Here Comes The Flood
In 1994, EMC’s Symmetrix set an industry high-water mark with its max capacity of 1TB (TeraByte) for an enterprise storage system. In 2016, NetApp introduced the FAS9000 which in a 24-node cluster config holds about 172PB (PetaByte) raw. Increasing by 172,000x after 22 years — while dramatically improving performance and adding dozens of wonderful features — is decidedly impressive. But unfortunately, it’s simply not enough. That heroic gain was merely enough to push corporate IT datacenters across the goal line and into The Peta-Scale Era… ten years late.
Meanwhile at AWS, Azure, Google, IBM Cloud, Apple, Facebook, and elsewhere in The Cloud, all of them were born immediately confronting mind-boggling data-explosion challenges. The global webscalers nowadays measure data in ExaBytes (EB) — thousands of PetaBytes. In the expanding bubble of their parallel universe it has always been The Exa-Scale Era. By distributing countless storage devices among numerous datacenters proliferating across multiple fault domains and geographies, storage architects for The Cloud seem to be coping. But even their best strategies may be overwhelmed by the coming tsunami of unprecedented exponential data growth.
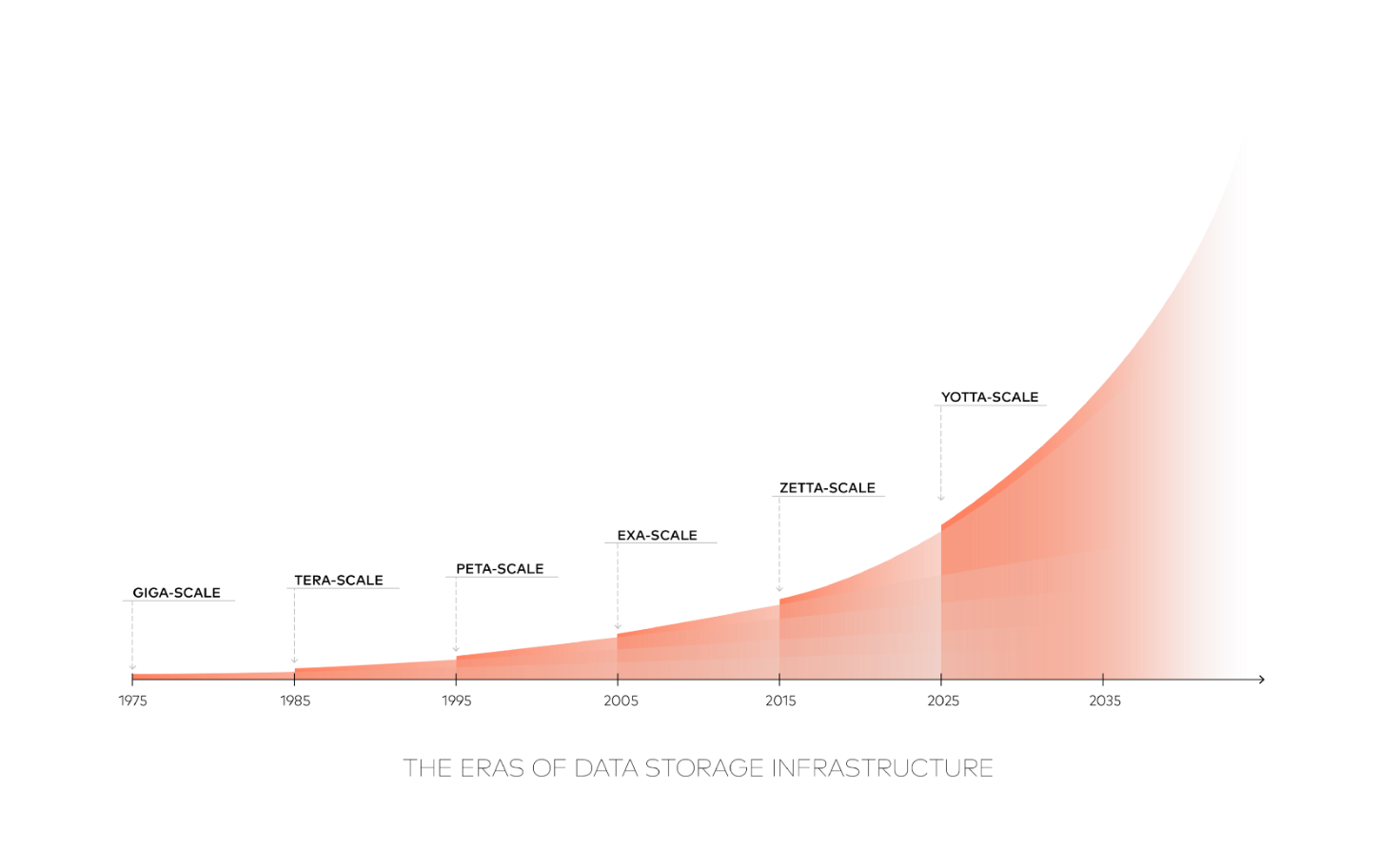
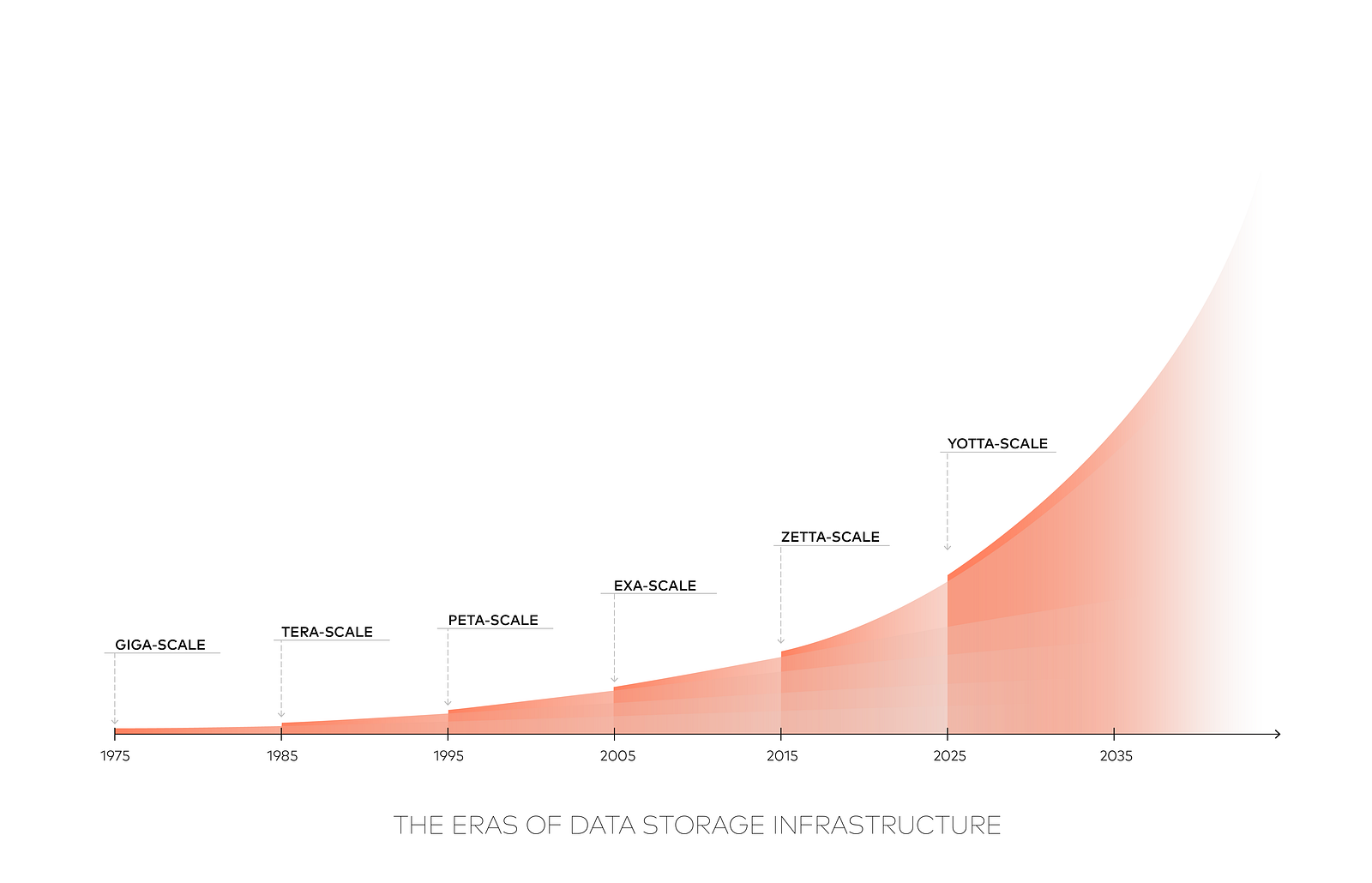
Consider this projection, below (excerpted from a Seagate-sponsored IDC study published in April 2017, “Data Age 2025”), showing the amount of data expected to be created each year.

