MinIO Replication Best Practices

Valuable data must be protected against corruption and loss, yet increasing volumes of data - and increasingly distributed data make this a daunting task. MinIO includes multiple data protection mechanisms, and this blog post focuses on replication best practices, a key protection for software-defined object storage that facilitates the creation and maintenance of multi-cloud data lakes so you can run workloads where they run best, with your organization’s most current data.
We will set up a geographically distributed infrastructure where we have a multi-node multi-drive MinIO cluster in multi-sites across vast distances. This will allow us to truly appreciate replication working at scale to help us understand the infrastructure needed for geographic load-balancing and high availability.
MinIO includes several ways to replicate data so you can choose the best methodology to meet your needs. We’ve already blogged about bucket based active-active replication for replication of objects at a bucket level and Batch Replication for replication of specific objects in a bucket which gives you more granular control.
Our dedication to flexibility means that MinIO supports replication on site and bucket levels to give you the ability to fine tune your replication configuration based on the needs of your application and have as much control as possible over the process. Data remains protected via IAM across multiple MinIO deployments using S3-style policies and PBAC. Replication synchronizes creation, deletion and modification of objects and buckets. In addition, it also synchronizes metadata, encryption settings and security token service (STS). Note that you can use site replication or bucket replication, but not both. If you are already running bucket replication, then it must be disabled for site-replication to work.
Since we introduced multi-site active-active replication, our focus has been on performance without causing any additional degradation on existing operations performed by the cluster. This allows you to replicate data across multiple datacenters, cloud and even for disaster recovery needs where one site going offline will not decrease availability. The replication configuration is completely handled on the server side with a set-it-and-forget-it ethos where the application using MinIO does not need to be modified in any way, everything is handled on the server side.
Data protection is much bigger than replication. MinIO also includes:
- Encryption: MinIO supports both encryption at Rest and in Transit. This ensures that data is encrypted in all facets of the transaction from the moment the call is made till the object is placed in the bucket.
- Bitrot Protection: There are several reasons data can be corrupted on physical disks. It could be due to voltage spikes, bugs in firmware, misdirected reads and writes among other things. MinIO ensures that these are captured and fixed on the fly to ensure data integrity.
- Erasure Coding: Rather than ensure redundancy of data using RAID which adds additional overhead on performance, MinIO uses this data redundancy and availability feature to reconstruct objects on the fly without any additional hardware or software.
- Secure Access ACLs and PBAC: Supports IAM S3-style policies with built in IDP, see MinIO Best Practices - Security and Access Control for more information.
- Tiering: For data that doesn’t get accessed as often you can siphon off data to another cold storage running MinIO so you can optimize the latest data on your best hardware without the unused data taking space.
- Object Locking and Retention: MinIO supports object locking (retention) which enforces write once and ready many operations for duration based and indefinite legal hold. This allows for key data retention compliance and meets SEC17a-4(f), FINRA 4511(C), and CFTC 1.31(c)-(d) requirements.
In this tutorial, we’ll take replication one step further to provide more depth around Multi-Site replication and show you the best practices for implementing replication based storage architectures. MinIO’s replication architecture does not interfere with the existing operations of the cluster ensuring there is no performance degradation.
Infrastructure overview
Below we have a diagram to show a brief overview of our infrastructure setup.
We have three different MinIO sites each geographically distant from one another. In each site, we have NGINX proxying the requests to three MinIO servers in the backend. If one of the MinIO servers is offline, NGINX ensures that the requests get routed to other MinIO nodes. Unbound is a DNS service that will resolve the DNS requests for MinIO servers running internally. We could use an external DNS such as Route53 but that requires a dedicated domain. So we will use a dummy hostname such as minio.local instead of editing the /etc/hosts file on all VMs; we just need to update /etc/resolv.conf with the Unbound server’s IP address.
