Introducing MinLZ compression algorithm

There exists different types of compression algorithms and very good implementations. At MinIO we already use an enhanced version of Snappy, which has been serving us well. But as time has moved on we found some possible improvements for better encoding of the compressed data.
We therefore set our goals:
- While keeping the existing speed of our compressor, would it be possible to improve compression enough to justify an upgrade with an easy upgrade path.
- Still provide compression/decompression that will outperform IO, so it can safely be left on.
This will explain some of the design considerations made for creating MinLZ. MinLZ is a compression algorithm developed by MinIO. The main goal is to provide a format that offers the best-in-class compression while providing very fast decompression even with modest hardware.
Snappy/LZ4 Heritage
An important factor we had to consider was the decompression speed. We also had to consider not implementing features that require certain CPU features to make operations fast. Since CPUs are scaling towards more cores we focused on having good options for highly concurrent compression and decompression while targeting a similar single-threaded performance.
Since our main goal is to retain the speed, we decided to stick to fixed size encoding, with byte aligned operations, since this allows very fast decoding without specific CPU instructions. Furthermore, we want our compressed output to be optionally seekable with an index and always able to be (de)compressed concurrently. This means that MinLZ also keeps compressed blocks independent of each other.
Lifting any of these limitations would undoubtedly increase the potential compression — but we would also begin to overlap with good compressors like Zstandard, which provides all of the above, but typically at a lower speed. Our goal for compression speed was to retain the same speed, but possibly sacrifice some encoding speed for decompression speed.
We see MinLZ as the next generation of LZ4/Snappy and we provide full backwards compatibility with Snappy/S2 in our Go implementation.
Static Encoding & Test Sets
Choosing a static encoding means that there will be little flexibility to adapt to content types dynamically. Different content will have different match characteristics. We found that most “typical” test-sets used for testing aren't very reflective of the typical content we encounter. For static encoding this is particularly important, since an improvement in one datatype can easily produce a regression in another.
Our primary data type has been on serialized data. That means that improvements on these data types have had the highest weight in our decisions. This ranges from human readable content like HTTP logs, JSON, CSV, XML to binary types like Protobuf, MsgPack, and database dumps.
Mixed files (file system backups), filesystem images and natural text have been checked for regressions, but have not been given special consideration.
Related: Data Storage Optimization Myths: Duduplication vs Compression
Block Improvements
A “block” is a stream of operations. Usually these are “emit literals” or copy operations. Emitting literals simply tells the decoder to append a number of given bytes to the output, which is then the base for the copy operations.
LZ4 is extremely fast to decompress since there is very little branching in the decoder. Those branches are easy to predict for the CPU. Our overall impression is that the flexibility of Snappy encoding is the better approach for more efficient results and worth taking a small speed hit for. We decided to continue on the “Snappy” approach, but see if there was anything that could be improved.
Copy Encoding
Copies are the base of LZ77 encoding. When decoding a stream a copy operation basically tells the encoder to “go back by a specific offset and copy a number of bytes to output”.
This is the encoding of offsets/lengths that are possible with Snappy:
The first limitation we saw was that lengths were quite limited. S2 added a “repeat” with the Invalid “Tag 1, Offset = 0” encoding, allowing it to extend the previous match. This allowed any length of match to be encoded as a copy+repeat. It was however wasting all the offset bits, since this had to be 0 to indicate the repeat.
Another thing that stood out was that Snappy jumps from 16-bit to 32 bit offsets. Many of the 32 bits used here would most often consist of 0s, since blocks never really got to this size.
Finally, when observing statistics, we found that moving one bit from the Tag 1 offsets to the length would yield better compression - even with less expensive repeats.
Looking at the offsets, we first got rid of the invalid “offset=0” value. Not having to check for that seems to outweigh the unconditional addition of a base value.
Second of all, the longer offsets have a 64 byte minimum. While this does enable slightly longer offsets, that is not the primary goal. The goal of this base value is to avoid a check of overlapping copies when decoding. With a base value of 64, we guarantee that it will always be possible to copy long matches 64 bytes at the time without risking overlapping the output.
This moves some branching from the decoder to the encoder. We did experiment with using higher base values, however it provided little benefit and just limited the flexibility of the encoder.
Another change is to add more flexible length encodings. This means that similar to literal encoding we reserve some lengths as special values, that will read the actual length from 1-3 following bytes. These all have base values, which also reduces further branching in the decoder.
Repeat Encoding
A “repeat” means a copy with the same offset as the last match. This can be used to extend the last copy or - more often - resume copying after one or more bytes that were different from the last output.
As mentioned above, the repeat encoding in S2 was a bit wasteful, since it was designed to fit into existing encoding.
After some experimentation, we found that long length literal operations were pretty rare, so we decided to “take” one bit from the length encoding and use that to indicate a repeat.
The repeat lengths and literal length encoding is the same, so this decoding can be shared.
We experimented with different repeat types. First a repeat with small offset. This will allow us to encode small inserts or deletes. However, from several experiments this had little impact, giving small improvements on some payloads and regressions on others due to taking away bits from other places. We decided to abandon this since it wasn’t worth the complexity and extra processing and the cost of detecting these.
Similarly, we experimented with having longer repeat history, similar to zstandard - and “promoted repeats”, where often used offsets would get stored. However, again, the gains were marginal - and while some payloads benefitted, the extra complexity, added decoding processing and size regressions on other payloads made us abandon this.
Fused Literals
Looking at LZ4, one thing that stood out was that it was very efficient with many small literal and copy blocks.
This is because the base encoding of operations is done like this…
LZ4 Encoding:
In cases where there are few literals and short copies both operations together only have a single byte of overhead.
