How to Install and Configure Kubeflow with MinIO Operator

Kubeflow is a modern solution to design, build and orchestrate Machine Learning pipelines using the latest and most popular frameworks. Out of the box, Kubeflow ships with MinIO inside to store all of its pipelines, artifacts and logs, however that MinIO is limited to a single PVC and thus cannot benefit from all the features a distributed MinIO brings to the table such as Active-Active Replication, unlimited storage via Tiering - and so much more.
In this blog post we are going to configure Kubeflow to use a large MinIO Tenant on the same Kubernetes cluster, but of course, this configuration applies to Kubeflow and MinIO being on different clusters as well. For your reference, please see our earlier blog post, Machine Learning Pipelines with Kubeflow and MinIO on Azure, and the Kubeflow site.
While we go from soup to nuts in this blog post, if you already have a Kubeflow setup and a MiniO setup, you can skip straight to the Configure Kubeflow section of this blog post to see what needs to be configured.
Setting up the MinIO Operator
Let's start by installing the MinIO Operator and creating a tenant that Kubeflow will use. My favorite way to install MinIO Operator is via kubectl apply -k but we also have Helm Charts available, and we are also available on the AWS Marketplace, Google Cloud Marketplace and Azure Marketplace.
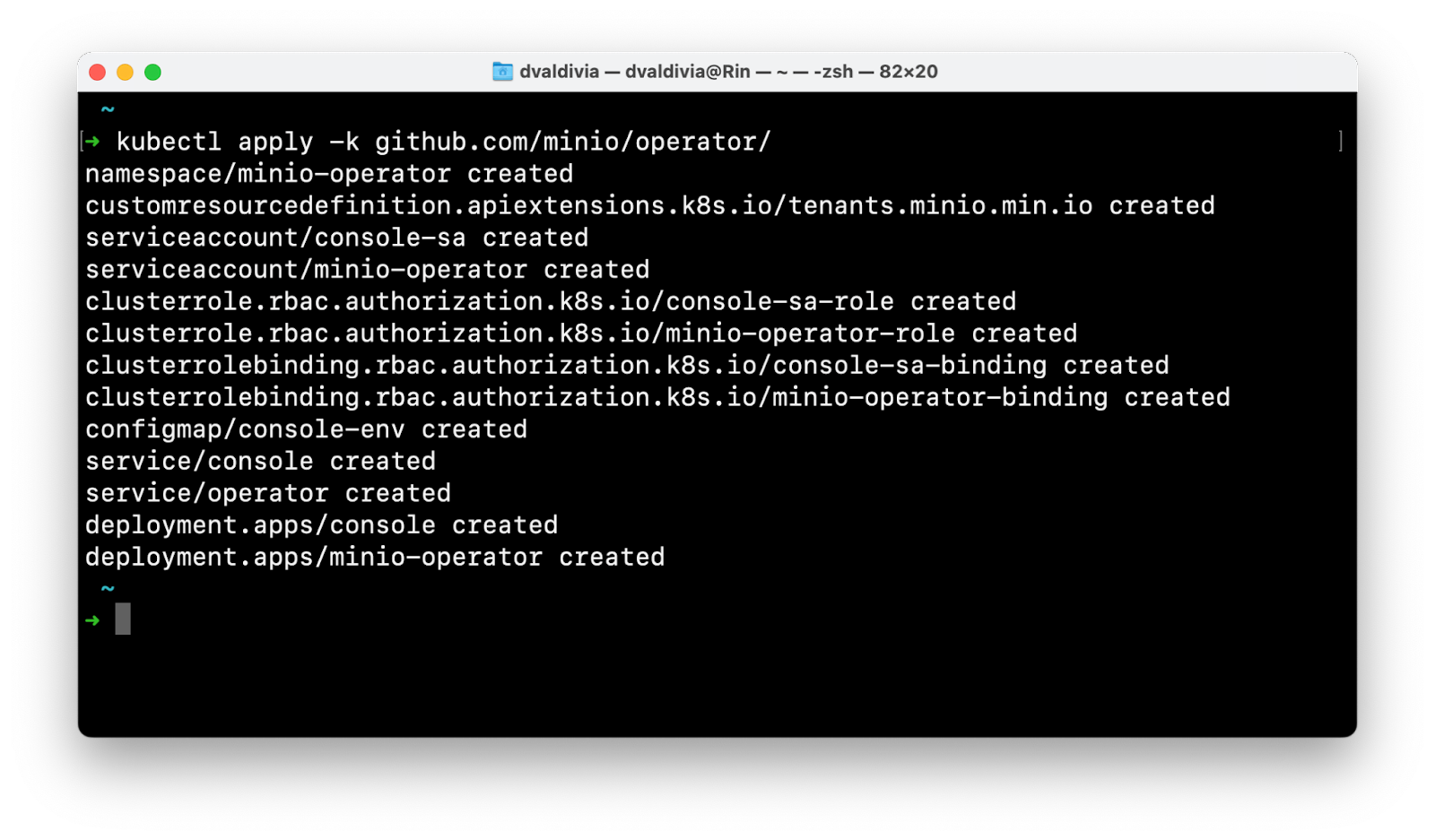
This will install the latest and greatest MinIO Operator, now we just need to log into the Operator UI and create a tenant. For this step we'll get a service account JWT token to login, but this UI can also be secured with AD/LDAP or OIDC.
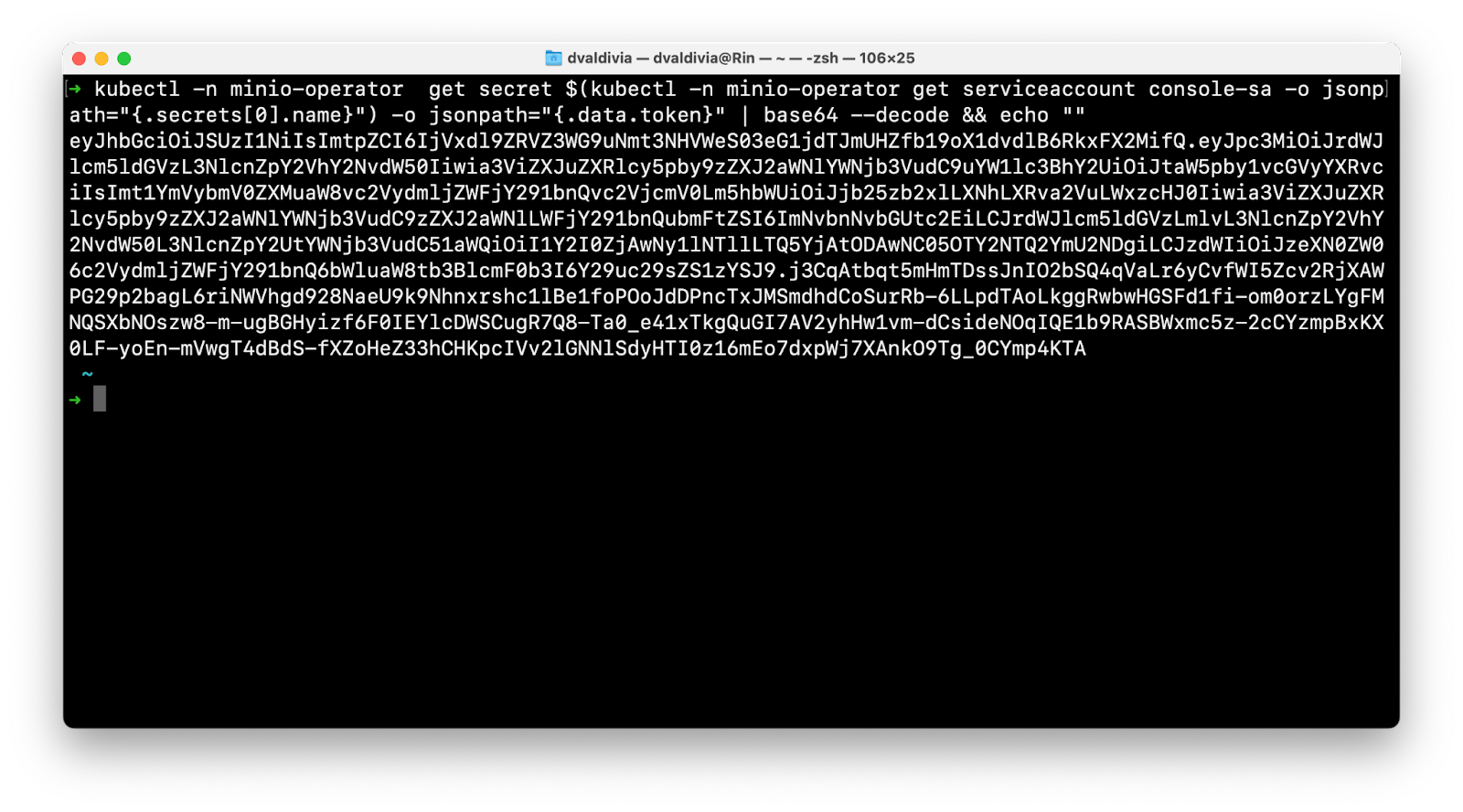
Now let's port forward the UI and login.
Now open a browser, go to http://localhost:9090 and login with the JWT token we got on the previous step.
After logging in, click on Create Tenant and set up a 1TiB tenant.
