Day 2 with MinIO: Scaling, Hardware Ops, Administration

The term "Day 2" refers to operations needed to maintain a cluster after the initial planning and deployment stages. This is when the cluster needs to be upgraded, storage needs to be expanded and resources need to be monitored. Not only that, but as the cluster grows over time it is inevitable there will be hardware failures. You should not worry about the failure, but rather you should assume that it will happen at one point or another and plan for it from the get go.
In today’s post, we’ll go deeper into some of the considerations for long-term MinIO management that you need to take into account, so that when Day 2 does roll around 48 hours later you have all your ducks in a row.
Cluster Hardware Operations
Expand MinIO Deployment
Our Engineers in SUBNET always recommend that customers start building clusters based on initial requirements and expand their MinIO deployment as the need for storage space increases. We built MinIO to make expansion easy using server pools. But the job doesn't end with expansion, you still need to ensure the data is replicated using bucket or site replication, more on this later.
There are a couple of prerequisites that you need to consider to ensure adding pools goes as smoothly as possible.
The firewall needs to be enabled to allow bidirectional traffic in a way it can talk to all the other MinIO nodes within the same cluster. This means the network should allow the MinIO port 9000 on all the nodes communicating with each other. In Linux that command would look something like this.
firewall-cmd --permanent --zone=public --add-port=9000/tcp
firewall-cmd --reload
In addition to firewalls, you need to ensure the traffic is distributed across the MinIO nodes in the cluster using the least connections algorithm for routing requests. We’ve shown how to do this in a previous blog post using Nginx.
All the servers in the pool must have the same CPU, Memory and raw Disk capacity. MinIO recommends direct-attached JBOD drives – meaning no network and no RAID. MinIO handles both the disk-level data protection using erasure coding and also hardware-level replication using bucket, site, and batch replication methods. This negates the need for any additional hardware or networking overhead to expand the cluster. MinIO requires using expansion notation {x...y} to denote a sequential series of drives when creating the new server pools. MinIO also requires that the ordering of physical drives remain constant across restarts so that the mount point always points to the same formatted drive. Our recommendation is to use /etc/fstab or a similar file-based mount configuration to ensure that drive ordering is more predictable and cannot be changed after a reboot. You can then specify the entire range of drives using the expansion notation /mnt/disk{1...4}. If you want to use a specific subfolder on each drive, specify it as /mnt/disk{1...4}/minio.
As mentioned earlier, it's crucial to select similar hardware configurations for all nodes in the new MinIO pool. Ensure the CPU, memory, motherboard, drive storage adapters and software such as operating system, kernel settings and system services are consistent across all nodes in the pool. The new pool may exhibit unpredictable performance if nodes have heterogeneous hardware or software configurations. Workloads that benefit from storing aged data on lower-cost hardware should instead deploy a dedicated “warm” or “cold” MinIO deployment using ILM and transition data to that tier. We’ll discuss more about ILMs later in this post.
We’ve written a post a while back on how easy and smooth it is to upgrade MinIO. We still recommend the same when expanding the pool. Do not do a rolling restart of MinIO, we recommend restarting MinIO running on all nodes at once since the operations are atomic and strictly consistent. So expanding a cluster will cause zero downtime in MinIO.
It is needless to say the raw capacity needs to be larger than the usable capacity to account for the erasure code storage of parity data and buffer space for unexpected usage. In general, we recommend planning for at least 2+ years before expanding as frequent expansions are not recommended as they increase the complexity of managing the cluster. In fact our Engineers recommend you make the initial cluster deployment’s usable space as large as reasonably possible, say for the next 5-6 years, this way you keep the number of pools in the cluster to a minimum.
To learn more about how to expand your cluster, please consult our docs.
Upgrade MinIO
As mentioned earlier, upgrades in MinIO are non-disruptive. We designed it in such a way that it promotes CI/CD with updates that happen regularly at a constant clip. You don’t need to schedule a maintenance window or take the cluster offline. We recommend picking a time when there is the least amount of traffic and doing an upgrade. What makes this even better is there is no need for a rolling restart of the MinIO daemon. MinIO Engineers recommend restarting all the MinIO daemons on all the nodes at the same time using something like Ansible so that all the nodes reconnect with the newer upgraded version of the binary.
