Interactive SQL query with Apache Presto on MinIO Cloud Storage
Data analysis and querying techniques offer insight into what users want, how they behave and much more. As growing volumes of data get into enterprise clouds, analysis technology is evolving to help enterprise make sense of this data.
The data analysis field itself is not new; there have been various tools and technologies in use for quite some time now. However as the data size reaches all-time highs, efficiency, responsiveness and ease of use of these tools are more critical than ever.
As enterprises move to object storage based private clouds that integrate with applications directly, it makes sense for the analysis technology to plugin to the object storage as well. Not only does this make the process efficient, it is easy to maintain as well.
In this post, we’ll talk about Presto — a fast, interactive, open source distributed SQL query engine for running analytic queries against data sources of all sizes ranging from GBs to PBs. Presto was developed at Facebook, in 2012 and open-sourced under Apache License V2 in 2013. Starburst, a company formed by the leading contributors to the project, offers enterprise support for Presto. Their engineers recently wrote a blog post about querying object store data lakes with Presto.
Presto can connect to various data sources with its Connectors. We’ll take a special look at the Hive connector, which lets Presto talk to Minio server. With Presto querying data from Minio server in your Private cloud — you have a secure and efficient data storage & processing pipeline.
Use cases
With Presto running queries on Minio server, multiple query users consume the same data from Minio, while applications producing data write to Minio. This leads to effective separation of compute and storage layers and hence flexible scaling options.
Such deployments can be then used for variety of use cases. For example
- General ad hoc interactive queries to understand patterns before getting into deep querying.
- Analyzing A/B tests results to understand user behaviour from test data.
- Train deep learning models from user data.
Why Minio
Minio is a highly scaleable and performant object storage server. It can be deployed on a wide variety of platforms and can plug in directly to any S3 speaking application. With features like SSE-C, Federation, Erasure coding, and others, Minio offers enterprise class object storage solution.
This makes Minio an ideal choice for private cloud storage requirements.
Why Presto
Presto allows querying data where it lives, including Hive, Cassandra, relational databases or even proprietary data stores. Here are some advantages:
- Separate compute from storage, and scale independently.
- A single Presto query can combine data from multiple sources, allowing for analytics across entire organizations.
- With its interactiveness, Presto is targeted at use cases that need response times ranging from sub-second to minutes.
- Presto was developed by Facebook for interactive queries against several internal data stores, including their 300PB data warehouse. Over 1,000 Facebook employees use Presto daily to run more than 30,000 queries that scan over a petabyte each per day in total.
- Other major Presto users include Netflix (using Presto for analyzing more than 10 PB data stored in AWS S3), AirBnb and Dropbox.
Comparison with Hive
- Speed: Presto is faster due to its optimized query engine and is best suited for interactive analysis. Hive, in comparison is slower.
- Flexible: Presto’s plug and play model for data sources enables easy joining and query across different data sources. Hive can plugin to Hadoop storage backends as well, but one at a time.
- ANSI SQL: Presto follows ANSI SQL which is the recognized SQL language and hence helps allow easy query migration without much overhead. Hive on the other hand has SQL like syntax which doesn’t strictly adhere to ANSI standards.
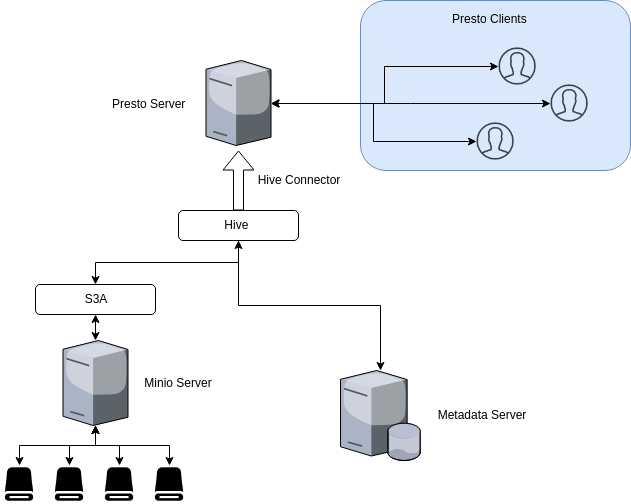
To connect Presto to Minio server, we’ll use the Presto Hive connector. Why Hive connector? Presto uses Hive metadata server for metadata and Hadoop s3a filesystem to fetch actual data from an S3 object store; both of these happen via the Hive connector.
