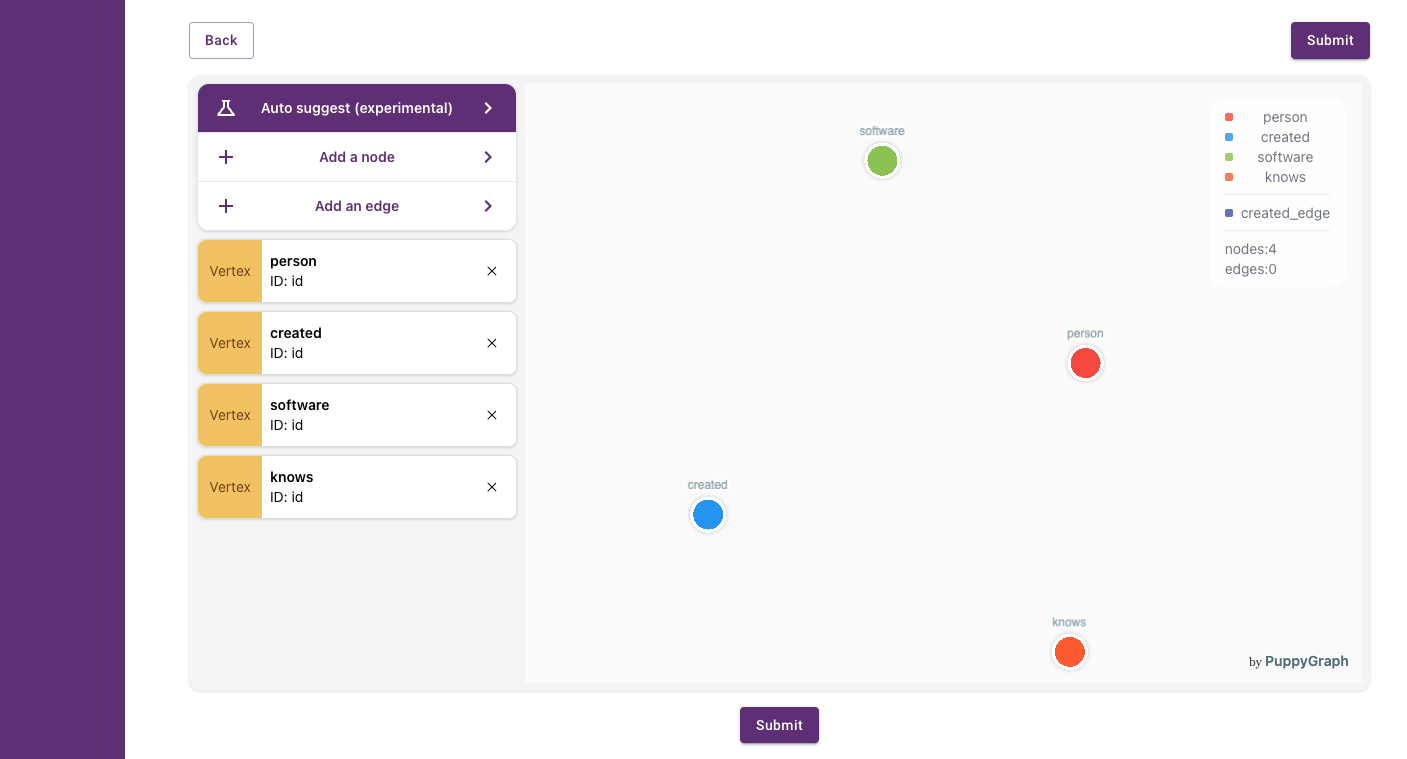
Edges
Add edges to define the relationships between notes. For example, the key ID is shared between the table's person and created. Defining this relationship as an edge will create a line between the tables graphing the relationship visually.