For detailed steps on how to upgrade MinIO in production take a look at our post here.
Decommissioning Server Pools
You might think the common reason for decommissioning pools is to reclaim unused space, but not quite. As we mentioned earlier, we don’t recommend you keep adding pools to your cluster as it might make managing it cumbersome. But what if you already have a couple of pools, can you simplify the management of your cluster? You sure can. This is where decommissioning the pools comes into play.
In essence, you build a new larger cluster that has the capacity to encompass one or more pools in your current cluster. Once the new pool is set up, you can migrate the data to the new pool by simply decommissioning the old pools. So you’ve gone from 5-6 pools to now down to two, but your overall capacity increased as well. This is why it is essential to talk to our engineers on SUBNET to help you architect your initial cluster setup. They can guide you properly on how to build your initial cluster without even the need to add pools in the future, but still design it in a way where you can add more pools if you need to expand in the future due to unforeseen demand.
Generally, the decommissioning feature is designed for removing an older server pool whose hardware is no longer sufficient or performant compared to the pools in the deployment. MinIO automatically migrates data from the decommissioned pools to the remaining pools in the deployment based on the ratio of free space available in each pool.
Non-Disruptive Hardware Failures
It's naive to think the best hardware will seldom fail. This is why it's better to anticipate and plan for failures rather than assume they will not occur. There are various types of failures but the three most common are Drive Failure, Node Failure and Site Failure.
As mentioned earlier we recommend using JBODs for the servers being used with MinIO. One of the reasons is during a failure it makes hot swapping one or more drives that much easier. You don’t need to reconfigure the RAID controller to remove a failed drive. MinIO detects the addition of new drives and heals them without requiring any node or deployment-level restart. MinIO healing occurs only on the replaced drives and does not impact cluster performance. MinIO healing ensures consistency and correctness of all data restored onto the drive.
There are two types of node failures that can happen in a MinIO cluster. Like all distributed software, a node can either lose connectivity with the cluster due to a brief network blip or perhaps it crashed and it had to be restarted. Regardless of the reason, as soon as the node connects to the rest of the cluster it will start the healing operations without impacting the performance of the cluster. The second type of failure is where a node completely fails and a new replacement has to be put into place without any of the existing data. It's crucial to ensure the new replacement has the same specs as the decommissioned server, if you cannot get a node with the same specs, get one with the same specs as the node with the LEAST raw disk space in the cluster.
Last but not least, the entire site could go offline as it has happened several times with many data centers around the world. Site replication keeps two or more MinIO clusters in sync with IAM policies, buckets, bucket configurations, objects and object metadata. If a peer site fails, such as due to a major disaster or long power outage, you can use the remaining healthy sites to restore the replicable data to another site. Once a new site is added, or if the existing site comes back online, there is no manual intervention required on your part to resync the data. When the sites talk to each other again, they will replicate the delta that was not replicated during the downtime, so no data is lost under any circumstances.
Administering the Cluster
Object Lifecycle Management
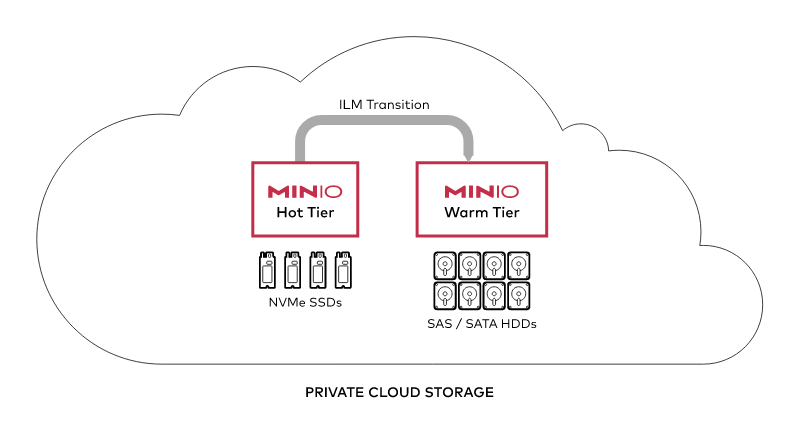
One of the core concepts that will aid in keeping your cluster lean, without the need to potentially add additional hardware are ILM rules. In a previous post we went deep into the various ILM rules and policies to show the lifecycle of an object and how you can plan to potentially siphon off old data in perhaps more commodity hardware with just spindle disks rather than fast NVMe drives.