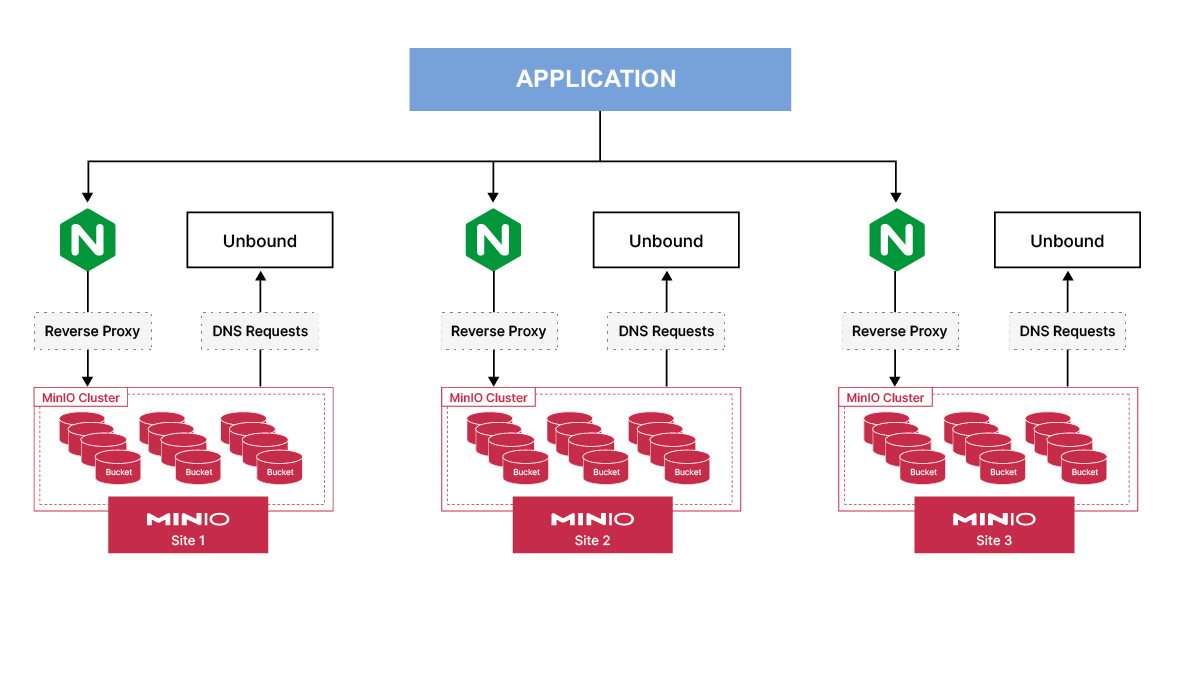
So it begs the question, why does MinIO recommend multi-site setup for best practices as opposed to say single site, single node and single drive configuration? There are a couple of reasons. When you think of data integrity you not only think about where your data is safe but you also want it to be redundant and scalable so your existing operations are not affected. In this setup we are thinking of redundancy in every facet of the stack:
First let's talk about redundancy
- There are multiple disks per node in case the disk fails. Using Erasure Coding, MinIO ensures that in case of a disk failure the data gets replicated to other disks.
- We set it up so that multiple nodes have multiple disks, in case an entire node goes offline there are other nodes in the site that can serve the data.
- In the worst case scenario when the entire site goes offline due to a power failure or network issue the data is available in another location where it could be served from.
But we also need to think about scalability and maintenance. Things are hardly static when managing infrastructure.
- This setup allows you to add more servers to the pool to scale your infrastructure horizontally as your data size and requirements increase. You can even remove nodes from the pool in the event of maintenance so you can preempt any failures before they happen.
- Same goes for the entire site. You will be able to add an entirely new site without disrupting the existing site and scale at geographic level. For instance say you want to use Anycast DNS, you can direct your requests to the geographically closer site so your end users get the data as quickly as possible. If you have to do maintenance on a particular site you can remove it from handling traffic until its ready to take traffic again using MinIO multi-site configuration.
