Machine Learning Using H20, R and MinIO

I’ve been working with neural networks and machine learning since the late ‘80. Yes, I’m that old. The first product I bought was California Scientific Software BrainMaker Professional. I loved that product because it got me started with neural networks. I still have it:

It was a 3 layer neural network product that came with source code in C to execute the models that it trained. I bought it for the source code. Little did I know the code was full of bugs, and it didn’t include code for training models. Knowing C, I went about adding the ability to train models based on the mathematical texts available at the time. I also made it into a DCE RPC server with threading and distributed execution across nodes. When I would describe to people what I was working on and I explained convergence using gradient descent they looked at me like I had two heads. We’ve come a long way in machine learning. Now ML platforms are available in the grocery store. Well, not quite, but you get the idea.
So many AI/ML platforms to choose from. Personally I like H2O. I find it fast, easy to manage and use, and very complete with the capabilities it offers. I also like working in R. I find R to be the most intuitive for me when I work with data and Machine Learning. Combining these two with MinIO Object Storage and it creates a very powerful platform for data scientists.
If you are not familiar with H2O here is a summary (from the website):
Open Source, Distributed Machine Learning for Everyone. H2O is a fully open source, distributed in-memory machine learning platform with linear scalability. H2O supports the most widely used statistical & machine learning algorithms including gradient boosted machines, generalized linear models, deep learning and more. H2O also has an industry leading AutoML functionality that automatically runs through all the algorithms and their hyperparameters to produce a leaderboard of the best models. The H2O platform is used by over 18,000 organizations globally and is extremely popular in both the R & Python communities.
If you are not familiar with R (from Wikipedia):
