MinIO AIStor with NVIDIA GPUDirect® RDMA for S3-Compatible Storage: Unlocking Performance for AI Factory Workloads

In large-scale AI, every watt, core, and microsecond is a competitive edge. GPUs drive the economics of training and inference, making it increasingly important for data paths and faster networks to scale alongside more demanding workloads.
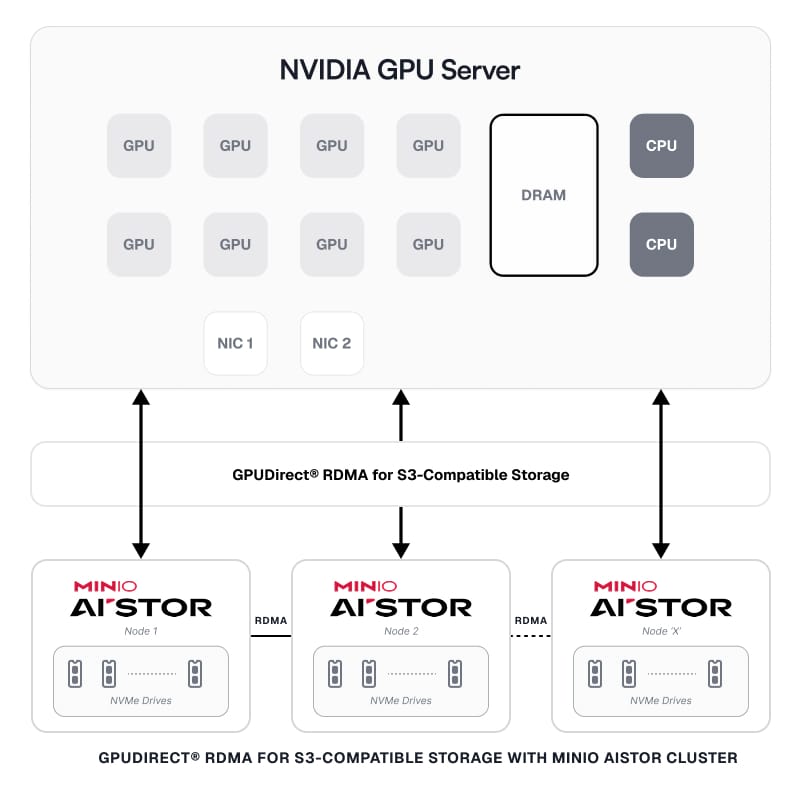
NVIDIA has changed the game with GPUDirect RDMA for S3-compatible storage, a breakthrough that preserves the universal S3 API and ecosystem that AI teams rely on, while introducing a direct, RDMA-accelerated data path optimized for GPU-era infrastructure. By reducing CPU involvement in the data path, it helps unlock higher throughput with lower overhead, keeping GPUs compute-bound and freeing host resources for higher-value tasks.Note: GPUDirect RDMA for S3-compatible storage is currently available in technical preview. MinIO will continue working closely with NVIDIA as this capability progresses toward general availability (GA).
MinIO AIStor builds directly on this innovation, providing high-performance S3 semantics with RDMA acceleration, enabling GPU clusters to access data at the speed today's AI demands.
Why RDMA for S3-Compatible Storage Is a Major Breakthrough
This work builds naturally on the GPUDirect® family of technologies, especially GPUDirect RDMA, which has established a proven pattern in accelerated computing: reduce CPU involvement and avoid unnecessary memory copies in the hottest data paths. Extending that philosophy to S3-compatible storage is what makes GPUDirect RDMA for S3-compatible storage such a significant advancement for AI infrastructure.
- Practical path to scaling 400GbE+ deployments: As NICs advance to 400GbE and beyond, traditional S3 data transfer can become constrained by CPU processing overhead, interrupt handling, packet processing, and protocol management, especially under sustained bandwidth and heavy concurrency. This can make consistent NIC bandwidth saturation harder to achieve, and in AI stacks, it risks depriving the GPUs of timely data and steals precious cycles from the very tasks you want the CPU handling: orchestration, scheduling, preprocessing, telemetry, and serving logic.
- Cluster-wide parallelism for GPU servers: GPUDirect® RDMA for S3-compatible storage turns the object store into a true parallel data plane. All MinIO AIStor nodes can participate equally and in parallel, pushing or pulling object data over the RDMA path to the GPU servers efficiently, so throughput scales with the cluster rather than being limited by CPU-heavy networking paths.