Infrastructure Setup
In this tutorial, we’ll set up the software-defined infrastructure (MinIO, VPC, Unbound, NGINX) in a distributed fashion and also share the code used to launch it. The result will be three identical MinIO deployments, each in its own region, with active-active replication between all three. The advantage of this design is that if one of the MinIO nodes in a particular site is down the other nodes can handle the traffic because NGINX will reroute the traffic to the healthy nodes. Moreover, if the entire site goes offline the other two sites can handle read and writes without any changes to the application since any data written to the other sites will get replicated over the site which was offline once it comes online.
It’s production ready and customizable to your requirements and the Infrastructure-as-Code has been set up as follows.
MinIO Site 1: https://github.com/minio/blog-assets/tree/main/replication-best-practices/terraform/infra/minio-1
MinIO Site 2: https://github.com/minio/blog-assets/tree/main/replication-best-practices/terraform/infra/minio-2
MinIO Site 3: https://github.com/minio/blog-assets/tree/main/replication-best-practices/terraform/infra/minio-3
Common Modules: https://github.com/minio/blog-assets/tree/main/replication-best-practices/terraform/infra/modules
Here are the components that will be deployed:
- VPC: This is where all our resources will be launched within a virtual private network. Imagine this as your own cage/rack within a datacenter.
- Unbound: This is a DNS service where you can add zone records locally for nodes to resolve MinIO hostnames. Why do we need this? The reason is twofold: First we need to ensure that the MinIO server hostnames are in sequential order in the configuration. Secondly it could become unwieldy to manage all these records in
/etc/hosts, because everytime a node gets added or removed the hosts file would need to be updated on all the nodes which could become cumbersome. This allows us to update it in Unbound and we’ll point the/etc/resolv.confto Unbound’s IP to resolve the hostnames. - NGINX: In a previous blog post we showed how to use NGINX as a reverse proxy with multiple MinIO servers as backend. While configuring site-to-site replication we will give the NGINX endpoint instead of the individual MinIO servers, this way if one of the MinIO nodes goes offline the requests will be routed to other MinIO nodes.
- MinIO: Last but certainly not least we’ll set up the MinIO cluster in a multi-node, multi-drive setup. We’ll duplicate this configuration across multiple regions so we can truly test out the site-to-site replication across geographies.
In total, we’ll launch 3 identical configurations of infrastructure in 3 different regions.
VPC
We will launch the VPC by calling the module from the directory.
This is how we are calling the module
module "hello_minio_vpc" {
source = "../modules/vpc"
minio_cidr_block = var.hello_minio_cidr_block
minio_cidr_newbits = var.hello_minio_cidr_newbits
minio_public_igw_cidr_blocks = var.hello_minio_public_igw_cidr_blocks
minio_private_ngw_cidr_blocks = var.hello_minio_private_ngw_cidr_blocks
minio_private_isolated_cidr_blocks = var.hello_minio_private_isolated_cidr_blocks
}This is where we’ve defined the VPC module
Unbound
Using the VPC resources we created in the previous step, we’ll launch Unbound in the public subnet of that VPC. This could be in a private subnet as well, as long as you do not need any other external access to the DNS server.
module "hello_minio_instance_unbound" {
source = "../modules/instance"
minio_vpc_security_group_ids = [module.hello_minio_security_group_unbound.minio_security_group_id]
minio_subnet_id = module.hello_minio_vpc.minio_subnet_public_igw_map[local.common_public_subnet]
minio_ami_filter_name_values = var.hello_minio_ami_filter_name_values
minio_ami_owners = var.hello_minio_ami_owners
minio_instance_type = var.hello_minio_instance_type
minio_instance_key_name = var.hello_minio_instance_key_name
minio_instance_user_data = templatefile("../templates/_user_data_unbound.sh.tftpl", {})
}Most of the Unbound configuration is managed via _user_data_unbound.sh.tftpl.
But in order to configure Unbound we’ll need the private IPs of the MinIO servers we’ll launch, but at this point the MinIO servers are not up yet.