“R is a programming language for statistical computing and graphics supported by the R Core Team and the R Foundation for Statistical Computing. Created by statisticians Ross Ihaka and Robert Gentleman, R is used among data miners and statisticians for data analysis and developing statistical software. Users have created packages to augment the functions of the R language.”
I find R to be the most intuitive for me when I am working with data, data analysis, and machine learning.
If you are not familiar with MinIO it is a 100% compatible drop in replacement for Amazon S3: https://min.io
In this article I’m going to setup H2O, R, and MinIO to train models using the H2O AutoML capability. The R language has a companion IDE called RStudio, which I will use for this development: https://www.rstudio.com/. If you want to follow along please install R and RStudio, and have access to an H2O cluster.
R studio provides a powerful IDE for R development. It generally looks like this:
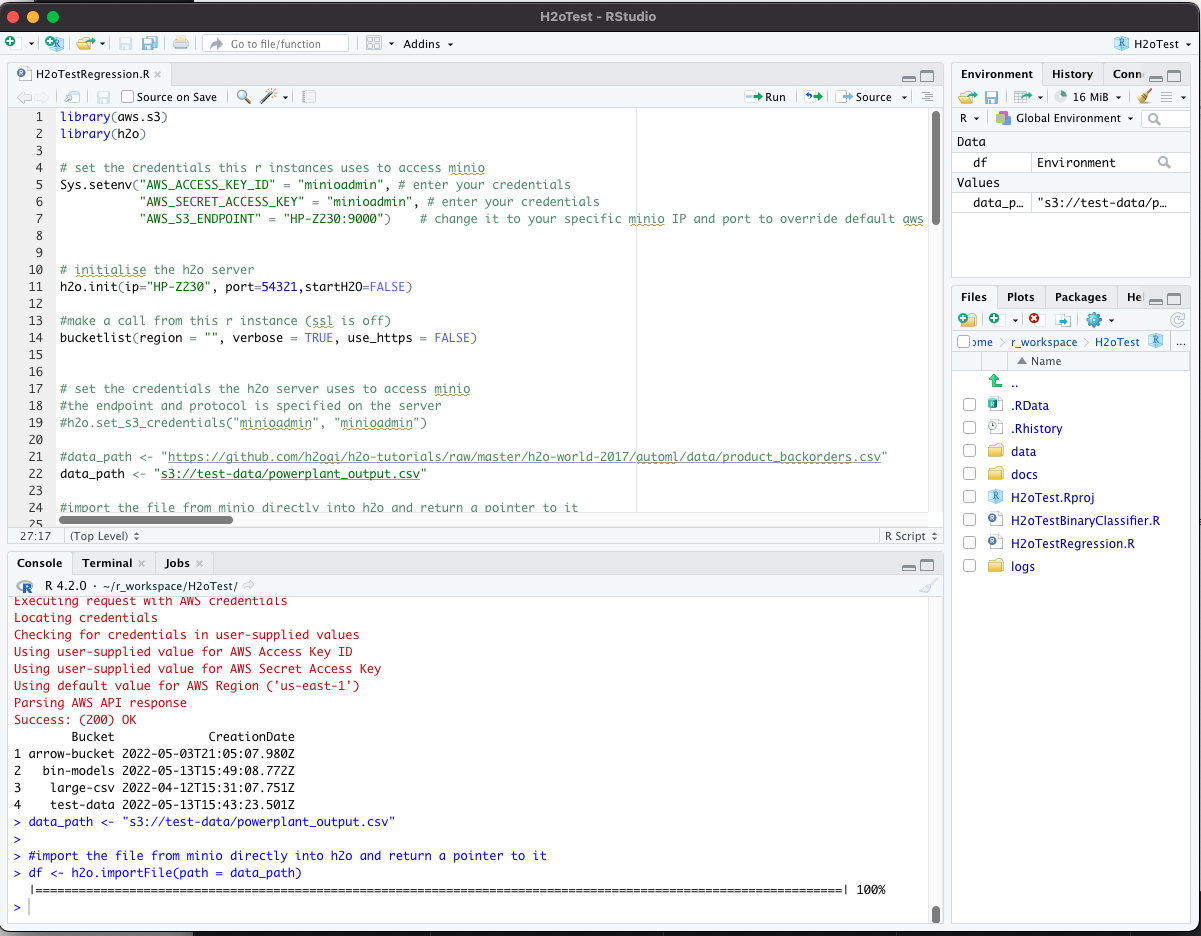
One of the challenges with working with very large training and execution data sets is that they simply don’t fit into memory. H2O solves this by creating a distributed computing platform from the nodes in the H2O cluster. If a given dataset is too large for your cluster then simply add more nodes with more RAM. That’s awesome. That means that lowly data scientists do not need to have machines with enormous amounts of RAM on each of their desks, but can leverage the collective RAM capability of a large H2O cluster.
MinIO provides the high performance object store to persist the large training and execution sets, and H2O is able to read and write directly from/to MinIO. Easy Peasy. I have a MinIO cluster running and the node I typically use to read and write from/to the cluster is “HP-Z230” on port 9000.
We start with loading a .csv file into an S3 bucket in MinIO. This can be accomplished with either the MinIO “mc” client, or through the MinIO console.
I’m using powerplant data from an H2O tutorial here: "https://github.com/h2oai/h2o-tutorials/raw/master/h2o-world-2017/automl/data/powerplant_output.csv"
And I have loaded that file into a bucket called test-data in MinIO. You will notice that this file isn’t very large, but this approach works for very large files as well - it just takes longer.
