MinIO and Apache Tika: A Pattern for Text Extraction
Tl;dr:
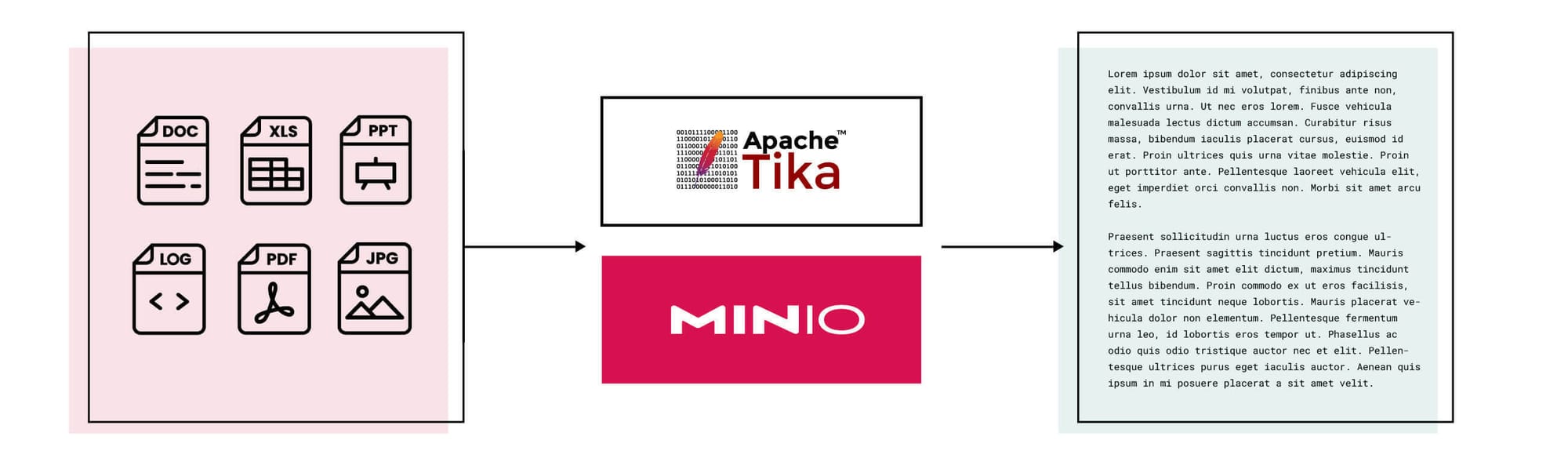
In this post, we will use MinIO Bucket Notifications and Apache Tika, for document text extraction, which is at the heart of critical downstream tasks like Large Language Model (LLM) training and Retrieval Augmented Generation (RAG).
The Premise
Let’s say that I want to construct a dataset of text that I can then use to fine-tune an LLM. In order to do this, we first need to assemble various documents (that might be in different form-factors due to their source) and extract the text from them. Dataset security and auditability are paramount, so these unstructured documents need to be stored in an object store to match. MinIO is the object store built for these situations and more. On the other hand, Apache Tika is a toolkit that “detects and extracts metadata and text from over a thousand different file types (such as PPT, XLS, and PDF).” Together, they come together to form a system that can achieve our objective.