Once the MinIO servers are up and you have their private IPs, add the following config to line #2 of the /etc/unbound/unbound.conf.d/myunbound.conf file right under the server: directive. You need to add this to each of the Unbound servers running on each site with the respective private IPs of each of the MinIO nodes.
local-zone: minio.local transparent
local-data: "server-1.minio.local A <MinIO Node 1 Private IP>"
local-data: "server-2.minio.local A <MinIO Node 2 Private IP>"
local-data: "server-3.minio.local A <MinIO Node 3 Private IP>"Be sure to restart Unbound after updating the config above with the A records for the changes to take effect
systemctl restart unboundNGINX cluster
In the NGINX blog post, we used the following configuration, which we’ve tweaked here slightly to match MinIO server hostnames
upstream minio_server {
server server-1.minio.local:9000;
server server-2.minio.local:9000;
server server-3.minio.local:9000;
}
server {
listen 80 default_server;
ignore_invalid_headers off;
client_max_body_size 0;
proxy_buffering off;
proxy_request_buffering off;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_connect_timeout 300;
proxy_http_version 1.1;
proxy_set_header Connection "";
chunked_transfer_encoding off;
proxy_pass http://minio_server;
}
}We’ll launch the NGINX servers using this configuration
module "hello_minio_instance_nginx" {
source = "../modules/instance"
minio_vpc_security_group_ids = [module.hello_minio_security_group_nginx.minio_security_group_id]
minio_subnet_id = module.hello_minio_vpc.minio_subnet_public_igw_map[local.common_public_subnet]
minio_ami_filter_name_values = var.hello_minio_ami_filter_name_values
minio_ami_owners = var.hello_minio_ami_owners
minio_instance_type = var.hello_minio_instance_type
minio_instance_key_name = var.hello_minio_instance_key_name
minio_instance_user_data = templatefile("../templates/_user_data_nginx.sh.tftpl", {
unbound_ip = module.hello_minio_instance_unbound.minio_instance_private_ip
})
minio_instance_user_data_replace_on_change = false
depends_on = [
module.hello_minio_instance_unbound
]
}The NGINX VM we launched will use the user data from _user_data_nginx.sh.tftpl which helps us install and configure NGINX as soon as the VMs are launched.
MinIO cluster
Last but not least, we’ll launch 3 MinIO nodes using the configuration below which will not only launch the VM but also attach a secondary volume that will be used for data.
module "hello_minio_instance_minio" {
source = "../modules/instance"
for_each = var.hello_minio_private_ngw_cidr_blocks
minio_vpc_security_group_ids = [module.hello_minio_security_group_minio.minio_security_group_id]
minio_subnet_id = module.hello_minio_vpc.minio_subnet_private_ngw_map[each.key]
minio_ami_filter_name_values = var.hello_minio_ami_filter_name_values
minio_ami_owners = var.hello_minio_ami_owners
minio_instance_type = var.hello_minio_instance_type
minio_instance_key_name = var.hello_minio_instance_key_name
minio_instance_user_data = templatefile("../templates/_user_data_minio.sh.tftpl", {
minio_version = "20221207005637.0.0"
unbound_ip = module.hello_minio_instance_unbound.minio_instance_private_ip
})
}
resource "aws_ebs_volume" "ebs_volume_minio" {
for_each = var.hello_minio_private_ngw_cidr_blocks
availability_zone = each.key
size = 10
}
resource "aws_volume_attachment" "volume_attachment_minio" {
for_each = var.hello_minio_private_ngw_cidr_blocks
device_name = "/dev/xvdb"
volume_id = aws_ebs_volume.ebs_volume_minio[each.key].id
instance_id = module.hello_minio_instance_minio[each.key].minio_instance_id
}Once the VM is launched with the attached HDD, we’ll format and mount it in _user_data_minio.sh.tftpl. It also has the MinIO configuration that goes in /etc/default/minio with our multi-node setup.
Ideally the only thing you need to manually configure in this setup is adding the MinIO server’s private IP as DNS A records to Unbound, the rest should be configured automagically based on the DNS names we preset.