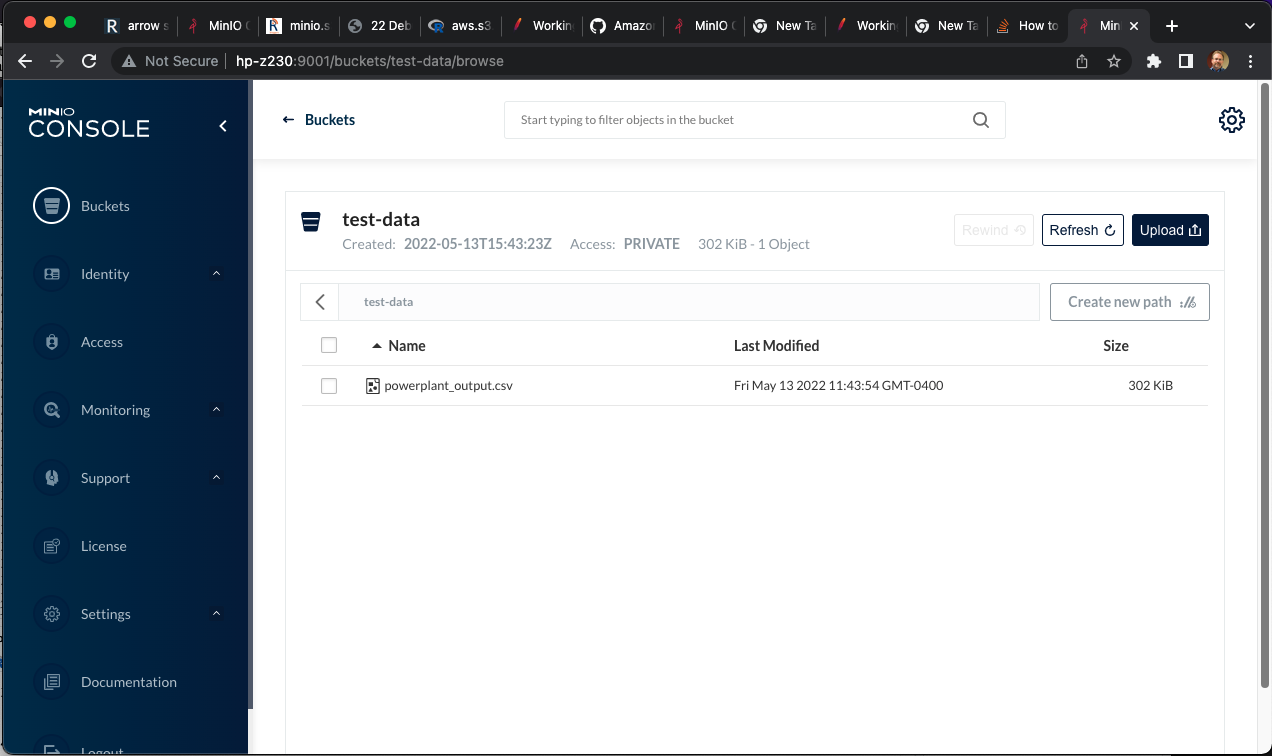
Having this data in the MinIO bucket is the starting point for our process. The next step is to configure H2O to be able to read and write from/to the MinIO s3 storage. There are some configuration steps necessary.
First we need to create a core-site.xml file that specifies the AccessKeyId and SecretAccessKey (the credentials) that H2O should use when accessing MinIO s3 storage. Here is an example:
bcosta@bcosta-HP-Z230-Tower-Workstation:~/h2o/h2o-3.36.0.3$ more core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--
<property>
<name>fs.default.name</name>
<value>s3://<your s3 bucket></value>
</property>
-->
<property>
<name>fs.s3.awsAccessKeyId</name>
<value>minioadmin</value>
</property>
<property>
<name>fs.s3.awsSecretAccessKey</name>
<value>minioadmin</value>
</property>
</configuration>Then the H2O program needs to be started with some parameters on the command line indicating where to access the object storage. Here is an example. I have MinIO running on a machine with the name "HP-Z230" on port 9000. Additionally the core-site.xml file is referenced:
java -Dsys.ai.h2o.persist.s3.endPoint=http://HP-Z230:9000 -Dsys.ai.h2o.persist.s3.enable.path.style=true -jar h2o.jar -hdfs_config core-site.xmlH2O should startup successfully. If there are a number of H2O nodes forming a cluster then these steps should be taken at each node. If in your environment you would prefer not to hardcode the credentials in the H2O config file there is a way to dynamically set them from R, but typically since the MinIO cluster and the H2O cluster are both part of the infrastructure, tying them together statically is not unusual.