This could mean you can keep your performant NVMe configured MinIO clusters (hot tier) lean while the high capacity spindle HDD configured MinIO clusters (cold tier) hold archival data. MinIO makes it very easy to use ILM rules because we designed them based on the S3 syntax – in fact, you can copy the rules from your S3 bucket and use it with MinIO.
Versioning and Object Locking
When dealing with various compliance agencies and legal holds, a WORM pattern emerges, Write-Once Read-Many. In MinIO, once the object is written it's immutable. You can enable object locking during bucket creation, as per S3 behavior, you can then configure object retention rules at any time. You cannot enable object locking on a bucket created without versioning enabled. Object locking requires versioning and enables the feature implicitly. The reason versioning and object locking are intertwined is that objects held under WORM locks are immutable until the lock expires or is explicitly lifted. Locking is a per-object version, where each version is independently immutable.
If an application performs an unversioned delete operation on a locked object, the operation produces a delete marker. Attempts to explicitly delete any WORM-locked object fail with an error. We support various modes depending on the compliance requirements, one such example is the GOVERNANCE mode which enables object locking by default.
Object Tiering
MinIO can programmatically configure object storage tiering so that objects transition from one state or class to another based on any number of variables - although the most commonly used are time and frequency of access. This functionality is best understood in the context of tiering. Tiering allows the user to optimize storage cost or functionality to address changing data access patterns. Tiered data storage is generally used in the following scenarios:
Tiering across storage mediums is the best known and most straightforward tiering use case. Here, MinIO abstracts the underlying media and co-optimizes for performance and cost. For example, data may be stored on NVMe or SSD for performance or nearline workloads but tiered to HDD media after a certain period of time or for workloads that value scale over performance. Over time, that data can be further migrated to long-term storage if appropriate.
Monitoring and Troubleshooting