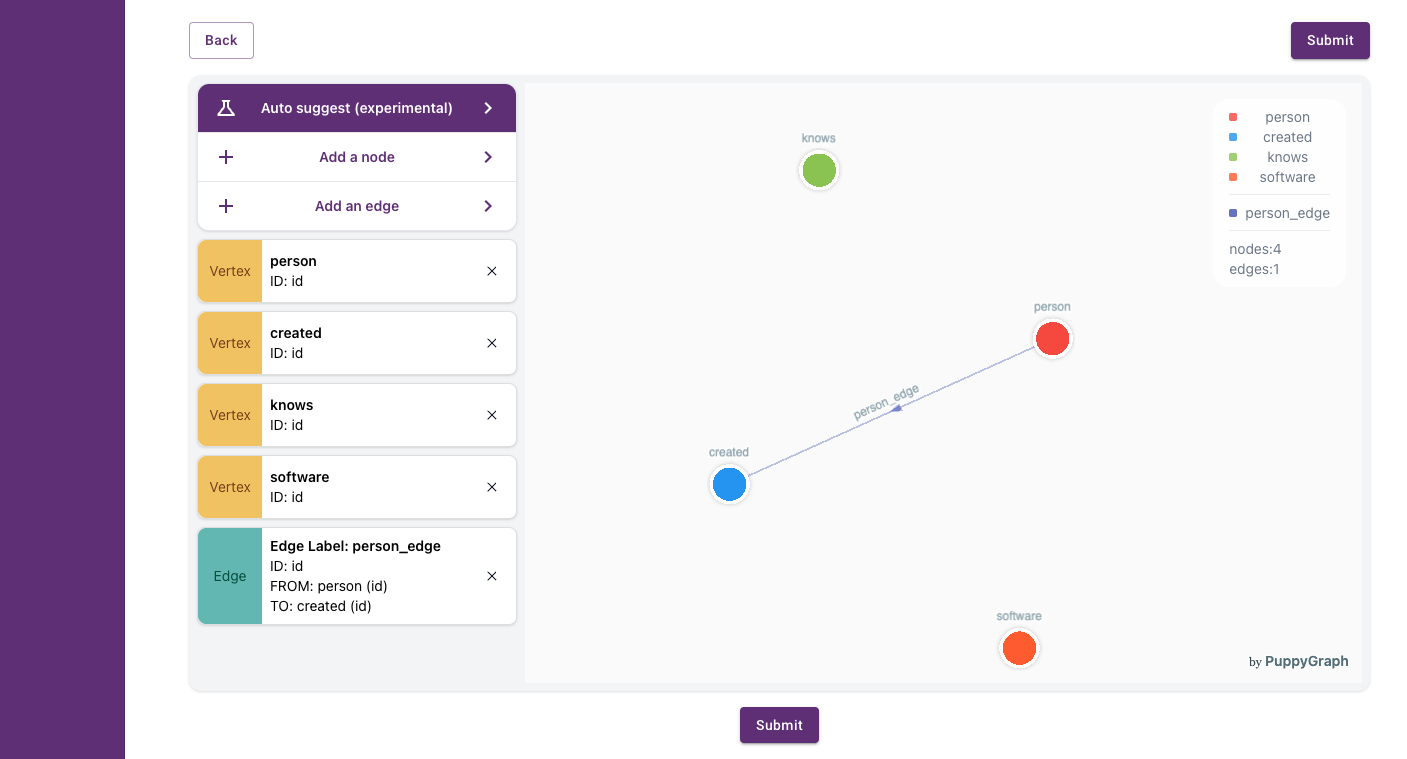
Continue to create edge relationships between the tables.