NVIDIA’s approach is significant because it modernizes the data plane while preserving the application plane:
- Applications and pipelines keep using S3 semantics (portability and ecosystem remain intact).
- The storage access path gains an RDMA-accelerated transfer layer, reducing CPU overhead and improving throughput as well as latency consistency.
- The architecture is designed to better align with GPU servers, where the objective is to keep GPUs compute-bound rather than I/O-bound.
The key point to remember is this: GPUDirect® RDMA for S3-compatible storage is not “a faster S3 implementation.” It’s a new way to move S3 object data that is far more compatible with the performance and efficiency requirements of GPU-era infrastructure.
CUDA Ecosystem Support: Making RDMA for S3-Compatible Storage Practical at Scale
NVIDIA is driving innovation not only in hardware, but in the software building blocks that make accelerated systems easier to adopt. The availability of CUDA libraries and supporting components that enable RDMA-accelerated data access reflects a broader trend: data movement is now a first-class optimization target in AI stacks, not an afterthought.
High-speed RDMA paths succeed or fail on details most application teams shouldn’t have to re-implement: memory registration, buffer lifecycle management, synchronization, and clean overlap of I/O with compute. This is where CUDA matters. CUDA provides a mature, widely adopted foundation for GPU memory management and synchronization, which helps storage-to-GPU transfer paths become correct, concurrent, and operationally supportable, not just fast.
Anchoring RDMA-enabled storage to the CUDA® software ecosystem creates a more consistent contract for:
- Memory semantics: clearer expectations around buffer lifetimes, registration behavior, and coordination with GPU memory allocation, reducing the risk of subtle correctness issues under load.
- Compute/I/O overlap: natural integration with stream-oriented execution so transfers can be pipelined with preprocessing, inference, and post-processing, improving utilization and smoothing tail latency.
- Deployability at scale: less bespoke glue code, fewer environment-specific edge cases, and alignment with the same driver/toolkit surface area used broadly across NVIDIA platforms.
This is what elevates RDMA for S3-compatible storage from a point optimization into a platform capability.
RDMA between MinIO AIStor Nodes
End-to-end performance isn’t only determined by the GPU server’s client path. In MinIO AIStor, a single GET or PUT involves internal data movement with erasure coding. If the storage backend cluster network is still constrained by CPU-heavy paths, you can end up with a fast “front door” with performance limited by slower internal aggregated throughput.
That’s why RDMA between MinIO nodes is also important. Accelerating node-to-node traffic can significantly improve:
- Sustained throughput under load,
- Latency consistency (less jitter),
- Faster internal fan-out/fan-in operations,
- Overall cluster efficiency, especially at scale.
Accelerating node-to-node transfers can improve the efficiency of shard distribution, reconstruction, and background operations such as healing and rebalancing, helping the cluster sustain higher throughput with tighter latency under load.
In other words: RDMA isn’t just a GPU-to-storage feature. It needs to be a cluster-wide performance multiplier when applied to internal storage traffic as well. MinIO now supports verbs RDMA between AIStor nodes.
Benchmark Results: Significant Gains in Performance
On a 400GbE end-to-end NVIDIA networking setup with MinIO AIStor, the gains from RDMA for S3-compatible storage were immediate and significant. When compared to S3 over HTTP, the RDMA-based solution achieved the following:
The key takeaway: GPUDirect® RDMA for S3-compatible storage doesn’t just move the same bytes faster; it fundamentally changes where the work happens. CPUs on the GPU servers are nearly idle for data movement and can be leveraged for orchestration, observability, or additional application logic.
Conclusion
The integration of GPUDirect® RDMA for S3-compatible storage with MinIO AIStor represents a strategic inflection point for AI infrastructure.
It preserves the universality of S3 while introducing a modern, RDMA-accelerated data plane designed for GPU-era requirements. As network speeds continue to climb, CPU-heavy access becomes increasingly difficult to scale efficiently. RDMA is the cleanest path forward, both to unlock performance today and to future-proof AI infrastructure for what comes next.
And importantly, the value compounds: pairing GPU-to-storage RDMA acceleration with RDMA inside the MinIO cluster improves performance end-to-end, keeping GPU pipelines fed and inference/training systems compute-bound, where they belong.
MinIO will continue to work closely with NVIDIA as NVIDIA advances RDMA for S3-compatible storage from technical preview to GA, with a focus on production-grade robustness, observability, and performance consistency under real-world concurrency patterns.