We’ve written several posts on the plethora of ways you can monitor MinIO. Of course, you can use Prometheus but you can also use other open source tools such as OpenTelemetry, OpenObserve and Jaeger to monitor cluster health such as available disk, Network Throughput, CPU/Memory consumption, among other critical system components. At MinIO we always recommend not only monitoring your cluster but understanding the graphs holistically. In other words, if you are monitoring the overall capacity of the cluster (as you should), you would want to look at the past few months to see how the data usage is increasing. Is the line of the graph moderately climbing every few TBs over the regular course of the application usage or do you see a sudden spike – if that spike becomes the new growth rate then you might have to add a new pool soon. Sometimes the data influx is probably garbage data that is not needed and can be cleaned up. But other times it could mean unforeseen use cases and a lot more disk space is being used. Either way, it's important to keep an eye on the cluster.
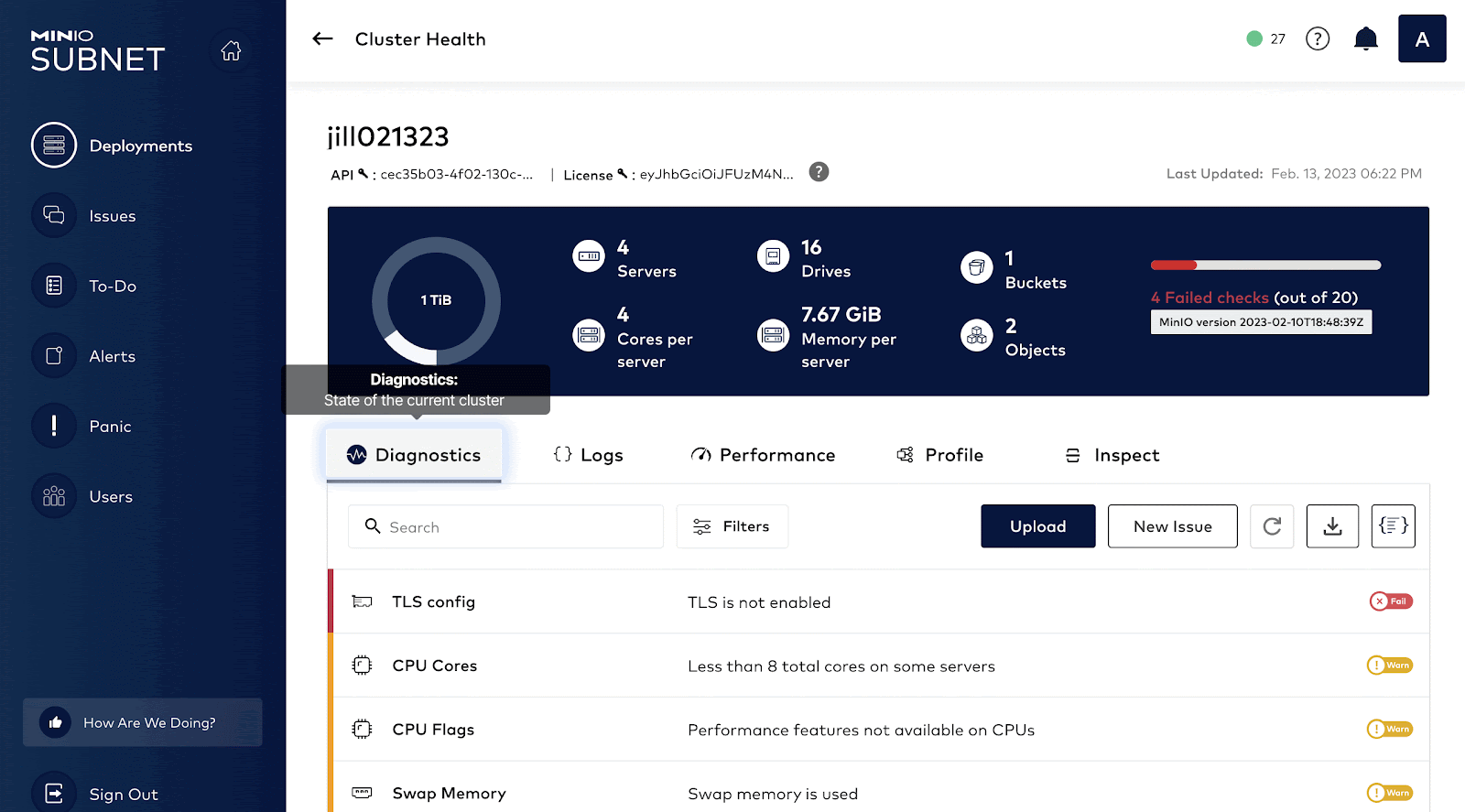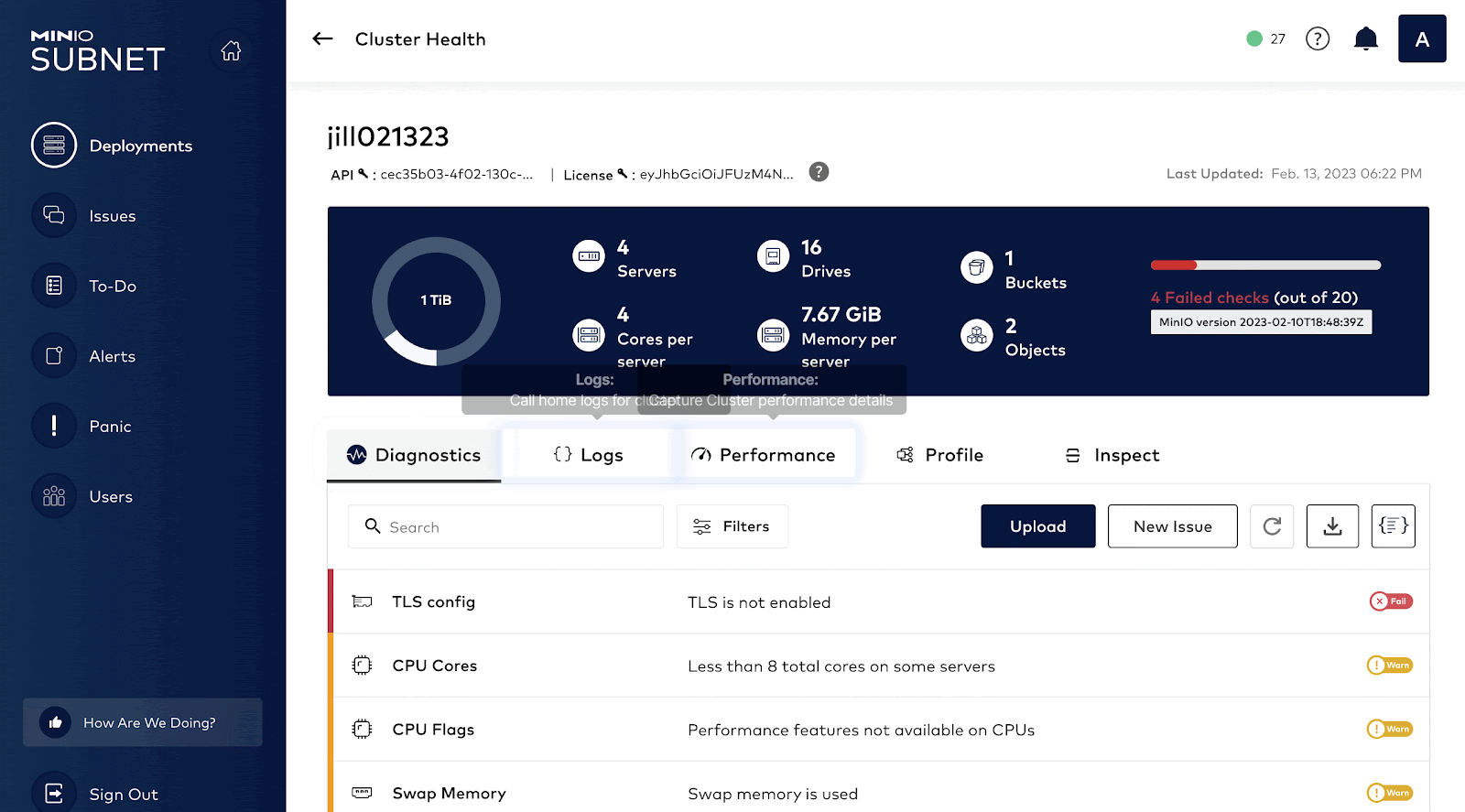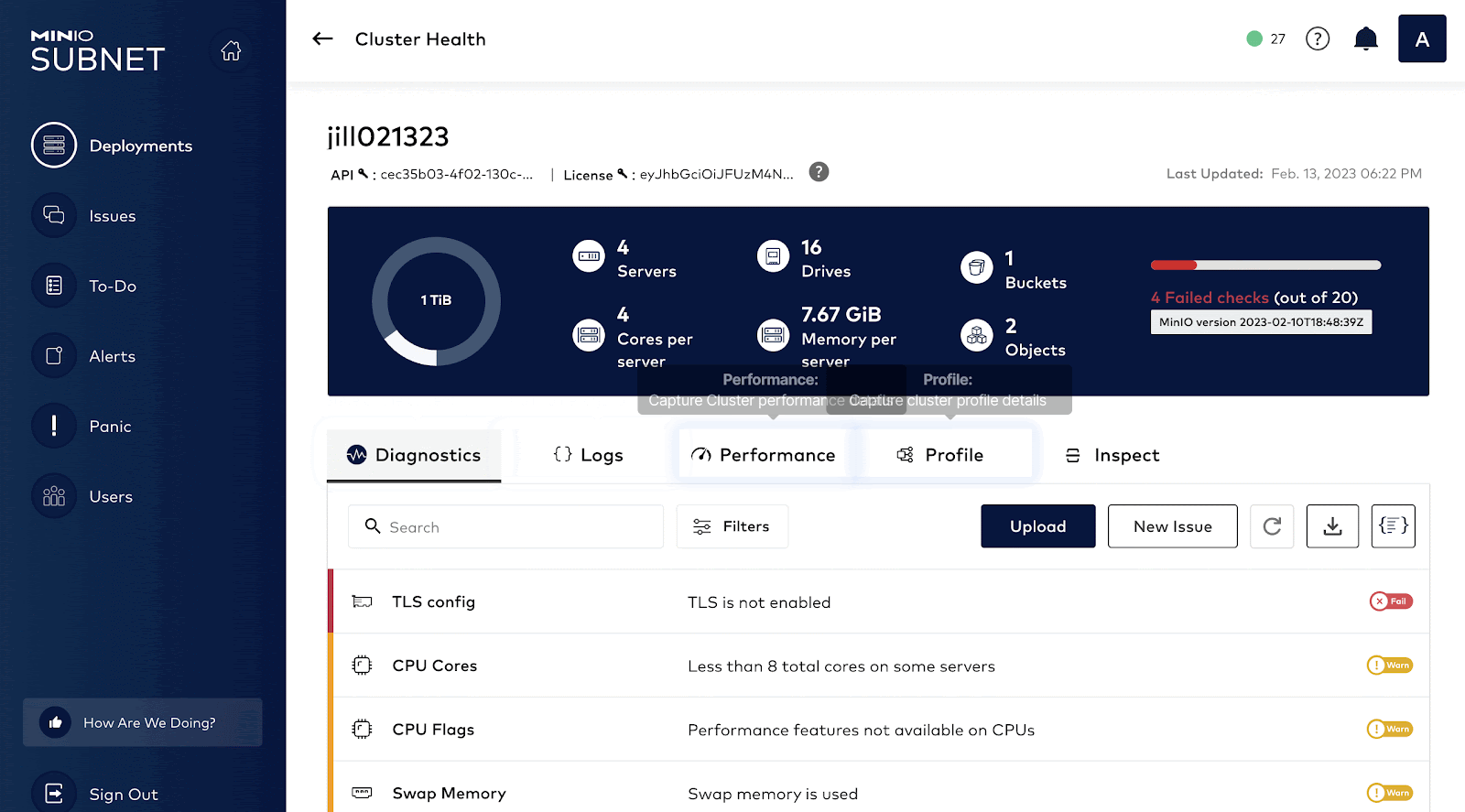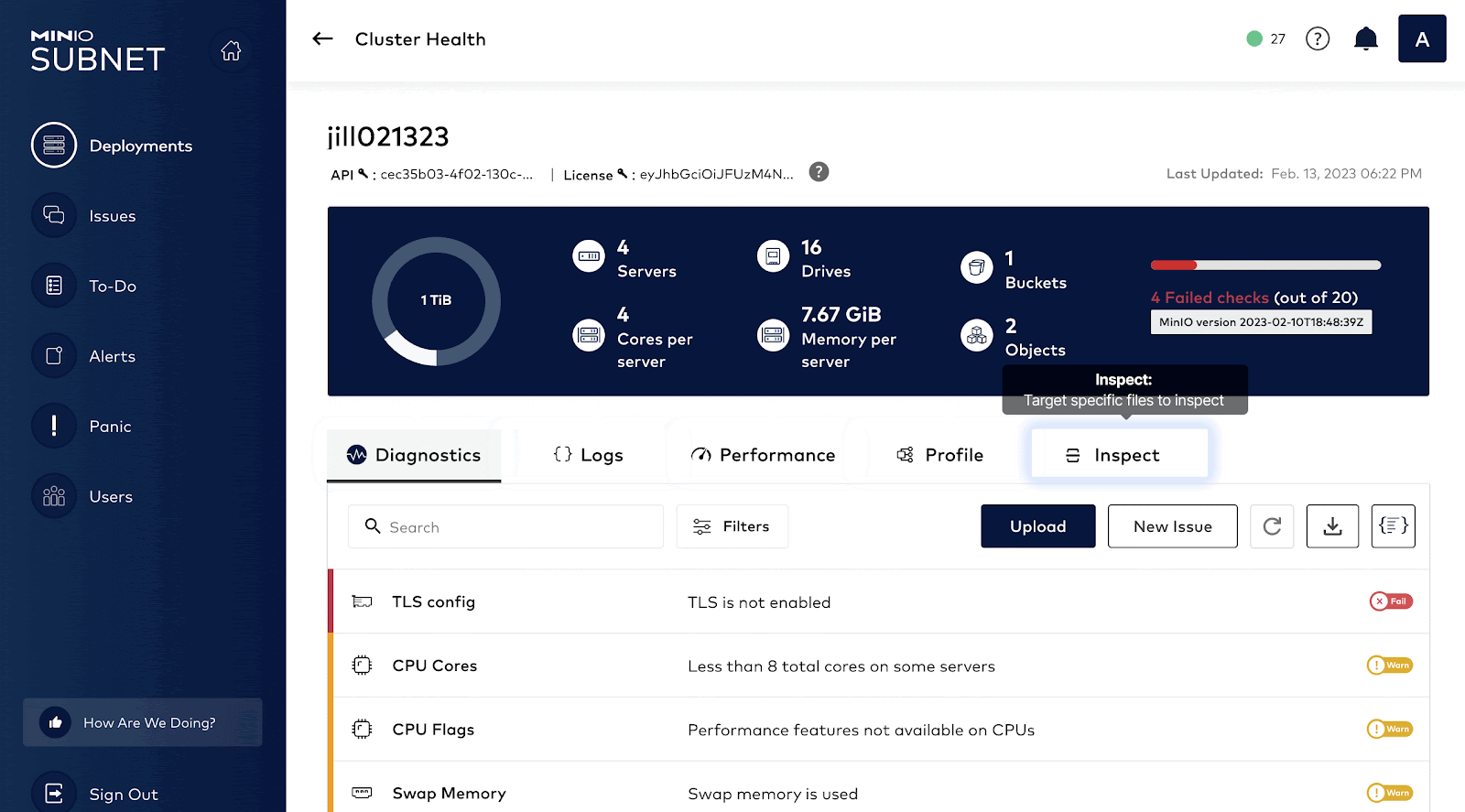