Start MinIO service on all the nodes. You can either use something like Ansible or do it manually
systemctl start minioSite Replication Configuration
Next we’ll actually launch the infrastructure we configured in the previous steps. This involves launching the VMs using Terraform and then configuring site replication with MinIO mc client.
Go into each of the minio-1, minio-2 and minio-3 directories and run the terraform command to launch infrastructure.
cd minio-1
terraform apply
cd minio-2
terraform apply
cd minio-3
terraform applyOnce all three sites are up the output will show the Public IPs of Unbound and NGINX along with the Private IPs of the 3 MinIO nodes similar to below.
hello_minio_aws_instance_nginx = "<public_ip>"
hello_minio_aws_instance_unbound = "<public_ip>"
minio_hostname_ips_map = {
"server-1.minio.local" = "<private_ip>"
"server-2.minio.local" = "<private_ip>"
"server-3.minio.local" = "<private_ip>"
}Don’t forget to configure the Unbound A records using the configuration we showed earlier in the previous step when configuring unbound.
Log into one of the NGINX nodes in site 1 to set up mc alias for all three sites. Ensure there is no data in any of the sites.
/opt/minio-binaries/mc alias set minio1 http://<nginx_public_ip> minioadmin minioadmin
/opt/minio-binaries/mc alias set minio2 http://<nginx_public_ip> minioadmin minioadmin
/opt/minio-binaries/mc alias set minio3 http://<nginx_public_ip> minioadmin minioadminLet's set it up so it replicates across all 3 sites
$ /opt/minio-binaries/mc admin replicate add minio1 minio2 minio3
Requested sites were configured for replication successfully.Verify the 3 sites are configured correctly
/opt/minio-binaries/mc admin replicate info minio1
SiteReplication enabled for:
Deployment ID | Site Name | Endpoint
f96a6675-ddc3-4c6e-907d-edccd9eae7a4 | minio1 | http://<nginx_public_ip>
0dfce53f-e85b-48d0-91de-4d7564d5456f | minio2 | http://<nginx_public_ip>
8527896f-0d4b-48fe-bddc-a3203dccd75f | minio3 | http://<nginx_public_ip>Check to make sure replication is working properly
/opt/minio-binaries/mc admin replicate status minio1
Bucket replication status:
No Buckets present
Policy replication status:
● 5/5 Policies in sync
User replication status:
No Users present
Group replication status:
No Groups presentCreate a bucket in minio1
/opt/minio-binaries/mc mb minio1/testbucketAdd any object into the bucket
/opt/minio-binaries/mc cp my_object minio1/testbucketList the objects in the other sites, in this case both minio2 and minio3
/opt/minio-binaries/mc ls minio2/testbucket
[2022-12-19 18:52:09 UTC] 3.0KiB STANDARD my_object
/opt/minio-binaries/mc ls minio3/testbucket
[2022-12-19 18:52:09 UTC] 3.0KiB STANDARD my_objectAs you can see it's almost instantaneous to replicate data to other sites even though they are geographically disparate.
Site Replication and Automation Enable the Multi-Cloud
The cloud operating model allows you to run the same setup and configuration no matter if it's a physical datacenter or virtual resources on the cloud. This is the only way to effectively deal with massive volumes of data, and the AI and analytics that must take place in real time. You must also design for a multi-cloud architecture that collects and shares data with the compute resources/best-of-breed services regardless of where they are to ensure the overhead of managing the infrastructure is as low as possible for your engineering and DevOps teams.
Site replication underlines the functionality of a multi-cloud architecture by setting up multiple sites and handing the replication on the server side. This allows you to simplify data management, metadata and configuration across multiple sites without any additional overhead required for the application to be modified in case of failures to one node or even the entire site. We showed you a working example of how to deploy to multiple sites/regions to configure replication and at the same time we’ve deployed for high availability, placing each of the multi-site MinIO clusters in a separate region to enable a robust business continuity and disaster recovery strategy.
If you have any questions about running this setup on your end or would like us to help you out with setting this up please reach out to us in Slack!