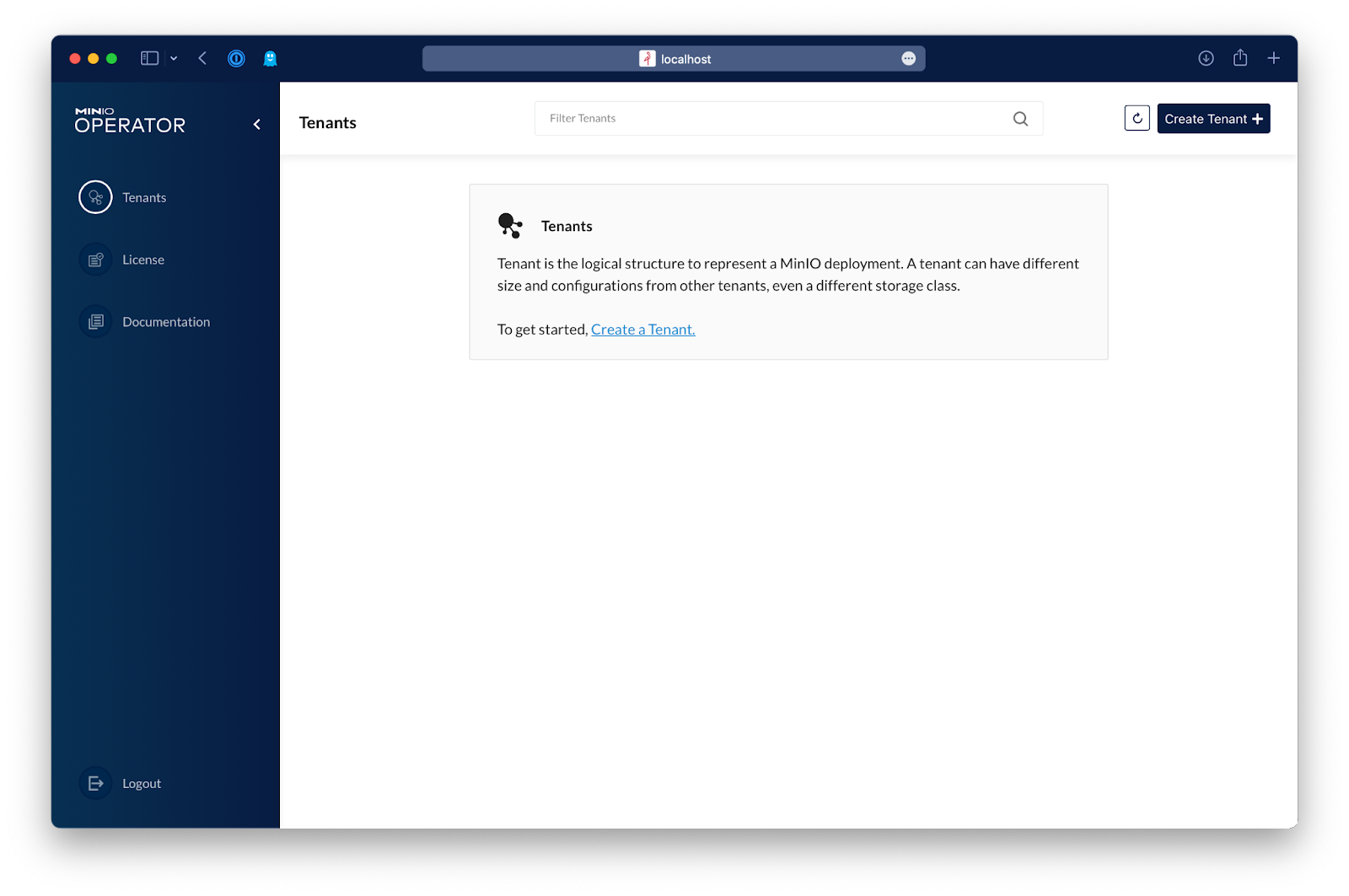
Enter the name of the new tenant and the namespace for it.
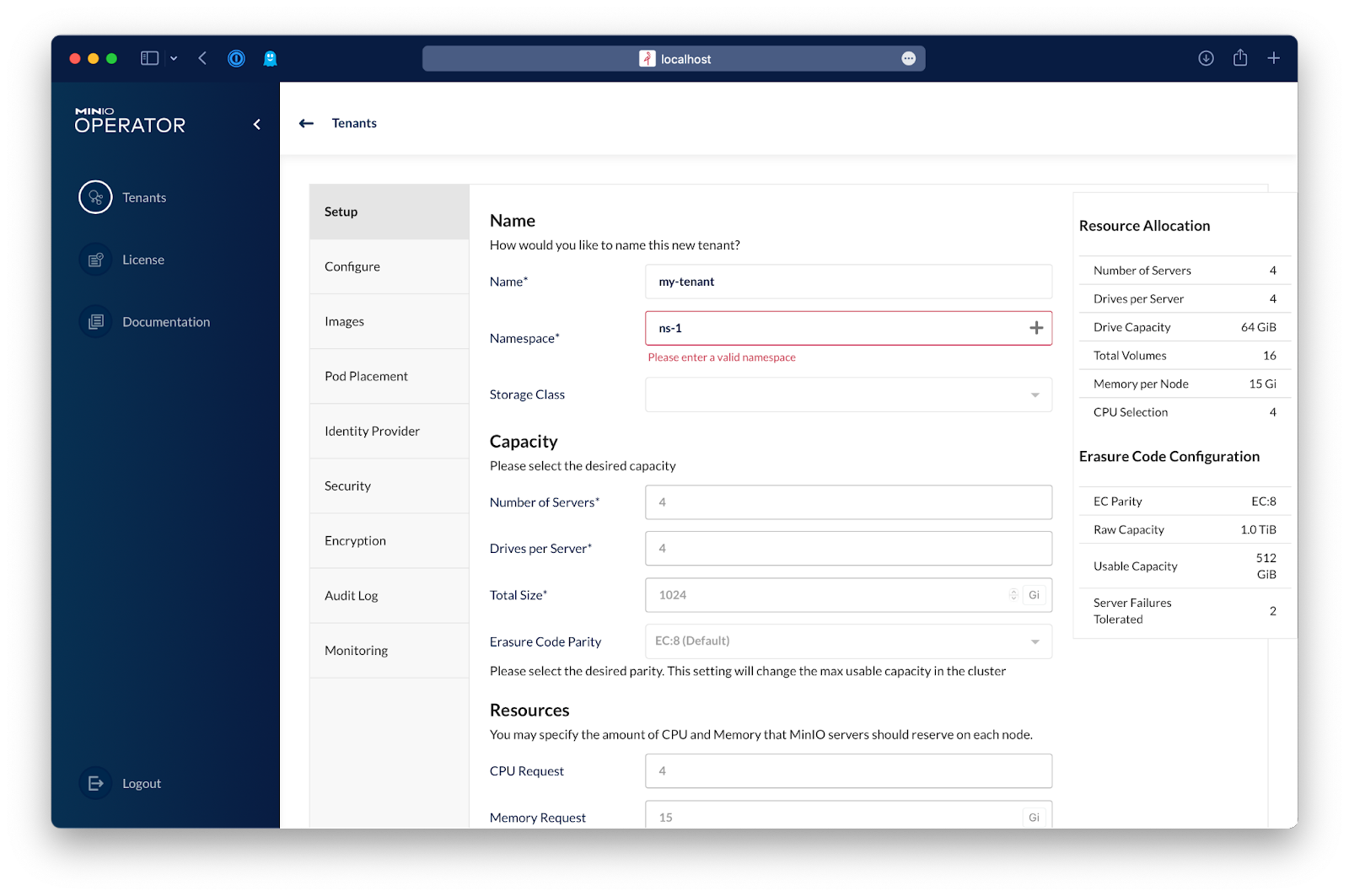
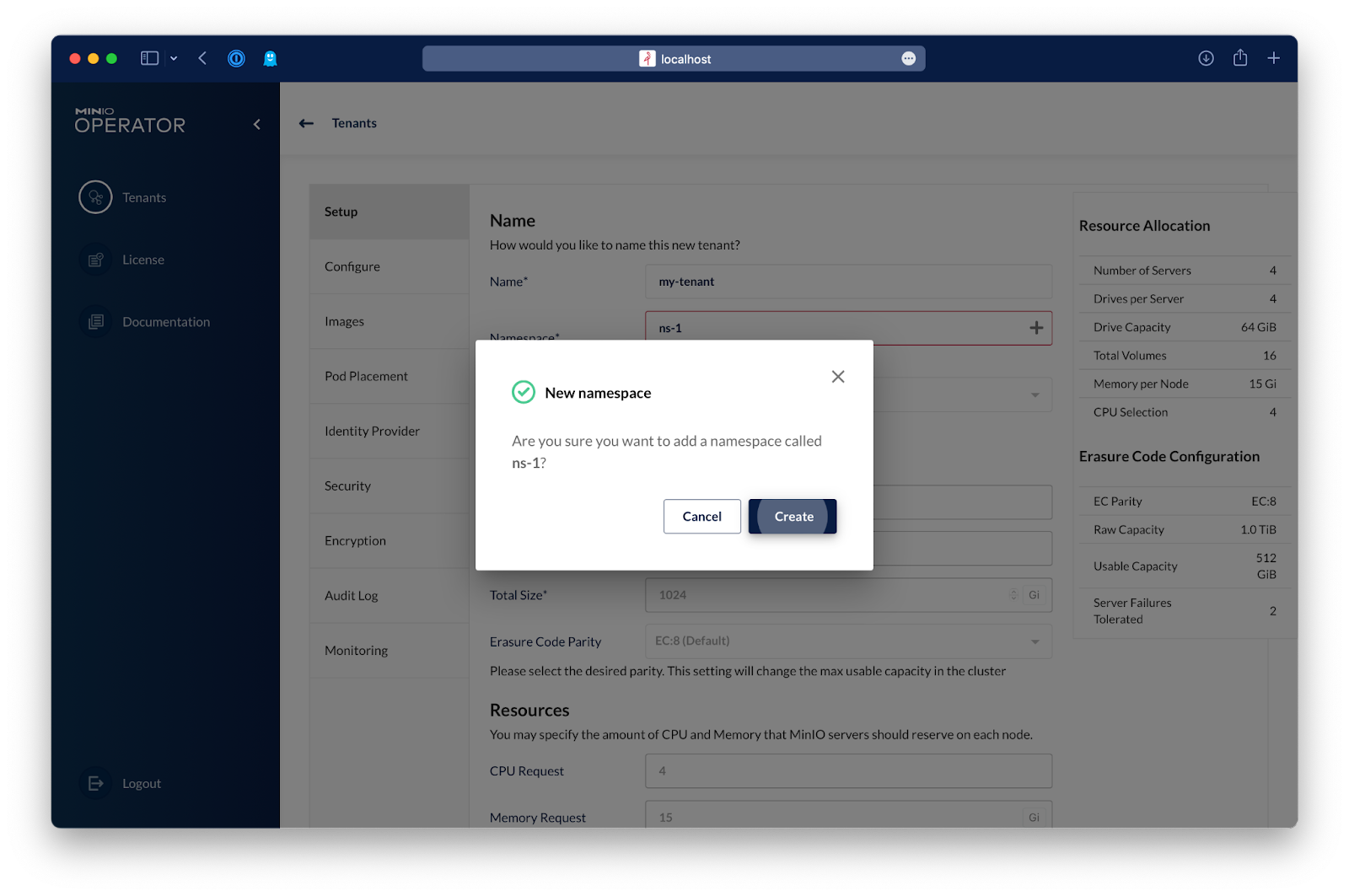
If the namespace doesn't exist you have the option to create the namespace.
Now let's size the tenant. I'll be setting up a 4 node cluster that has 4 drives on each node, in this case, because we’re on Kubernetes, node or server translates to pods and drives per server translates to PVCs per pod.
I'm also starting with 1TiB of capacity but you can always expand the capacity of the tenant.
