Hadoop HDFS's Logical Successor
The demise of Hadoop is probably overblown. It will not suddenly disappear from the enterprise landscape - there are simply too many clients, too much sunk investment for it to vanish into the night.
What is not overblown is the fact that Hadoop, like countless technologies before it, is in secular, irreversible decline.
There are a number of reasons but they all fall under two common themes: price and performance.
Price seems odd for a technology whose open source licensing model is pure (congrats Cloudera), but price isn’t simply the cost of the software. Price includes the cost to install, configure and maintain that software. For Hadoop those costs are too high - data locality creates inefficient allocation of compute and storage, complexity means there are too many human costs. The cloud, public or private, offers simplicity, elasticity and the massive benefits associated with disaggregation.
Performance, once the pillar of the Hadoop story, has continued to improve, with the community adding optimizations and new projects (Spark, Presto, Impala, Drill). Hadoop’s technology substitutes, however, have improved at a far faster rate and has a higher ceiling driven by denser compute, faster networking and highly performant, software defined storage. The tradeoff or “rationale” that fueled Hadoop’s growth phase: complexity and higher costs in exchange for performance isn’t valid anymore.
The cloud, public or private, now offers Hadoop-like performance at a fraction of the cost and complexity.
Related: Migrating Hadoop HDFS to Modern Object Storage
This is what fuels the evolution and adoption of new technology - better performance or lower costs. When you get both the end comes quickly if you cannot respond.
Too few people are talking about this component - the response. With MapR’s asset sale, there is only one commercial entity left in the Hadoop space - Cloudera. That company has a $1.6B valuation, $103M in cash and burns about $50M a quarter. That doesn’t instill confidence in the ecosystem.