Presto only uses the metadata and data via the Hive connector. It does not use HiveQL or any part of Hive’s execution environment.
To deploy Minio with Presto, we’ll need to setup Hive first. Only then can the Presto Hive connector use the hive metadata server.
- Start Minio server — Deploy Minio server as explained here. Then create a bucket
presto-minioon your Minio server. We’ll use this bucket later. - Setup Hadoop — Hadoop serves as the base platform for Hive. Setup Hadoop as follows:
- Download latest Hadoop release from the
2.8release line here. Unpack the contents in a directory, which we’ll refer to as the Hadoop installation directory. - Set environment variable
$HADOOP_HOMEto the Hadoop installation directory. Also updatePATHusing:export PATH=$PATH:$HADOOP_HOME/bin
export SPARK_DIST_CLASSPATH=$(hadoop classpath) - Open the file
$HADOOP_HOME/etc/hadoop/hdfs-site.xmland add the content below inside<configuration>tag.<property>
<name>fs.s3a.endpoint</name>
<description>AWS S3 endpoint to connect to.</description>
<value>http://127.0.0.1:9000</value>
</property><property>
<name>fs.s3a.access.key</name>
<description>AWS access key ID.</description>
<value>minio</value>
</property><property>
<name>fs.s3a.secret.key</name>
<description>AWS secret key.</description>
<value>minio123</value>
</property><property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
<description>Enable S3 path style access.</description>
</property><property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
<description>The implementation of S3A Filesystem</description>
</property>
Remember to use the actual values of Minio server endpoint and access/secret keys above.
3. Setup Hive —Install stable release of Hive by downloading relevant tarball from here.
- Unpack the contents in a directory, we’ll refer to this directory as the hive installation directory.
- Set environment variable
$HIVE_HOMEto the hive installation directory. - Add
$HIVE_HOME/binto yourPATH, using:
export PATH=$HIVE_HOME/bin:$PATH- Add the
jarfiles for Hadoop and aws-sdk-java to Hive library:mv ~/Downloads/hadoop-aws-2.8.2.jar $HIVE_HOME/lib
mv ~/Downloads/aws-java-sdk-1.11.234.jar $HIVE_HOME/lib - Use below HDFS commands to create
/tmpand/user/hive/warehouse(akahive.metastore.warehouse.dir) and set permissions withchmod g+wbefore creating a table in Hive.$HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse - Next step is to set up schema for Hive$HIVE_HOME/bin/schematool -dbType derby -initSchema
We’re using derby here as the metadata database for testing/demonstration purposes.
- Start the Hive server using$HIVE_HOME/bin/hiveserver2
By default it listens on port 10000.
- Finally, start the Hive metadata server using$HIVE_HOME/bin/hiveserver2 --service metastore
By default, metadata server listens on port 9083. We’ll use this as the metadata server for Presto.
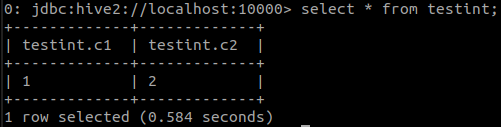
If you’re doing this for testing purposes and dont have real data on Hive to test, use the Hive2 client beeline to create a table, populate some data and then display contents using the select statement.
4. Setup Presto — Presto installation steps are explained on the documentation page. Follow these steps and create the relevant config files. We’ll now move to the step where we configure Presto Hive connector to talk to the Hive metastore we just started.
- Create
etc/catalog/hive.propertieswith the following contents to mount thehive-hadoop2connector as thehivecatalog:connector.name=hive-hadoop2
hive.metastore.uri=thrift://127.0.0.1:9083
hive.metastore-timeout=1m
hive.s3.aws-access-key=minio
hive.s3.aws-secret-key=minio123
hive.s3.endpoint=http://127.0.0.1:9000
hive.s3.path-style-access=true
hive.s3.ssl.enabled=false
Note the metastore URI pointing to the Hive metastore server created in the previous step.