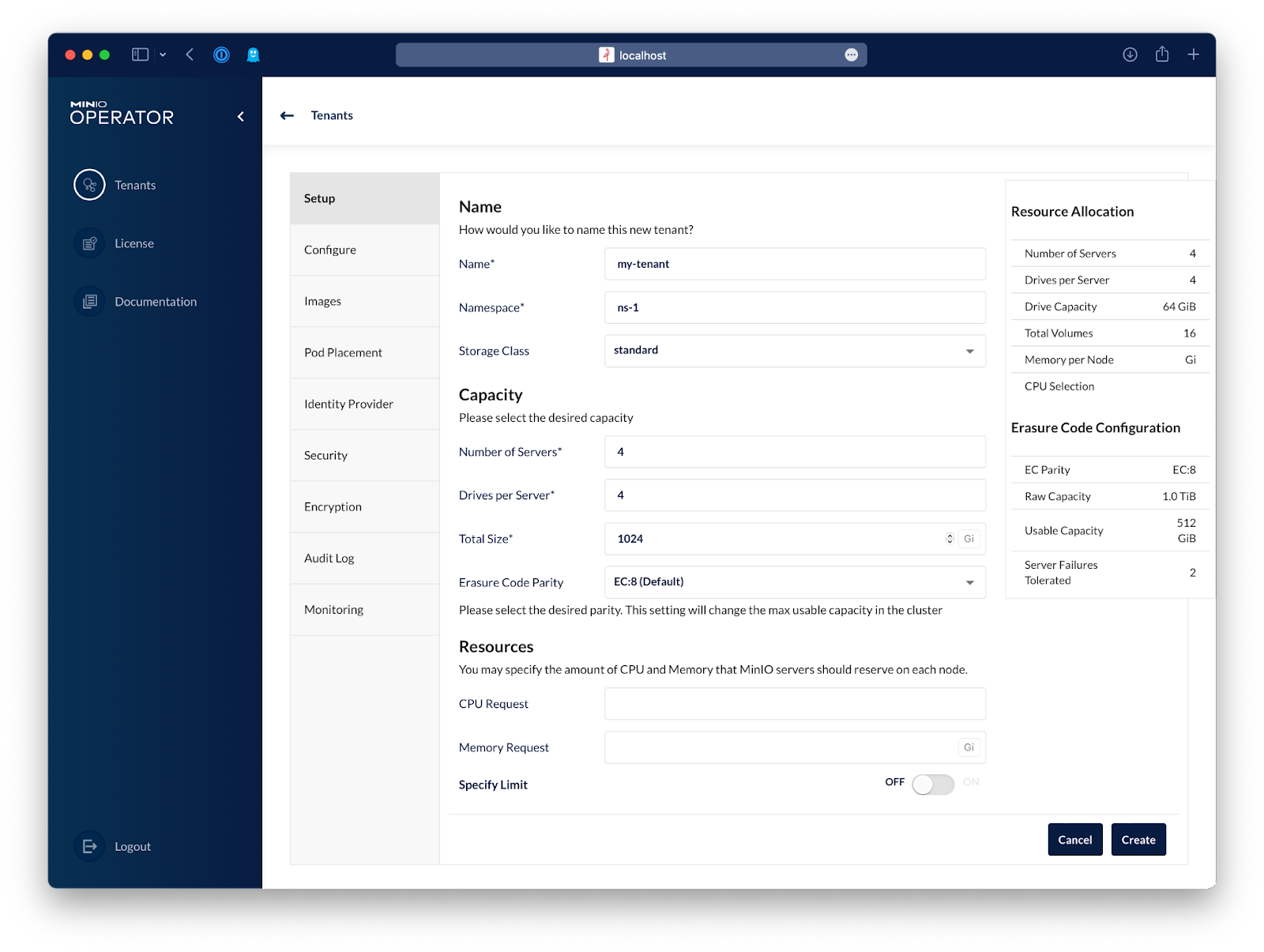
Let's go to Identity Provider and create a basic user that will be used by Kubeflow. If you choose to configure an external identity provider that uses OpenID or Active Directory/LDAP, you can just go ahead and create a service account after you log in to the tenant.
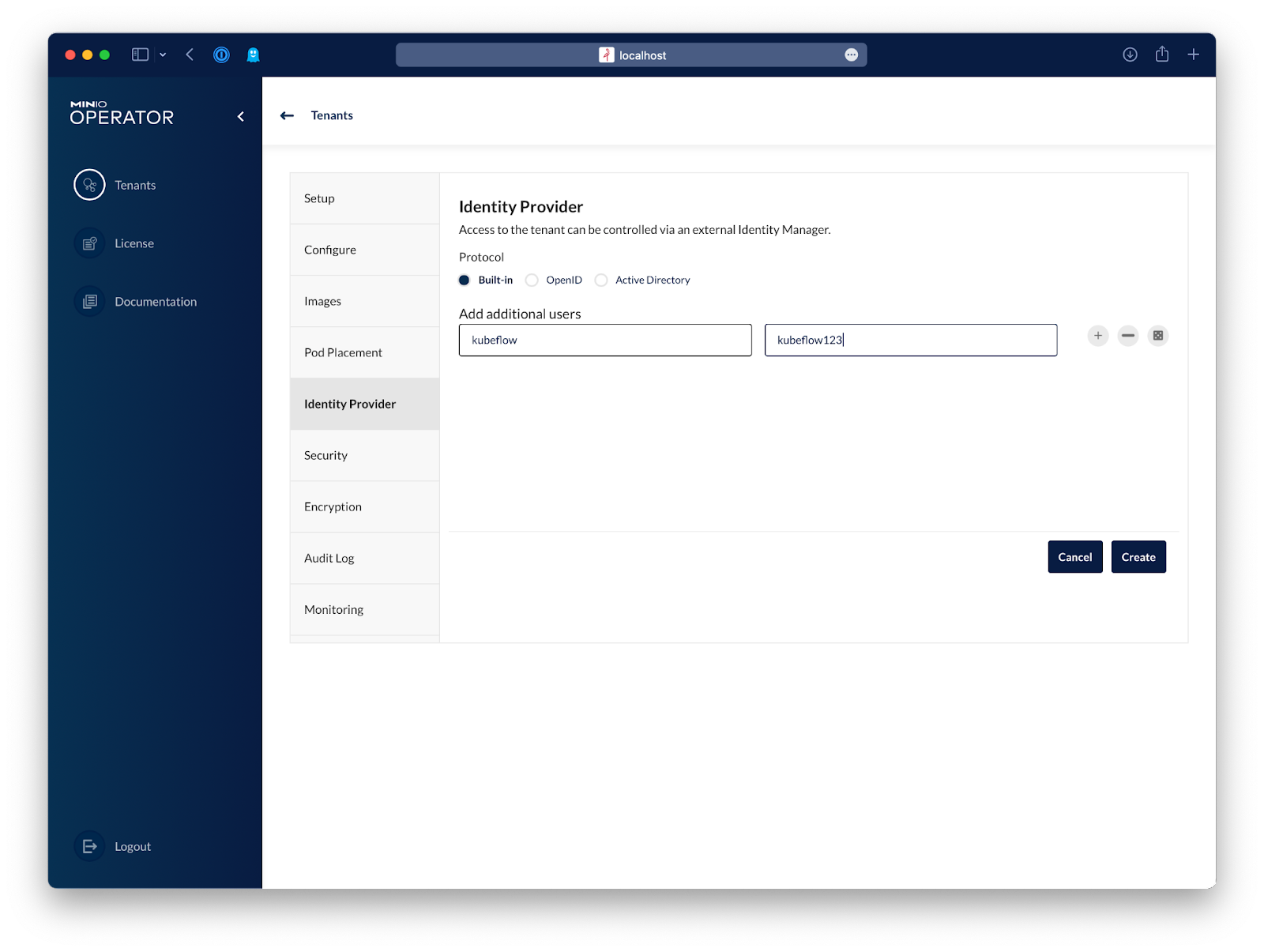
Lastly, we'll disable TLS just to keep this blog post from getting too long, but if you want to have TLS enabled on your tenant, you'll need a certificate configured on the tenant that Kubeflow trusts.
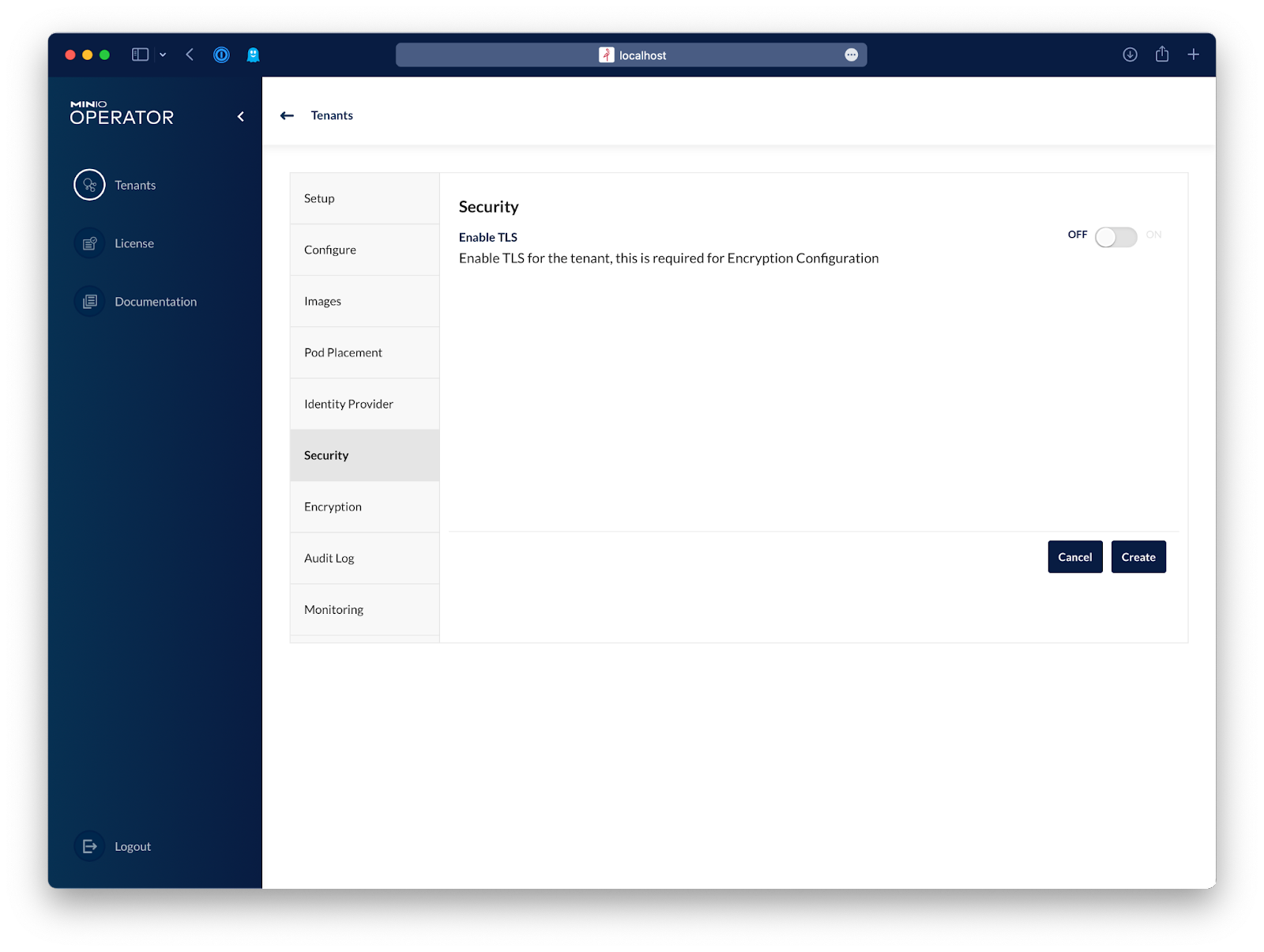
And that's it, just hit Create and the tenant will be created in a few minutes.