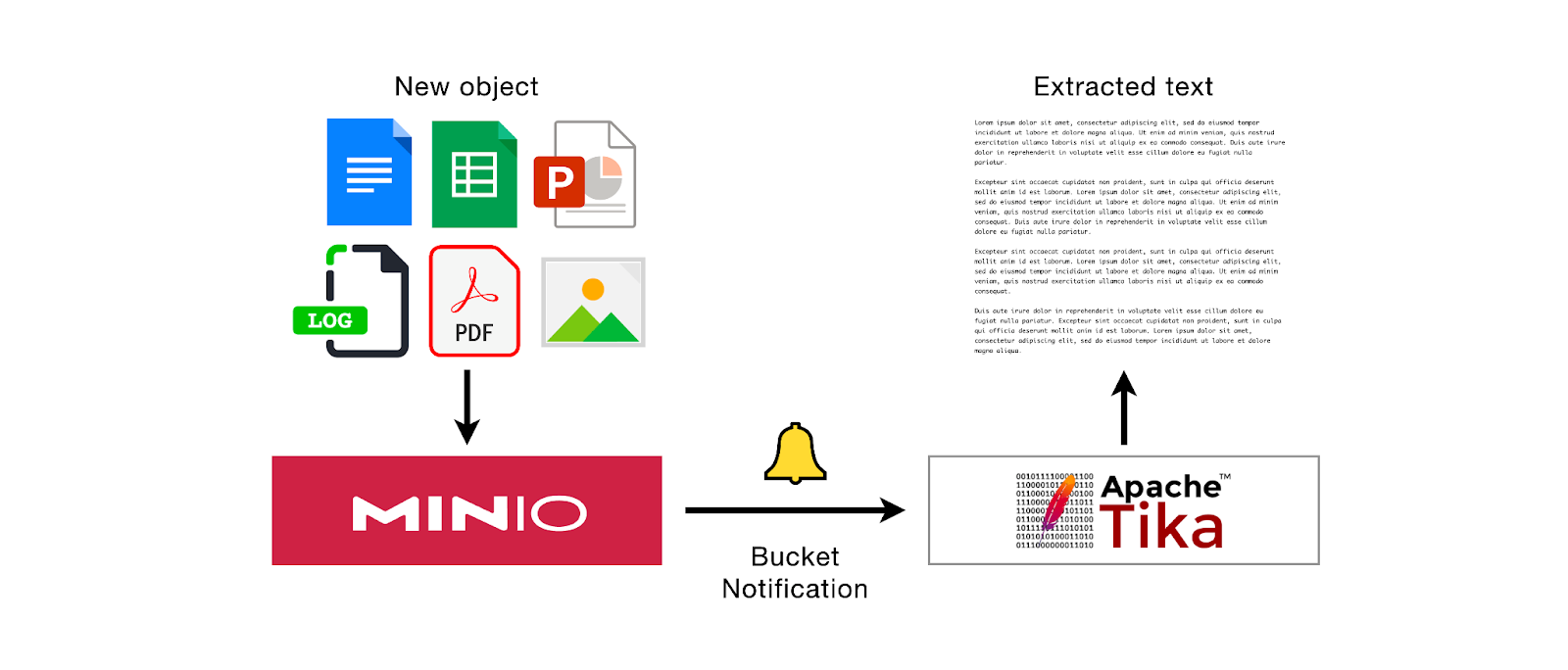
In an earlier post, we put together an object detection inference server with MinIO right out of the box and roughly 30 lines of code. We are going to leverage that highly portable and repeatable architecture once again, this time for the task of text extraction. Below is a rough depiction of the system we are going to build.
Setting up Apache Tika
The simplest way to get Apache Tika up and running is with the official Docker image. Check Docker Hub for your desired Tika image version/tag.
In this example, I allow it to use and expose the default port, 9998.
docker pull apache/tika:<version>
docker run -d -p 127.0.0.1:9998:9998 apache/tika:<version>Use docker ps or Docker Desktop to verify that the Tika container is running and has exposed port 9998.
Building the Text Extraction Server
Now that Tika is running, we need to construct a server that can programmatically make Tika extraction requests for new objects. Following that, we need to configure webhooks on a MinIO bucket to alert this server about the arrival of new objects (in other words, PUT events for a bucket). Let’s walk through it step-by-step.
To keep things relatively simple and to highlight the portability of this approach, the text extraction server will be built in Python, using the popular Flask framework. Here’s the code for the server (also available in the MinIO Blog Resources repository under extraction_server.py) that performs text extraction on new documents added to a bucket with the use of Tika (via Tika-Python)
"""
This is a simple Flask text extraction server that functions as a webhook service endpoint
for PUT events in a MinIO bucket. Apache Tika is used to extract the text from the new objects.