Again, after doing some statistical analysis, we found that most literal blocks were very short. In fact most are less than 4 bytes. With one byte over overhead - to store tag and length plus the copy tag, these were quite inefficient.
With long offsets we found that we could easily spare 3 bits by limiting the maximum offset to 2MB. Limiting offsets would limit the possible matches that could be referenced, but we found that in most payloads long offsets were generally quite rare. Being able to emit fused literals on average made up for the benefits of very long offsets.
To have efficient representation of short+closer matches with fused literals we also added a fused literal mode with 2 byte offset similar to the copy. With that we ended up with the following encoding types for fused literals:
We can now represent a short literal + medium offset with only 1 byte overhead, and “long offsets” can have 0 to 3 literals without any additional overhead.
The limited back-reference offset will only “affect” blocks that are actually bigger than 2MiB, and we found that it only had a small impact on most practical content, so we believe this is a worthwhile tradeoff. Furthermore, limiting offsets also reduces the chance of referencing data that is out of CPU cache, increasing decompression speed.
The limited length of the fused literals and the guarantee that it will always be followed by a 4 byte copy also means that copying these literals can be done with less branching than separate blocks.
To read all the details of the encoding, see the SPEC.md in the github repository. We also provide simplified compression/decompression examples in internal/reference.
Stream Improvements
The stream format remains largely unchanged from Snappy/S2, except that previous compressed blocks are no longer used.
Stream Identifier
The stream identifier is changed with a new magic string. Also the stream identifier now includes the maximum block size that can be expected on the stream. This allows for allocating buffers at an appropriate size.
EOF validation
Streams now have EOF validation. Previously (in Snappy) there was no way to detect truncated streams at a block boundary. An EOF block optionally includes the number of decompressed bytes that should have been produced by the stream.
A valid MinLZ must include an EOF block, but may be followed by another stream identifier.
Stream Seeking
MinLZ carries over stream indexes from S2. A stream index allows random seeking within a compressed stream.
The index can either be added to the end of a stream or kept separately depending on the use case. All indexes are optional.
User Defined Chunks
The user defined chunks have been revised a bit.
- 0x00 -> 0x7F are internal types and should not be used for user data.
- 0x80 -> 0xBF are now defined as “skippable user chunks”. When encountering an unknown chunk, it can safely be skipped.
- 0xC0 -> 0xFD are “non-skippable user chunks”. If encountering an unknown chunk with one of these IDs decoding should stop.
You should still use additional checks to ensure that the chunk is of the expected type.
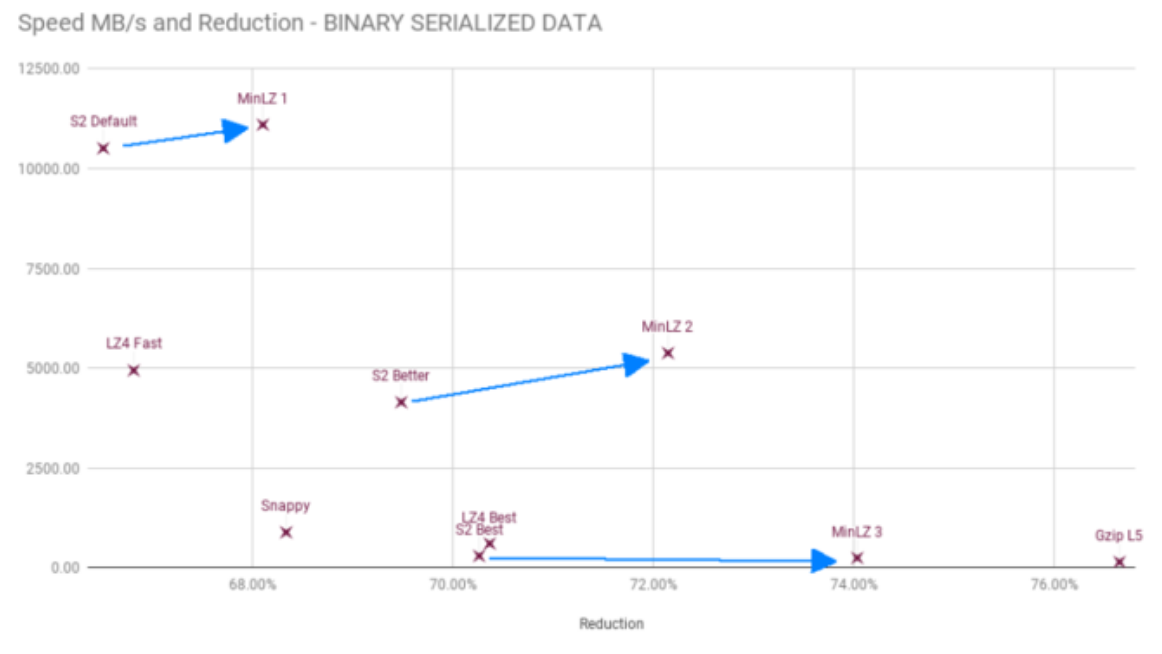
Efficiency and Benefits
So how much of a difference does this all make? Here are some stats and graphs that show the effective savings you will see for each data type, meaning you will get 10-20% disk space for free compared to the existing compression.
Give it a go
If you want to try out MinLZ without any code, go to https://github.com/minio/minlz, you can use our commandline tool.
The tool is called mz and allows stream and block compression and decompression Furthermore, it adds “tail” and “offset” decompression of streams with an index, as well as http/https input.
If you have any questions be sure to reach out to us at hello@min.io.