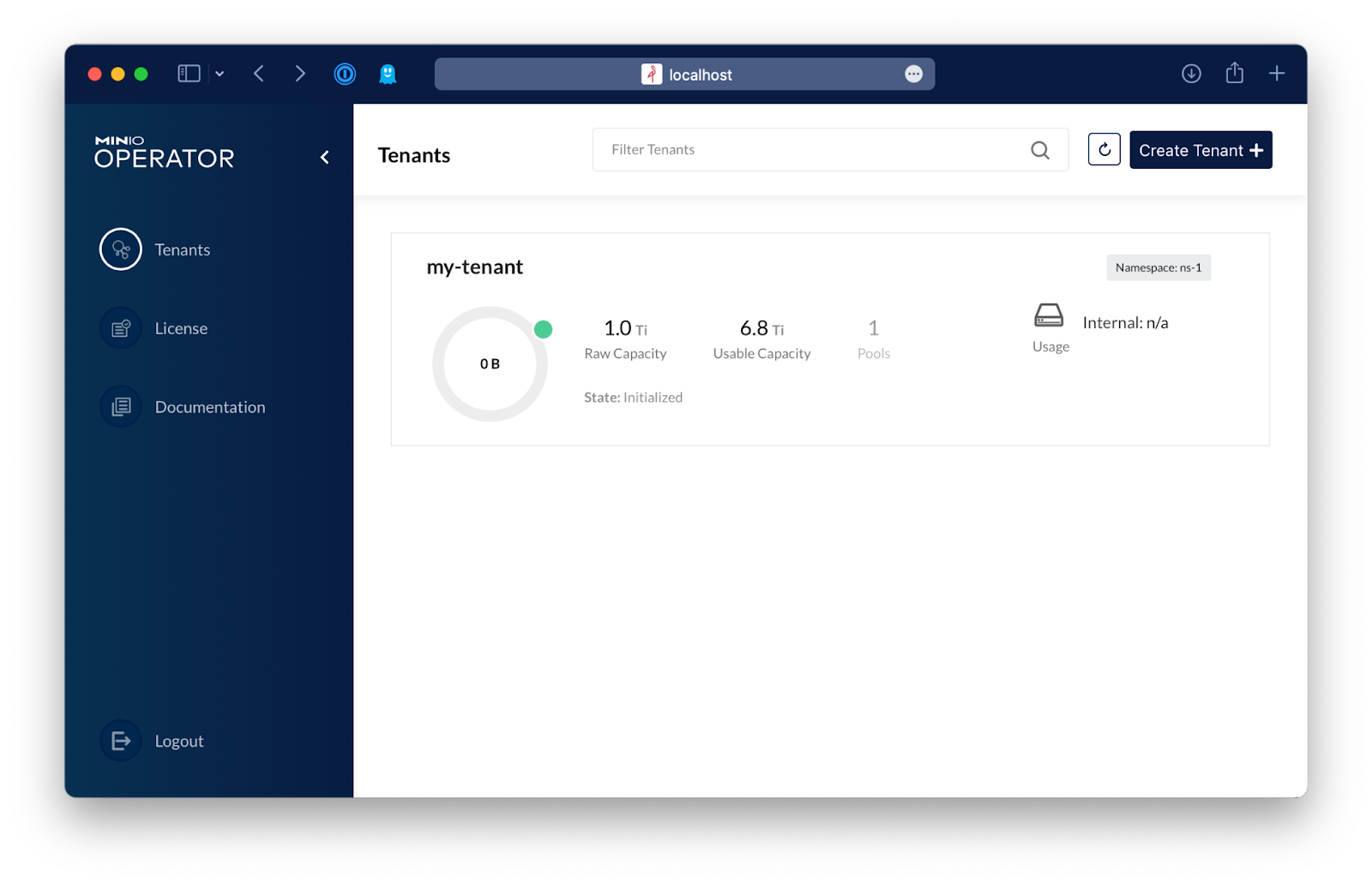
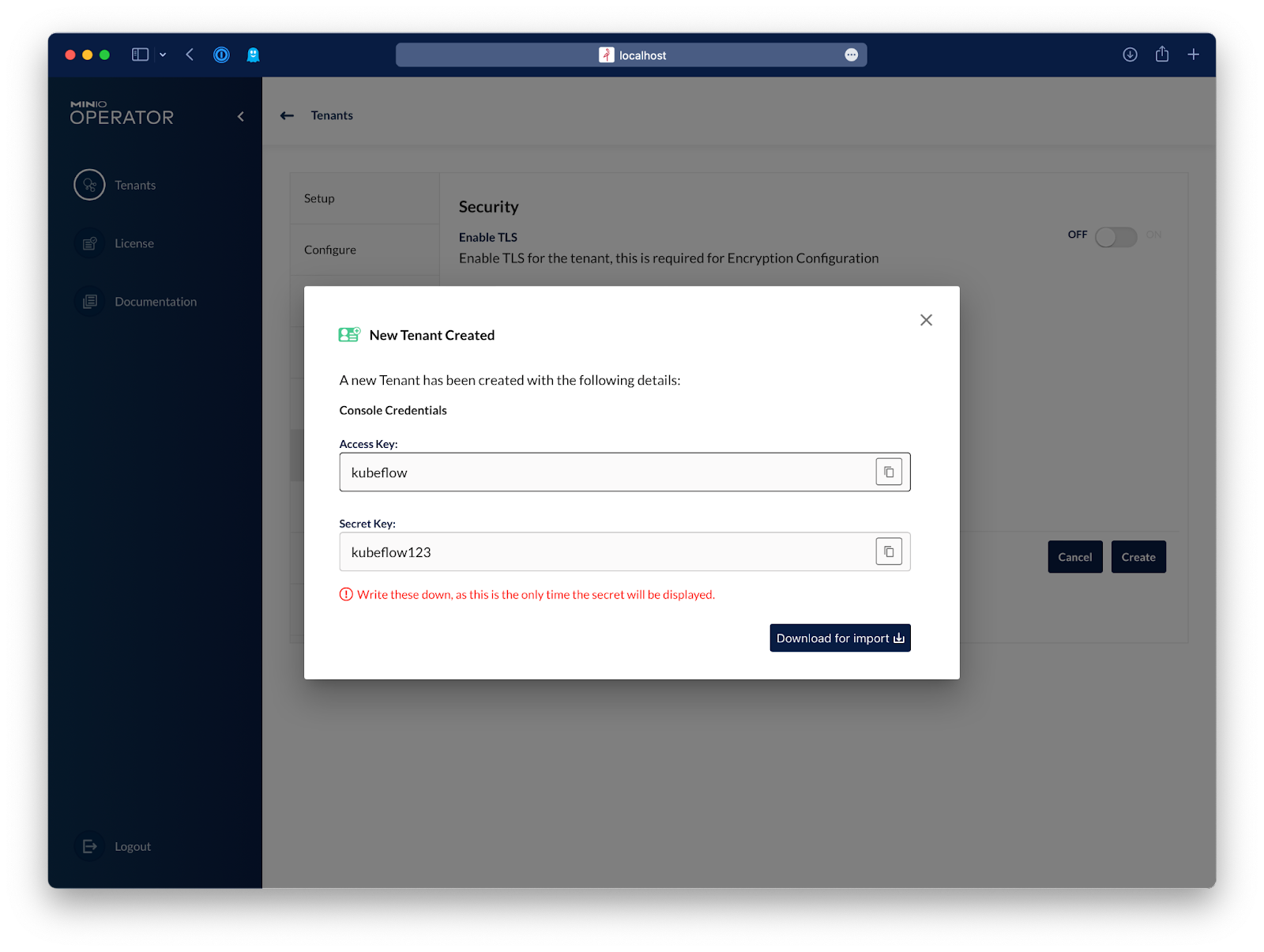
That's it, now you have a distributed, high performance, hyper scale object storage that can be expanded endlessly. From here, let's configure Kubeflow to use this MinIO deployment.
Setting up Kubeflow
In this section, we'll set up Kubeflow from scratch on Kubernetes. This works for on-premise deployments, development environments or any public cloud, although cloud providers frequently offer a pre-configured version of Kubeflow.
We'll be using the kubeflow/manifest repository. Bear in mind there are some strict requirements for this to work, for example, the highest version of Kubernetes supported by Kubeflow 1.5.0 (at the time of writing) is 1.21 so make sure you’re using a Kubernetes cluster that meets this requirement.
One additional requirement is to have Kustomize version 3.2.0, and that's it.
Let's start by cloning the kubeflow/manifest repository
Then change directories the manifest folder and run the following command:
This command will take a few minutes to install all the resources needed by Kubeflow. If anything fails to apply, the command will continue attempting to apply it until it succeeds entirely.
After a few minutes, you can confirm all the pods in the kubeflow namespace are up and running:
Now we will configure Kubeflow to use our new MinIO.
Configure Kubeflow
The following section is the core of connecting Kubeflow and MinIO. Please note that the resources that need to be modified in this section are also what you'd tweak if you were starting with an existing Kubeflow deployment.
We are going to edit a variety of Config Maps, Secrets and Deployments on the kubeflow namespace first, and then on any existing user namespaces.
All of these steps assume MinIO is running in the ns-1 namespace and running on port 80. If you were running the tenant with TLS you'd use port 443.
