Hyper-Scale Machine Learning with MinIO and TensorFlow

We are living in a transformative era defined by information and AI. Massive amounts of data are generated and collected every day to feed these voracious, state-of-the-art, AI/ML algorithms. The more data, the better the outcomes.
One of the frameworks that has emerged as the lead industry standards is Google's TensorFlow. Highly versatile, one can get started quickly and write simple models with their Keras framework. If you seek a more advanced approach TensorFlow also allows you to construct your own machine learning models using low level APIs. No matter what strategy you choose, TensorFlow will make sure that your algorithm gets optimized for whatever infrastructure you select for your algorithms - whether it's CPU's, GPU's or TPU's.
As datasets become too large to fit into memory or local disk, AI/ML pipelines now have the requirement to load data from an external data source. Take for example the ImageNet dataset with its 14 Million Images with an estimated storage size of 1.31TB. This dataset cannot be fit into memory nor on any machine local storage drive. These challenges are further complicated if your pipelines are running inside a stateless environment such a Kubernetes (which is increasingly the norm).
The emerging standard for this problem is to employ high performance object storage in the design of your AI/ML pipelines. MinIO is the leader in this space and has published a number of benchmarks that speak to its throughput capabilities. In this post, we will cover how to leverage MinIO for your TensorFlow projects.
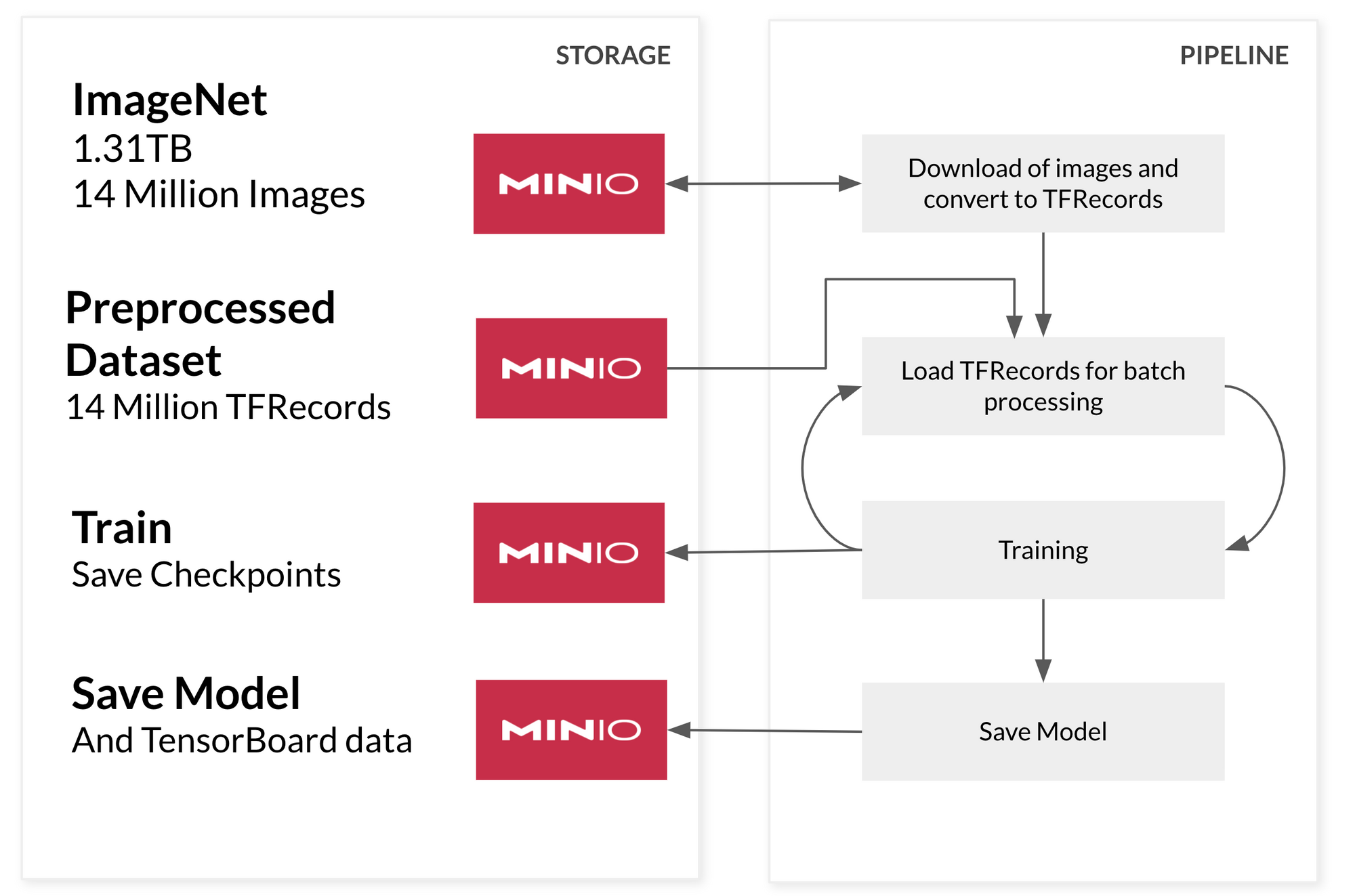
A Four Stage Hyper-Scale Data Pipeline
To build a hyper-scale pipeline we will have each stage of the pipeline read from MinIO. In this example we are going to build four stages of a machine learning pipeline. This architecture will load the desired data on-demand from MinIO.
First, we are going to preprocess our dataset and encode it in a format that TensorFlow can quickly digest. This format is the tf.TFRecord, which is a type of binary encoding for our data. We are taking this step because we do not want to waste time processing the data during the training as we are planning on loading each batch of training directly from MinIO as it's needed. If the data is pre-processed before we feed it into the model training we save a significant amount of time. Ideally, we create pre-processed chunks of data that group a good chunk of records - at least 100-200MB in size.