More importantly, the drivers of ecosystem growth (Presto, Spark, Impala…) were designed to work independently of Hadoop - indeed Databricks sees themselves as 100% cloud. As a result, the “community” around Hadoop doesn’t have much incentive to rally to the flag. They have already moved on.
This will accelerate Hadoop’s decline. No one is interested in arresting the slide - even the SI’s with big practices built around it are making alternate plans because they know that recommending Hadoop for a net new install tells your client that you are hopelessly behind the cloud-native times (which makes the IBM/Cloudera partnership a headscratcher).
To illustrate the point, take our object storage software. Like Cloudera we target the private cloud and are highly adept at performance driven workloads.
That is where the similarities end.
AIStor is part of a disaggregated software stack that is build using cloud-native technologies. It scales, simply and gracefully to exa scale. Exceptionally lightweight, it can be bundled with the application stack like NodeJS, Redis and MySQL. It supports the S3 API, allowing applications to be cloud ready from day one. AIStor’s list of enterprise features cover everything from SSO to erasure coding and bitrot protection and have led to its deployment in more than one third of the Fortune 500.
What really makes it stand out, however, is the performance.
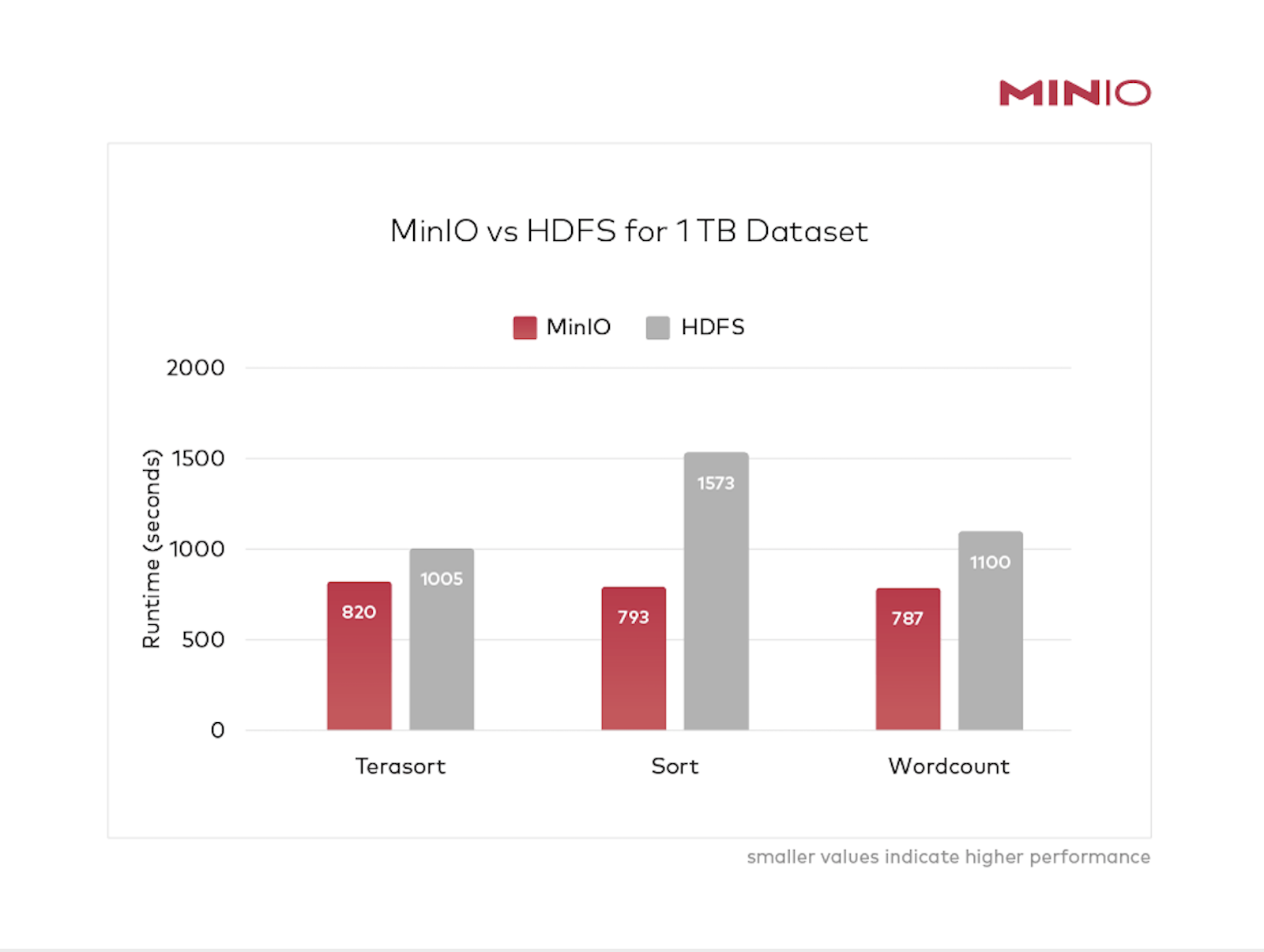
*smaller is better
AIStor’s object storage is faster than HDFS. This has never been the case before.
This is what makes object storage the logical successor to Hadoop HDFS. Performance at scale with a superior TCO.
One might ask, why not block or file? To be sure, every vendor would like to lay claim to the $10B market. The answers are simple and while there is some religion involved, most would agree on the basic facts.
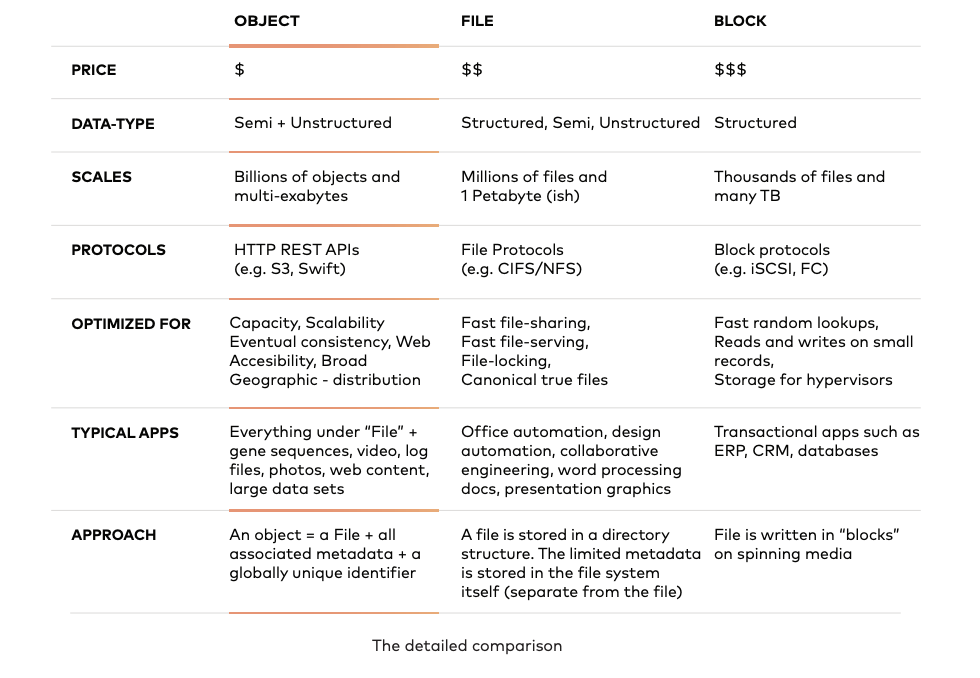
Basically, modern, high performance object storage has the flexibility, scalability, price, APIs, and performance. With the exception of a few corner cases, object storage will win all of the onprem workloads.
Again, this won’t happen overnight - but it will happen in a timeframe measured in quarters, not decades. Join the discussion on Twitter or ping us at hello@min.io to go deeper and get a copy of our Hadoop migration guide.