Submit before continuing to the next steps or your selections will be lost
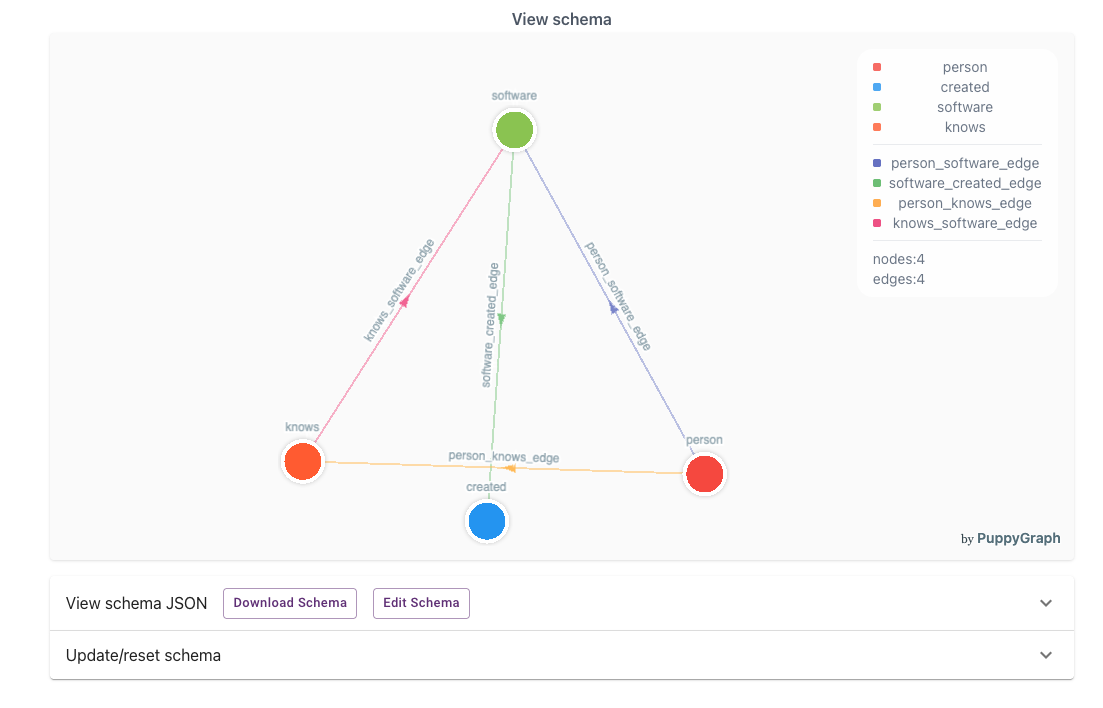
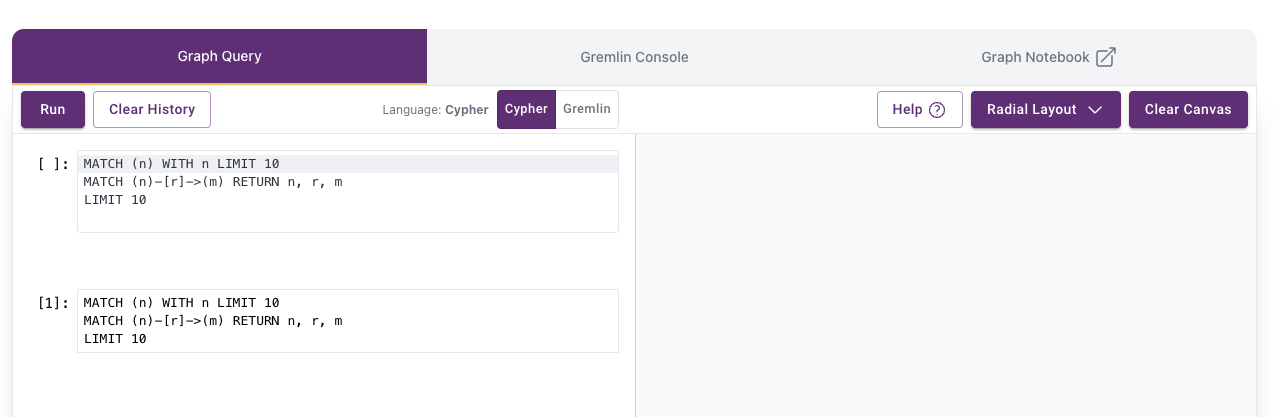
Craft Queries
You can use the dashboard to keep track of the nodes and edges you’ve created and use the query interface to write queries against your data.
Shutdown Docker
When you’re done experimenting, run the following commands to stop and remove everything created by docker; all the containers, networks and volumes.
docker compose down
Relationships Matter
Data lakehouses contain complex and interconnected information. Entities, events, dependencies, and metadata often span multiple tables and systems. Making these relationships available for analysis is a core responsibility of modern data architecture. By combining Apache Iceberg, Project Nessie, MinIO AIStor, and PuppyGraph, teams can expose and explore these connections without adding operational complexity or introducing new data stores.
Join us on our Slack or at hello@min.io with any questions.






