Publish from Kafka, Persist on MinIO

Streaming data is a core component of the modern object storage stack. Whether the source of that data is an edge device or an application running in the datacenter, streaming data is quickly outpacing traditional batch processing frameworks.
Streaming data includes everything from log files (think Splunk SmartStore), web or mobile applications, autonomous vehicles, social networks and, of course financial data. The data is often time-series and as such it needs to be processed with the attendant challenges of filtering, sampling and windowing. The payoff is big, however, and feeds the real-time engine for the enterprise.
How the enterprise handles streaming data can be become highly complex but this post will start with the basics, with one of the most popular streaming engines, Apache Kafka as our example.
Apache Kafka is an open-source distributed event streaming platform that allows users to store, read and process streaming data. It reads and writes stream of events allowing inflow, outflow and storage of massive amount of customer data in a distributed, highly scalable, elastic, fault-tolerant, and secure environment.
Kafka supports a large variety of data sources and stores them in the form of “topics” by processing the information stream. It also dumps the data to numerous sink-like datastores such as MySQL and MinIO.
To facilitate this movement of data stream from source to sink we need Kafka Connect, a tool for and reliably streaming data at scale between Apache Kafka and other data systems.
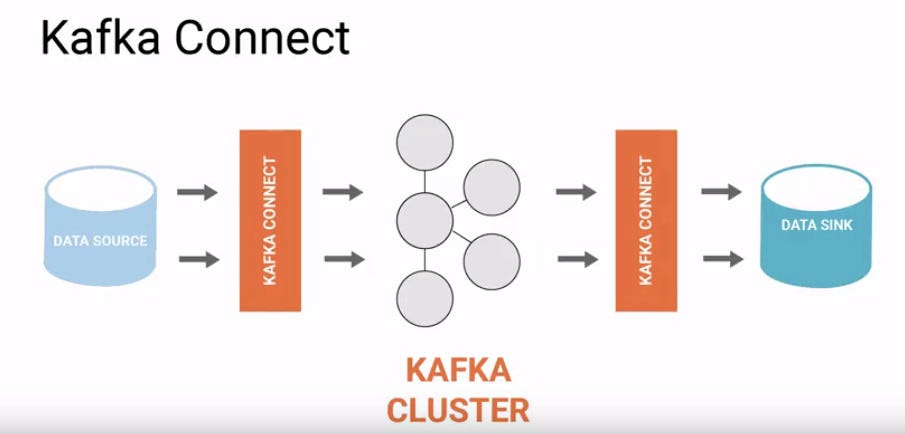
Kafka and MinIO together can be used for ingress / managing and finally storing huge data volumes.
The following is a step by step tutorial on how to integrate the two:
- Install and run Apacha Kafka on Ubuntu 20.04 : Follow the link till step 4 to run kafka as systemd services. https://www.digitalocean.com/community/tutorials/how-to-install-apache-kafka-on-ubuntu-20-04
2. Install and run Minio on Ubuntu 20.04 :
- Create user and group to run MinIO server sudo useradd minio-user -m
sudo passwd minio-user - Run Minio as systemd service : To run MinIO in a distributed mode follow the link https://github.com/minio/minio-service/tree/master/linux-systemd/distributed. Do not forget to configure the following : MINIO_VOLUMES : with actual paths to volume mounts
MINIO_OPTS=” — address :9000" : MinIO server port
MINIO_ACCESS_KEY and MINIO_SECRET_KEY : actual credentials to be used for MinIO server.
3. Install minio-client & create a bucket : Follow the link to get started with minio client https://docs.min.io/docs/minio-client-quickstart-guide.html

4. Integrating Kafka with Minio : Use Confluent S3 plugin to stream Kafka messages to MinIO buckets.
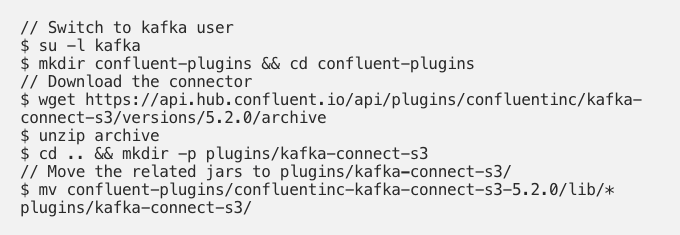
Create two config fileconnector.properties and s3-sink.properties inside the plugin directory. These are needed to start kafka connector.
- Copy paste the below in
connector.properties
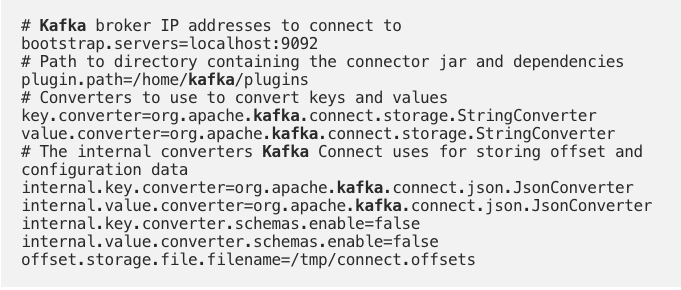
- Copy paste the below in
s3-sink.properties
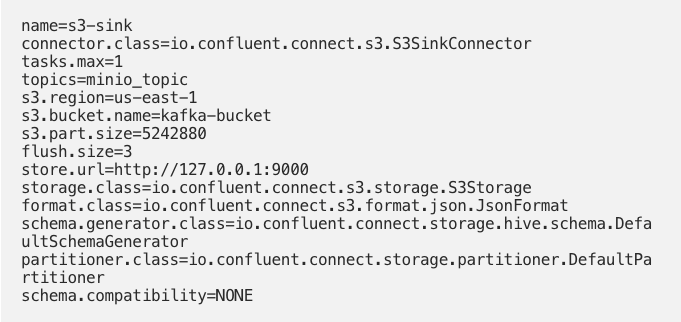
5. Create Kafka Topic : Create Kafka Topic called minio_topic. This is the same topic we set above in s3-sink.properties file.

6. Configure MinIO credentials : This is needed to connect to MinIO Server.

- Add the below details in
credentials

8. Start Kafka connector

9. Publish data to Kafka topic : Since the flush size defined in s3-sink.properties is set to 3, plugin would flush the data to MinIO once there are three messages in the topic minio_topic.

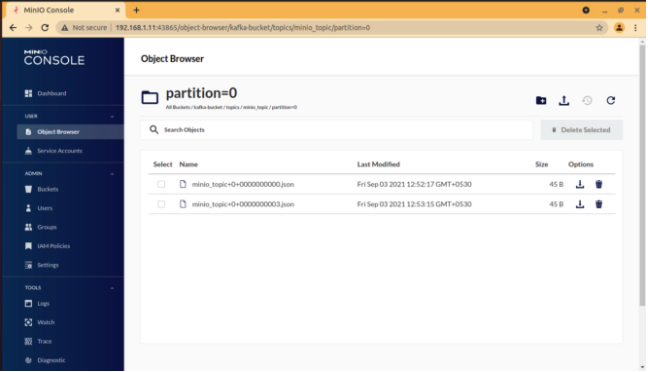
10. Verify the data on MinIO server

11. Login to MinIO console to re-verify.