On to the code! The first steps are loading the required libraries and testing our connections. In this block i load the aws.s3 and h2o libraries, set some credentials so that R can see the MinIO s3 cluster, and give it all a shake to see if it’s working. Since MinIO is 100% compatible with Amazon s3 we can use the AWS library or use the MinIO library - it doesn’t matter. H2O provides an R compatible library with the download and that should be used to access the H2O server. It is necessary that the versions of the R library and the H2O server match, otherwise the init call below will fail with an appropriate message.
library(aws.s3)
library(h2o)
# set the credentials this r instances uses to access minio
Sys.setenv("AWS_ACCESS_KEY_ID" = "minioadmin", # enter your credentials
"AWS_SECRET_ACCESS_KEY" = "minioadmin", # enter your credentials
"AWS_S3_ENDPOINT" = "HP-Z230:9000") # change it to your specific minio IP and port to override default aws s3
# initialise the h2o server
h2o.init(ip="HP-Z230", port=54321,startH2O=FALSE)
#make a call from this r instance (ssl is off)
bucketlist(region = "", verbose = TRUE, use_https = FALSE)Executing this code in R Studio should result in successful initialization of the H2O server, as well as a successful connection to the MinIO cluster and a list of the buckets being returned. This tests connectivity from R to both H2O and MinIO.
The next step tests the ability of H2O to access the MinIO cluster directly. Remember - we will be loading files that are too large to pass them through the R environment running on my laptop. H2O needs to be able to read the large files from MinIO into it’s distributed computing environment directly.
# set the data_path for the object we will read
data_path <- "s3://test-data/powerplant_output.csv"
#import the file from minio directly into h2o and return a pointer to it
df <- h2o.importFile(path = data_path)
h2o.describe(df)Notice the h2o.importFile() call. This is executed in R, but directs the H2O server to load the file directly into the cluster’s memory from the MinIO S3 store. If this works then you now have R talking to H2O, R talking to MinIO, and H2O talking to MinIO. The world is your oyster!
Next we convert the data into a format H2O likes and split it using a call to the server - we are effectively remotely executing data manipulation calls against the large dataset.
#convert the raw dataframe on the server to a hex file and return a pointer to it
data.hex <- as.h2o(df)
y <- "HourlyEnergyOutputMW"
splits <- h2o.splitFrame(data.hex, ratios = 0.8, seed = 1)
train <- splits[[1]]
test <- splits[[2]]Now that we have some training and testing data we are ready to execute some AutoML against the training set to build and compare some models. I’m using some defaults, and limiting the exploration time to 60 seconds below, but there are a tremendous number of parameters that can be set for the H2O AutoML capability - too many to cover here. Once complete the code prints the leaderboard.
## Run AutoML stopping after 60 seconds. The `max_runtime_secs` argument provides a way to limit the AutoML run by time. When using a time-limited stopping criterion, the number of models train will vary between runs. If different hardware is used or even if the same machine is used but the available compute resources on that machine are not the same between runs, then AutoML may be able to train more models on one run vs another.