Tenant URL: minio.ns-1.svc.cluster.local
Tenant Port: 80
Edit Configmaps
pipeline-install-config
Edit the pipeline-install-config config map and add the following fields to .data:
Edit command:
workflow-controller-configmap
Edit the configmap workflow-controller-configmap and configure the endpoint field inside the s3 section to point to your tenant
Use this command to edit the configmap:
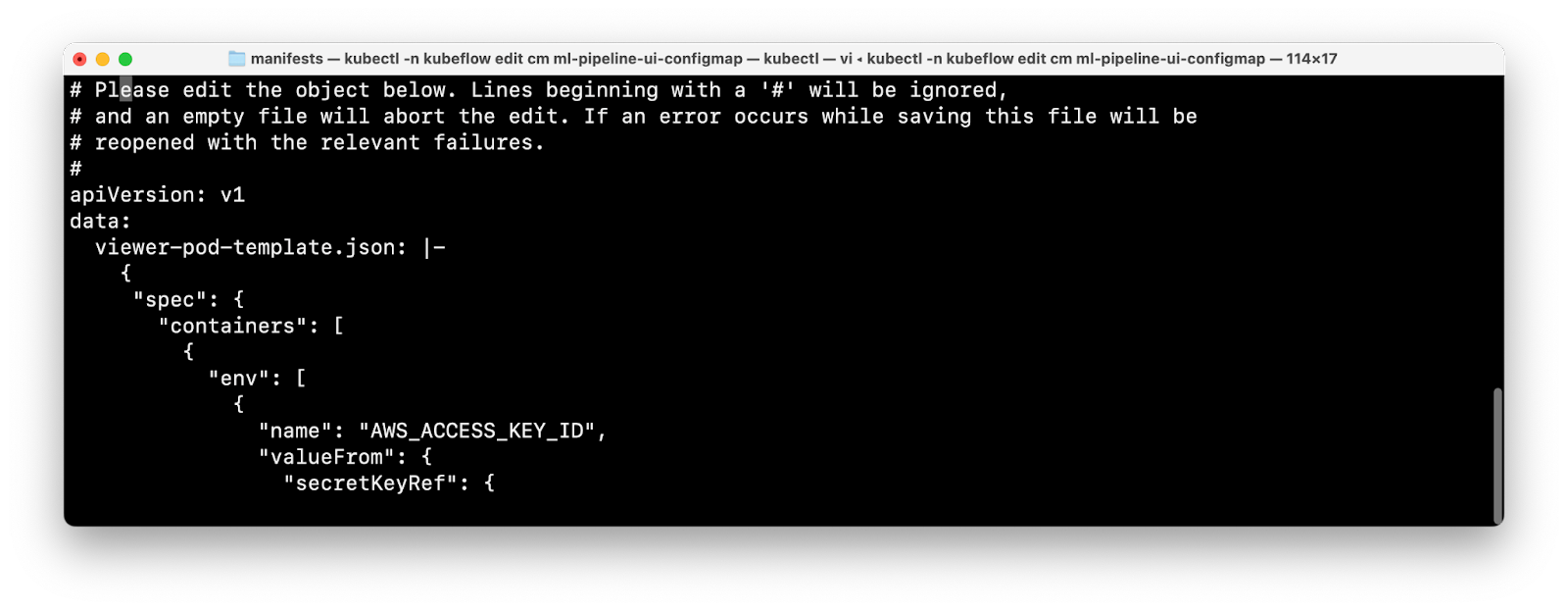
ml-pipeline-ui-configmap
Edit the ml-pipeline-ui-configmap configmap and replace the json content of viewer-pod-template.json with the following json:
Use this command to edit the configmap:
Make sure the indentation structure of the json matches the existing format.
Edit Secrets
We will update the secret that holds the credentials to MinIO, however these are meant to be base64 encoded, so you can encode them with shell:
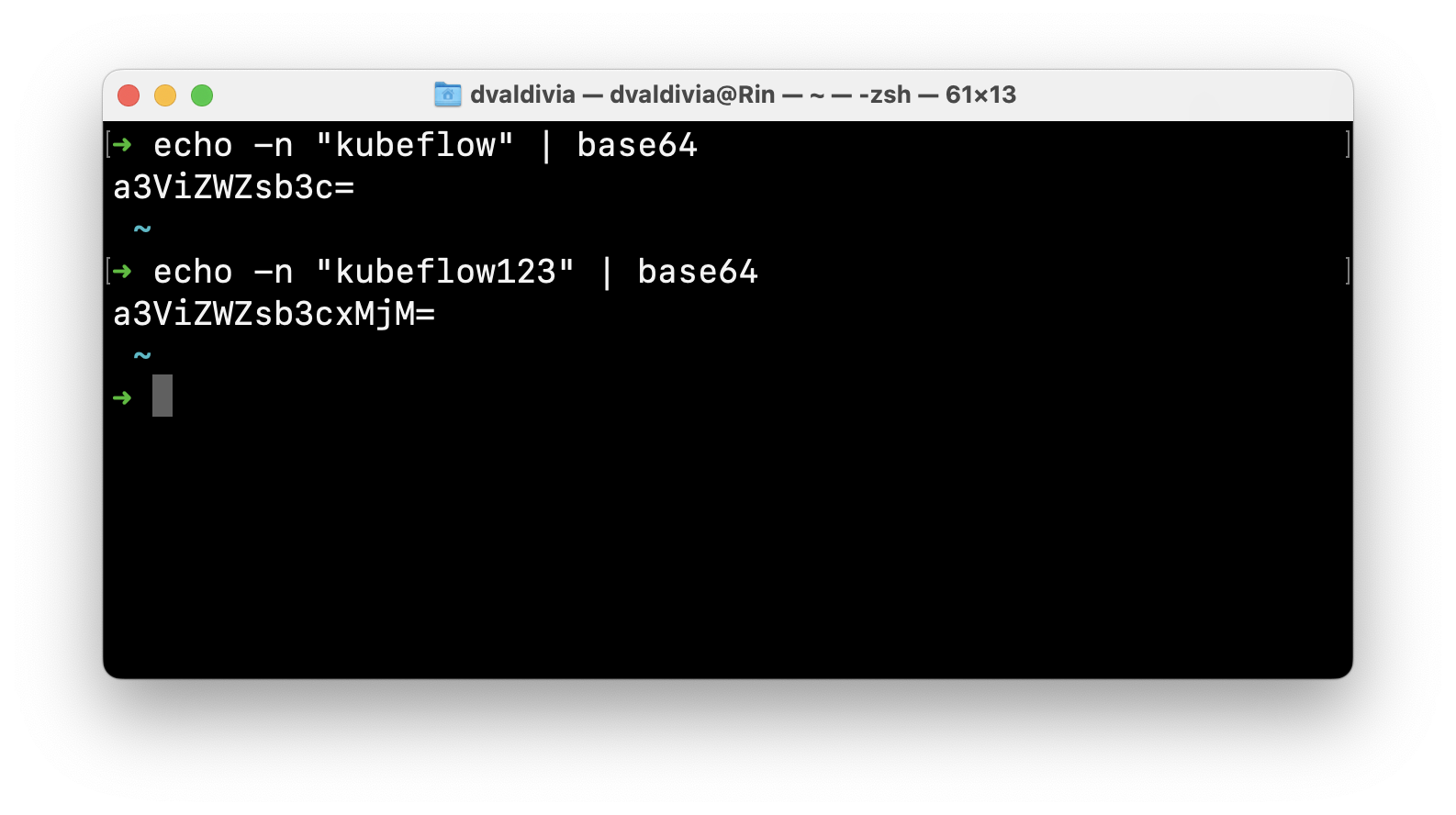
mlpipeline-minio-artifact
Edit the secret mlpipeline-minio-artifact and set these values in the .data field
Use this command to edit the configmap:
Edit Deployments
We will now edit the deployments last to cause a pod restart and to get everything ready.
ml-pipeline-ui
Edit the ml-pipeline-ui deployment and add the following environment variables:
Note: make sure to edit the MINIO_NAMESPACE environment variable to be empty, this is critical as that environment variable is already present in the deployment.
Use the following command to edit the configmap:
ml-pipeline
Edit the ml-pipeline deployment and add the following environment variables:
Use the following command to edit the deployment:
Configure Every User Namespace
This is also very important, for every user namespace, patch the ml-pipeline-ui-artifact deployment in that namespace and the artifact secret. For example, in my case my namespace is kubeflow-user-example-com since we used the example manifest.
Edit the secret mlpipeline-minio-artifact and set these values in the .data field:
Edit the ml-pipeline-ui-artifact and add the following environment variables
Use the following command to edit the artifact:
At this point Kubeflow is properly configured to use your tenant. There’s one last step and then we are good to test our deployment.
Migrate All Data from Kubeflow's Internal MinIO to the New Tenant
Now that we have configured everything, we just need to make sure the data Kubeflow is expecting to be in its buckets is actually there. Let’s copy that data over and then shutdown the internal MinIO that we’re replacing.
To achieve this we will use MinIO Client (mc), a CLI tool for managing MinIO. We'll do all these operations from a pod running inside Kubernetes, but you can do this via port-forwarding and using mc from your own machine if you choose to do so.
Let's run a pod with an Ubuntu shell:
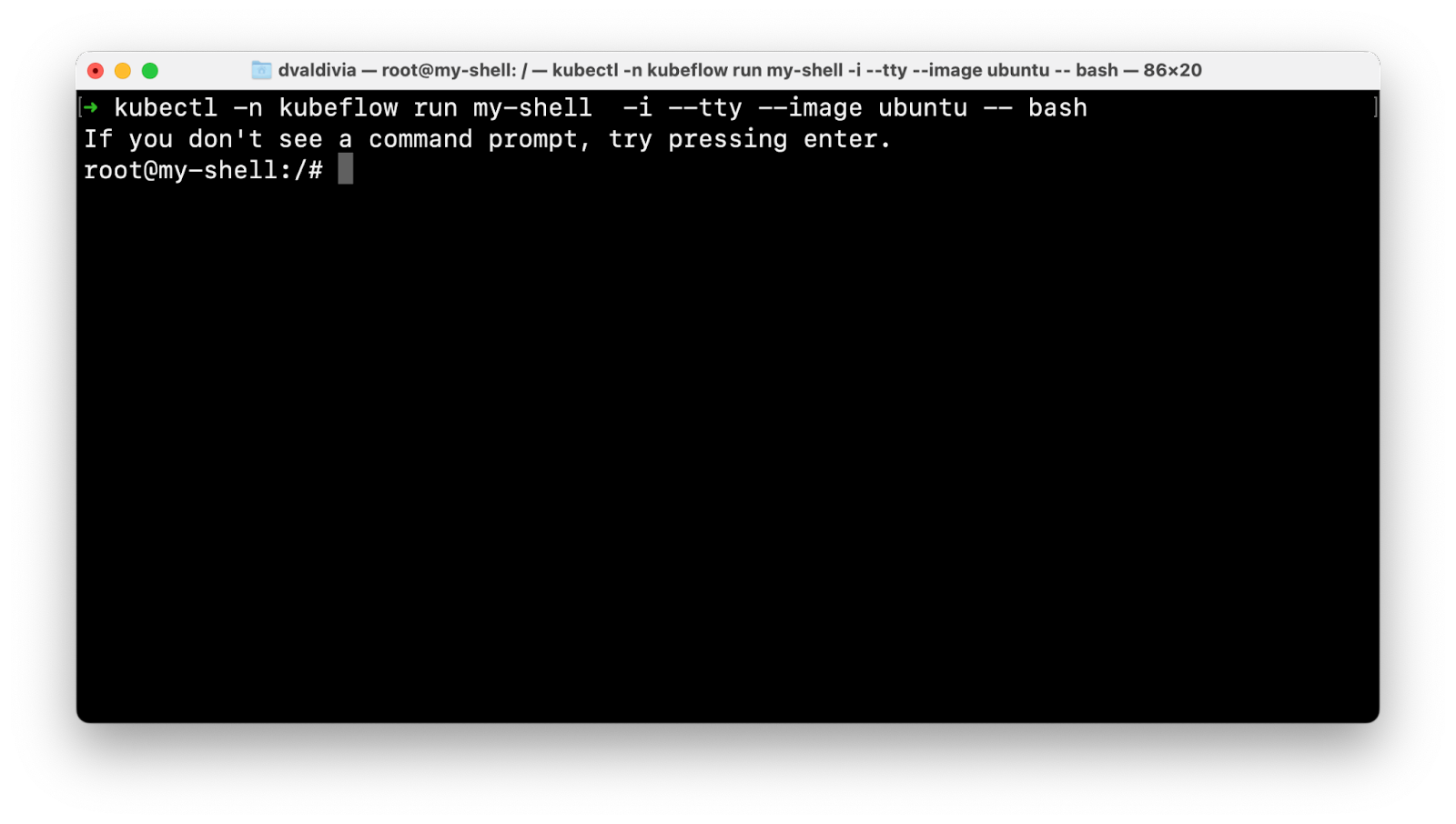
This shell runs on a pod running inside our Kubernetes cluster in the Kubeflow namespace.