- Start Presto server using
bin/launcher run. You should see a message like this on the console:
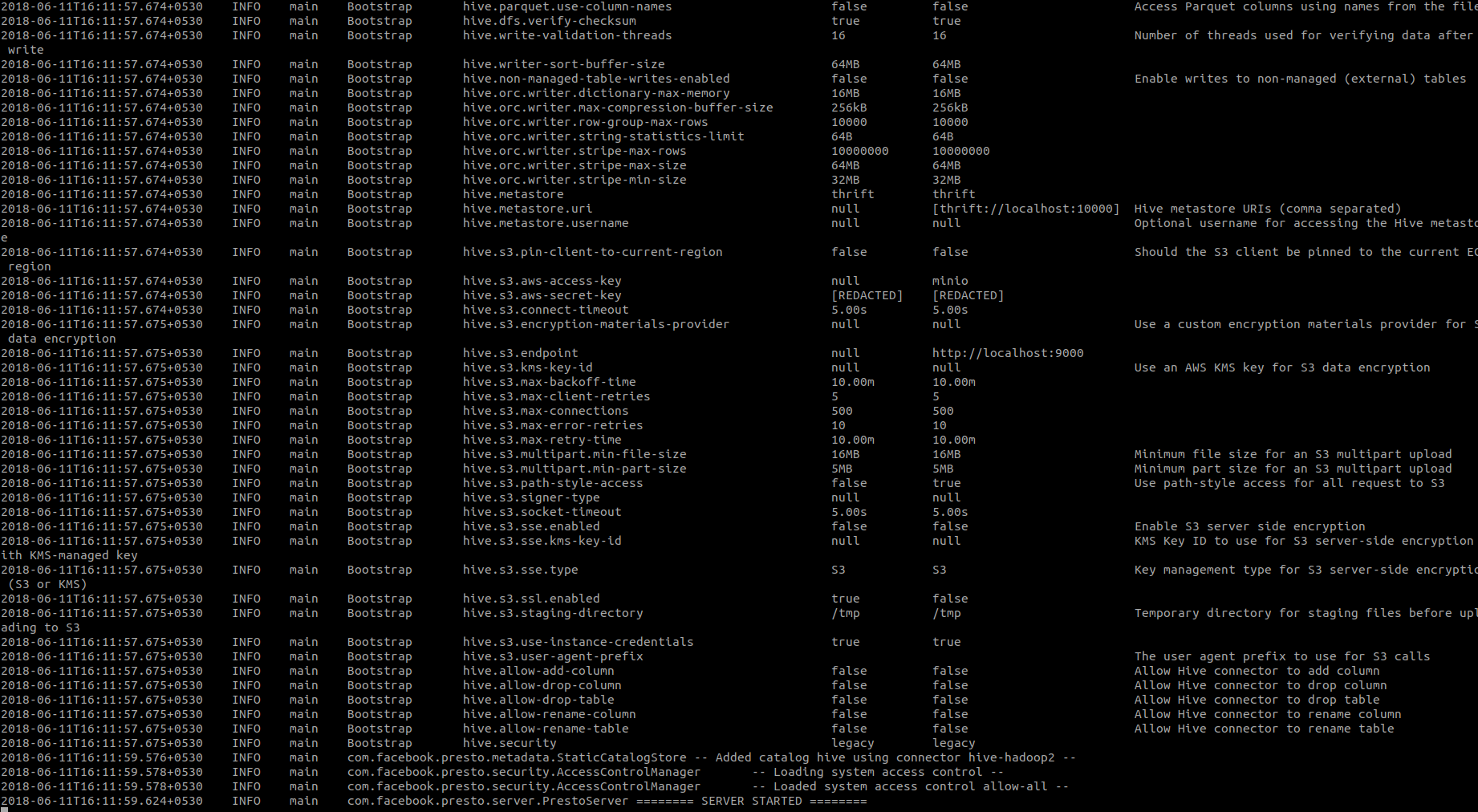
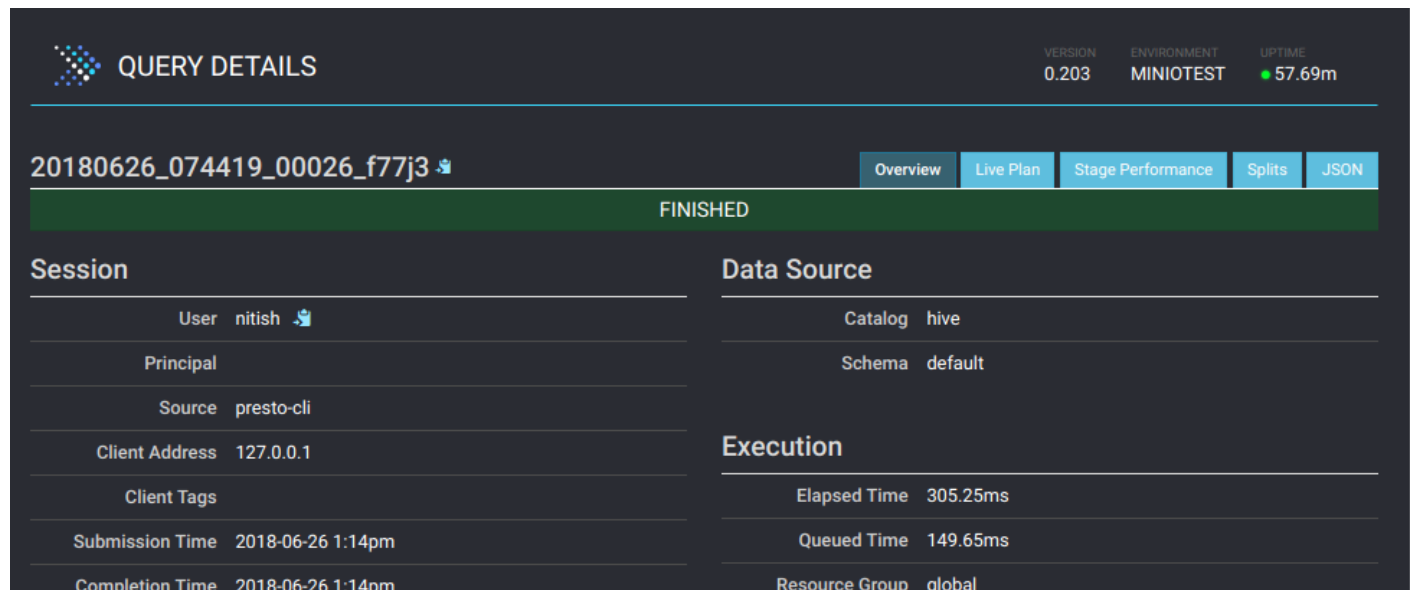
This mean Presto is now up and running. You can also access Presto UI at http://localhost:8080/ui/ via your browser.