To speed up the data-loading and training stages we are going to leverage the excellent tf.data api. This API is designed to efficiently load data during the training/validation of our model. It prepares the next batch of data as the current one is being processed by the model. The advantage of this approach is that it ensures efficient utilization of expensive GPUs or TPUs which cannot sit idle due to slow loading data. MinIO does not encounter this problem - it can saturate 100Gbps network with a few NVMe drives or also with Hard Disk Drives ensuring the pipeline is crunching data as fast as the hardware allows.
During training we want to make sure we store the training checkpoints of our model as well as TensorBoard histograms. The checkpoints are useful in case the training gets interrupted and we want to resume the training or if we get more data and want to keep training our model with the new data and the TensorBoard histograms let us see how the training is going as it happens. TensorFlow supports writing both of these directly to MinIO.
A quick side note. When the model is complete we will save it to MinIO as well - allowing us to serve it using TensorFlow Serving - but that's a post for some other time.
Building the Pipeline
For our hyper-scale pipeline we are going to use a dataset that can easily fit into your local computer so you can follow along. The Large Movie Review Dataset from Stanford is great since it has a large number of samples (25,000 for training and 25,000 for testing) so we are going to build a sentiment analysis model that will tell us whether a movie review is positive or negative. Keep in mind that each step can be applied to any larger dataset. The advantage of this dataset is that you can try on your own computer. Let's get started!
Download the dataset and upload it to MinIO using MinIO Client
curl -O http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
mc mb myminio/datasets
mc cp aclImdb_v1.tar.gz myminio/datasets/Let's start by declaring some configurations for our pipeline, such as batch size, location of our dataset and a fixed random seed so we can run this pipeline again and again and get the same results.