Now we will:
- Install wget
- Download mc
- Make mc executable
- Add an alias to the current MinIO
- Add an alias to the new MinIO
- Copy all the data
To accomplish this we run the following commands:
Finally, turn off the internal MinIO as it is no longer required.
All right! We are done moving to the full MinIO deployment.
Validate that Kubeflow is Using the new MinIO
Next we’ll validate the setup and run some pipelines.
If you go to MinIO Operator, you can see the tenant now has data:
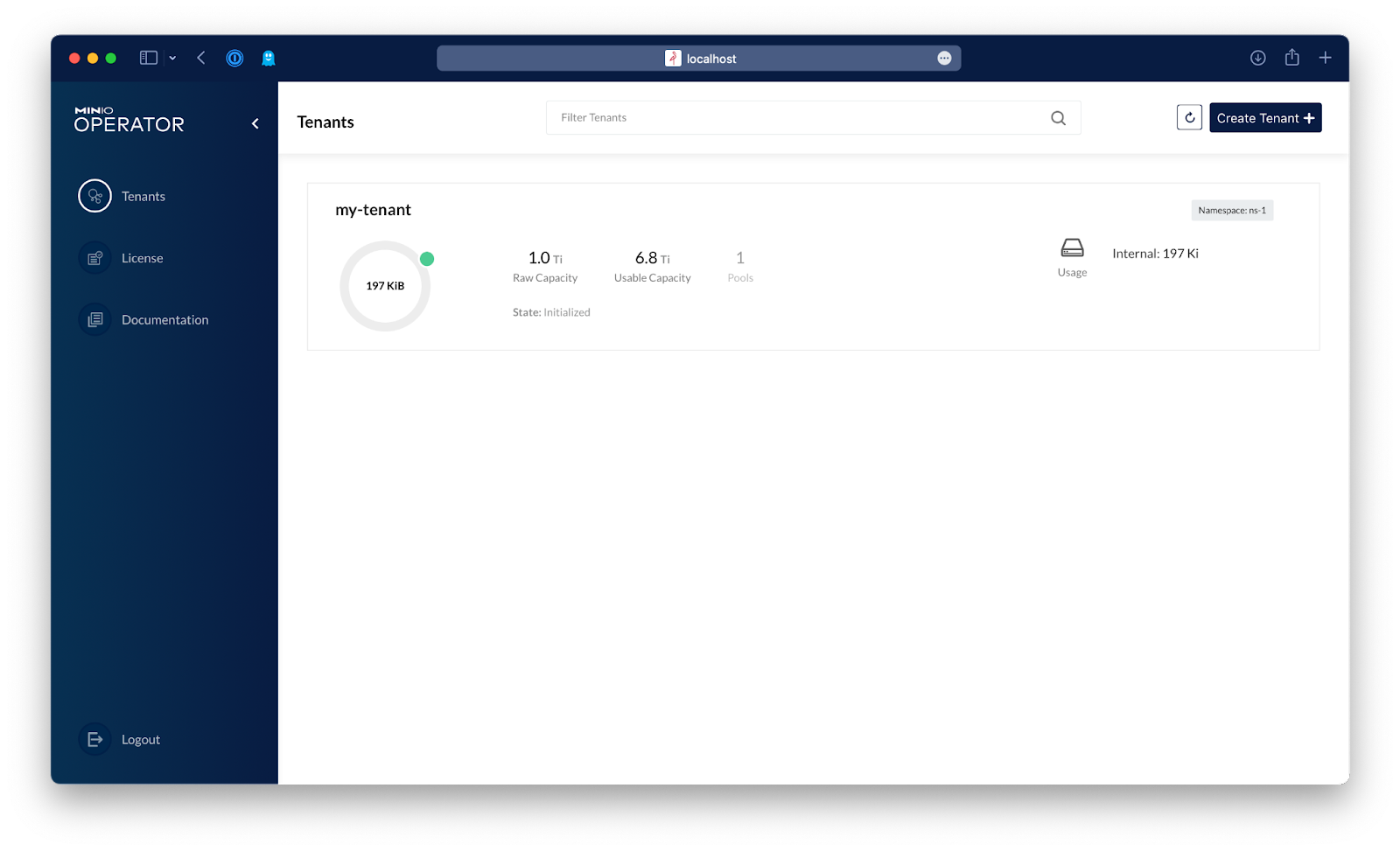
Click the tenant, and then click Console in the top right of the browser window to open MinIO Console in order to browse that tenant.
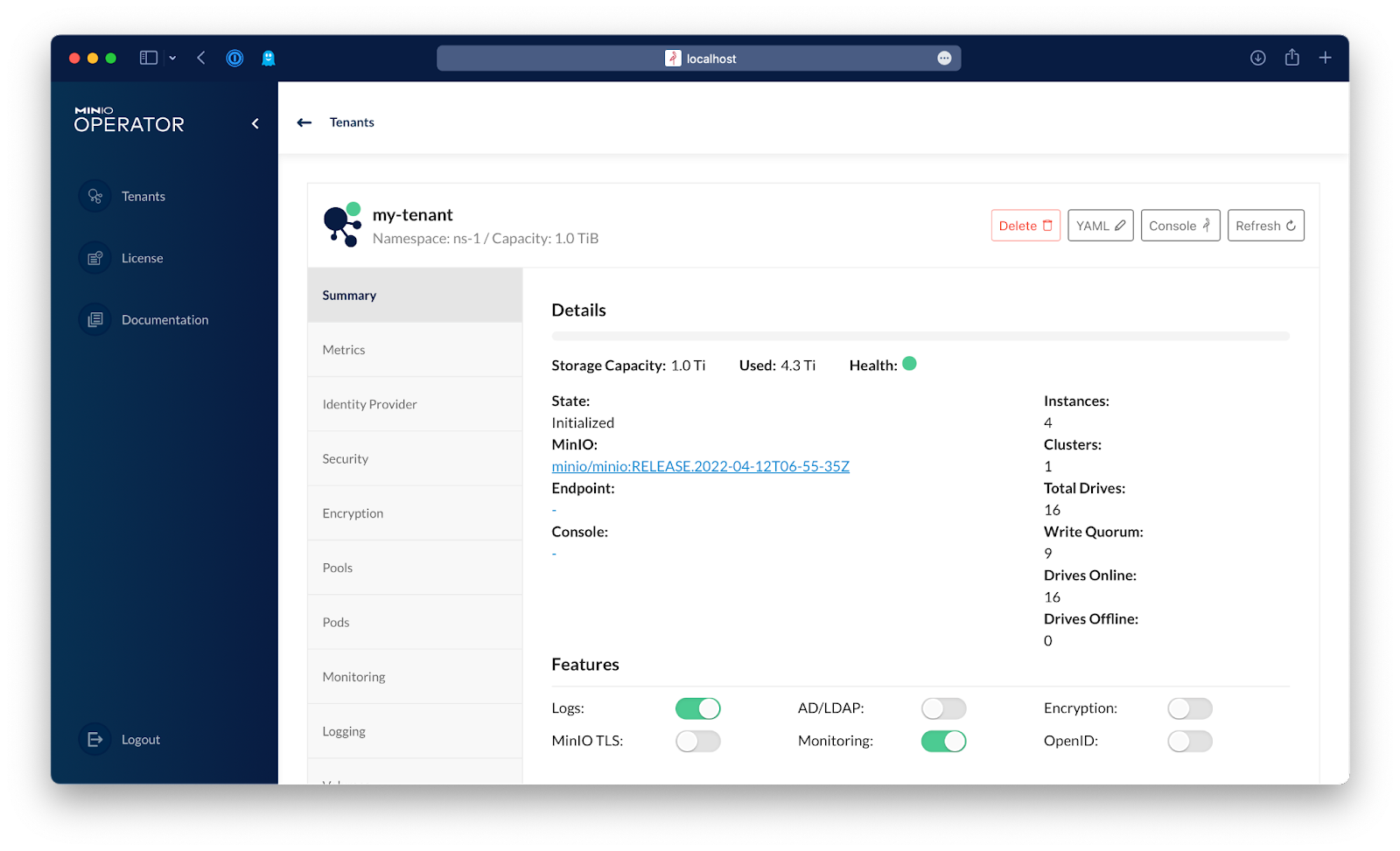
From this view, you can see the mlpipeline bucket. Click browse to see its contents.
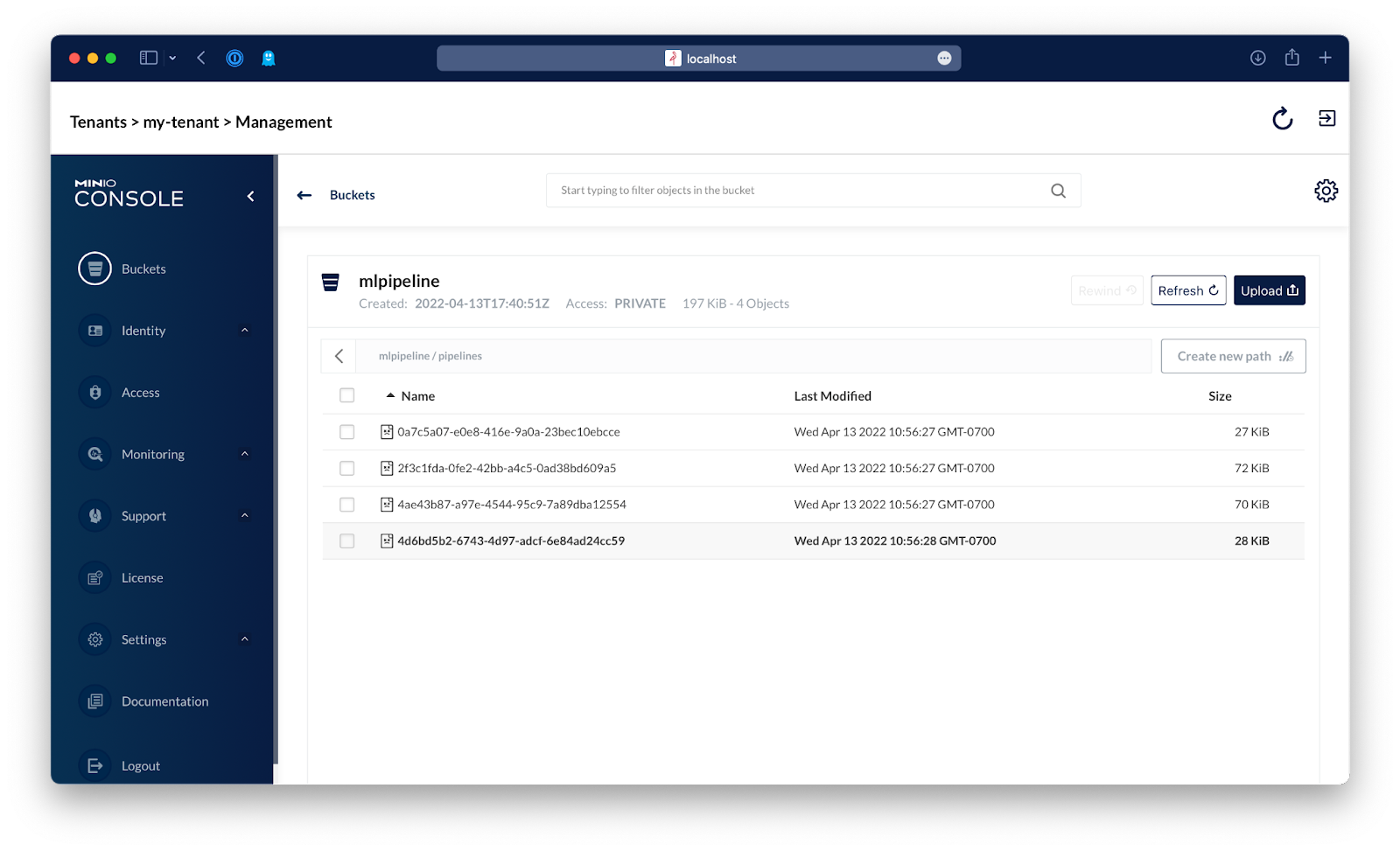
You'll see the existing demo pipelines have been copied over.