"""
from flask import Flask, request, abort, make_response
import io
import logging
from tika import parser
from minio import Minio
# Make sure the following are populated with your MinIO details
# (Best practice is to use environment variables!)
MINIO_ENDPOINT = ''
MINIO_ACCESS_KEY = ''
MINIO_SECRET_KEY = ''
# This depends on how you are deploying Tika (and this server):
TIKA_SERVER_URL = 'http://localhost:9998/tika'
client = Minio(
MINIO_ENDPOINT,
access_key=MINIO_ACCESS_KEY,
secret_key=MINIO_SECRET_KEY,
)
logger = logging.getLogger(__name__)
app = Flask(__name__)
@app.route('/', methods=['POST'])
async def text_extraction_webhook():
"""
This endpoint will be called when a new object is placed in the bucket
"""
if request.method == 'POST':
# Get the request event from the 'POST' call
event = request.json
bucket = event['Records'][0]['s3']['bucket']['name']
obj_name = event['Records'][0]['s3']['object']['key']
obj_response = client.get_object(bucket, obj_name)
obj_bytes = obj_response.read()
file_like = io.BytesIO(obj_bytes)
parsed_file = parser.from_buffer(file_like.read(), serverEndpoint=TIKA_SERVER_URL)
text = parsed_file["content"]
metadata = parsed_file["metadata"]
logger.info(text)
result = {
"text": text,
"metadata": metadata
}
resp = make_response(result, 200)
return resp
else:
abort(400)
if __name__ == '__main__':
app.run()
Let’s start the extraction server:
Make note of the hostname and port that the Flask application is running on.
Setting up Bucket Notifications
Now, all that’s left is to configure the webhook for the bucket on the MinIO server so that any PUT events (a.k.a., new objects added) in the bucket will trigger a call to the extraction endpoint. With the mc tool, we can do this in just a few commands.
First, we need to set a few environment variables to signal to your MinIO server that you are enabling a webhook and the corresponding endpoint to be called. Replace <YOURFUNCTIONNAME> with a function name of your choosing. For simplicity, I went with ‘extraction.’ Also, make sure that the endpoint environment variable is set to the correct host and port for your inference server. In this case, http://localhost:5000 is where our Flask application is running.
export MINIO_NOTIFY_WEBHOOK_ENABLE_<YOURFUNCTIONNAME>=on
export MINIO_NOTIFY_WEBHOOK_ENDPOINT_<YOURFUNCTIONNAME>=http://localhost:5000Once you have set these environment variables, start the MinIO server (or if it was already running, restart it). In the following steps, we will be needing an ‘alias’ for your MinIO server deployment. To learn more about aliases and how to set one, check out the documentation. We will also be making use of mc, the MinIO Client command line tool, so make sure you have it installed.
Next, let’s configure the event notification for our bucket and the type of event we want to be notified about. For the purposes of this project, I created a brand new bucket also named ‘extraction’. You can do this either via the MinIO Console or mc commands Since we want to trigger the webhook on the addition of new objects to the ‘extraction’ bucket, PUT events are our focus. Replace ALIAS with the alias of your MinIO server deployment and BUCKET with the desired bucket on that server. Just as before, make sure to replace <YOURFUNCTIONNAME> with the same value that you used in the earlier step.
mc event add ALIAS/BUCKET arn:minio:sqs::<YOURFUNCTIONNAME>:webhook --event put
Finally, you can check that you have configured the correct event type for the bucket notifications by verifying whether s3:ObjectCreated:* is outputted when you run this command:
mc event ls ALIAS/BUCKET arn:minio:sqs::<YOURFUNCTIONNAME>:webhook
If you want to learn more about publishing bucket events to a webhook, check out the documentation as well as this deep-dive into event notifications. Now, we are ready to try out our text extraction server.
Try it Out
Here’s a document that I want to extract text from. It’s a PDF of the Commodities Future Modernization Act of 2000, an influential piece of financial legislation in the United States.

I put this PDF in my ‘extraction’ bucket using the MinIO Console.