random_seed = 44
batch_size = 128
datasets_bucket = 'datasets'
preprocessed_data_folder = 'preprocessed-data'
tf_record_file_size = 500
# Set the random seed
tf.random.set_seed(random_seed)
# How to access MinIO
minio_address = 'localhost:9000'
minio_access_key = 'minioadmin'
minio_secret_key = 'minioadmin'We are going to download our dataset from MinIO using minio-py
minioClient = Minio(minio_address,
access_key=minio_access_key,
secret_key=minio_secret_key,
secure=False)
try:
minioClient.fget_object(
datasets_bucket,
'aclImdb_v1.tar.gz',
'/tmp/dataset.tar.gz')
except ResponseError as err:
print(err)Now let's uncompress the dataset to a temporary folder (/tmp/dataset) to preprocess our data
extract_folder = f'/tmp/{datasets_bucket}/'
with tarfile.open("/tmp/dataset.tar.gz", "r:gz") as tar:
tar.extractall(path=extract_folder)Pre-Processing
Due to the structure of the dataset we are going to read from four folders, initially test and train which hold 25,000 examples each, then, in each of those folders we have 12,500 of each label pos for positive comments and neg for negative comments. From these four folders, we are going to store all samples into two variables, train and test. If we were preprocessing a dataset that couldn't fit in the local machine we could simply load segments of the object, one at a time and process them as well.
train = []
test = []
dirs_to_read = [
'aclImdb/train/pos',
'aclImdb/train/neg',
'aclImdb/test/pos',
'aclImdb/test/neg',
]
for dir_name in dirs_to_read:
parts = dir_name.split("/")
dataset = parts[1]
label = parts[2]
for filename in os.listdir(os.path.join(extract_folder,dir_name)):
with open(os.path.join(extract_folder,dir_name,filename),'r') as f:
content = f.read()
if dataset == "train":
train.append({
"text":content,
"label":label
})
elif dataset == "test":
test.append({
"text":content,
"label":label
})We will then shuffle the dataset so we don't introduce bias into the training by providing 12,500 consecutive positive examples followed by 12,500 consecutive negative examples. Our model would have a hard time generalizing that. By shuffling the data the model will get to see and learn from both positive and negative examples at the same time.
random.Random(random_seed).shuffle(train)
random.Random(random_seed).shuffle(test)Since we are dealing with text we need to turn the text to a vector representation that accurately depicts the meanings of the sentence. If we were dealing with images we would resize the images and turn them into vector representations having each pixel be a value of the resized image.
For text, however, we have a bigger challenge since a word doesn't really have a numerical representation. This is where embeddings are useful. An embedding is a vector representation of some text, in this case we are going to represent the whole review as a single vector of 512 dimensions. Instead of doing the pre-processing of text manually (tokenizing, building vocabulary and training an embeddings layer) we are going to leverage an existing model called USE (Universal Sentence Encoder) to encode sentences into vectors so we can continue with our example. This is one of the wonders of deep learning, the ability to re-use different models alongside yours. Here we use TensorFlow Hub and we are going to load the latest USE model.
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder-large/5")Since it would be too much to create the embeddings of 25,000 sentences and keep that in memory, we are going to slice our datasets into chunks of 500.
To store our data into a TFRecord we need to encode the features as tf.train.Feature. We are going to store the label of our data as list of tf.int64 and our Movie Review as a list of floats since after we encode the sentence using USE we will end-up with a embedding of 512 dimensions
def _embedded_sentence_feature(value):
return tf.train.Feature(float_list=tf.train.FloatList(value=value))
def _label_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def encode_label(label):
if label == "pos":
return tf.constant([1,0])
elif label == "neg":
return tf.constant([0,1])
# This will take the label and the embedded sentence and encode it as a tf.TFRecord
def serialize_example(label, sentence_tensor):
feature = {
'sentence': _embedded_sentence_feature(sentence_tensor[0]),
'label': _label_feature(label),
}
example_proto = tf.train.Example(features=tf.train.Features(feature=feature))
return example_proto
def process_examples(records,prefix=""):
starttime = timeit.default_timer()
total_training = len(records)
print(f"Total of {total_training} elements")
total_batches = math.floor(total_training / tf_record_file_size)
if total_training % tf_record_file_size != 0:
total_batches += 1