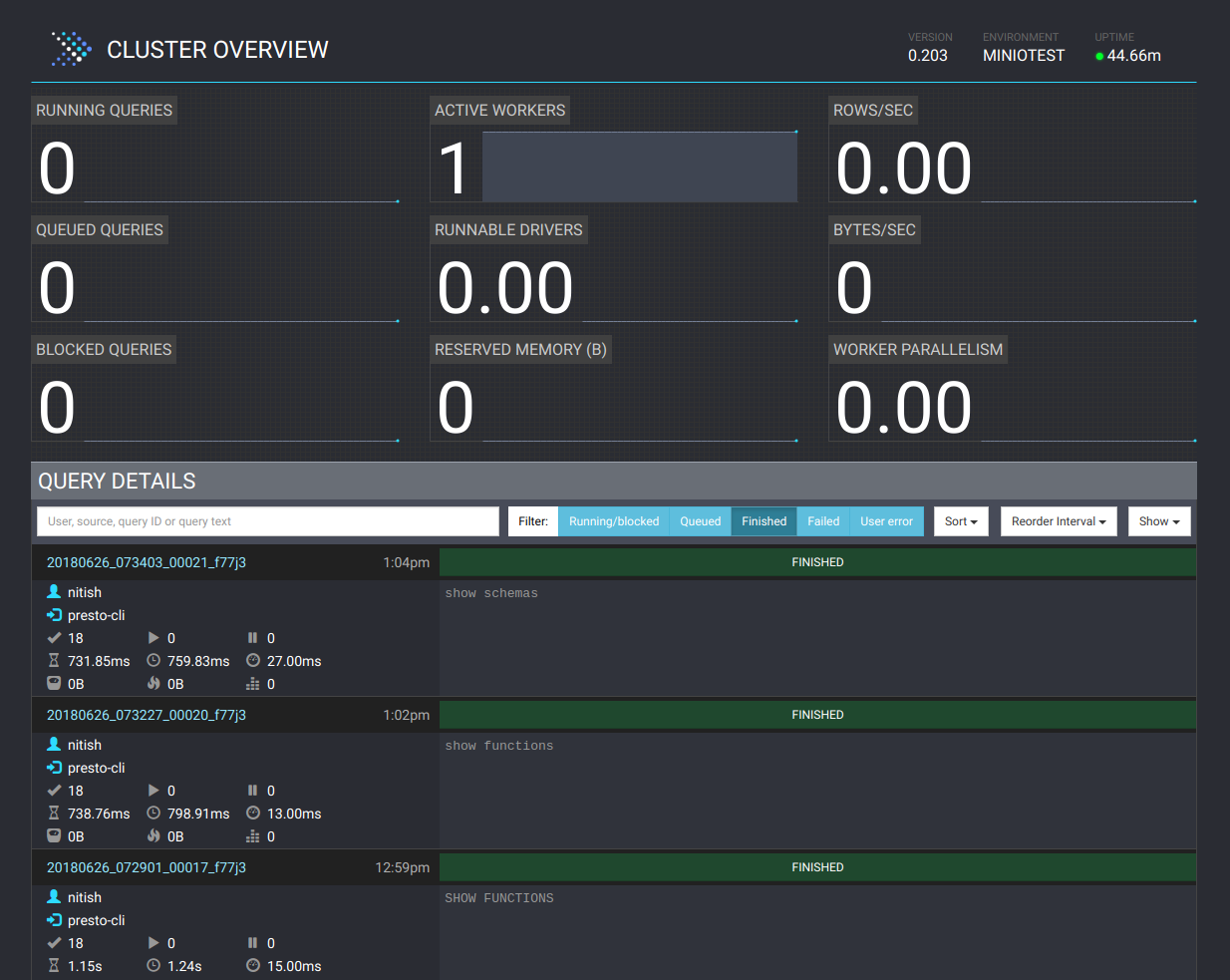
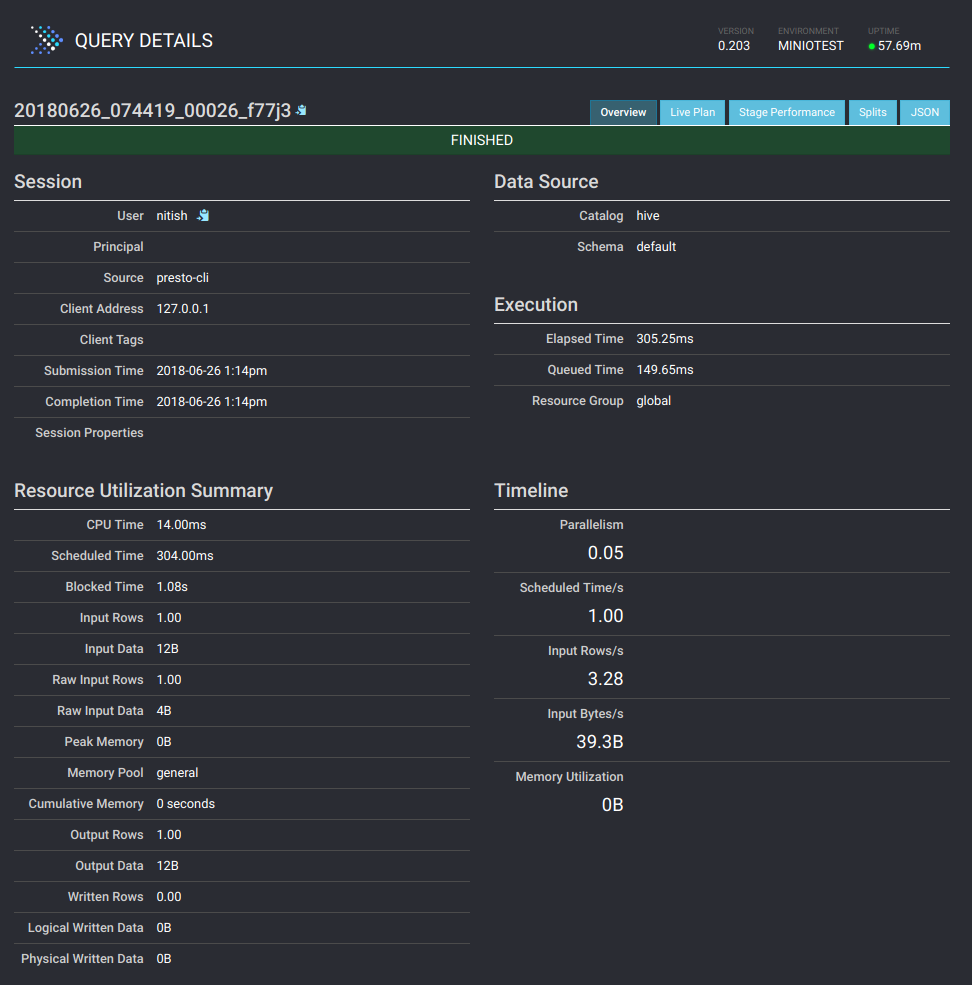
Presto UI offers great details about each query being executed as well. Click on a query to see details like resource utilization, timelines, stages and tasks done by workers etc. Here is how the details page looks like