Now let's go into Kubeflow and run some pipelines, you can use port forwarding to expose the Kubeflow central dashboard:
Then in your browser go to http://localhost:8080.
Login with the default credentials for this example setup:
Email Address: user@example.com
Password: 12341234
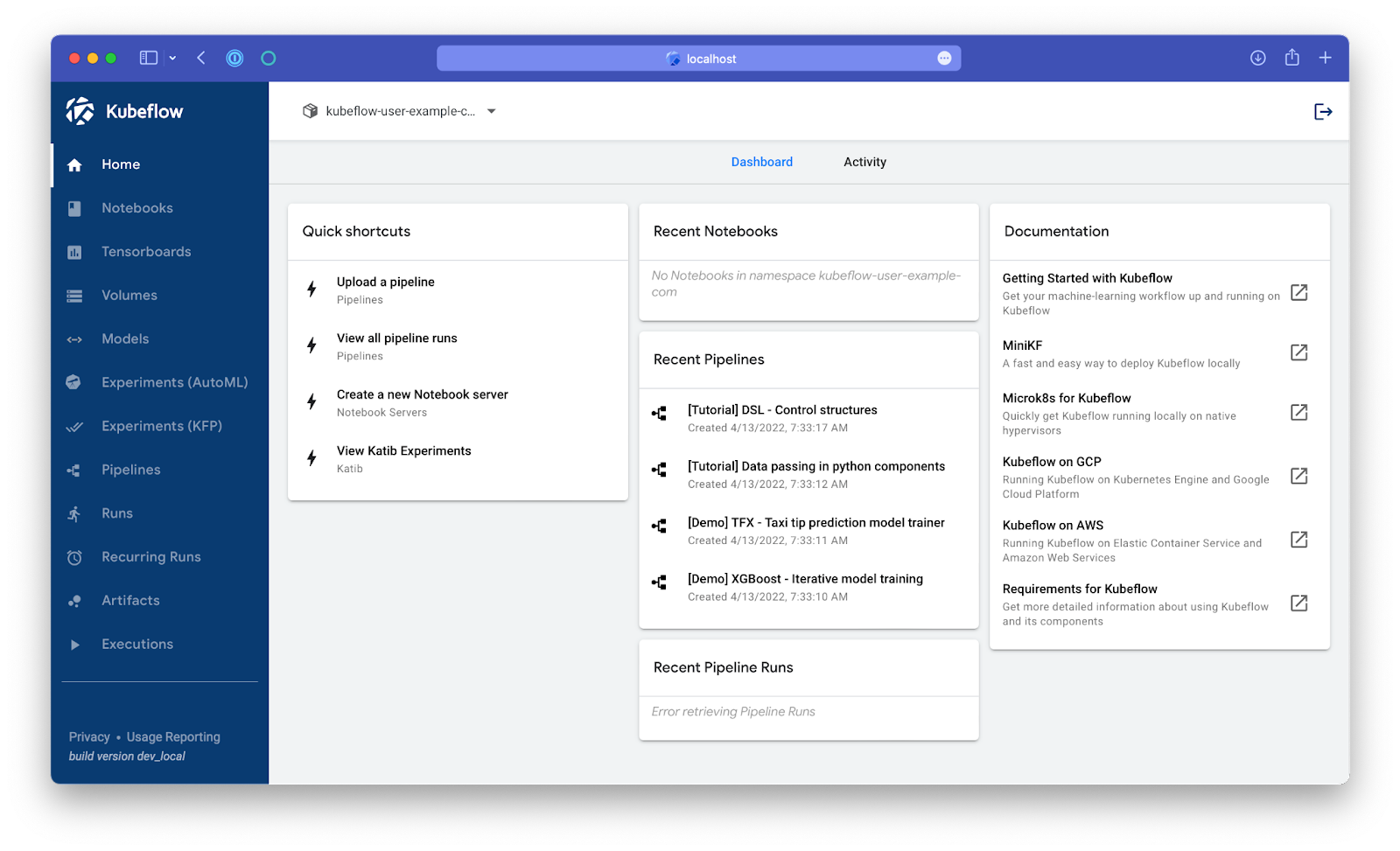
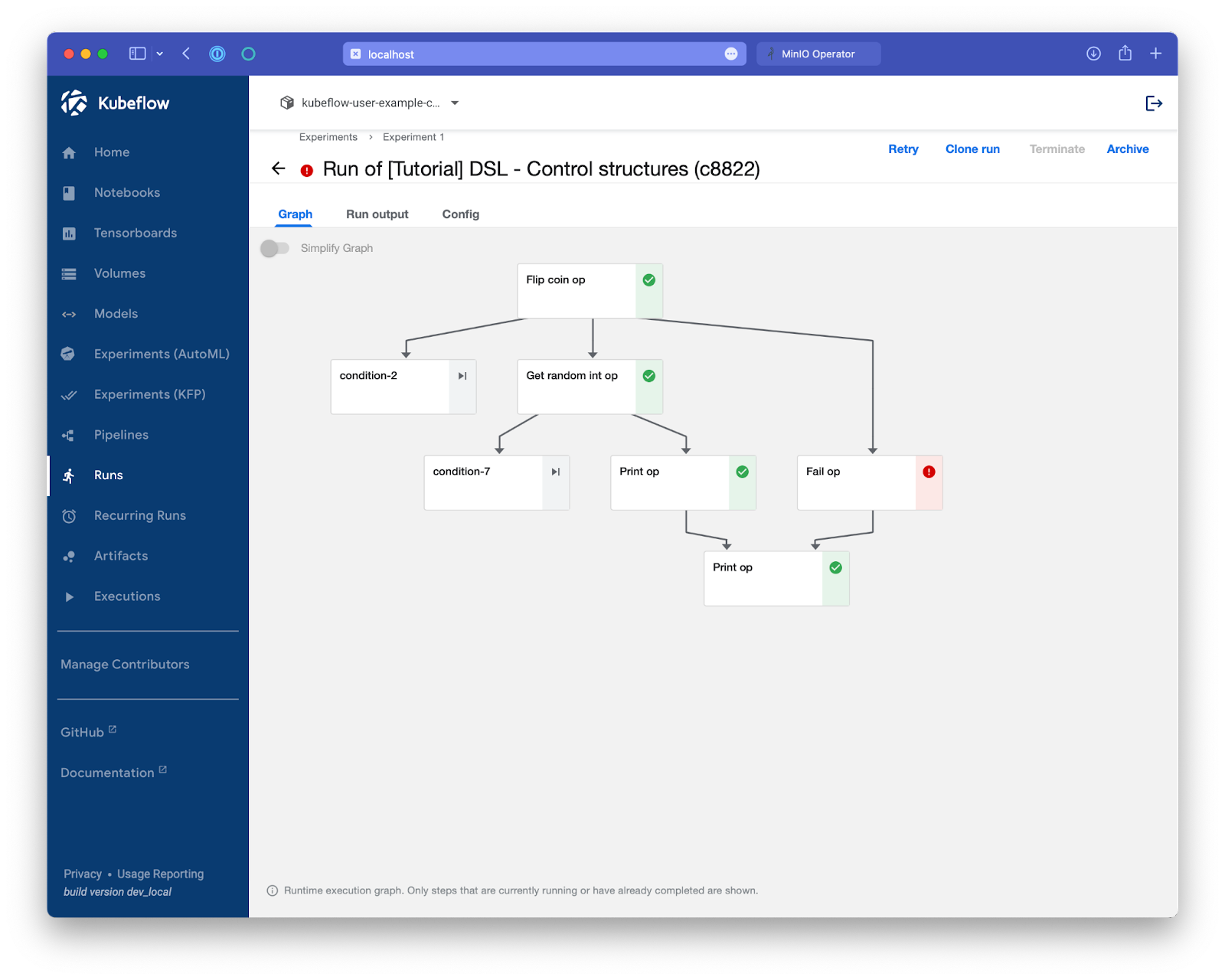
Then go to the Pipelines menu in the left menu bar. We’re going to run the most basic pipeline, "[Tutorial] DSL - Control structures":
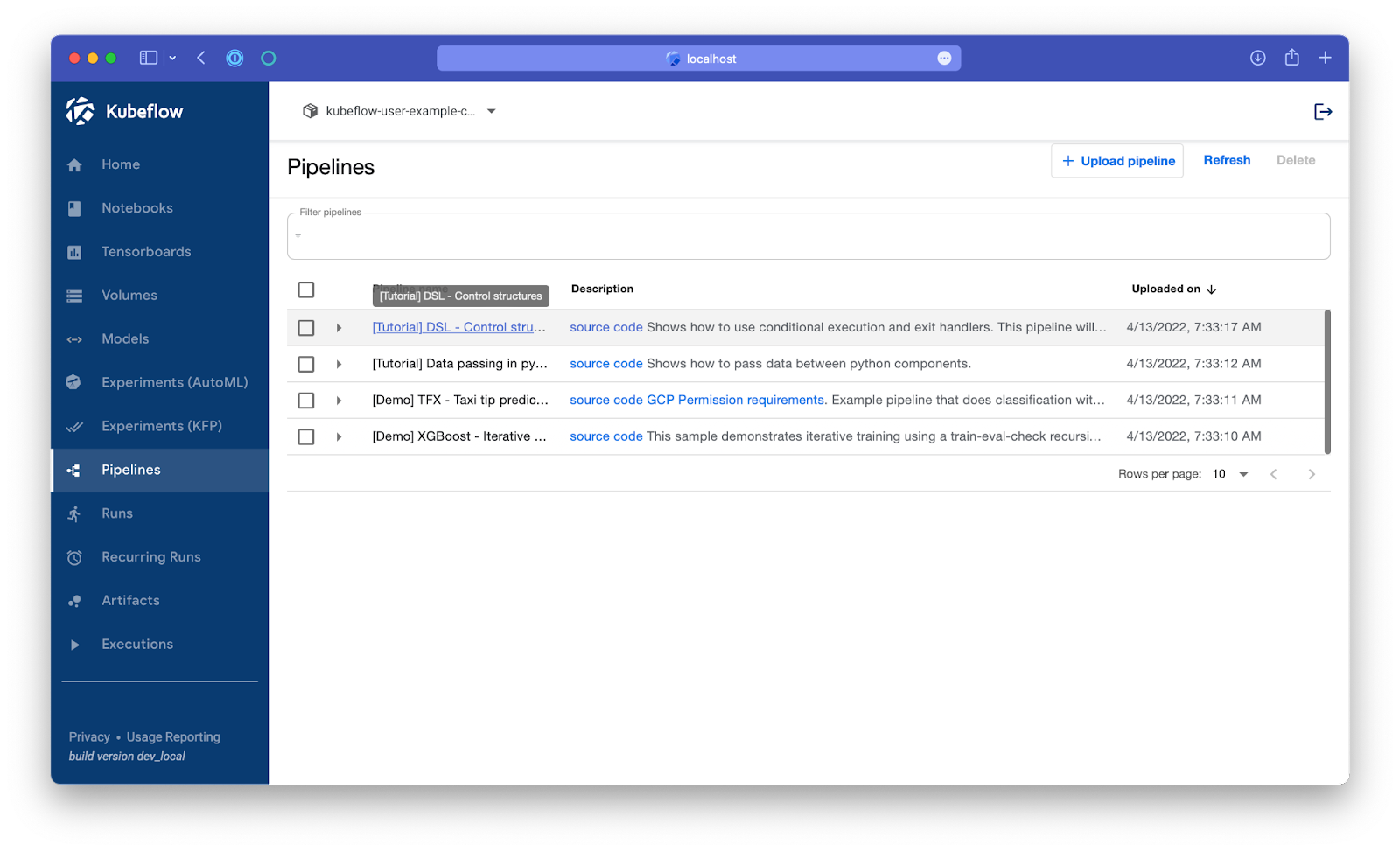
Click on the pipeline’s name.