print(f"Total of {total_batches} files of {tf_record_file_size} records")
counter = 0
file_counter = 0
buffer = []
file_list = []
for i in range(len(records)):
counter += 1
sentence_embedding = embed([records[i]['text']])
label_encoded = encode_label(records[i]['label'])
record = serialize_example(label_encoded, sentence_embedding)
buffer.append(record)
if counter >= tf_record_file_size:
print(f"Records in buffer {len(buffer)}")
# save this buffer of examples as a file to MinIO
counter = 0
file_counter+=1
file_name = f"{prefix}_file{file_counter}.tfrecord"
with open(file_name,'w+') as f:
with tf.io.TFRecordWriter(f.name,options="GZIP") as writer:
for example in buffer:
writer.write(example.SerializeToString())
try:
minioClient.fput_object(datasets_bucket, f"{preprocessed_data_folder}/{file_name}", file_name)
except ResponseError as err:
print(err)
file_list.append(file_name)
os.remove(file_name)
buffer=[]
print(f"Done with chunk {file_counter}/{total_batches} - {timeit.default_timer() - starttime}")
if len(buffer) > 0:
file_counter+=1
file_name = f"file{file_counter}.tfrecord"
with open(file_name,'w+') as f:
with tf.io.TFRecordWriter(f.name) as writer:
for example in buffer:
writer.write(example.SerializeToString())
try:
minioClient.fput_object(datasets_bucket, f"{preprocessed_data_folder}/{file_name}", file_name)
except ResponseError as err:
print(err)
file_list.append(file_name)
os.remove(file_name)
buffer=[]
print("Total time preprocessing is :", timeit.default_timer() - starttime)
return file_list
process_examples(train,prefix="train")
process_examples(test,prefix="test")
print("Done Preprocessing data!")At this point we are done preprocessing our data. We have a set of .tfrecord files stored on our bucket. We will now feed that to the model allowing it to consume and train concurrently.
Training
We are going to get a list of files (training data) from MinIO. Technically the pre-processing stage and the training stage could be completely decoupled so it's a good idea to list the file chunks we have in bucket.
# List all training tfrecord files
objects = minioClient.list_objects_v2(datasets_bucket, prefix=f"{preprocessed_data_folder}/train")
training_files_list = []
for obj in objects:
training_files_list.append(obj.object_name)
# List all testing tfrecord files
objects = minioClient.list_objects_v2(datasets_bucket, prefix=f"{preprocessed_data_folder}/test")
testing_files_list = []
for obj in objects:
testing_files_list.append(obj.object_name)In order to have TensorFlow connect to MinIO we are going to tell it the location and connection details of our MinIO instance.
os.environ['AWS_ACCESS_KEY_ID'] = minio_access_key
os.environ['AWS_SECRET_ACCESS_KEY'] = minio_secret_key
os.environ['AWS_REGION'] = "us-east-1"
os.environ['S3_ENDPOINT'] = minio_address
os.environ['S3_USE_HTTPS'] = "0"
os.environ['S3_VERIFY_SSL'] = "0"
Now let us create a tf.data.Dataset that loads records from our files on MinIO as they become needed. To do that we are going to take the list of files we have and format them in a way that references the location of the actual objects. We will do this for the testing dataset as well.
all_training_filenames = [f"s3://datasets/{f}" for f in training_files_list]
testing_filenames = [f"s3://datasets/{f}" for f in testing_files_list]The following step is optional, but I recommend it. I am going to split my training dataset into two sets, 90% of the data for training and 10% of the data for validation, the model won't learn on the validation data but it will help the model train better.
total_train_data_files = math.floor(len(all_training_filenames)*0.9)
if total_train_data_files == len(all_training_filenames):
total_train_data_files -= 1
training_files = all_training_filenames[0:total_train_data_files]
validation_files = all_training_filenames[total_train_data_files:]Now let's create the tf.data datasets:
AUTO = tf.data.experimental.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
dataset = tf.data.TFRecordDataset(training_files,num_parallel_reads=AUTO,compression_type="GZIP")
dataset = dataset.with_options(ignore_order)
validation = tf.data.TFRecordDataset(validation_files,num_parallel_reads=AUTO,compression_type="GZIP")
validation = validation.with_options(ignore_order)
testing_dataset = tf.data.TFRecordDataset(testing_filenames,num_parallel_reads=AUTO,compression_type="GZIP")
testing_dataset = testing_dataset.with_options(ignore_order)In order to decode our TFRecord encoded files we are going to need a decoding function that does the exact opposite of our serialize_example function. Since the data coming out of the TFRecord has shape (512,) and (2,) respectively, we are going to reshape it as well since that's the format our model will be expecting to receive.