Bear in mind that a single ZB (ZettaByte) is a MILLION PetaBytes. IDC’s prediction that 163 ZB — 163 million PB’s — will be created in 2025 might make you feel giddy if you concentrate on it for very long. But in fact their extrapolation may be low. Entering The Yotta-Scale Era in 2025 will test the fortitude of everyone involved. For now, in 2018, coping with the intensifying demands of The Zetta-Scale Era is already more than most participants can comfortably handle.
From ~40ZB in 2020 to 163ZB in 2025 is barely over a 4x increase during a five-year span during which we can confidently expect ongoing advances in digital photographic & video resolution, a profusion in IoT applications and devices generating increasingly rich data, and increasing availability of technology in the hands of an increasingly large percentage of the global population. All of that will be happening at a time when robots, AI, and other non-human-controlled sources will be tirelessly generating data 24x7. If 40ZB in 2020 is in the right ballpark, than the actual total amount of storage required in 2025 could easily turn out to be far greater than the 163ZB estimate. This is a dismal prospect, considering that even 163ZB would be intimidating to accommodate.
Although a hefty chunk of those new ZB’s will be in the form of video flowing up to The Cloud out of smartphones and other personal devices (plus zillions of Tweets, FaceBook posts, ads, messages and other ephemera), much — arguably most — of the new data flooding into the world will be generated by commercial business activity. Often IoT will be the culprit, owned and operated by corporations. Sensors and actuators increasingly infest all the equipment, operators, supplies and environments associated with every aspect of industrial IoT, connected car, intelligent transportation, and Smart Cities.
The data produced by all those IoT devices has significant business value and will not only need to be captured, but must also be accessible to analytics, and in many cases will also be used for Machine Learning. Simply archiving it all will not be enough. Huge quantities of data will need to be ingested at fantastic data rates, and will also be accessed in multiple contexts which have non-trivial performance requirements.
Such incomprehensibly huge quantities of data cannot be economically stored in public Cloud reservoirs. Imagine the AWS S3 bill for the recurring monthly cost associated with storing even 1 ZB — one million PetaBytes! Plus there would be stupendous network charges associated with subsequently downloading any significant portion of that data for analytics or other use outside of The Cloud. Enterprise customers will simply have to implement their own infrastructure to control expenses. Collectively, the global community of Enterprise IT is embarking upon The Zetta-Scale Era looking for its own set of solutions.
Looking back over The Peta-Scale Era, take a moment to consider that conventional enterprise NAS & SAN storage infrastructure systems took 22 years to scale from 1-TB to 172-PB. At that same pace, it could take another 22 years to enter The Zetta-Scale Era — i.e., 172,000x 172PB = 29.5 ZB. But the world can’t wait 22 more years. Clearly we will need to at least augment that evolutionary process with something else.
Most data stored in The Cloud is in the form of Object Storage, and the AWS S3-API associated with it is an excellent protocol to be used in distributed application deployments spanning WANs as well as LANs. Its scalability has worked out very well for The Exa-Scale Era, and it has even been productively deployed in the corporate IT world as well. But as discussed above, during The Zetta-Scale Era, ingesting and processing millions of PetaBytes will require a new level of performance in combination with a more distributed approach to deployment than we’ve generally seen before in corporate datacenters. And integration with a broad variety of data formats and legacy enterprise platforms will also be important to enterprise customers for reasons that haven’t been very relevant to the web oligarchs.
The good news is that MinIO’s Object Server design addresses all of these concerns: S3-API, fully distributed (including erasure coding and bit-rot detection and auto-healing), multi-PetaByte scale without trading off exceptional performance, and multiple options for simple integration with legacy enterprise platforms.
Just in time for The Zetta-Scale Era!