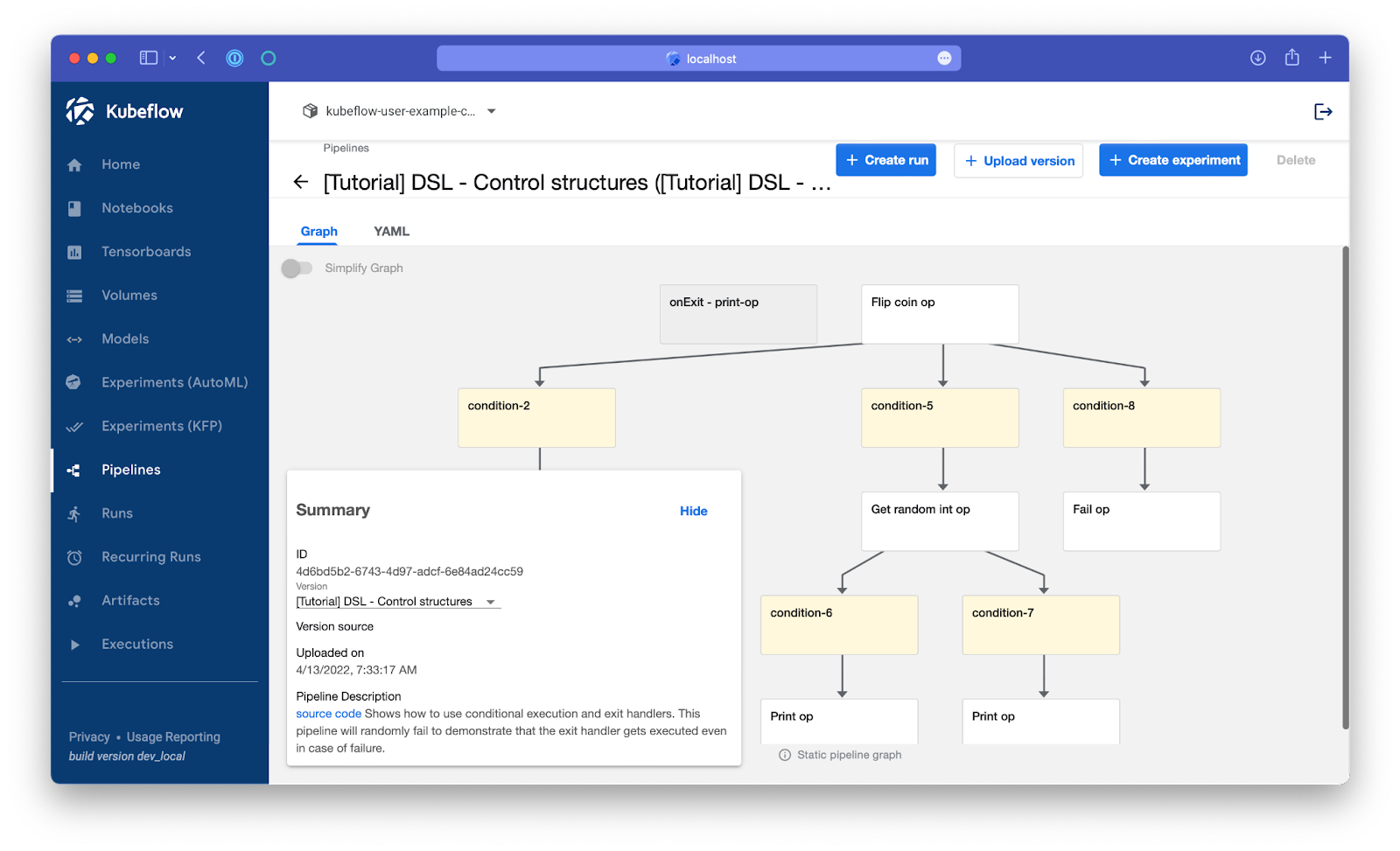
From here, click Create Experiment on the top right. This will create a new experiment since it's the first time it is running, but in subsequently you can re-use this experiment.
And click on Start:
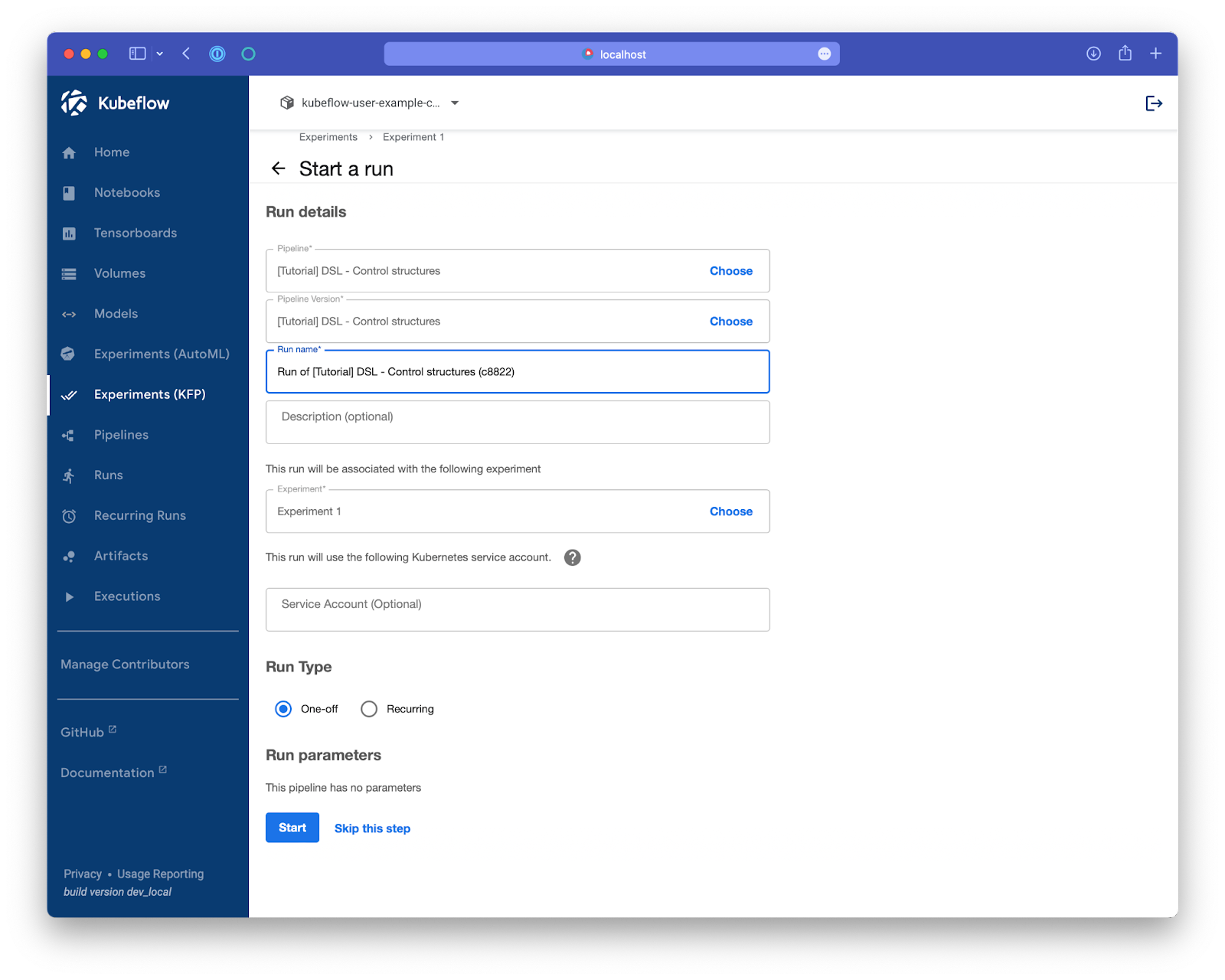
After the run is complete, explore the pipeline to verify that it ran successfully.
Kubeflow and MinIO for Multi-Cloud Machine Learning
This blog post taught you how to replace the MinIO that ships with Kubeflow with the MinIO Operator. You’re now prepared to take your Kubeflow use to the next level and back it with Kubernetes-native high performance and highly scalable MinIO object storage.
When it comes to Machine Learning pipelines and infrastructure, use MinIO's Lifecycle Management to deploy tenants backed by super fast NVMe drives as your hot tier for fast training and model serving, and also set up a warm tier backed up by SSDs or HDDs for your aging datasets. MinIO does this transparently without disrupting your applications.Tiering is configured on a per-bucket basis or even for a single prefix within a bucket, providing granular control over which data gets moved to a slower tier.
With MinIO's Active-Active Replication, you can configure buckets serving production machine learning models to be replicated instantly across multiple sites for disaster recovery and fast failover.
I truly hope this blog post helped you discover how easy it is to set up MinIO object storage on Kubernetes and to consume it with Kubeflow. If you have any questions, please join our Slack community and ask!