def decode_fn(record_bytes):
schema = {
"label": tf.io.FixedLenFeature([2], dtype=tf.int64),
"sentence": tf.io.FixedLenFeature([512], dtype=tf.float32),
}
tf_example = tf.io.parse_single_example(record_bytes,schema)
new_shape = tf.reshape(tf_example['sentence'],[1,512])
label = tf.reshape(tf_example['label'],[1,2])
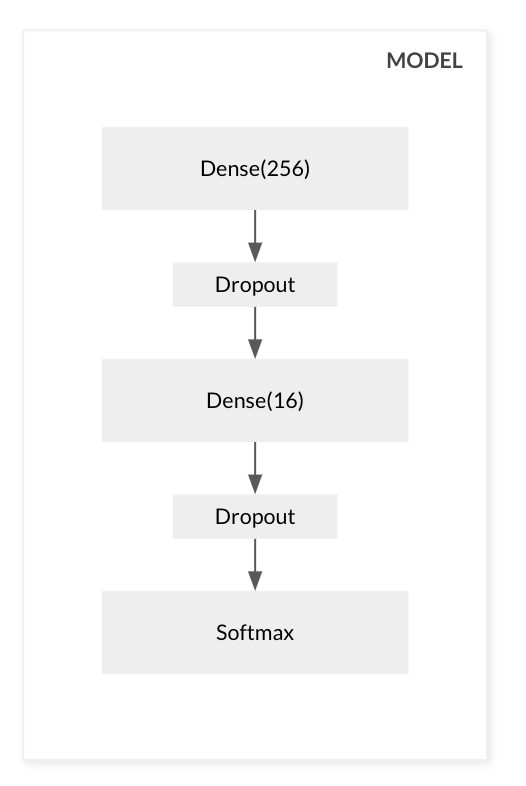
return new_shape,labelLet's build our model, nothing fancy, I'm just going to use a couple of Dense layers with a softmax activation at the end. We are trying to predict whether the input is positive or negative so we are going to get probabilities of the likelihood of each.
model = keras.Sequential()
model.add(
keras.layers.Dense(
units=256,
input_shape=(1,512 ),
activation='relu'
)
)
model.add(
keras.layers.Dropout(rate=0.5)
)
model.add(
keras.layers.Dense(
units=16,
activation='relu'
)
)
model.add(
keras.layers.Dropout(rate=0.5)
)
model.add(keras.layers.Dense(2, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
Let's prepare our datasets for the training stage by having them repeat themselves a little and batch 128 items at a time
mapped_ds = dataset.map(decode_fn)
mapped_ds = mapped_ds.repeat(5)
mapped_ds = mapped_ds.batch(128)
mapped_validation = validation.map(decode_fn)
mapped_validation = mapped_validation.repeat(5)
mapped_validation = mapped_validation.batch(128)
testing_mapped_ds = testing_dataset.map(decode_fn)
testing_mapped_ds = testing_mapped_ds.repeat(5)
testing_mapped_ds = testing_mapped_ds.batch(128)As we train we would like to store checkpoints of our model in case the training gets interrupted and we would like to resume where we left off. To do this we will use the keras callback tf.keras.callbacks.ModelCheckpoint to have TensorFlow save the checkpoint to MinIO after every epoch.
checkpoint_path = f"s3://{datasets_bucket}/checkpoints/cp.ckpt"
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,
verbose=1)We also want to save the TensorBoard histograms so we are going to add a callback to store those in our bucket under the logs/imdb/ prefix. We are identifying this run with a model_note and the current time, this is so we can tell apart different instances of training.