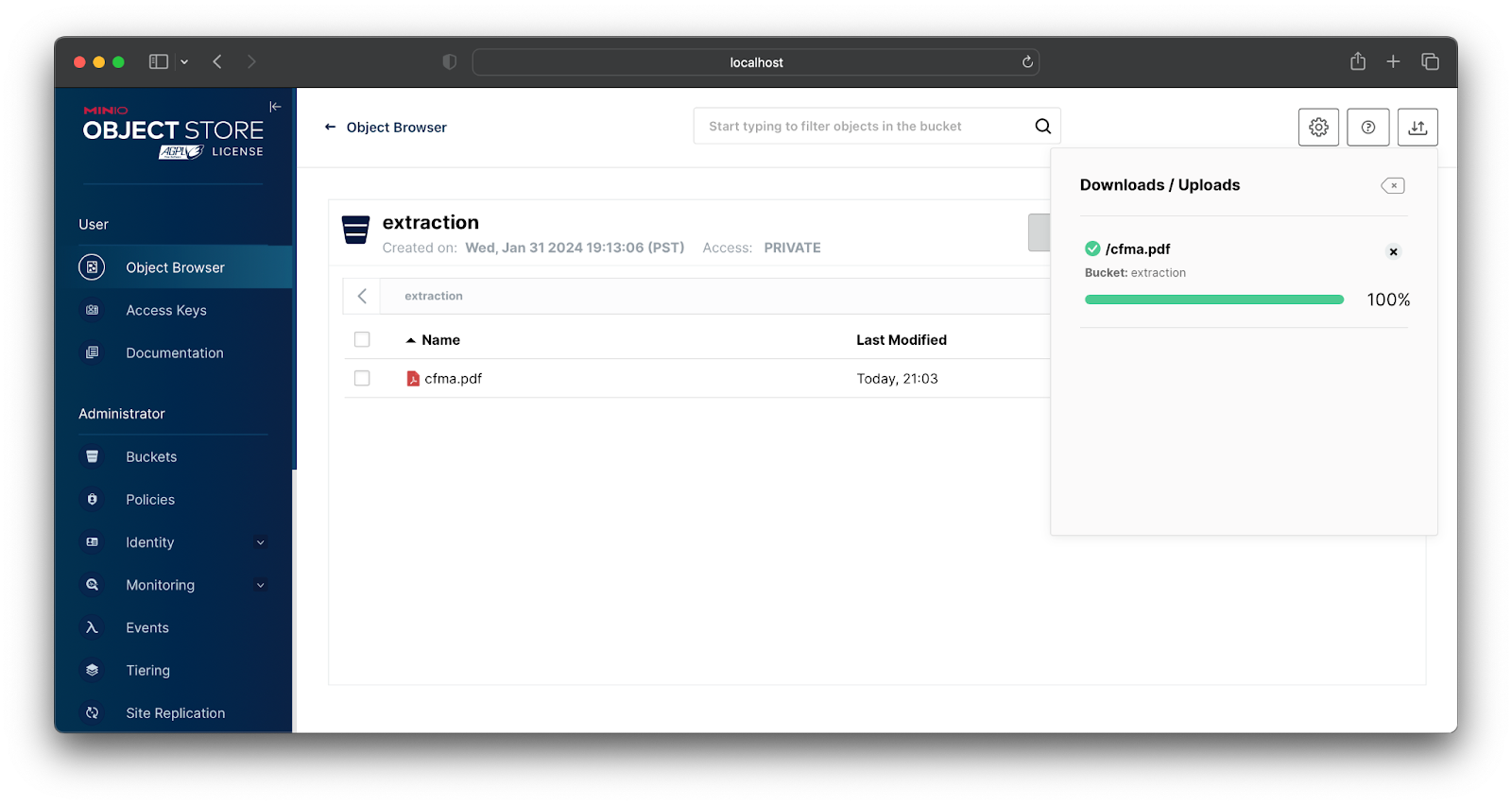
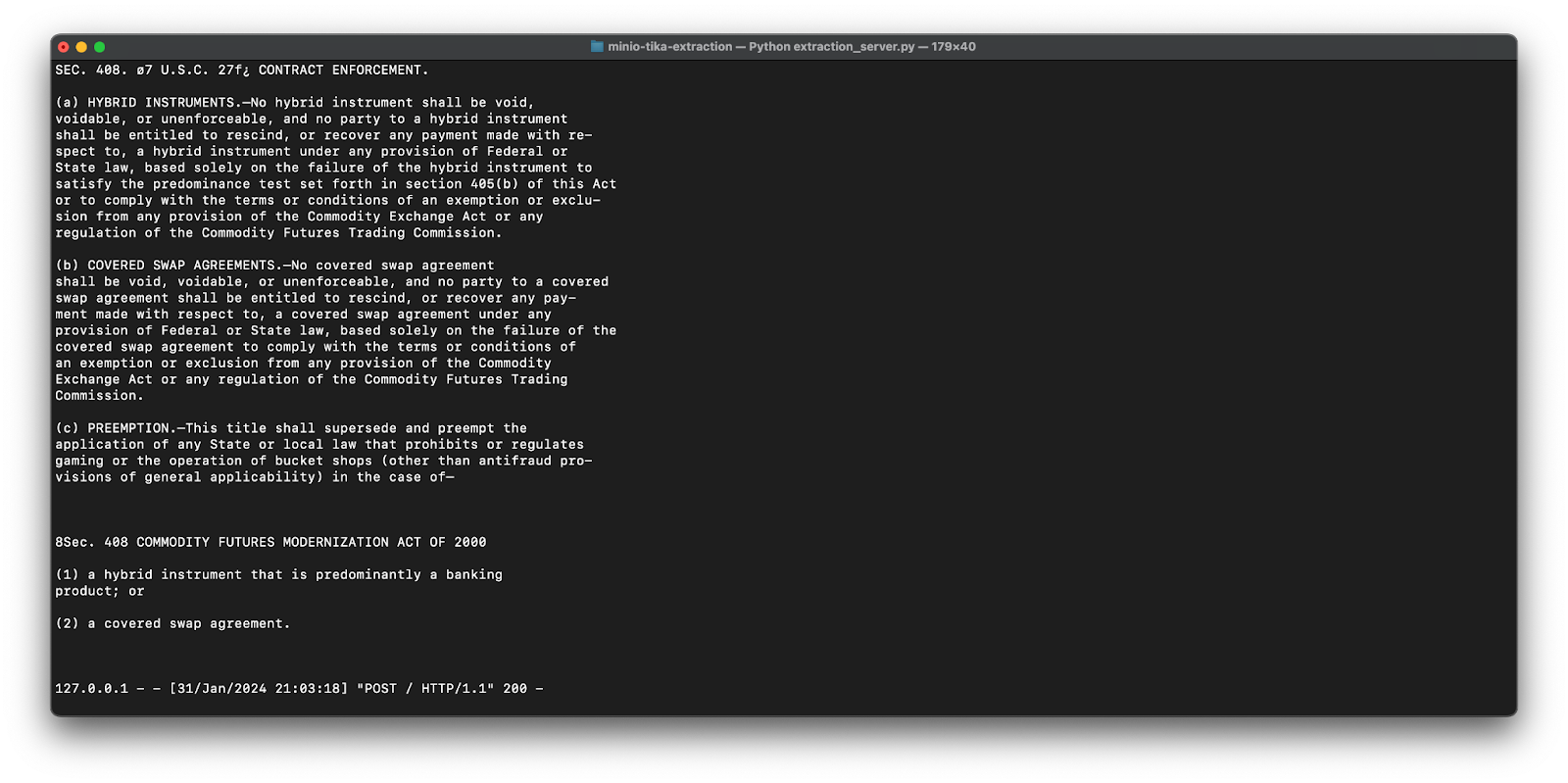
This PUT event triggers a bucket notification which then gets published to the extraction server endpoint. Accordingly, the text is extracted by Tika and printed to the console.