Once an issue has been detected by monitoring, next comes troubleshooting the issue. How do we find the root cause for the spike in graphs? It could be anything: Disk, Network, Memory. This is where the SUBNET portal comes in handy. In order to have a comprehensive understanding of the client system, MinIO developed a capability called HealthCheck which is available only to commercial customers via SUBNET.
HealthCheck provides a graphical user interface for supported components and runs diagnostics checks continually to ensure your environment is running optimally. It also catalogs every hardware and software component to ensure consistency across the environment while surfacing any discrepancies. This speeds up root cause analysis and issue remediation by quickly identifying performance and integration issues.
Object Encryption
Data stored in object storage solutions may potentially need to meet compliance requirements and be protected, and each object needs to be encrypted and stored, as well as decrypted when required. For these reasons, infrastructure and security teams require a solid vaulting solution.
Products/Applications need to encrypt data: Products/Applications do not need to complicate their implementation with cryptography when they can just rely on Hashicorp’s Vault to provide this capability. Vault focuses on signing and verifying data, not storing it. The combination of applications such as MinIO and Vault will ensure data at rest security requirements are met.
Protect databases and web services credentials: Microservices architecture with polyglot databases and integrations with multiple web services or microservices is commonplace. In addition, there are always multiple environments. With infrastructure-as-code and automation, managing credentials and access keys becomes essential, making it necessary to have a high-performing key management and storage solution such as Vault and KES.
Certificates for data in transit: Whether it is a website accessed from a browser, communication between applications and databases, from applications to web services or between microservices, the communication channels between each must be encrypted. Vault can generate PKI certificates that can be used to secure data in transit in these channels.
In order to provide functionality for regulatory compliance around secure locking and erasure, MinIO encrypts objects at the storage layer by using Server-Side Encryption (SSE) to protect objects as part of write operations. MinIO does this with extreme efficiency – benchmarks show that MinIO is capable of encrypting/decrypting at close to wire speed.