model_note="256-input"
logdir = f"s3://{datasets_bucket}/logs/imdb/{model_note}-" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=logdir)Finally we will train the model:
history = model.fit(
mapped_ds,
epochs=10,
callbacks=[cp_callback, tensorboard_callback],
validation_data=mapped_validation
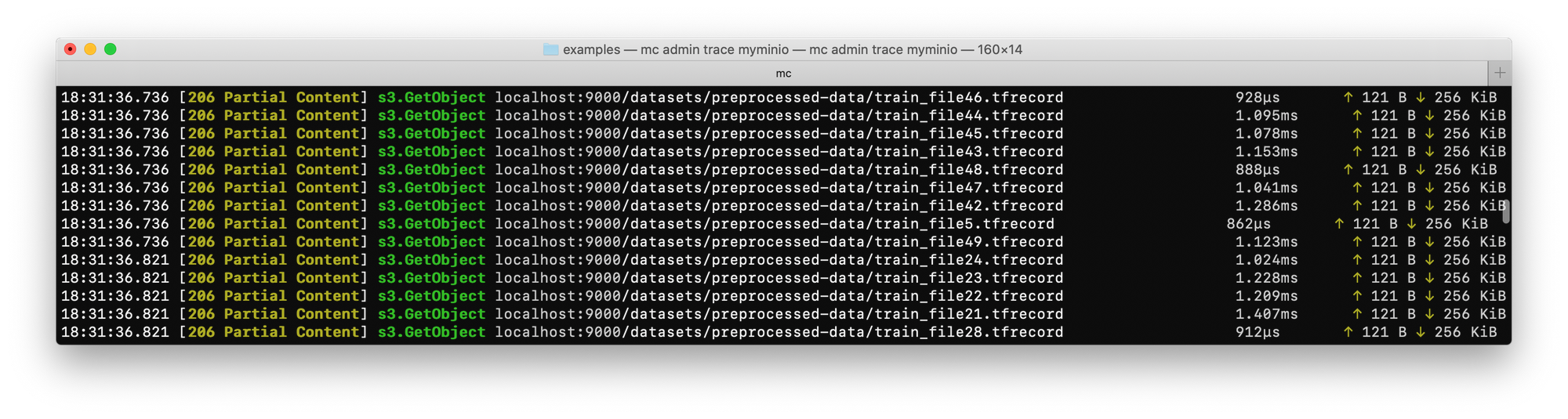
)If we run mc admin trace myminio we can see TensorFlow reading the data straight from MinIO, but only the parts it needs:
Now that we have our model, we want to save it to MinIO:
model.save(f"s3://{datasets_bucket}/imdb_sentiment_analysis") Let's test our model and see how it performs:
testing = model.evaluate(testing_mapped_ds)This returns 85.63% accuracy, not state of the art, but also not bad for such a simple example.
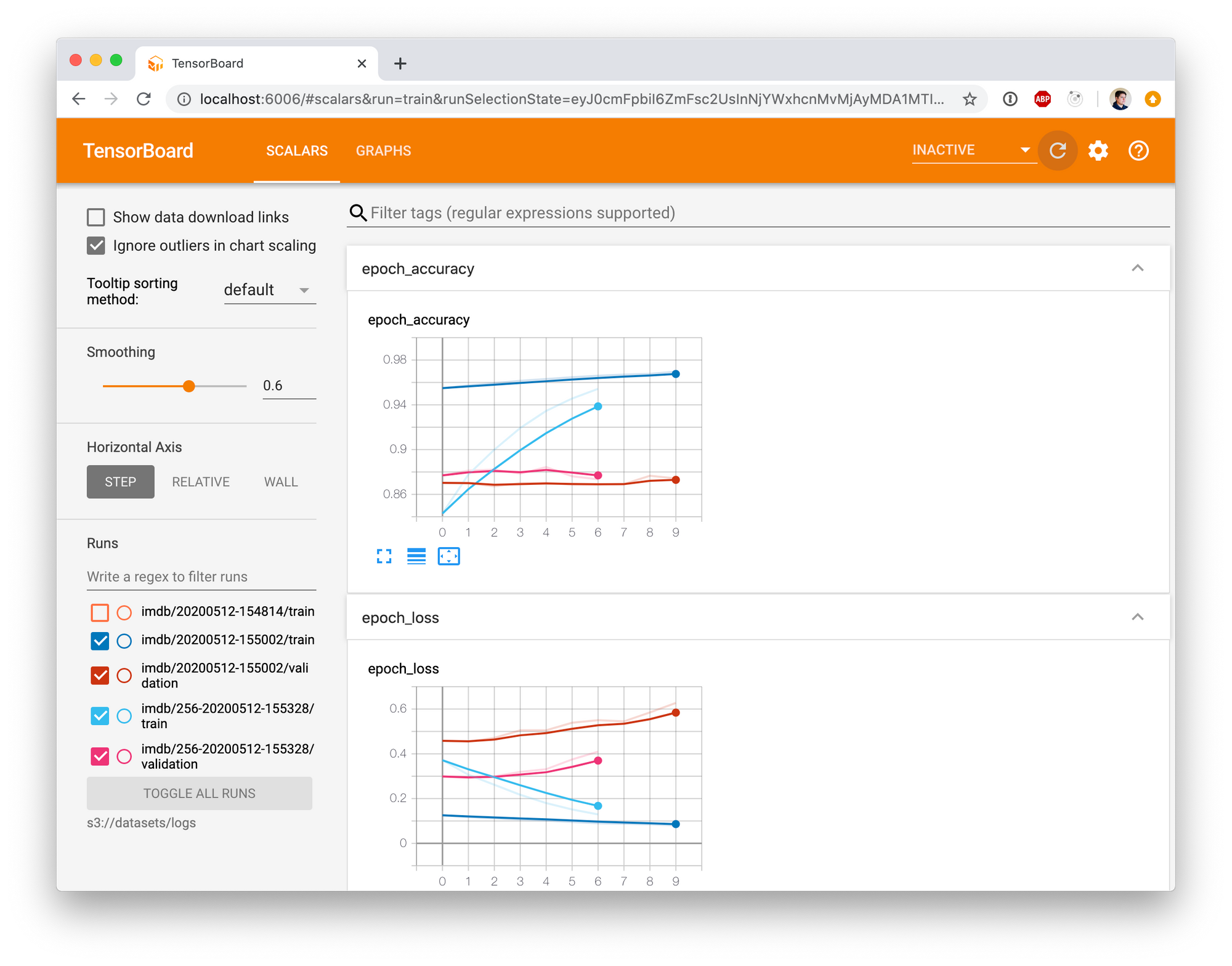
Let's run TensorBoard to explore our models loading the data straight from MinIO
AWS_ACCESS_KEY_ID=minioadmin AWS_SECRET_ACCESS_KEY=minioadmin AWS_REGION=us-east-1 S3_ENDPOINT=localhost:9000 S3_USE_HTTPS=0 S3_VERIFY_SSL=0 tensorboard --logdir s3://datasets/logsThen go to http://localhost:6006 on your browser
We can play with our model and see if it works
samples = [
"This movie sucks",
"This was extremely good, I loved it.",
"great acting",
"terrible acting",
"pure kahoot",
"This is not a good movie",
]
sample_embedded = embed(samples)
res = model.predict(sample_embedded)
for s in range(len(samples)):
if res[s][0] > res[s][1]:
print(f"{samples[s]} - positive")
else:
print(f"{samples[s]} - negative")This returns the following output
This movie sucks - negative
This was extremely good, I loved it. - positive
great acting - positive
terrible acting - negative
pure kahoot - positive
This is not a good movie - negativeConclusion
As demonstrated, you can build large scale AI/ML pipelines that can rely entirely on MinIO. This is a function of both MinIO's performance characteristics but also its ability to seamlessly scale to Petabytes and Exabytes of data. By separating storage and compute, one can build a framework that is not dependent on local resources - allowing you to run them on a container inside Kubernetes. This adds considerable flexibility.
You can see how TensorFlow was able to load the data as it was needed and no customization was needed at all, it simply worked. Moreover this approach could be quickly extended to training by running TensorFlow in a distributed manner. This ensures there is very little data to shuffle over the network between training nodes as MinIO becomes the sole source of that data.
The code for this post is available on Github at : https://github.com/dvaldivia/hyper-scale-tensorflow-with-minio