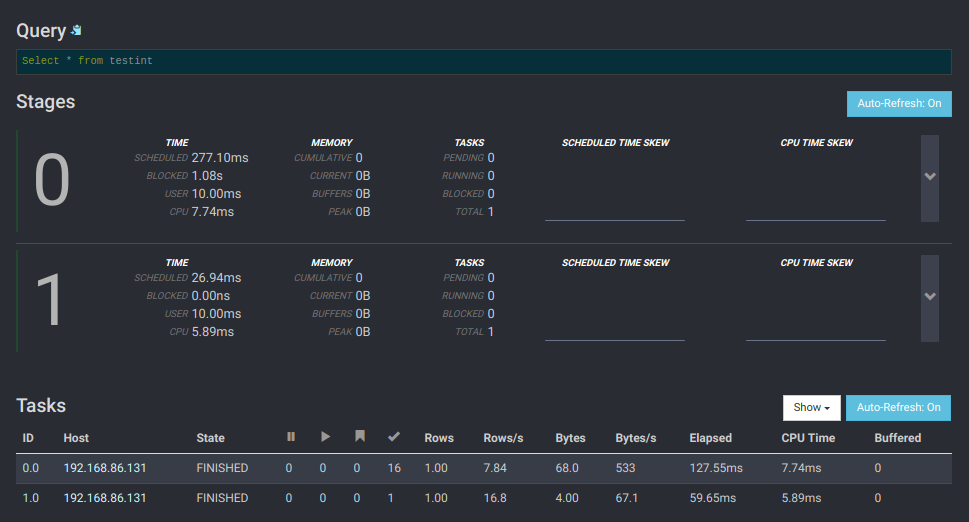
You can now use the Presto CLI to issue queries for data stored on the Minio server. You can also use one of the Presto Clients.
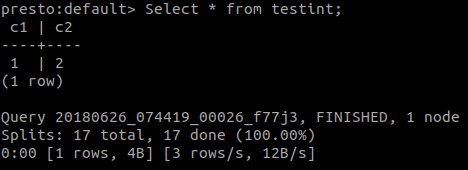
To confirm if the table created in Hive is available via Presto client, start the cli tool and issue a select statement for the same table. You should see the same contents.
In this post, we learned about why and how Presto is taking the centre stage as the tool of choice when querying large datasets from platforms like Minio. We then learned the steps to setup and deploy Presto on private infrastructure.