Next Steps
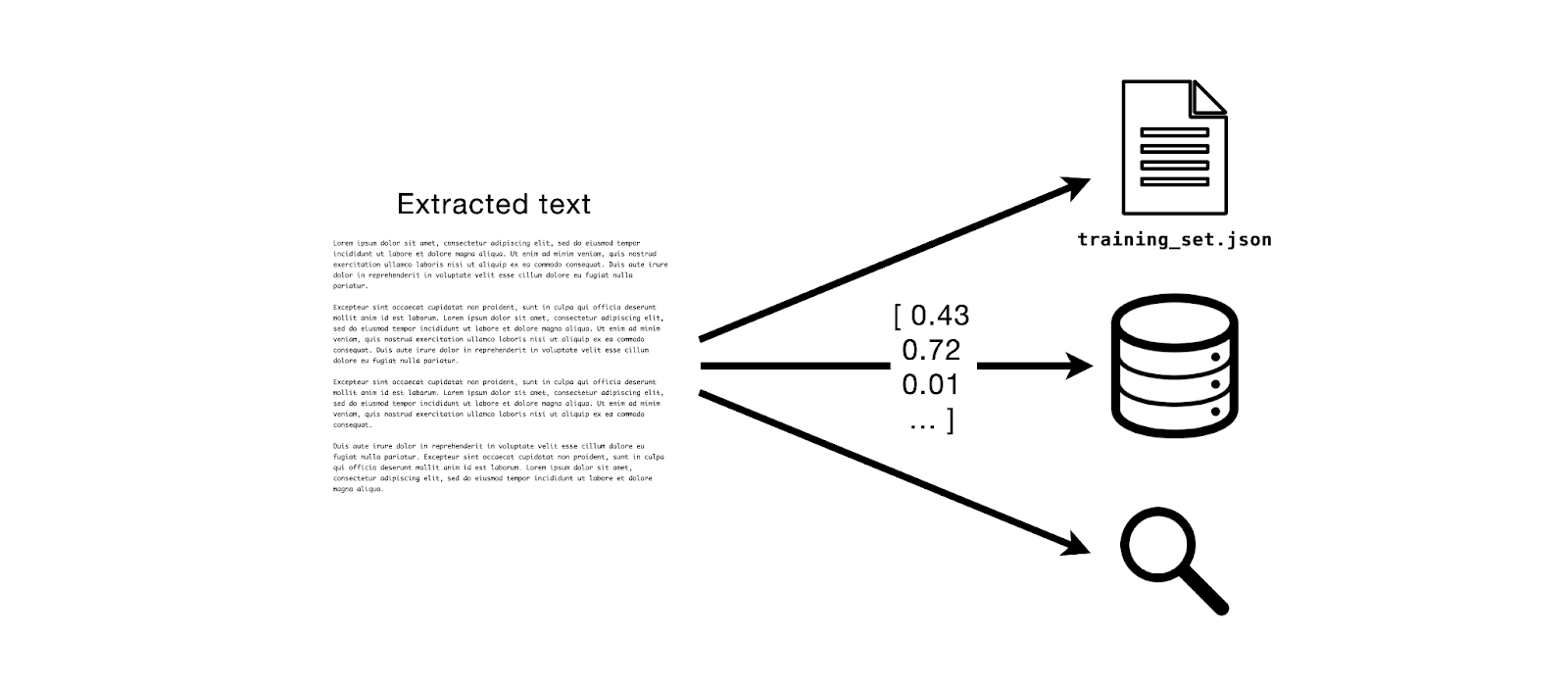
Although we are just printing out the extracted text for now, this text could have been used for many downstream tasks, as hinted at in The Premise. For example:
- Dataset creation for LLM fine-tuning: Imagine you want to fine-tune a large language model on a collection of corporate documents that exist in a variety of file formats (i.e., PDF, DOCX, PPTX, Markdown, etc.). To create the LLM-friendly, text dataset for this task, you could collect all these documents into a MinIO bucket configured with a similar webhook and pass the extracted text for each document to a dataframe of the fine-tuning/training set. Furthermore, by having your dataset’s source files on MinIO, it becomes much easier to manage, audit, and track the composition of your datasets.
- Retrieval Augmented Generation: RAG is a way that LLM applications can make use of precise context and avoid hallucination. A central aspect of this approach is ensuring your documents’ text can be extracted and then embedded into vectors, thereby enabling semantic search. In addition, it’s generally a best practice to store the actual source documents of these vectors in an object store (like MinIO!). With the approach outlined in this post, you can easily achieve both. If you want to learn more about RAG and its benefits, check out this earlier post.
- LLM Application: With a programmatic way to instantly extract the text from a newly stored document, the possibilities are endless, especially if you can utilize an LLM. Think keyword detection (i.e., Prompt: “What stock tickers are mentioned?”), content assessment (i.e., Prompt: “Per the rubric, what score should this essay submission get?), or pretty much any kind of text-based analysis (i.e., Prompt: “Based on this log output, when did the first error occur?”).
Beyond the utility of Bucket Notifications for these tasks, MinIO is built to afford world-class fault tolerance and performance to any type and number of objects– whether they are Powerpoints, images, or code snippets.
If you have any questions join our Slack Channel or drop us a note at hello@min.io. We are here to help you.