Logging
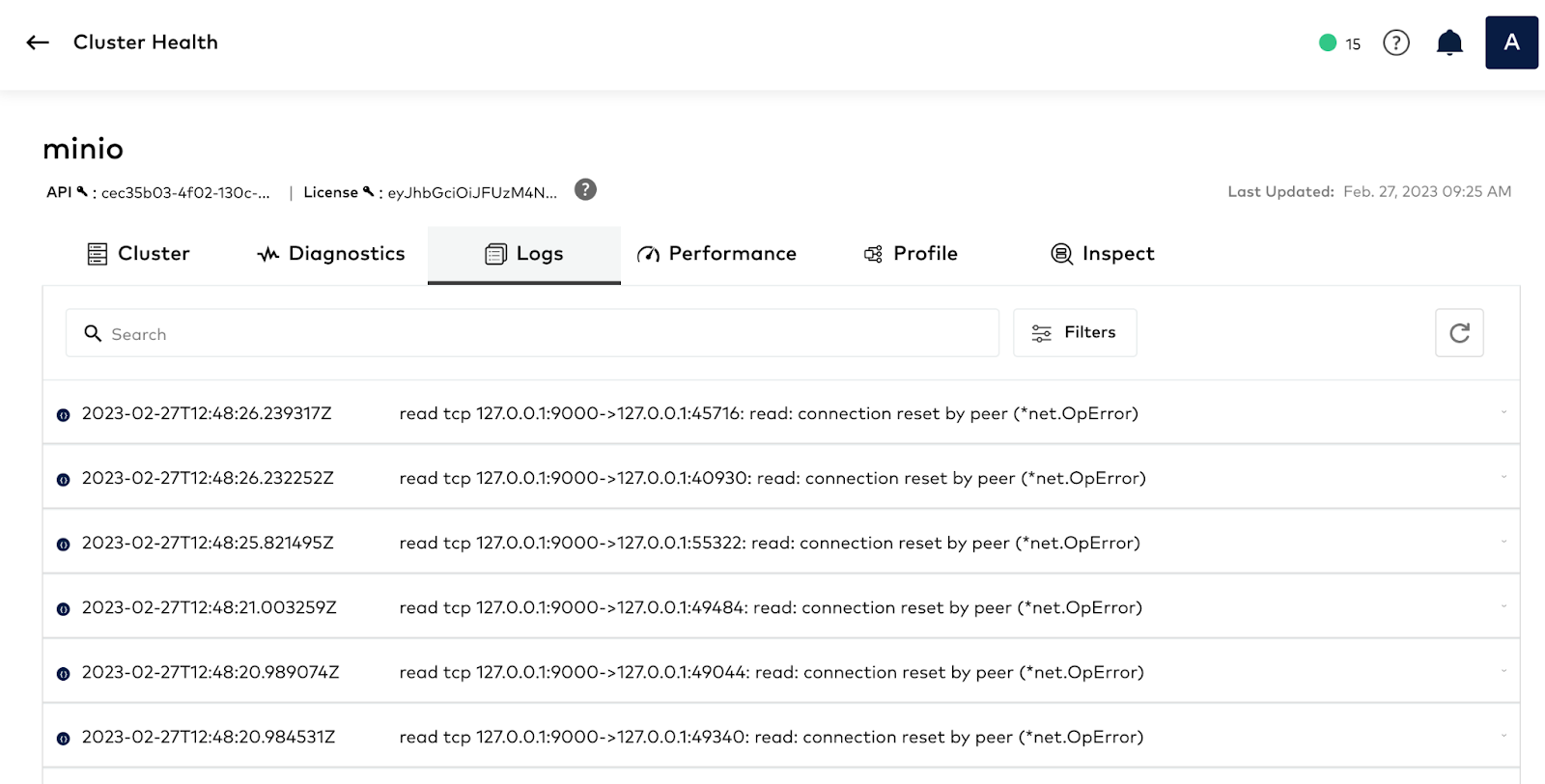
With MinIO you can send logs to multiple destinations for analysis. You can send logs to remote targets, for example a webhook provided by ElasticSearch, and you can also send them directly to the SUBNET support portal – there is no need to manually upload them. By sharing the logs, you give the engineering team from MinIO assisting you on the issue more granular details on the operations of the cluster. You can automate sending logs to SUBNET by enabling call home logs for the cluster using the following command:
Once you enable it, it might take a few minutes for the logs to be sent to the SUBNET portal, give it 30 minutes just to be sure and then refresh to check.
Delightful Day 2
We built MinIO with Day 2 in mind. That is why we designed upgrades to be a non-disruptive routine task. This lets your Engineering and DevOps teams focus on writing code that adds value instead of spending time managing storage infrastructure. While the focus of new customers is generally Day 0 and Day 1, it is paramount to plan for Day 2 during those discussions to have smooth sailing ahead.
If you would like to learn more about Day 2 ops or if you have any questions be sure to reach out to us on Slack!