aml <- h2o.automl(y = y,
training_frame = train,
leaderboard_frame = test,
max_runtime_secs = 60,
seed = 1,
project_name = "powerplant_lb_frame")
## Leaderboard
print(aml@leaderboard)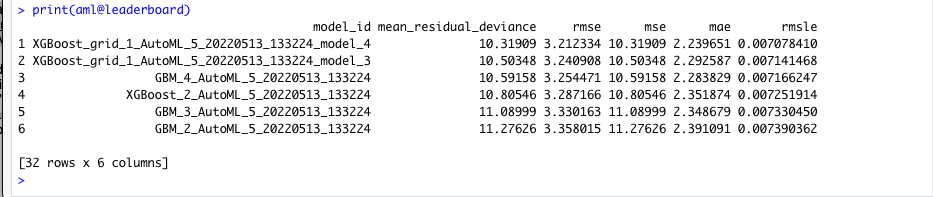
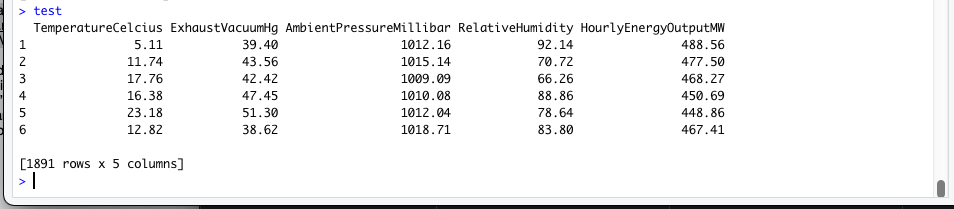
Next we send the test data through the lead model to see some predictions. Here is the head of the test data. The model will be predicting that last column - “HourlyEnergyOutputMW”:
## Predict Using Leader Model
pred <- h2o.predict(aml, test) # predict(aml, test) and h2o.predict(aml@leader, test) also work
head(pred)Again, notice that for the prediction H2O is accessing the test data directly from MinIO S3 storage. The test file can be very large assuming a large H2O cluster.
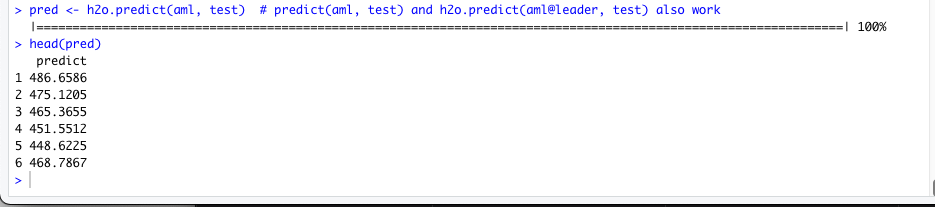
Those look reasonable, and finally we can assess the performance of the model and save the model back to MinIO s3 storage:
perf <- h2o.performance(aml@leader, test)
perf
# save leader as bin
h2o.saveModel(aml@leader, path = "s3://bin-models/powerplant_output_model_bin")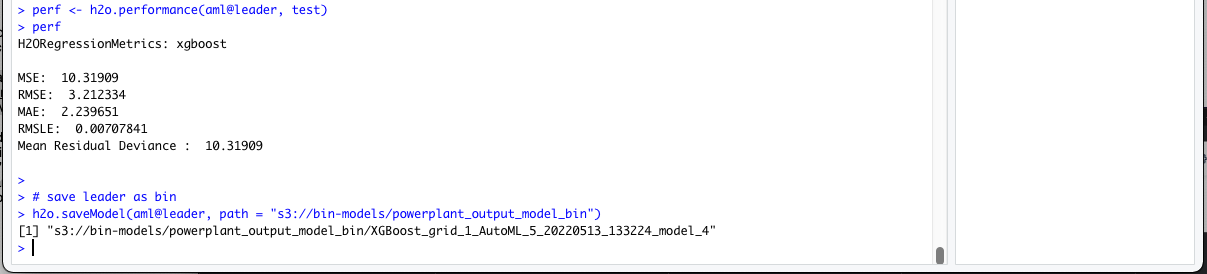
I’ve saved the model into a bucket called bin-models, and if I look in the console I see the model stored in MinIO:
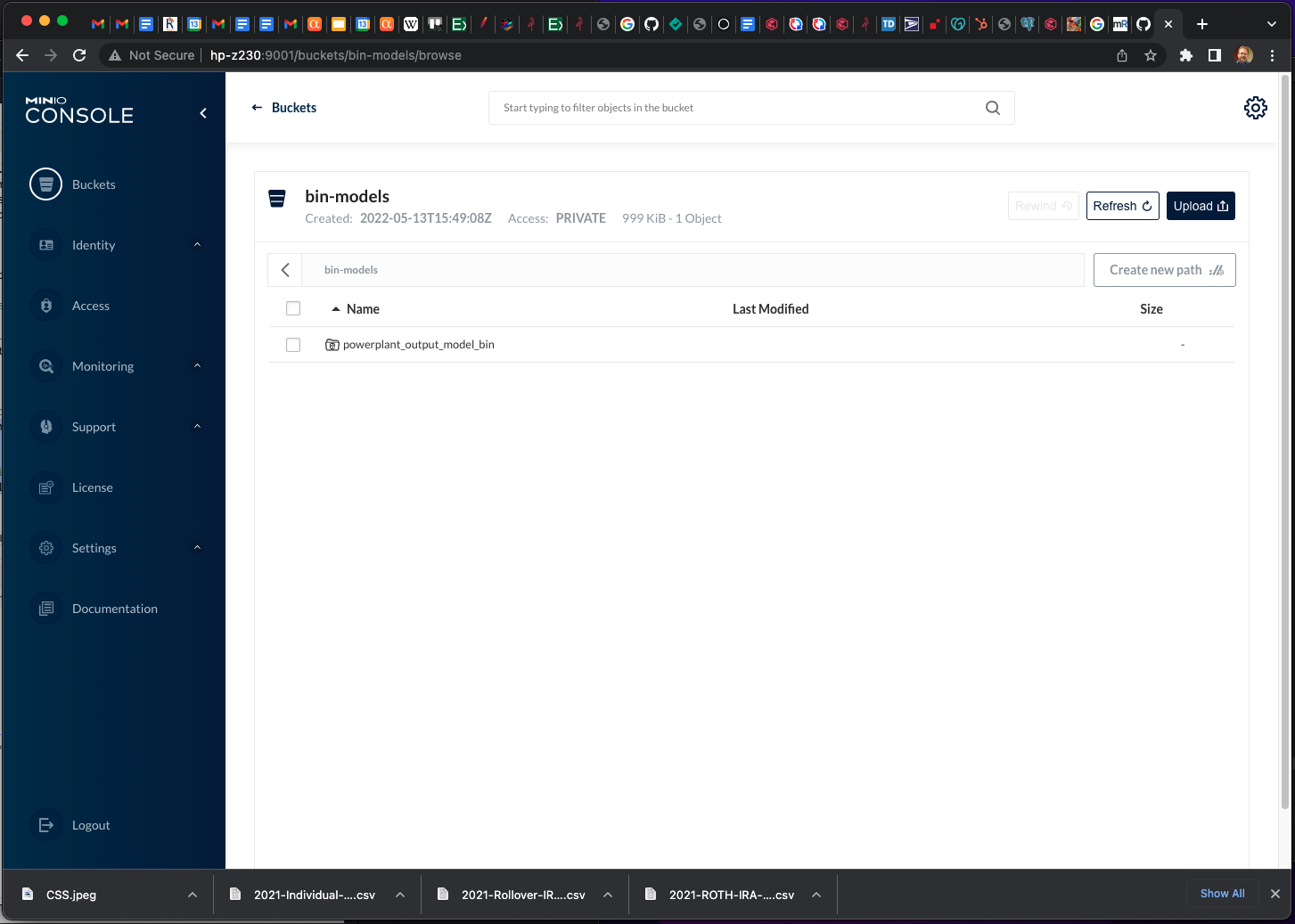
H20 with R and MinIO
This was a quick example of using H2O with R and MinIO to create an AI/ML platform that can handle large files and to train models using AutoML, test them, evaluate the performance of the leader, and ultimately save the model in MinIO S3 object storage for future use. I hope it’s helpful, I enjoyed writing it.






